Backpressure Contracts for Device Ingest


Modern device systems do not usually fail because one request is too large. They fail because many reasonable requests arrive at the wrong time, under the wrong retry behavior, with no shared contract between client and server.
That pattern shows up most clearly during reconnects. Devices go offline for minutes or hours, collect a backlog locally, then come back at once. If the client also has “replay last N minutes” logic, if the API responds with 429 or transient 5xx under pressure, and if retries are unbounded or poorly shaped, the ingest path can turn into an amplifier. A backlog becomes a burst. A burst becomes a retry loop. And that loop pushes storage and indexing layers into unstable territory—hot DynamoDB partitions, overloaded OpenSearch shards, growing queues, rising latency, and avoidable cost.
The fix is not “more throttling” in isolation. It is an explicit backpressure contract across the entire ingest path. Clients need to know how fast they are allowed to send, servers need to communicate partial progress clearly, retries must be made safe through idempotency, and downstream systems must be protected from synchronized write spikes. When this contract is designed well, reconnects stop being chaotic events. Recovery becomes predictable.
The real failure mode is replay amplification
A reconnect storm is rarely caused by a single mechanism. It is usually the multiplication of several small design choices:
- Devices buffer data while offline.
- Reconnect logic replays a recent time window “just in case.”
- APIs reject excess load with 429 or intermittent 5xx.
- Clients retry too aggressively, often with many concurrent requests.
- The same data is written multiple times because deduplication is weak.
- Indexing pipelines treat duplicates as fresh work and reprocess them.
This is replay amplification: one unit of original data creates multiple units of ingest work. In healthy systems, retries may raise request volume modestly. In unstable systems, they multiply it.
A useful way to think about the problem is this:
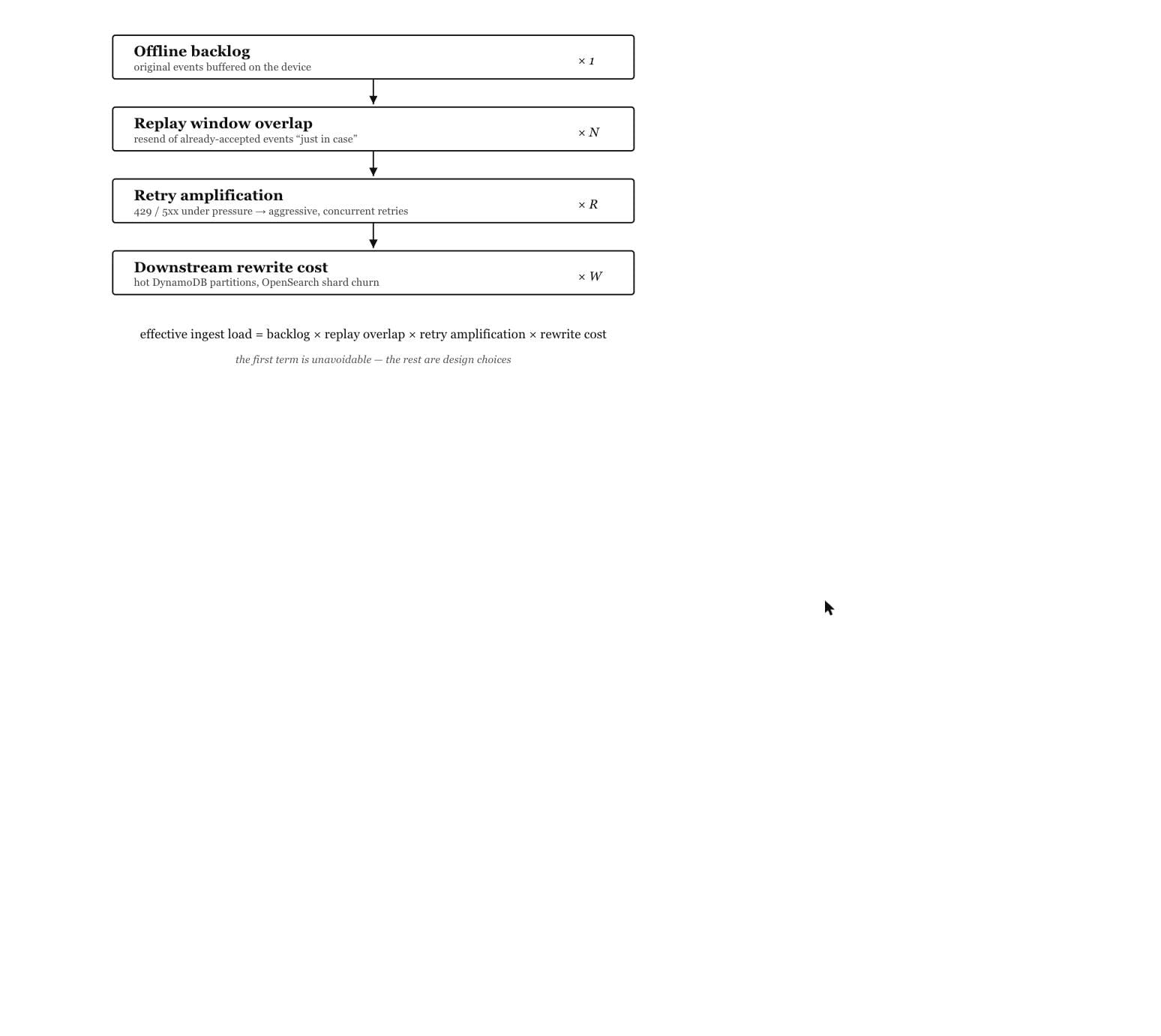
effective ingest load = original backlog × replay overlap × retry amplification × downstream rewrite cost
The first term is unavoidable. The rest are design choices.
A disciplined backpressure contract is about shrinking those multipliers. It does not eliminate reconnect bursts entirely, but it ensures they degrade into controlled recovery instead of runaway load.
How Replay Amplification Builds
During reconnect, offline backlog, overlapping replay windows, and retries multiply into far more ingest work than the original data ever required:
Backpressure is not a throttle. It is a contract.
Many pipelines apply throttling only at the edge: reject requests when traffic is high and hope clients back off. That protects the service for a moment, but it does not create coordinated behavior. In fact, it often makes the pattern worse, because clients receive a generic failure and respond independently, each retrying on its own schedule.
A backpressure contract is broader. It answers five questions explicitly:
What can be accepted now?
Not every request needs an all-or-nothing answer. Servers should be able to accept part of a batch and make that progress visible.
How should the client resume?
Clients need a concrete watermark or cursor so they do not resend already accepted data.
When should the client retry?
Retry timing must be communicated, not guessed. Retry-After is part of the protocol, not a nice-to-have header.
What happens if data is resent anyway?
Retries must be safe. That means idempotency all the way down, not only at the API layer.
How is downstream capacity protected?
Even when the API is stable, storage and indexing backends must not receive synchronized spikes beyond their sustainable write envelope.
Once framed this way, backpressure becomes an architectural discipline rather than a narrow rate-limit feature.
At Hoomanely, this way of thinking matters because systems connected to real devices do not behave like clean web clients. Connectivity is intermittent, power cycles happen, and local buffering is normal. For products in this category, ingest reliability is part of product trust. A device can only feel dependable if reconnects recover cleanly without silent loss, runaway duplication, or unstable downstream behavior.
Start at the API: partial acceptance and explicit progress
The most important improvement in reconnect-heavy ingest systems is moving away from binary success/failure responses for large batches.
When a device sends a backlog, the server should not be forced into only two choices: accept everything or reject everything. Under pressure, the better behavior is often partial acceptance. The server accepts up to a safe amount, persists exactly what was accepted, and returns a response that tells the client where to resume.
That response should include:
- a high-watermark indicating the last accepted event sequence, timestamp, or offset
- the accepted count
- the rejected or deferred range
- a Retry-After value that reflects current capacity
- optionally, a reason code such as
queue_saturated,tenant_rate_limited, orsearch_backpressure
This matters because most ingest storms are worsened by ambiguity. If the client does not know whether event 712 was accepted, it often resends 680–750. That overlap is where replay multiplication begins.
A better contract looks like this conceptually:
- Client sends batch
[601..750] - Server safely accepts
[601..690] - Server returns watermark
690, retry-after8s - Client resumes from
691, not601
That single change removes a huge class of overlap-driven duplicates.
The server should also cap per-request work deliberately. Large backlog flushes should be segmented by policy, not by accident. A request that attempts to push 30 minutes of buffered data should not be allowed to monopolize API workers, queue slots, and downstream write bandwidth. Bounded work per request creates fairness and keeps latency predictable for the rest of the fleet.
Admission control must exist before storage pain appears
A common mistake is to discover backpressure too late—only when DynamoDB throttles or OpenSearch indexing slows down. By then, the system is already in the failure path.
Admission control should happen earlier, at the point where the system still has choices. That usually means three layers:
Concurrency caps at the API layer
Limit how many ingest batches can actively execute at once, globally and per tenant or device group. This prevents a single reconnect wave from consuming all workers.
Queue-backed smoothing
Do not force every accepted batch into immediate downstream writes. A queue gives the system a pressure buffer and allows workers to pull at a sustainable rate.
Rate shaping by tenant/device identity
Different fleets behave differently. A small number of noisy devices should not destabilize a larger healthy population. Shape traffic by tenant, device cohort, or region when needed.
The goal is not to slow everything down. It is to keep the pipeline inside a controllable operating envelope. Under spike conditions, predictable slowness is much better than oscillation.
This is where many teams over-index on average throughput. The real target should be recovery stability: how gracefully the system drains backlog after reconnect without driving error storms or backend hotspots. Sustainable ingest is usually more valuable than peak ingest.
The Backpressure Contract Across the Ingest Path
The contract spans the whole path: API admission, queue smoothing, worker pacing, storage-safe writes, and search-aware indexing.
Devices
│
▼
Ingest API → partial acceptance + watermark + Retry-After
│ (concurrency caps)
▼
Queue / buffer → smoothing
│
▼
Worker pool → paced writes
│
▼
DynamoDB (idempotent writes) + OpenSearch (bounded bulk indexing)
Idempotency is the line between safe retries and destructive retries
Backpressure alone is not enough if every retry creates duplicate work.
In reconnect-heavy systems, idempotency is not optional plumbing. It is the mechanism that converts retries from a risk into a recovery tool. Without it, every transient failure inflates write volume. With it, retries can be aggressive enough to recover but harmless enough not to amplify storage and indexing work.
Strict idempotency usually requires a stable event identity that survives retransmission. That identity should be derived from immutable event attributes—device ID plus monotonic sequence number, for example—not generated per request. If the same event appears five times, the system should recognize it as the same fact, not five facts.
The contract needs to hold through multiple layers:
- API layer: detect duplicate submissions quickly
- queue layer: avoid enqueuing duplicate work items
- storage layer: upsert or conditional-write by stable key
- indexing layer: treat repeats as no-op or cheap overwrite, not full re-ingest
This is especially important for search. OpenSearch often becomes the hidden multiplier in replay storms because duplicated writes do more than consume indexing throughput. They trigger segment churn, refresh pressure, merge pressure, and localized shard heat. Weak deduplication at the ingest layer becomes index thrash later.
Good idempotency design also improves observability. Once duplicate detection is real, teams can measure retry amplification precisely instead of inferring it indirectly from elevated traffic.
At Hoomanely, the value of this pattern is not theoretical. Device-originated systems often replay for legitimate reasons: reconnects, local uncertainty, and defensive resend logic. The platform benefits when those replays are made structurally safe instead of being treated as exceptional.
The client must become a cooperative participant
Many backend teams try to solve replay storms entirely server-side. That rarely works. If clients remain free to dump unlimited backlog concurrently and retry on short timers, the server is forced into permanent defense mode.
The client must participate in the backpressure contract.
Two mechanisms are especially effective:
1. Token-bucket sending for backlog drain
A reconnecting device should not flush everything immediately. It should spend from a local token bucket that limits burst size and steady-state send rate. This lets the client drain backlog gradually while still allowing some initial catch-up speed.
The bucket should be sized for the kind of device and connectivity pattern, not just peak optimism. Small controlled bursts plus steady drain almost always outperform “send everything now” once real backend costs are included.
2. Bounded exponential backoff
Retries should not be infinite, synchronized, or aggressively parallel. Use exponential backoff with jitter, bound the maximum retry rate, and honor server-provided Retry-After when present. The client should also reduce concurrency when repeated pressure signals are observed.
This is the difference between a client that reacts emotionally to failure and one that reacts contractually.
A simple but effective rule is: never let retry traffic exceed fresh traffic for long. When retries dominate, the system is spending more energy repeating the past than making forward progress.
Protecting DynamoDB from synchronized write spikes
DynamoDB is usually not the first component teams blame, but it often reveals the true shape of reconnect storms. If keys are poorly distributed, a reconnect wave can push a narrow slice of partitions disproportionately hard.
Three defenses matter most here.
Partition-key design that avoids concentration
Keys should spread high-frequency writes. Device-only keys often become too concentrated if a small cohort reconnects simultaneously. Time bucketing, tenant-aware distribution, or deliberate write sharding may be needed depending on access patterns.
Burst smoothing before persistence
Even well-designed keys suffer when thousands of writes arrive in lockstep. Queue smoothing and worker pacing reduce synchronized pressure and let adaptive capacity work with you instead of after the fact.
Write paths that make duplicates cheap
If duplicate retries repeatedly hit the same items, storage cost and conditional contention rise quickly. Stable identities plus idempotent writes reduce this dramatically.
The important mindset is that backend throttling should be the last line of defense, not the main control plane. Once DynamoDB is visibly hot, earlier stages have already failed to coordinate.
Protecting OpenSearch from bulk-index collapse
OpenSearch tends to fail differently. It may not reject immediately; instead it degrades through indexing latency, shard imbalance, refresh pressure, and merge overhead. In reconnect storms, this often looks like the API “mostly works” while search freshness and indexing stability quietly erode.
To keep indexing healthy:
Use bulk indexing with bounded batch sizes
Oversized bulk requests increase tail latency and recovery pain. Batches should be large enough for efficiency, small enough for predictable retry behavior.
Separate storage acceptance from indexing urgency
Not every accepted write must become an immediate search document. Under pressure, it is better to preserve the source of truth first and let indexing lag temporarily than to overload both layers together.
Apply backpressure-aware fallbacks
If indexing pressure rises beyond threshold, reduce indexing concurrency, widen refresh intervals where acceptable, or temporarily degrade non-critical search updates. This is effectively a circuit-breaker posture for search freshness.
The key is to decide intentionally what can lag. Most systems are better served by slightly delayed search than by unstable ingest.
What Stable Reconnect Looks Like
A healthy reconnect combines token-bucket drain, server watermarking, queue smoothing, and bounded indexing under pressure:
t0 Device reconnects with local backlog [601..750]
t1 Token-bucket drain begins (controlled burst, not a flood)
t2 Server accepts [601..690] → watermark = 690, Retry-After = 8s
t3 Client resumes from 691 (duplicates safely ignored)
t4 Queue smooths writes; search lag tolerated, source of truth stable
Measure the contract, not just the errors
A system can have low 5xx rates and still be unhealthy if it is recovering inefficiently. The backpressure contract should be validated with metrics that reflect coordination, not only availability.
The most useful ones are:
- retry amplification factor: total ingest attempts ÷ original events
- 429/5xx spike rate during reconnect windows
- p95 ingest completion latency for buffered backlog
- queue depth and drain time
- duplicate suppression rate
- DynamoDB hotspot incidence
- OpenSearch indexing lag and shard pressure
These metrics make the trade-offs visible. For example, a slightly longer drain time may be completely acceptable if retry amplification drops sharply and backend hotspots disappear. That is often a sign of a healthier system, not a slower one.
A mature platform should also test this contract intentionally. Reconnect storms, replay overlaps, partial backend saturation, and retry loops should be simulated before production traffic does it for you. The goal is not only to survive failure, but to ensure the system recovers in a controlled shape.
Why this matters beyond infrastructure
Backpressure contracts sound operational, but they are product architecture in disguise.
For device-backed experiences, reconnects are normal. So are offline gaps. Users do not care whether a burst came from backlog flush, replay logic, or shard imbalance. They experience the outcome: delayed insights, duplicated events, stale search, battery-heavy retry loops, and systems that feel unreliable exactly when they should be recovering.
That is why this topic matters to Hoomanely as well. Hoomanely’s broader mission is to build dependable, intelligent systems around pet care and connected experiences. In that kind of environment, stable ingest is not a backend nicety. It is the foundation that allows device data, event pipelines, and downstream intelligence to remain trustworthy under real-world connectivity conditions. A strong backpressure contract directly strengthens that trust.
Key takeaways
Replay storms are rarely caused by one bad retry. They emerge when backlog flush, replay overlap, ambiguous failures, weak idempotency, and backend sensitivity reinforce one another.
The solution is to replace reactive throttling with an explicit end-to-end contract:
- partial acceptance instead of binary failure
- watermarks instead of ambiguous progress
- Retry-After instead of guesswork
- admission control before backend distress
- idempotency that makes retries safe
- client token buckets and bounded backoff
- storage and search layers protected by shaping, batching, and fallback modes
When those pieces align, reconnect spikes stop behaving like incidents and start behaving like load that the system already knows how to absorb.
That is the real value of backpressure contracts. They do not eliminate bursts. They make bursts boring.
Before and After: Throttling vs a Coordinated Contract
The same reconnect, handled two ways: reactive throttling on the left, a coordinated contract on the right.
Reactive throttling → Coordinated backpressure
Binary 429 / 5xx rejects → Partial acceptance + watermark
Unbounded client retries → Token bucket + bounded backoff
Duplicate writes amplify → Idempotent, deduplicated writes
Hot partitions, shard churn → Smoothed, batched, search-aware
Reconnect = incident → Reconnect = absorbable load