Designing Hardware That Handles Unclean Power Removal

Every embedded engineer has experienced it.
A prototype is running perfectly on the bench. Sensors are streaming data, processors are executing complex algorithms, peripherals are synchronized, and logs indicate everything is healthy. Then someone accidentally unplugs the power cable.
The board shuts down instantly.
Power is restored a few seconds later—and suddenly the system refuses to boot, configuration data is corrupted, flash memory contains invalid values, or one peripheral remains stuck until a manual reset.
The problem wasn't the firmware.
It wasn't even the hardware failure.
It was the assumption that power would disappear gracefully.
In reality, embedded systems deployed in homes, factories, vehicles, and outdoor environments rarely experience perfect shutdown conditions. Users disconnect cables, batteries become depleted, connectors momentarily lose contact, power adapters sag under heavy loads, and brown-outs occur during switching events. Hardware must therefore be designed to survive unexpected power removal without entering undefined states.
At Hoomanely, designing intelligent products such as EverBowl reinforced a simple engineering principle: a system should never depend on software to survive the moment software stops running.
The board itself should naturally recover from abrupt power removal and return to a known-good state when power is restored.
That philosophy starts at schematic capture and continues through PCB layout, power architecture, storage selection, and reset strategy.
Why Sudden Power Loss Is Harder Than It Looks
Many engineers imagine power removal as an ideal vertical drop from 5 V to 0 V.
Real hardware behaves very differently.
Bulk capacitors discharge at different rates, regulators collapse independently, batteries disconnect gradually, USB cables bounce during unplugging, and peripheral rails decay asynchronously. One IC may still operate while another has already powered down.
The result is a period where digital logic exists in an undefined region.
During this interval:
- GPIO outputs may float unpredictably.
- Communication buses may become partially active.
- EEPROM or flash writes may stop halfway.
- Reset circuits may release too early.
- Power sequencing assumptions collapse.
- Internal state machines can lock into invalid states.
Ironically, the most dangerous moment for many embedded systems is not startup—it is shutdown.
Designers who understand this reality build products that survive years in the field. Those who ignore it often discover intermittent failures that are nearly impossible to reproduce in the laboratory.
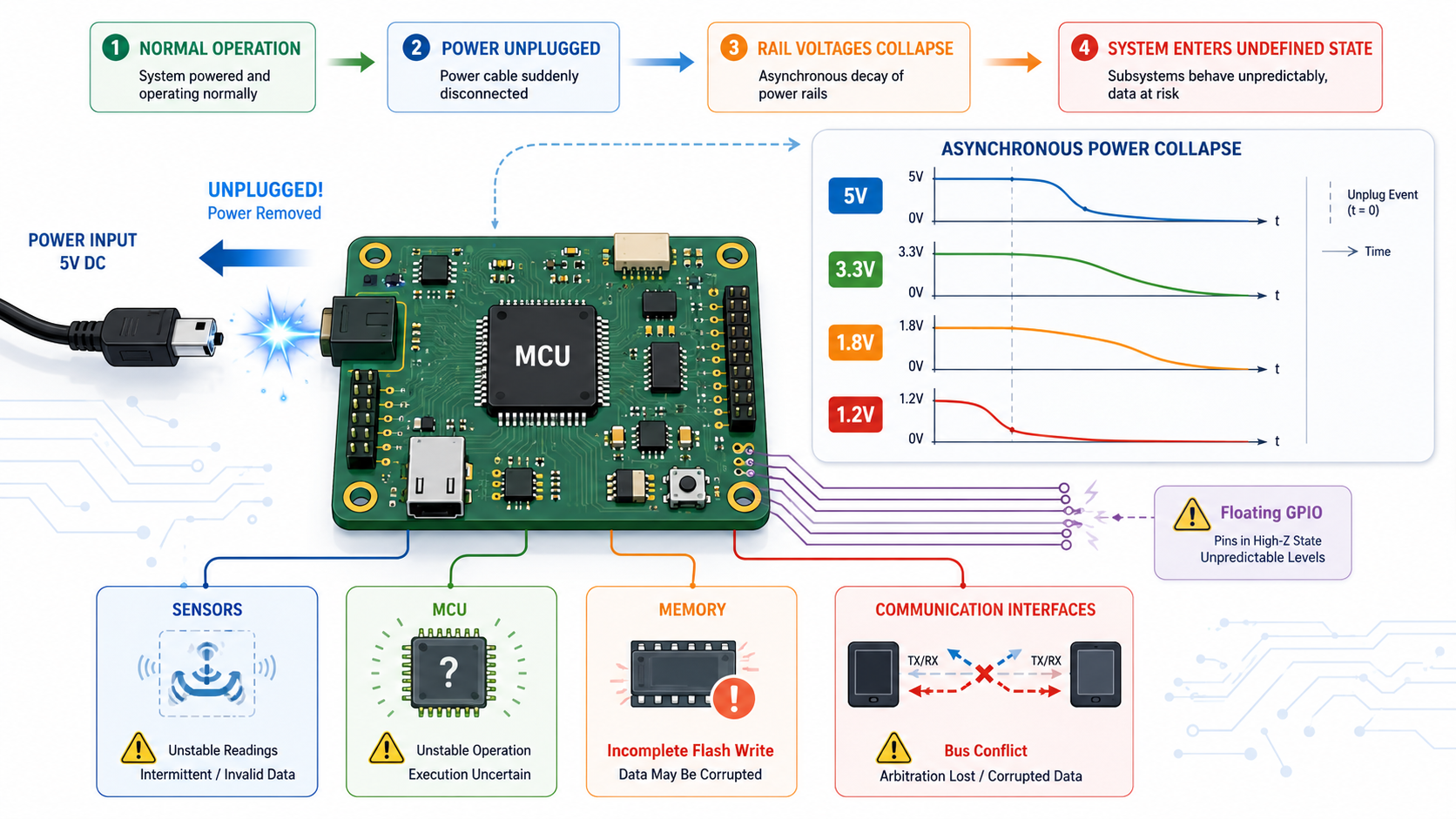
The Importance of Controlled Power Rail Collapse
A robust design treats power-down almost like reverse power sequencing.
Instead of allowing every rail to decay randomly, designers attempt to maintain a predictable hierarchy.
The processor should lose execution before peripherals begin generating interrupts.
Sensors should stop transmitting before communication buses lose pull-ups.
External memory should become inaccessible before its supply voltage enters undefined regions.
Power supervisors, reset ICs, enable pins, and discharge circuits all contribute to making shutdown deterministic instead of chaotic.
In the EverBowl architecture, multiple regulated domains support imaging sensors, microcontrollers, wireless communication modules, and analogue measurement circuits.
Although these domains operate independently during normal operation, they are designed so that no subsystem remains partially alive while another critical controller has already stopped functioning. That coordination significantly reduces unpredictable restart behaviour after abrupt power interruptions.
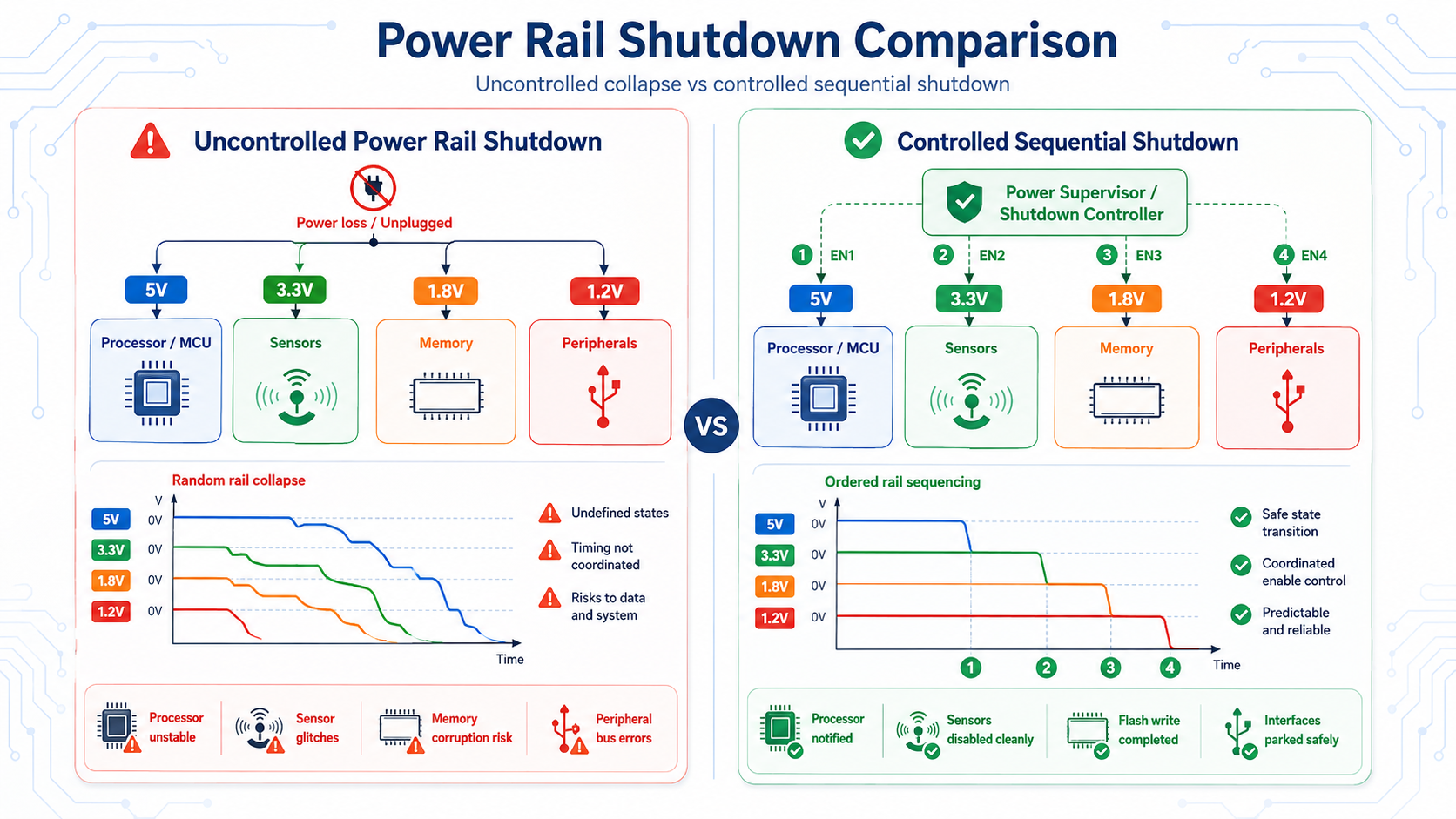
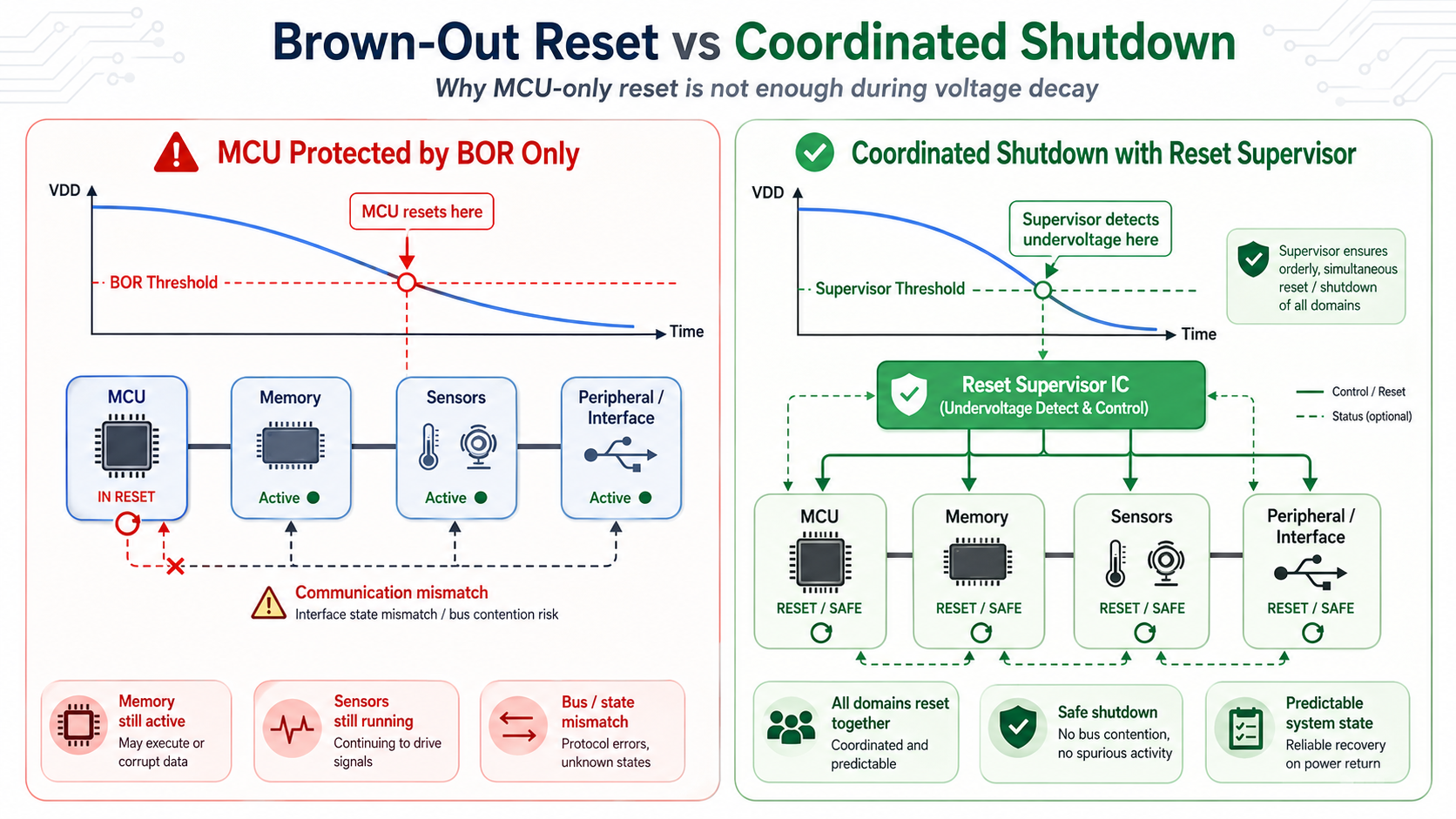
Brown-Out Detection Is Only Half the Solution
Most modern microcontrollers include Brown-Out Reset (BOR) circuitry.
When supply voltage drops below a threshold, the processor resets automatically.
While useful, BOR alone cannot solve every shutdown problem.
Peripheral ICs often have different operating voltage limits.
One device may continue transmitting over SPI while another has already stopped responding.
An external sensor may drive logic high into an MCU whose protection diodes are now conducting.
The CPU may reset correctly while external memory receives corrupted commands.
Designers therefore combine BOR with hardware supervisors, voltage monitors, and enable logic that disable peripherals before voltage reaches unsafe regions.
Rather than asking "Will the MCU reset?", experienced engineers ask:
"Will every device in the system stop behaving predictably before entering undefined voltage levels?"
That distinction separates robust products from fragile prototypes.
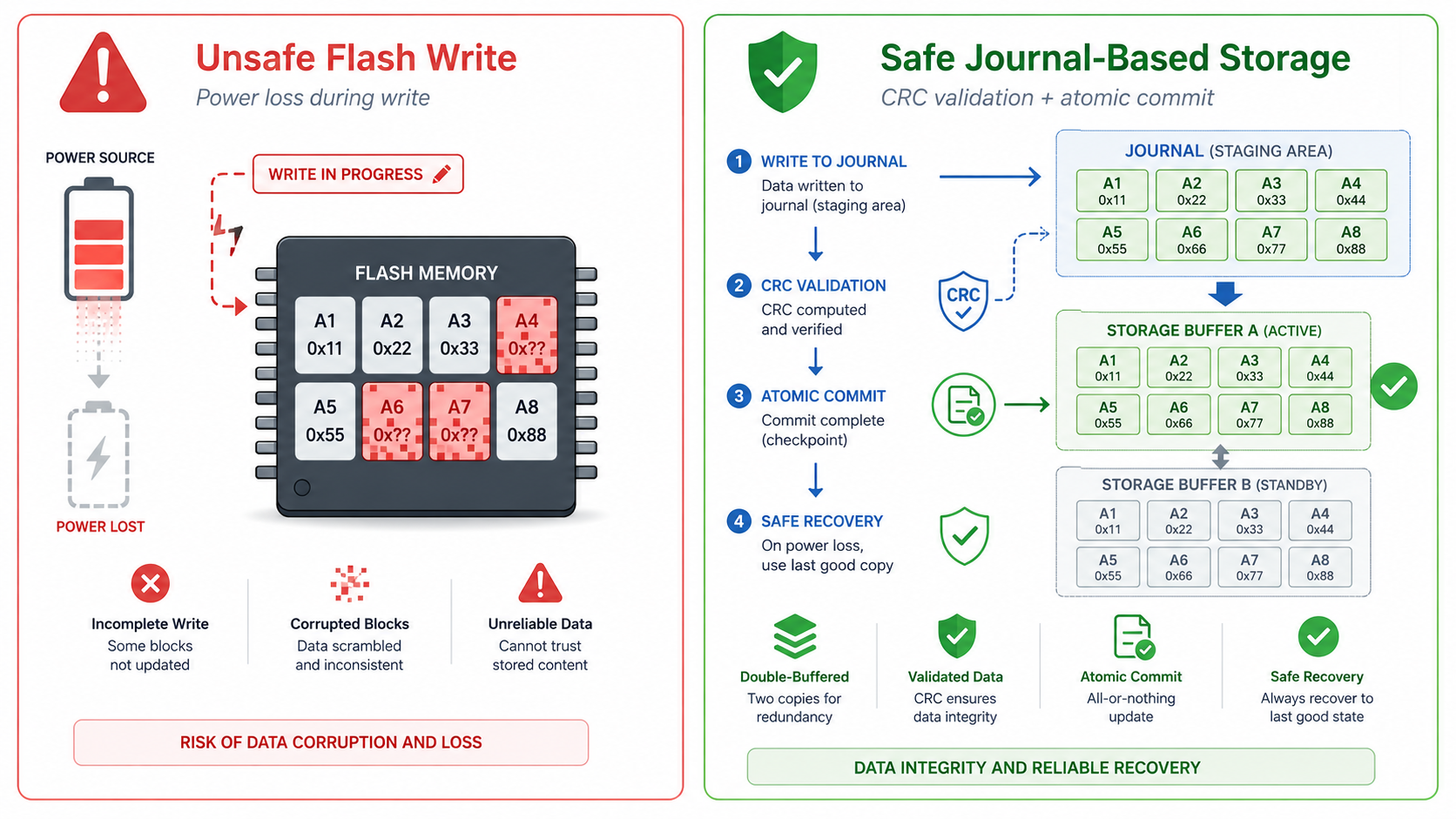
Avoid Writing Critical Data During Unstable Power
Flash memory and EEPROM corruption frequently occur during power loss.
Configuration parameters, calibration constants, counters, and logs may be updated just as voltage collapses.
A partially completed write operation can invalidate an entire storage sector.
Professional embedded systems therefore avoid continuous writes.
Instead, they employ strategies such as:
- Double-buffered configuration storage
- Version-tagged records
- CRC verification
- Journal-style logging
- Atomic commit structures
- Deferred writes after stable operation
The hardware contributes by ensuring adequate power stability during write cycles or preventing writes altogether during brown-out conditions.
Some systems even reserve capacitor energy solely to complete pending storage operations before shutdown.
Although this adds slight cost, it dramatically increases long-term reliability.
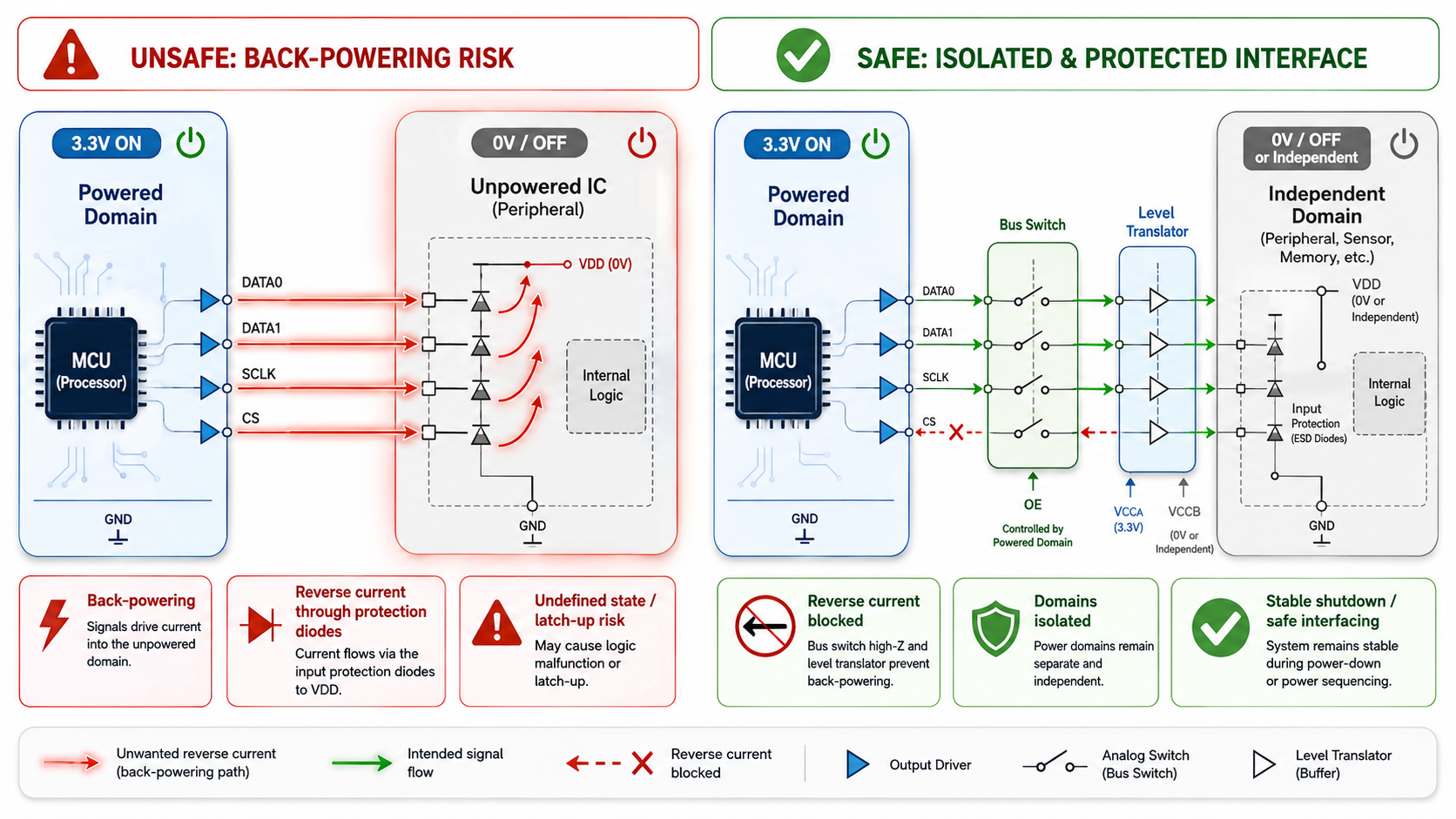
Prevent Back-Powering Between Power Domains
One overlooked source of shutdown failures is back-powering.
Imagine one subsystem loses power while another remains active.
A communication line connected between them may source current through internal ESD diodes, unintentionally powering sections of an unpowered IC.
The device now operates at an undefined voltage.
Current consumption increases.
Logic states become unpredictable.
Subsequent startup behavior becomes inconsistent.
Preventing back-powering requires thoughtful interface design.
Engineers commonly use:
- Series resistors
- Bus switches
- Level translators with isolation
- Power-domain-aware buffers
- Controlled enable signals
- High-impedance default states
These measures ensure each subsystem truly powers down instead of remaining partially energized through signal connections.
The result is cleaner shutdown behaviour and much more repeatable boot performance.
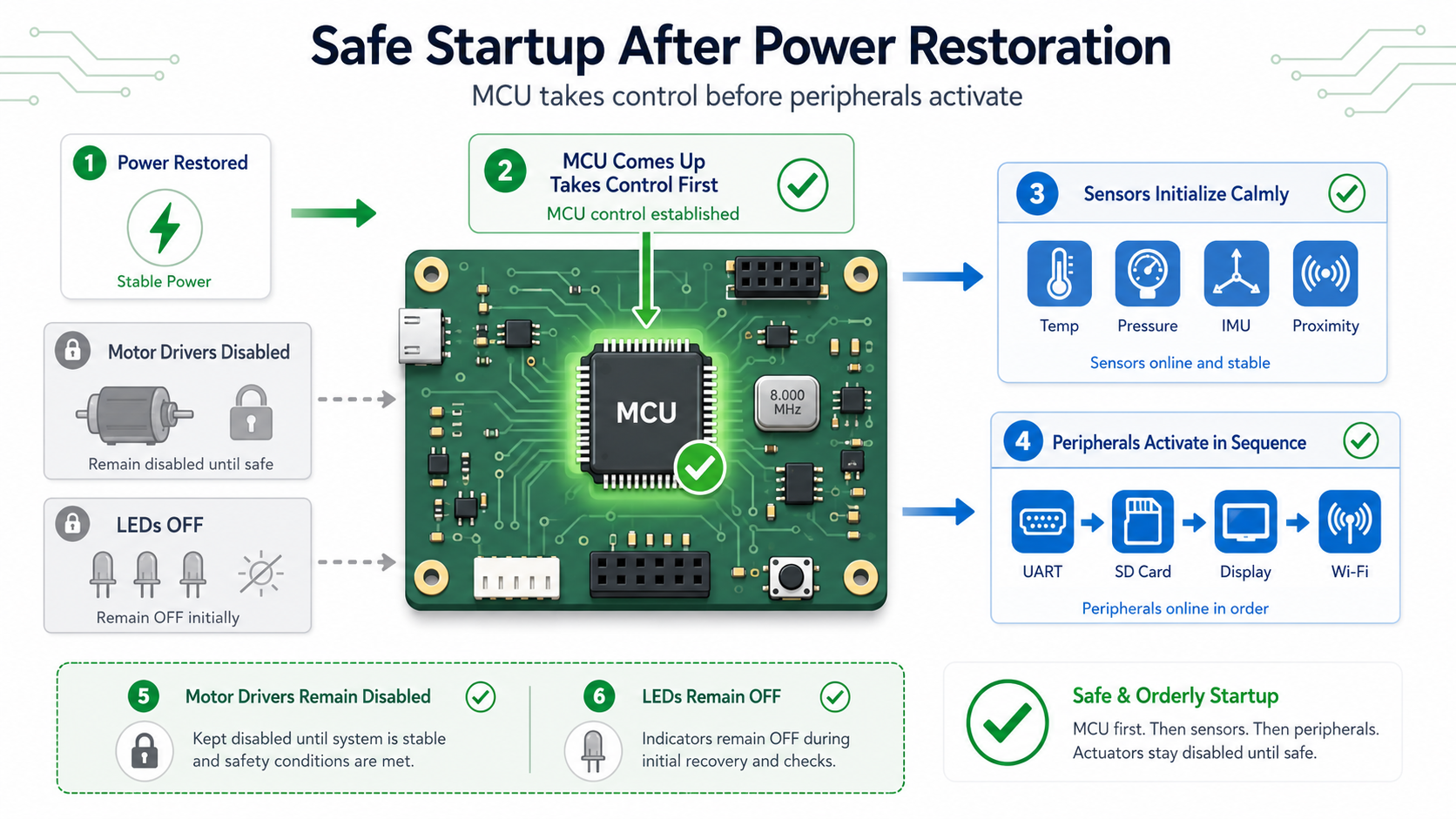
Hardware Should Default to Safe States Automatically
One of the most valuable design philosophies is allowing hardware to recover naturally without software intervention.
Suppose power disappears while an actuator is enabled.
When power returns, should that actuator immediately restart?
Probably not.
The board should ensure all outputs begin from known-safe states.
Pull-down resistors, pull-up resistors, default enable polarity, reset supervisors, and transistor biasing networks should collectively guarantee predictable startup regardless of how power was removed.
This principle extends across the entire design.
Motor drivers should remain disabled.
LED drivers should stay off.
Wireless transmitters should not activate unexpectedly.
Sensor excitation circuits should initialise cleanly.
The processor should regain complete control before external devices become active.
Designing for safe defaults transforms unexpected shutdown from a dangerous event into an ordinary operational condition.
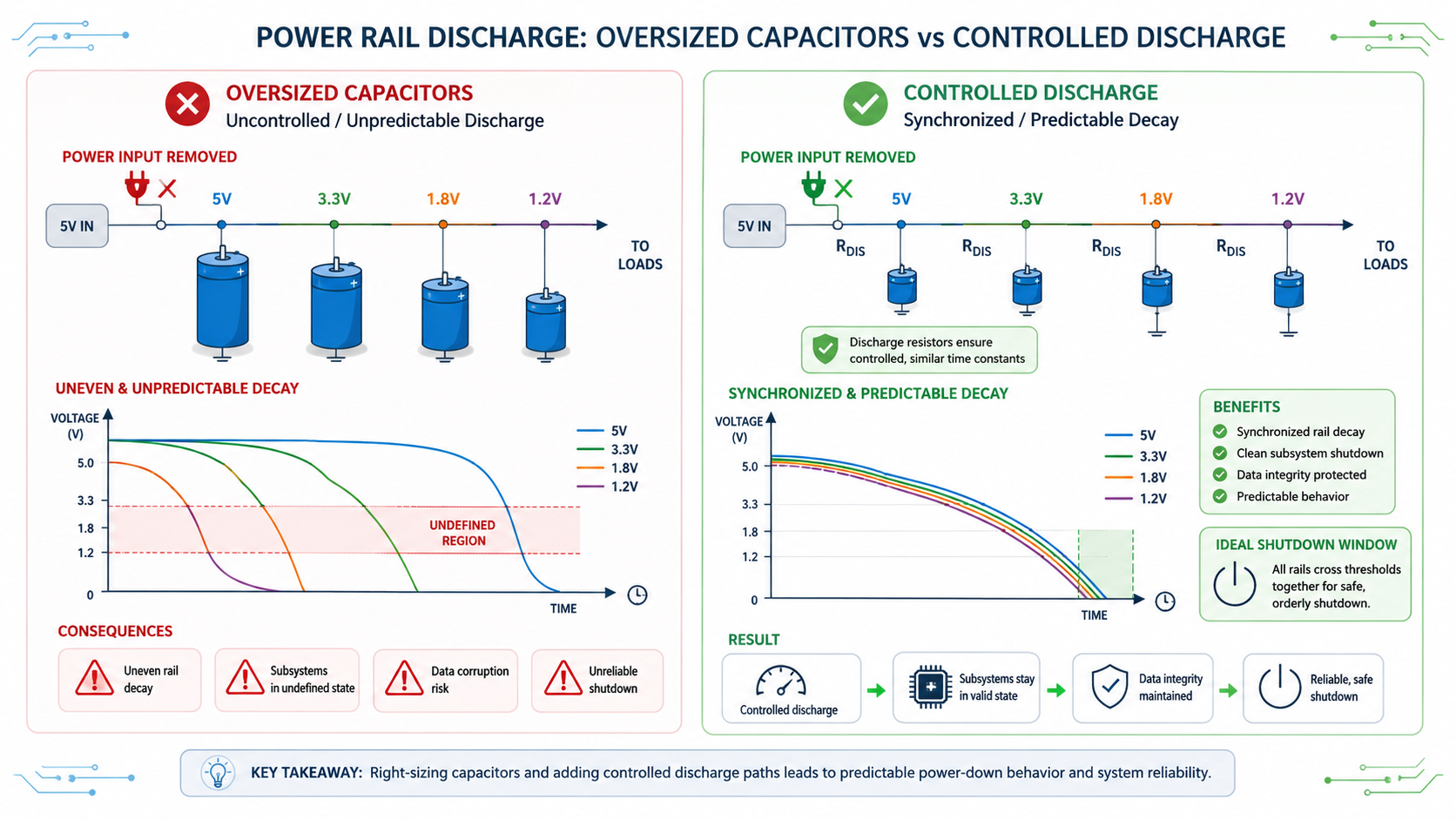
Why Capacitors Can Be Both Friends and Enemies
Engineers instinctively add larger capacitors for stability.
Yet excessive capacitance can complicate shutdown.
Large energy reservoirs extend rail decay times.
One regulator may remain active significantly longer than another.
Reset timing assumptions change.
Mixed-voltage interfaces remain energised unexpectedly.
Instead of blindly increasing capacitance, designers analyse discharge profiles.
Sometimes adding controlled discharge resistors or active load switches improves reliability more than increasing capacitor size.
The objective is not maximising stored energy.
It is creating predictable energy behaviour.
A rail that decays consistently over 15 milliseconds is often preferable to one that unpredictably collapses anywhere between 5 and 80 milliseconds.
Predictability simplifies every other subsystem.
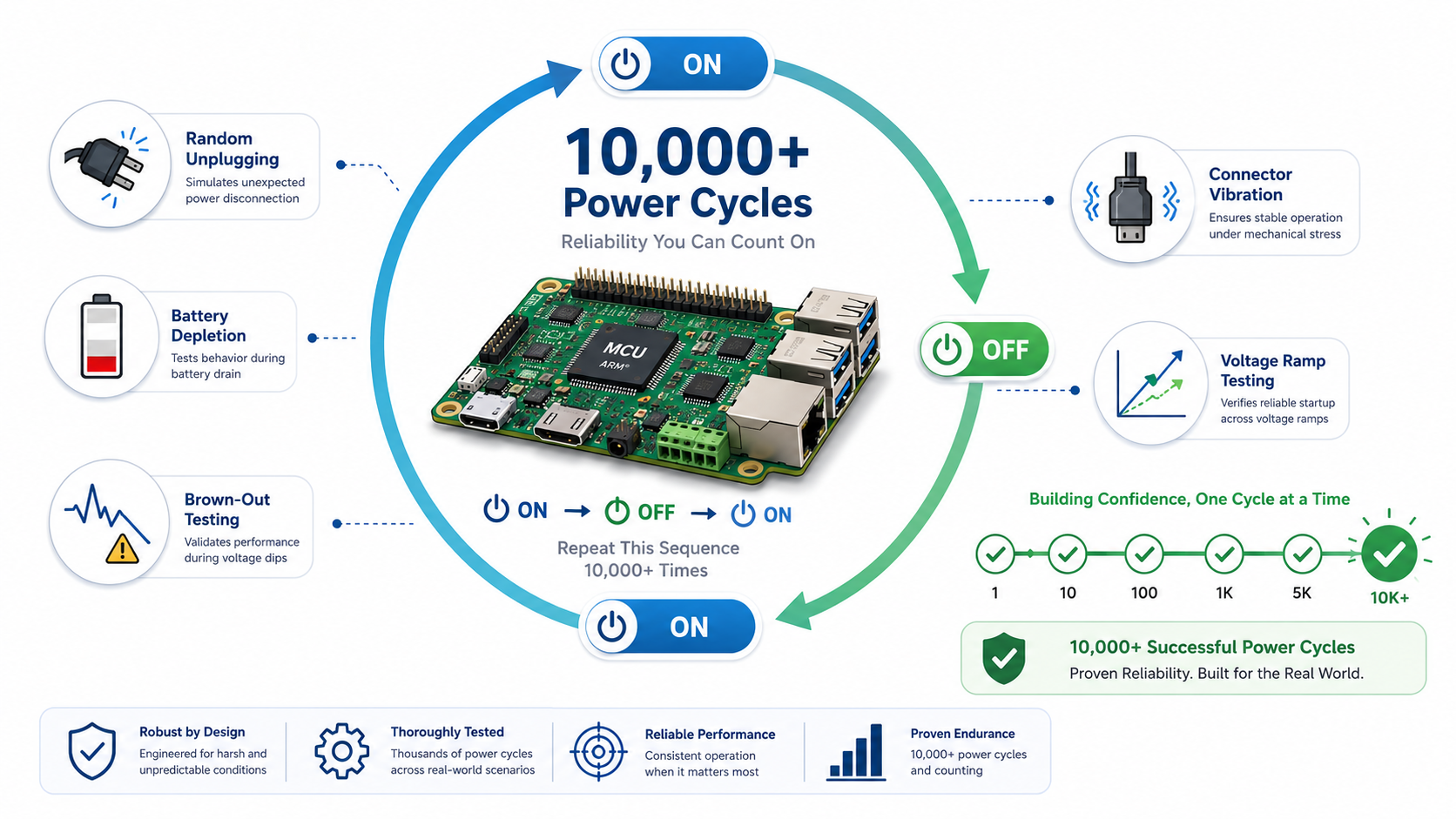
Design for Thousands of Power Cycles, Not Just One
During development, engineers may reboot a board dozens of times.
In production, that number becomes thousands.
Consumer devices experience accidental unplugging.
Industrial controllers endure maintenance shutdowns.
Battery-operated products encounter repeated depletion cycles.
Every power interruption becomes another reliability test.
Design validation should therefore include aggressive power-cycle testing.
Successful qualification involves:
- Random unplug intervals
- Brown-out sweeps
- Rapid reconnect events
- Partial connector insertion
- Voltage ramp testing
- High-load shutdown conditions
- Simultaneous peripheral activity during power removal
Systems that survive these tests generally demonstrate exceptional field reliability because they have already experienced conditions harsher than normal customer use.
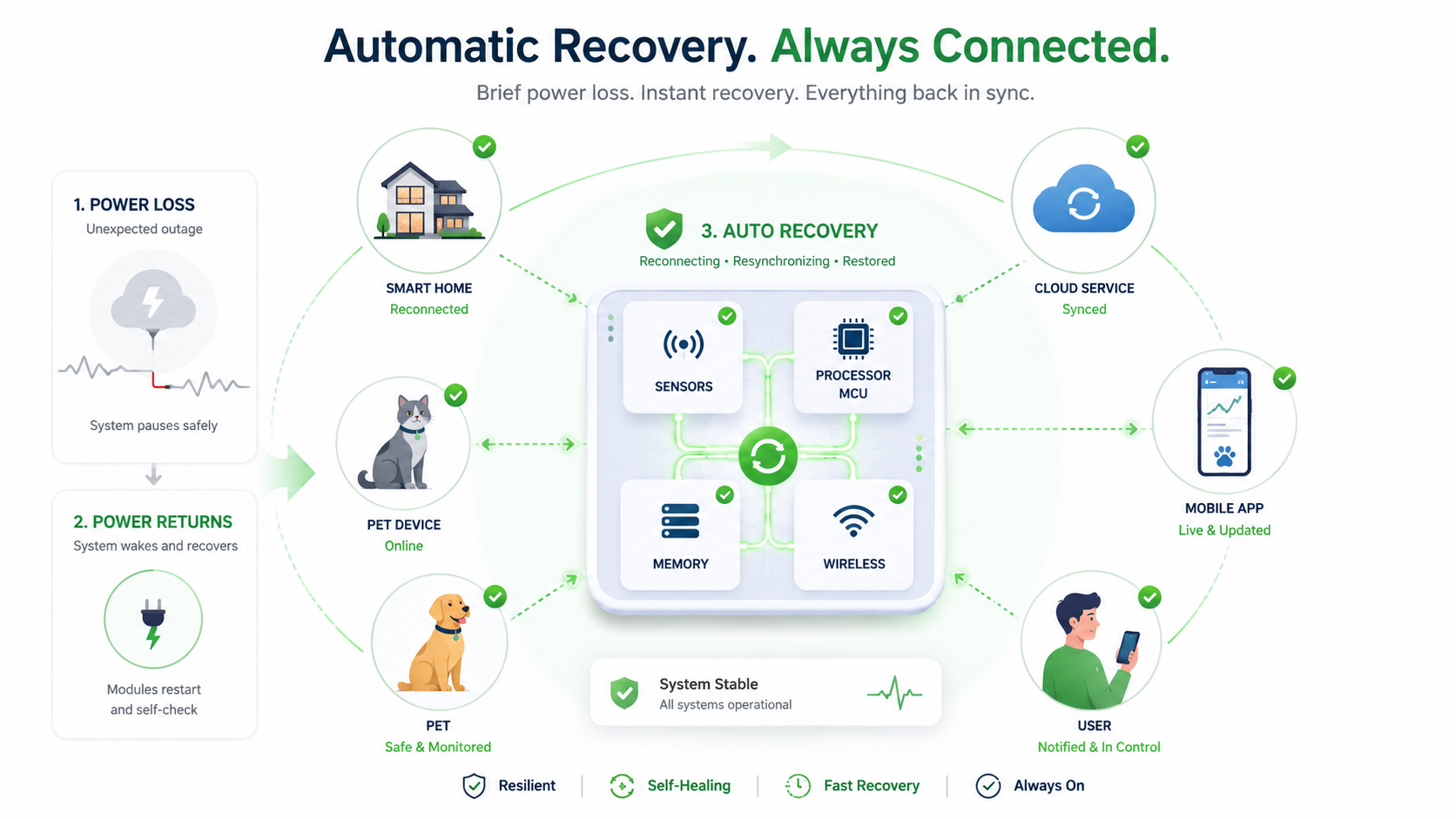
A Practical Perspective from Hoomanely
Developing connected sensing platforms like EverBowl highlighted an important lesson: reliability is defined not by how a device behaves under ideal laboratory conditions, but by how gracefully it handles imperfect real-world events.
Pets do not wait for orderly shutdown sequences.
Users do not always use certified power adapters.
Power cables loosen, outlets fluctuate, and homes experience brief interruptions.
Rather than relying entirely on software recovery routines, Hoomanely's engineering philosophy emphasises hardware architectures that naturally return to stable operation after unexpected events. That means carefully coordinating regulators, resets, power domains, storage strategies, and interface isolation so that every restart begins from a clean foundation rather than an uncertain state.
The most dependable products are often those whose recovery mechanisms remain invisible to the end user.
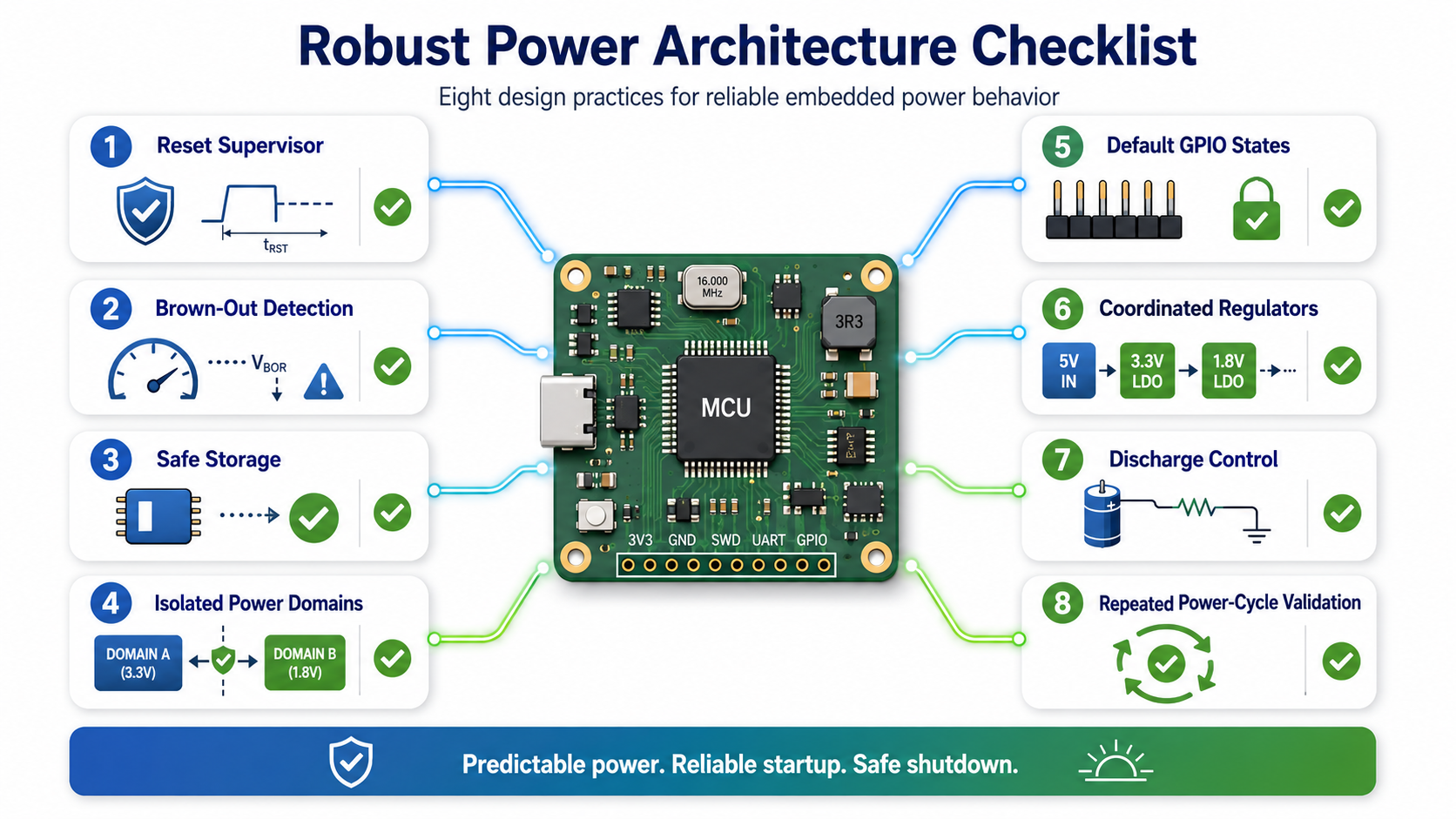
Best Practices for Handling Unclean Power Removal
Engineers designing resilient embedded hardware should keep several principles in mind:
- Design shutdown behaviour with the same care as startup sequencing.
- Use reset supervisors in addition to internal brown-out detection.
- Prevent writes to non-volatile memory during unstable voltage conditions.
- Eliminate back-power paths between independent supply domains.
- Ensure outputs default to safe states without firmware assistance.
- Coordinate regulator sequencing and discharge timing.
- Validate the design through repeated random power-cycle testing.
- Consider every unexpected unplug event as a normal operating condition.
These practices significantly reduce field failures and simplify long-term maintenance.
Conclusion
Unexpected power removal is inevitable.
Whether caused by user action, battery depletion, connector wear, or infrastructure instability, every embedded system will eventually experience an uncontrolled shutdown.
The difference between a fragile product and a dependable one lies in how it responds to that moment.
Reliable hardware is not defined by maximum processing speed or feature count. It is defined by its ability to recover from the unexpected without corruption, confusion, or manual intervention.
Designing boards that tolerate unclean power removal requires thoughtful architecture, disciplined power-domain management, safe default states, intelligent storage strategies, and predictable shutdown behavior.
At Hoomanely, this philosophy continues to shape every embedded platform we build. Because in real-world engineering, success is measured not only by how a system starts—but by how confidently it starts again after everything suddenly goes dark.