From Bark to Insight: On-Device Acoustic Event Detection

A pet's day has a soundtrack, and most of it is health data. The rhythmic crunch of kibble, a gulp of water, a bark at the doorbell, the wet cough that wasn't there last week — each is a signal a vet would want to know about. The problem is that a microphone hears everything: fans, footsteps, television, silence. Turning that raw stream into a short, trustworthy list of events — "ate for 90 seconds," "barked three times," "something unusual at 2 a.m." — is a real signal-processing and machine-learning problem, and it has to run at the edge without melting the battery or drowning the network. This post walks through how our devices listen: how they extract features, gate detections cleanly, flag the genuinely weird, and keep a heavy classifier from ever stalling the live audio path.
The Problem: Hearing Is Easy, Listening Is Hard
Capturing audio is the trivial part. The hard part is deciding what counts. A naive detector that fires the instant a score crosses a threshold produces a storm of fragmented, flickering events — one chewing session becomes forty "eat" blips because the score dances around the line.
A second trap is the open-ended nature of "interesting." We can train detectors for known sounds like eating and barking, but the most clinically valuable events are often the ones we didn't anticipate — a new wheeze, an odd whimper, a sound that simply doesn't match this pet's normal. You can't write a threshold for "abnormal."
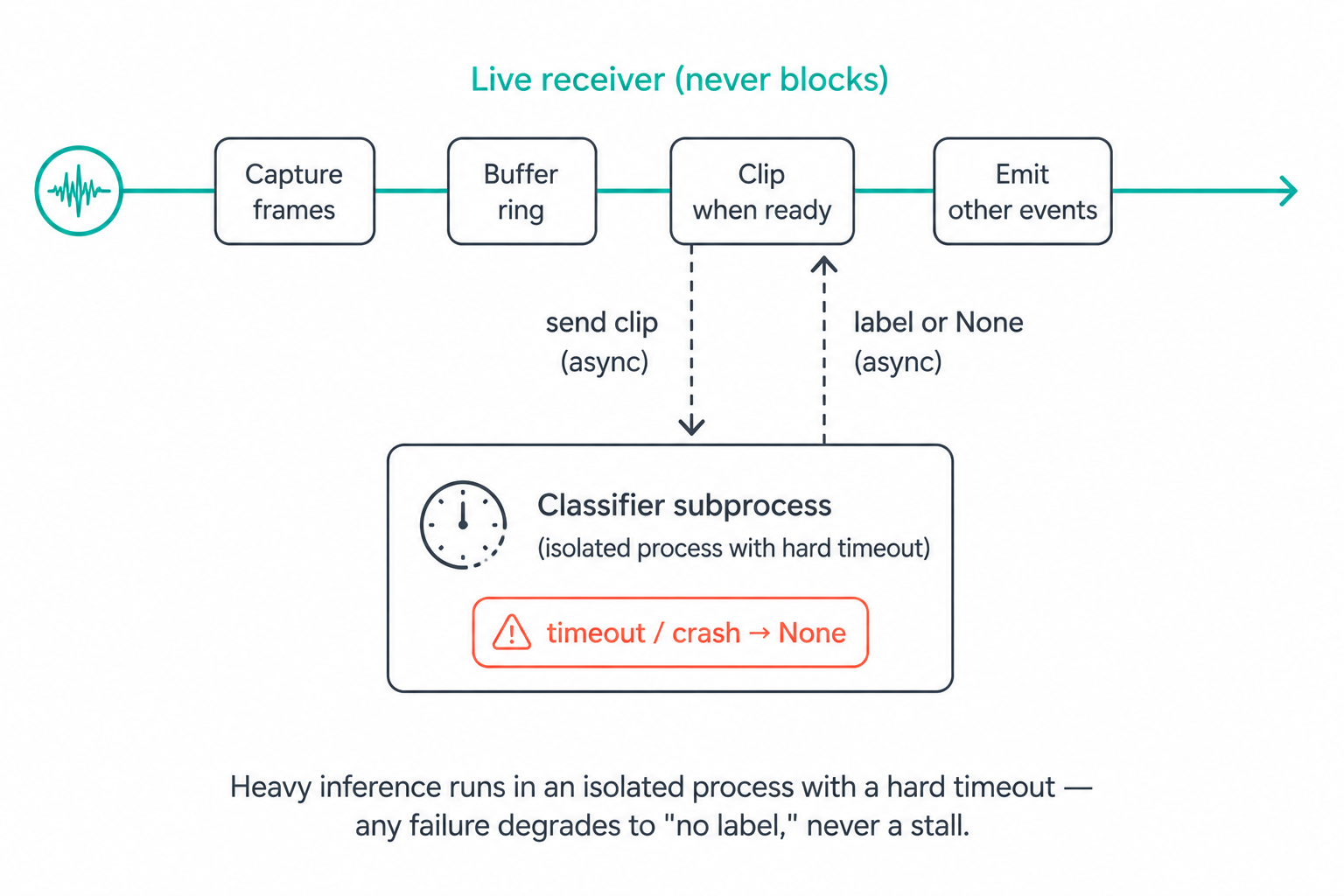
And a third constraint sits underneath everything: this runs on a small edge device that is also receiving live data. A deep audio model can take seconds and occasionally hang. If classification ever blocks the receiver, we don't just lose an event label — we lose the live stream. So the architecture has to treat heavy inference as something that can fail or time out without consequence.
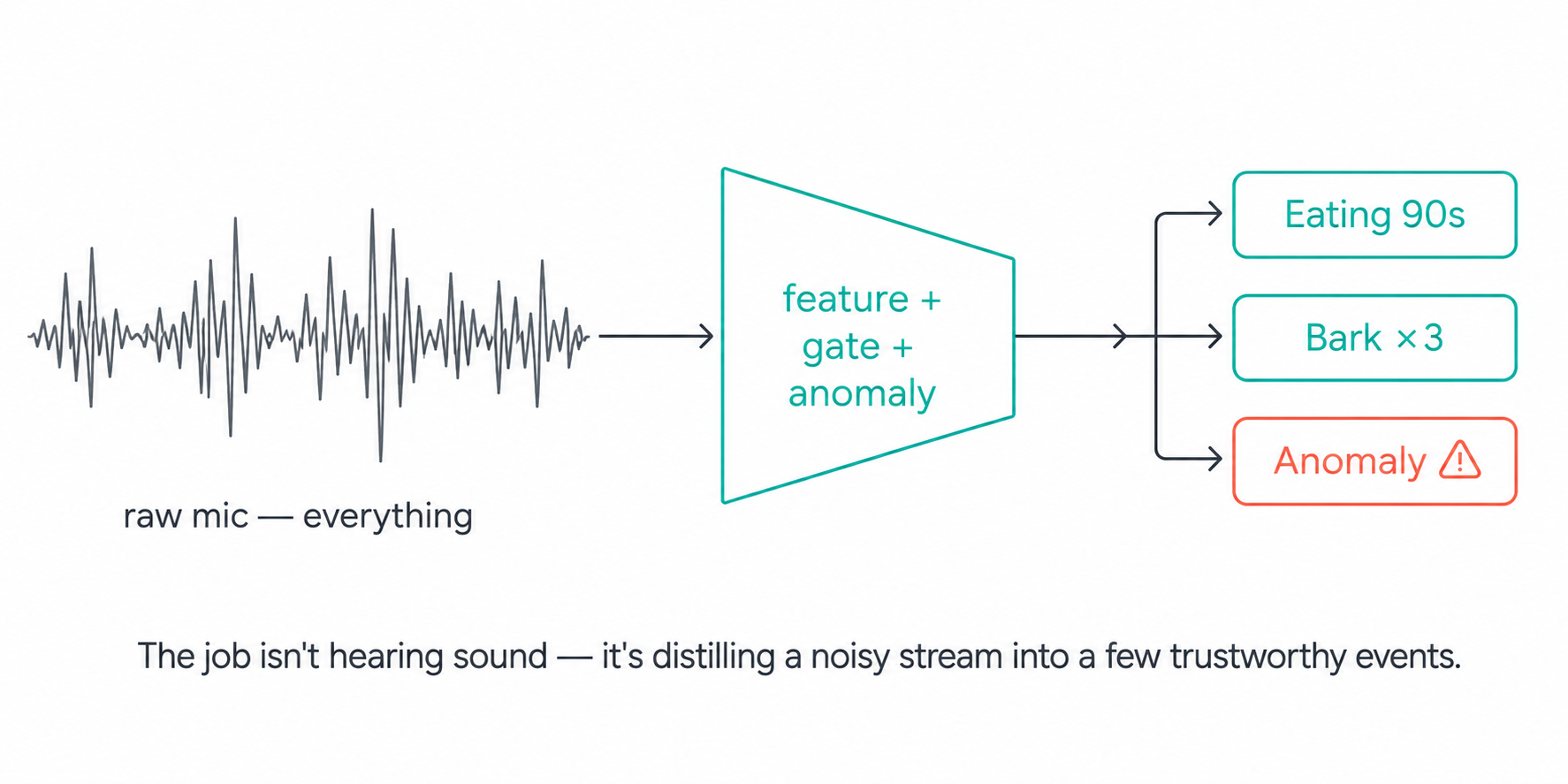
The Approach: Features, Gates, and a Model of "Normal"
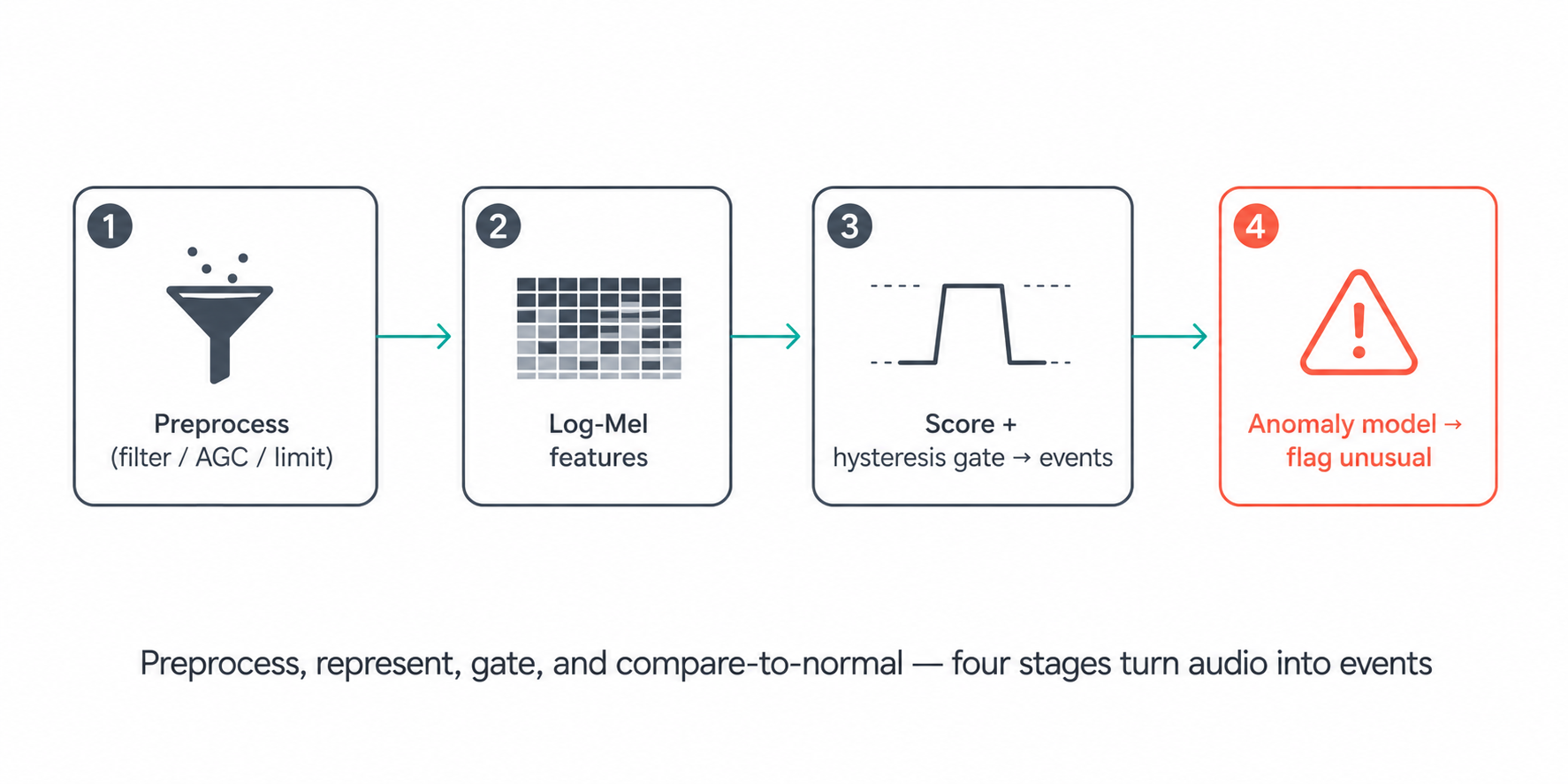
Our pipeline mirrors how a careful human would reason about sound, in four stages. First, preprocess — filter, level, and limit the raw audio so loud and quiet clips are comparable. Second, extract features — convert the waveform into a log-Mel spectrogram, the time-frequency representation that makes eating, barking, and ambient noise look distinct. Third, score and gate — turn features into detection scores and commit to events only when the evidence is stable. Fourth, flag anomalies — learn what this environment normally sounds like and surface anything that deviates.
The feature foundation is a log-Mel spectrogram: a power spectrogram mapped onto perceptually-spaced frequency bands and converted to decibels. It's the same front-end most modern audio models use, because it compresses raw audio into a compact image-like form where events have characteristic shapes:
613 mel_spec = librosa.feature.melspectrogram(
614 S=np.abs(stft)**2,
615 sr=config.sr,
616 n_fft=config.n_fft,
617 hop_length=hop_length,
618 win_length=win_length,
619 n_mels=config.n_mels,
620 fmin=config.fmin,
621 fmax=config.fmax
622 )
623 log_mel = librosa.power_to_db(mel_spec, ref=1.0)
From that representation we derive per-frame detection scores for eating and barking, plus a compact embedding used for anomaly detection. Everything downstream operates on these features, not the raw samples.
The Process: Committing to an Event Without Flickering
The cure for flickering detections is hysteresis — the same trick a thermostat uses. We require a high score to start an event, but only drop the event when the score falls below a lower threshold, and we discard anything too short to be real. Two thresholds plus a minimum duration turn a jittery score into clean start/stop boundaries:
781 if not in_event:
782 if score >= on_thresh:
783 in_event = True
784 event_start = t
785 max_score = score
786 else:
787 max_score = max(max_score, score)
788 if score < off_thresh:
789 event_length = t - event_start
790 if event_length >= min_frames:
791 events.append({
792 'start_frame': event_start,
793 'end_frame': t,
794 'max_score': max_score
795 })
796 in_event = False
The gap between on_thresh and off_thresh is what gives the detector its stability: once it commits to "the dog is eating," a brief dip in the score won't end the event, and a brief spike in noise won't start one. The min_frames check then throws away blips too short to be a genuine chew or bark.
Flagging the unexpected. For sounds we can't pre-define, we don't classify — we model normality and look for outliers. The device watches a warm-up period to learn what this environment usually sounds like, fits an Isolation Forest on those embeddings, then scores every later frame against that learned baseline:
882 warmup_data = embedding[:config.anomaly_warmup]
883 forest = IsolationForest(
884 contamination=config.anomaly_contamination,
885 random_state=42,
886 n_estimators=100
887 )
888 forest.fit(warmup_data)
889
890 # Compute scores for remaining frames
891 for t in range(config.anomaly_warmup, n_frames):
892 score = forest.decision_function(embedding[t:t+1])[0]
893 anomaly_scores[t] = score
This is what lets the system surface a sound it was never trained on — a new cough, an unusual whine — as "this doesn't match normal," using a dynamic threshold on the post-warm-up scores rather than a hand-tuned cutoff.
Keeping the Heavy Model Off the Critical Path
On the connected side, a richer classifier (a general audio-tagging neural network) labels clips with categories. But that model is comparatively heavy and occasionally slow, and it must never jeopardize the live receiver. So we run it as a separate OS process with a hard timeout, and treat every failure mode as "no label, move on":
103 try:
104 proc = subprocess.run(cmd, env=env, timeout=TIMEOUT_S,
105 stdout=subprocess.DEVNULL, stderr=subprocess.PIPE)
106 if proc.returncode != 0:
107 LOG.warning("classify: binary rc=%d cid=%s err=%s",
108 proc.returncode, cid,
109 proc.stderr.decode("utf-8", "replace")[-200:])
110 return None
111 with open(json_path) as f:
112 return json.load(f)
113 except subprocess.TimeoutExpired:
114 LOG.warning("classify: timeout after %.0fs cid=%s", TIMEOUT_S, cid)
115 return None
A crash, a non-zero exit, or a hang all collapse to the same safe outcome: return nothing, log it, keep the receiver alive. The classifier is an enhancement to the event stream, never a dependency of it — which is exactly the posture a heavy model deserves on an always-on device.
The Results
The combination produces an event stream that's both clean and open-ended. Hysteresis means an eating session is reported as one event with sensible boundaries, not a flurry of fragments. The dual-threshold-plus-duration logic rejects momentary noise. And the anomaly model gives the system a way to say "something here is unusual" without anyone having to anticipate every possible sound.
Just as important, it's robust by construction. The lightweight feature-and-gate path is cheap enough to run continuously, while the expensive neural classifier is quarantined behind a process boundary and a timeout, so the device's core job — capturing and forwarding audio — is never at the mercy of a slow model. Events and labels flow up to the cloud; raw audio doesn't have to.
Why It Matters at Hoomanely
Hoomanely is reinventing healthcare for pets — replacing reactive, imprecise care with continuous, clinical-grade monitoring that catches problems early. Our devices form a Physical Intelligence ecosystem: sensors fused at the edge, feeding the Biosense AI Engine that turns raw signals into personalized, preventive insights.
Sound is one of the richest behavioral and physiological windows we have into a pet. Changes in eating cadence can signal dental pain or nausea; shifts in vocalization can reflect anxiety or distress; and a new, anomalous sound at night might be the first sign of a respiratory issue. Detecting those events on the device — and flagging the ones that don't fit a pet's normal — is how the Biosense engine gets a timeline of behavior, not just a pile of audio files.
Our guiding principle is that every signal matters and every detail counts. Listening well — committing to real events, surfacing the unexpected, and never letting the smart part break the simple part — is how we turn a microphone into a genuine instrument of preventive care.
Key Takeaways
- Represent before you reason. A log-Mel spectrogram turns raw audio into a compact, event-distinct form that both detectors and models work from.
- Gate with hysteresis. Separate on/off thresholds plus a minimum duration convert a jittery score into clean, single events instead of a flicker of fragments.
- Model "normal" to catch the unknown. An Isolation Forest fit on a warm-up baseline flags anomalous sounds you never trained for — the clinically valuable surprises.
- Quarantine heavy inference. Run a slow neural classifier in a separate process with a hard timeout so a crash or hang degrades to "no label," never a stalled stream.
- Send events, not the firehose. Distilling audio into a few labeled events on-device saves bandwidth and protects privacy while preserving the health signal.
Author's Note
This acoustic pipeline runs across Hoomanely's physical-intelligence devices — the lightweight feature-and-gate detector on-device, and a general audio classifier wrapped safely behind a process boundary on the connected hub. It's the natural partner to motion sensing: where the inertial sensor captures that something happened, audio captures what it sounded like. Together they give the Biosense AI Engine a fuller, more honest picture of how a pet is really doing — one trustworthy event at a time.