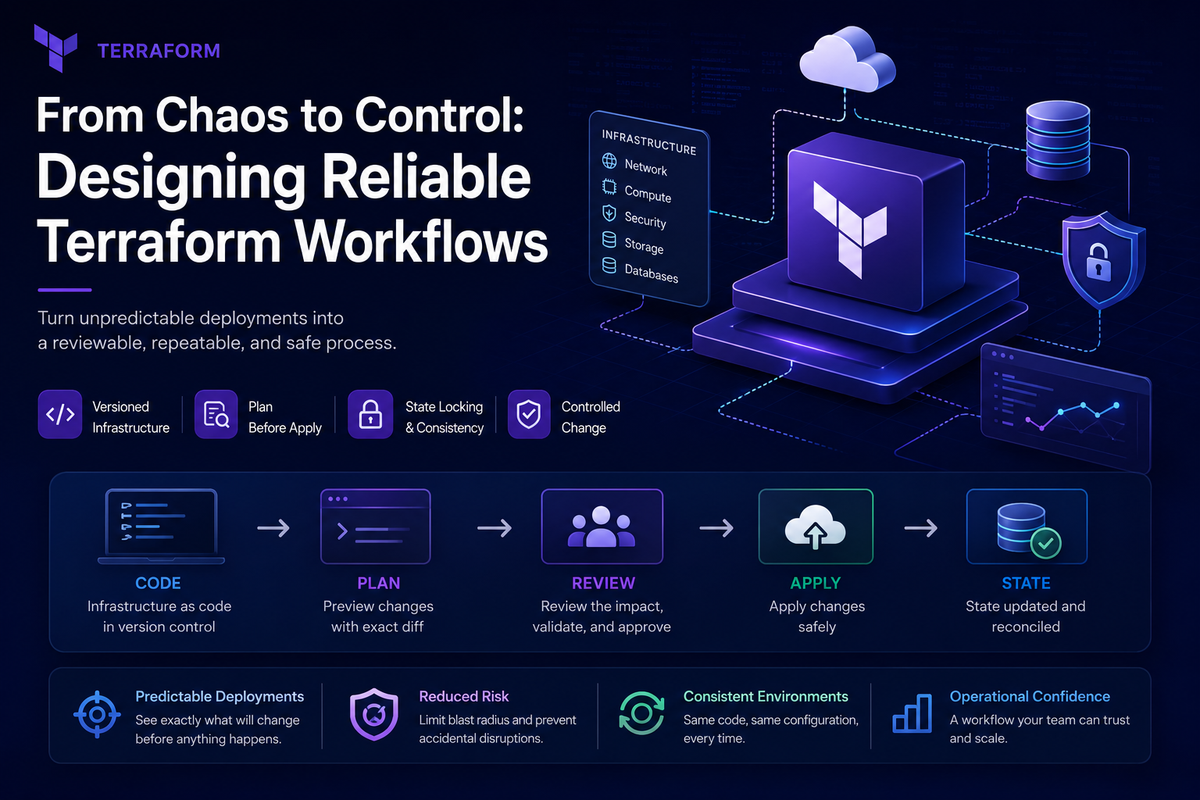
From Chaos to Control: Designing Reliable Terraform Workflows.
Most production incidents do not begin with faulty application code. They begin with infrastructure changes that nobody fully understood.
A security policy modified through a cloud console. A manual configuration update made during an urgent fix. An environment that slowly diverges from the documentation intended to describe it.
Individually, these changes appear harmless. Collectively, they create infrastructure that becomes increasingly difficult to reason about. Teams lose confidence in deployments, engineers become reluctant to make changes, and operational risk grows with every release.
This challenge is not unique to any organization or cloud provider. It is a natural consequence of scale.
Terraform is often described as an Infrastructure as Code tool, but its real value extends beyond resource provisioning. At its best, Terraform provides an architectural framework for managing change. It transforms infrastructure from an unpredictable collection of resources into a versioned, reviewable, and auditable system.
This article explores the architectural principles behind reliable Terraform workflows and how they help engineering teams move from deployment uncertainty to operational confidence.
When Infrastructure Becomes Difficult to Trust
Every growing engineering organization eventually encounters the same set of challenges.
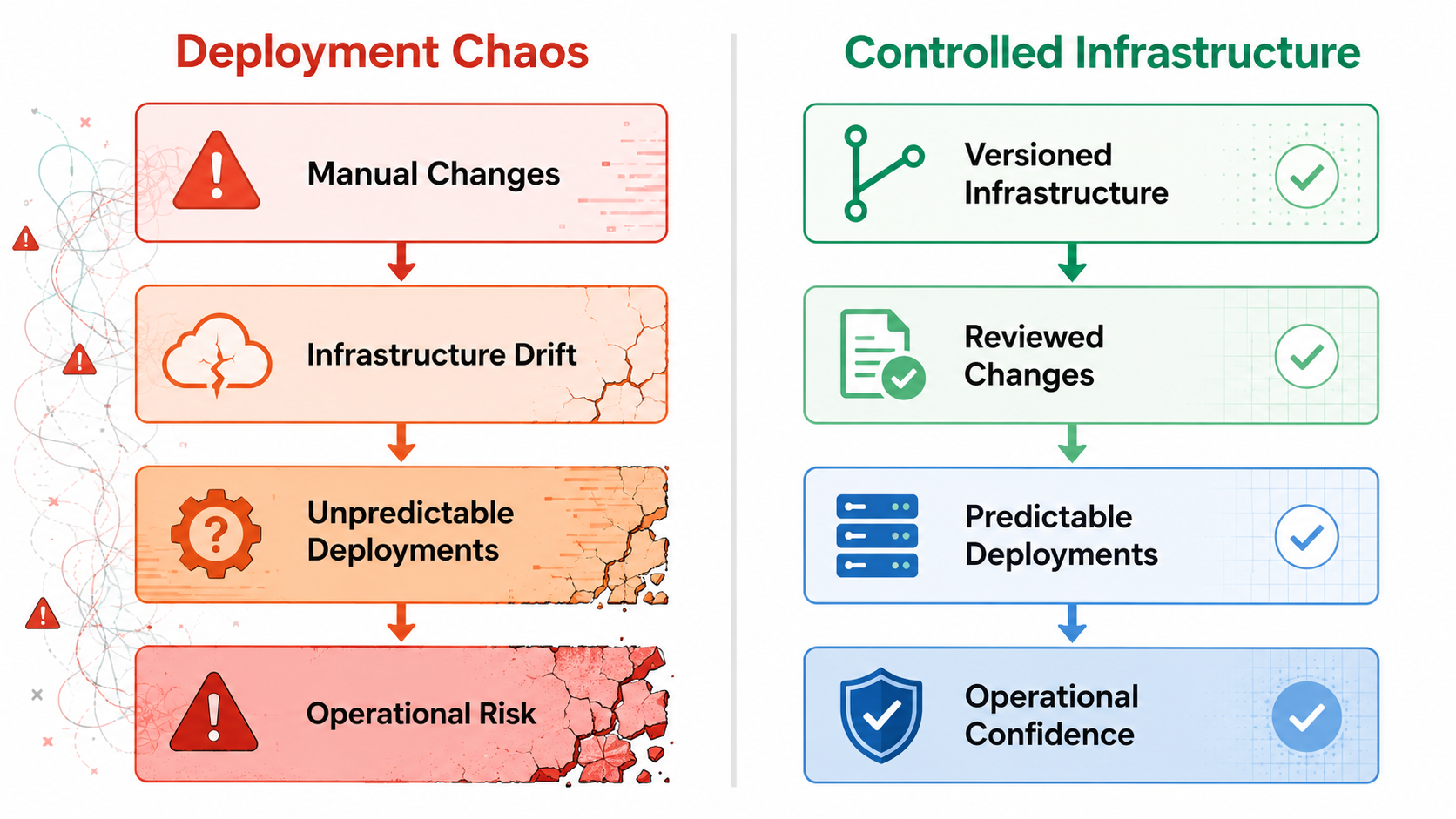
Infrastructure Drift
Infrastructure changes occur through multiple channels automation, manual interventions, emergency fixes, and platform updates.
Over time, the deployed environment begins to diverge from the documented or expected state.
The result is a simple but dangerous question:
What does production actually look like today?
When nobody can answer confidently, operational risk increases significantly.
Lack of Predictability
Without a reliable mechanism to preview changes, deployments become reactive rather than deliberate.
Engineers can describe what they intend to modify, but they cannot always predict the full impact of those changes across interconnected resources.
Expanding Blast Radius
Cloud environments are deeply interconnected.
A seemingly isolated modification can trigger cascading effects across networking, security, compute, storage, or identity systems.
The challenge is not making changes it is understanding their consequences.
Environment Inconsistency
Many teams rely on staging environments as a validation layer.
However, when staging and production evolve independently, successful testing loses much of its value.
A deployment process is only as trustworthy as the consistency of the environments it manages.
Figure 1 — Reliable infrastructure begins with controlling change.
The Architectural Shift: Managing Desired State
The fundamental innovation behind Terraform is not automation.
It is the concept of desired state management.
Rather than describing a sequence of actions, teams describe the infrastructure that should exist. Terraform then determines the difference between the current state and the desired state.
This seemingly simple approach changes how infrastructure evolves.
Instead of executing deployment instructions blindly, teams gain visibility into:
- What will change
- Why it will change
- Which resources are affected
- What the resulting state will look like
Infrastructure management becomes a process of reconciliation rather than execution.
That distinction is critical.
Reliable systems are not built by executing more commands. They are built by reducing uncertainty.
Architecture as a Collection of Reusable Building Blocks
As organizations grow, infrastructure complexity increases rapidly.
Networks expand. Services multiply. Security requirements become more sophisticated. Compliance obligations emerge.
Managing this complexity requires architectural boundaries.
Terraform modules provide those boundaries.
Rather than treating infrastructure as a single monolithic configuration, teams can organize resources into reusable domains such as:
- Networking
- Security
- Compute
- Storage
- Messaging
- Observability
Each module becomes a standardized building block that can be composed into larger systems.
This creates two significant advantages.
First, consistency improves because environments are assembled using the same underlying components.
Second, infrastructure evolution becomes more manageable because changes remain localized rather than spreading unpredictably throughout the platform.
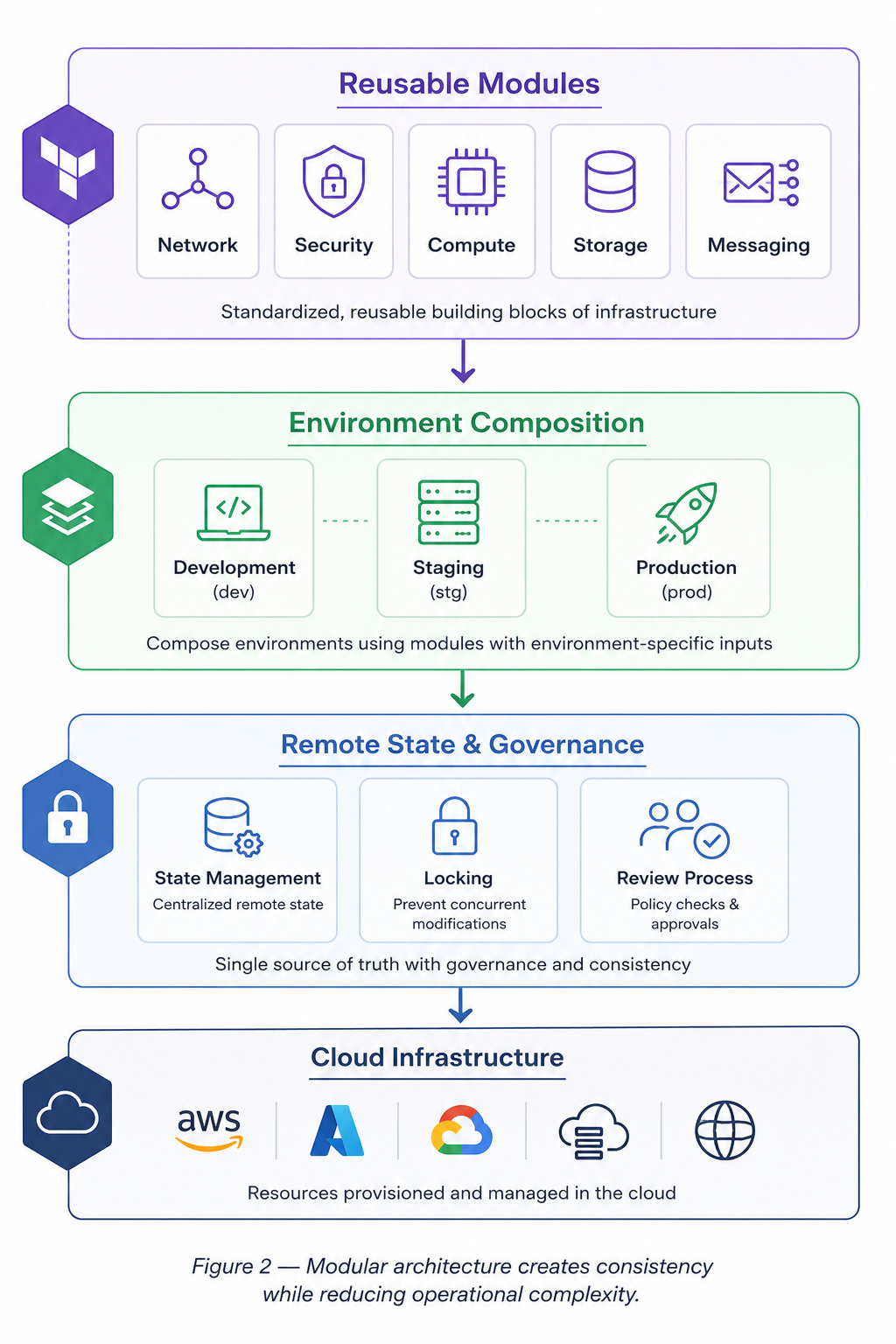
Figure 2 — Modular architecture creates consistency while reducing operational complexity.
Why State Management Matters More Than Most Teams Realize
Infrastructure cannot be managed reliably without a trusted source of truth.
Terraform's state layer provides this foundation.
A centralized state system ensures that every engineer, automation pipeline, and deployment process operates from the same understanding of the environment.
Without shared state:
- Concurrent deployments create conflicts
- Infrastructure drift becomes invisible
- Resource ownership becomes unclear
- Recovery becomes significantly harder
With centralized state and locking mechanisms, infrastructure changes become coordinated rather than competitive.
This transforms deployments from isolated actions into controlled organizational processes.
The operational value is substantial.
Many deployment failures are not caused by infrastructure definitions themselves—they are caused by conflicting assumptions about the current state of the system.
The Power of Reviewable Change
One of Terraform's most valuable architectural characteristics is its ability to convert infrastructure modifications into reviewable artifacts.
Every proposed change becomes a diff.
That diff can be analyzed, discussed, challenged, and approved before anything reaches production.
This mirrors the software development practices that engineering teams already trust.
Code reviews have long been considered essential for application development.
Infrastructure deserves the same rigor.
When infrastructure changes become reviewable:
- Risk becomes visible.
- Drift becomes detectable.
- Destructive actions become obvious.
- Teams gain confidence in deployment outcomes.
The deployment process shifts from execution to decision-making.
And decision-making is where reliability is created.
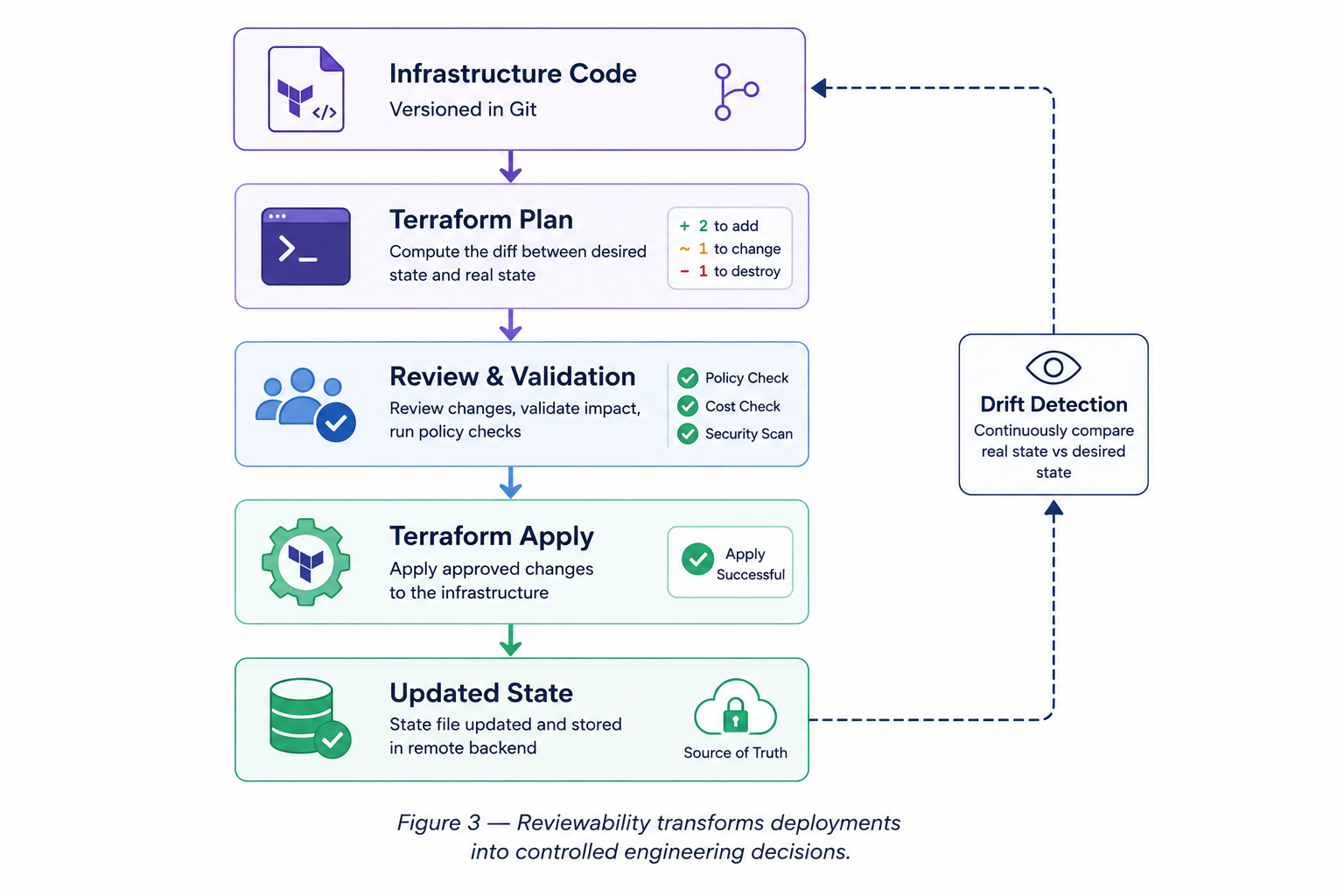
Figure 3 — Reviewability transforms deployments into controlled engineering decisions.
Separating Infrastructure Evolution from Application Delivery
One of the most important lessons in modern cloud operations is that not all changes occur at the same pace.
Infrastructure evolves slowly.
Applications evolve rapidly.
Treating both layers identically creates unnecessary operational friction.
Infrastructure concerns typically include:
- Networking
- Security policies
- Permissions
- Compute definitions
- Platform configuration
Application concerns typically include:
- Container releases
- Feature deployments
- Bug fixes
- Runtime updates
Successful organizations establish clear boundaries between these responsibilities.
Terraform manages the durable shape of the platform.
Deployment pipelines manage application releases.
This separation allows each layer to evolve independently while reducing the risk of unintended interference.
Operational maturity is often less about introducing new tools and more about creating clear ownership boundaries.
The Real Outcome: Deployment Confidence
The ultimate goal of infrastructure architecture is not automation.
It is confidence.
A reliable Terraform workflow enables teams to answer critical questions before changes occur:
- What is changing?
- Why is it changing?
- Which resources are affected?
- What is the risk?
- Can the change be safely reversed?
When these questions have clear answers, deployment anxiety begins to disappear.
Engineering teams spend less time investigating infrastructure behavior and more time building products.
That shift in focus is where the real business value emerges.
Key Takeaways
- Infrastructure reliability is fundamentally a change-management problem.
- Terraform's greatest value is creating predictable, reviewable infrastructure evolution.
- Modular architectures improve consistency and reduce operational complexity.
- Centralized state management establishes a trusted source of truth.
- Reviewable diffs transform deployments from risky actions into informed decisions.
- Separating infrastructure concerns from application delivery improves operational scalability.
- The ultimate outcome is not automation—it is deployment confidence.