From Raw Logs to Canonical Issues: Signature Extraction and Topic Modelling for Fleet Observability


A fleet of connected devices is a relentless text generator. Every device runs a dozen cooperating services, and each one narrates its life in log lines: startup banners, retries, sensor readings, stack traces. Across a hundred-plus devices that adds up to hundreds of thousands of lines a day, spiking into the millions during a noisy rollout. Buried in that stream is a small number of distinct problems, each repeated thousands of times with slightly different wording.
The core engineering challenge of observability isn't storing those lines. It's the inverse problem: given a torrent of near-duplicate, semi-structured text, recover the handful of underlying issues that generated it, and give each one a stable identity you can count, track, and reason about over time. This post is about how that machinery actually works, from a single raw line all the way to a canonical issue: signature extraction, templating, fingerprinting, and the topic modelling that groups it all together.
The pipeline at a glance
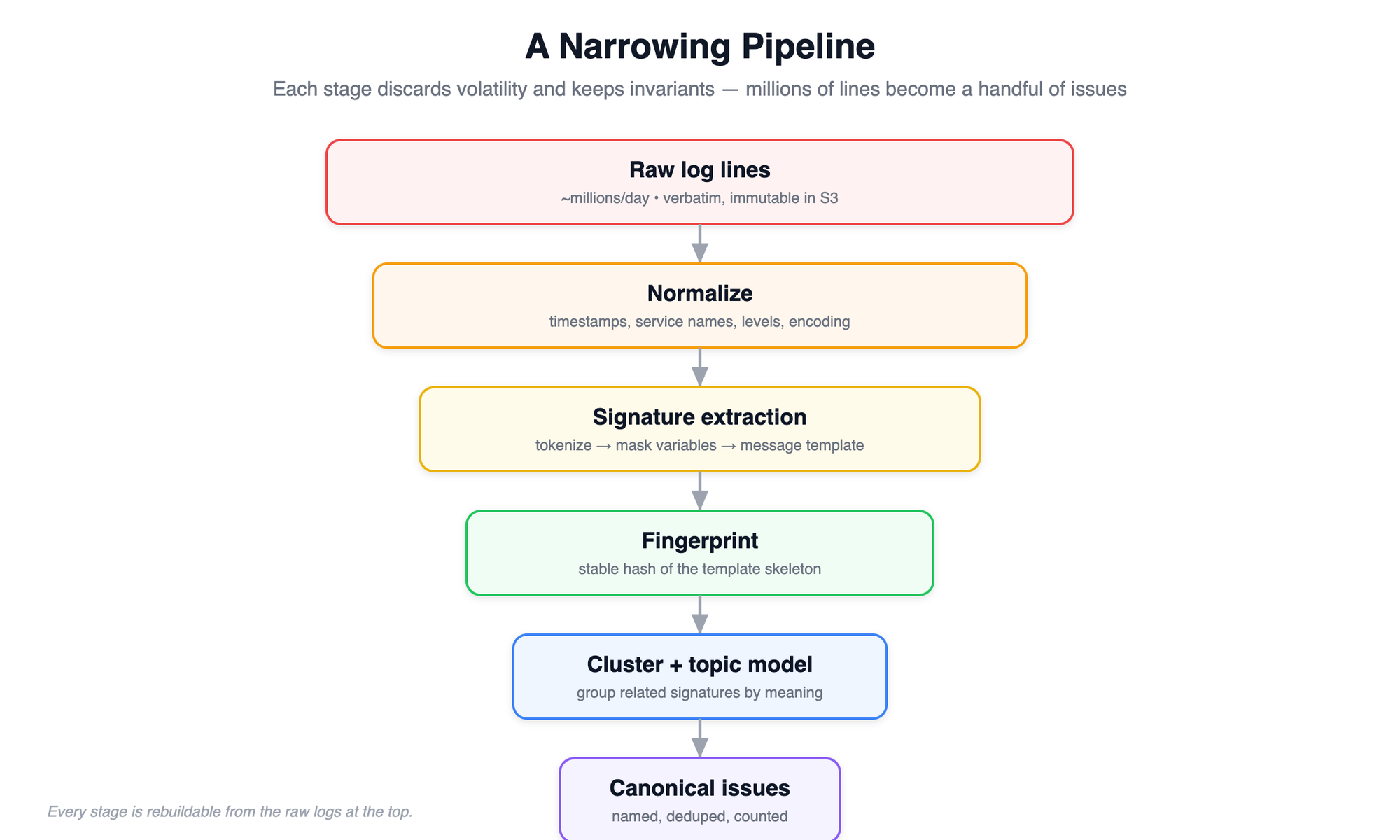
The pipeline is a series of narrowing stages. Raw log batches are ingested and stored verbatim as the durable source of truth. From there, each line passes through normalization, then signature extraction, then fingerprinting, then clustering and topic modelling, and finally canonical issue formation. Every stage throws away volatility and keeps invariants, so a million chaotic lines collapse, step by step, into a short list of named issues with stable identifiers.
The guiding principle is that raw events are immutable and everything downstream is a derived, rebuildable view. If we change the templating rules or retrain the topic model tomorrow, we can replay the raw logs and recompute every signature and cluster from scratch.
Figure 1 — The narrowing pipeline: raw lines are normalized, reduced to signatures, fingerprinted, clustered, and finally promoted to canonical issues.
Step 1: normalization
Before we can extract anything meaningful, raw lines need a common shape. Different services emit different timestamp formats, different level conventions (ERR vs ERROR vs error), and sometimes mangled encodings. Normalization parses each line into a small struct: a UTC timestamp, a service name, a severity level, and a free-text message body. This is deliberately mechanical and lossless in spirit; we keep the original line intact and only attach structure on top. Everything after this point operates on the normalized message body, not the raw bytes.
Step 2: signature extraction
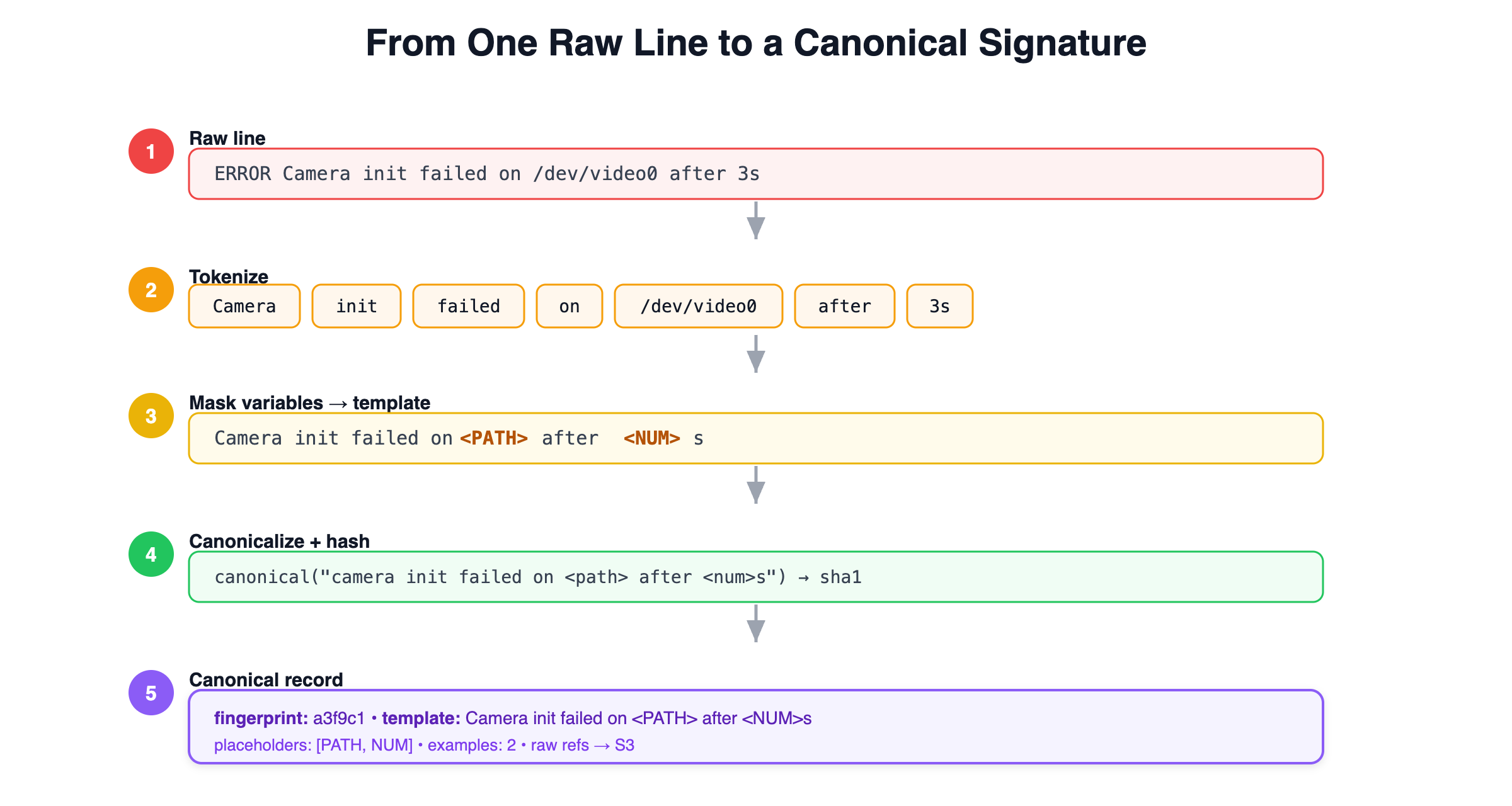
This is the stage that does the heavy lifting. A signature is the invariant skeleton of a message with all of its variable parts masked out. The intuition is simple: a log statement in code is a fixed format string interpolated with runtime values. Two log lines produced by the same line of source code share that format string, even though their interpolated values differ. Signature extraction tries to recover that format string from the rendered output.
We do it in two passes. First, tokenization splits the message body into tokens on whitespace and punctuation boundaries. Second, each token is classified as either a constant (a word that tends to recur verbatim across many lines) or a variable (a token whose value changes from line to line: numbers, hex IDs, UUIDs, IP addresses, file paths, device identifiers, durations). Variable tokens are replaced with typed placeholders, so a sensor reading becomes <NUM> and a device path becomes <PATH>. What remains is the message template.
Concretely, the two lines "Camera init failed on /dev/video0 after 3s" and "Camera init failed on /dev/video2 after 7s" both reduce to the template "Camera init failed on <PATH> after <NUM>s". The volatile bits are gone; the meaning is preserved.
Step 3: fingerprinting and canonical form
A template is human-readable, but we need a compact, stable identity to use as a key. So we canonicalize the template (lowercase, collapse whitespace, sort out any order-insensitive fields) and hash it. That hash is the fingerprint: a short, deterministic identifier for "this kind of message." The same source statement always produces the same fingerprint, regardless of which device emitted it or what runtime values it carried.
The fingerprint, the canonical template, the typed placeholders, and a few representative example lines together form the canonical record for that signature. It's the atomic unit everything downstream counts and tracks. Crucially, the canonical record is derived: it carries no device-specific or time-specific data itself, only a pointer back to the raw lines in object storage that match it.
Figure 2 — Signature extraction and canonicalization: a raw line is tokenized, its variables masked into a template, then hashed into a stable fingerprint.
Step 4: clustering and topic modelling
Fingerprinting alone gets us a long way: it collapses thousands of near-identical lines into one signature. But it's brittle in one direction. Two messages that mean the same thing can still produce different fingerprints if their wording differs even slightly, for example "camera initialization timed out" versus "failed to init camera (timeout)". A purely lexical hash treats those as two separate problems. To a human triaging the fleet, they're one.
This is where topic modelling comes in. Instead of comparing the literal characters of two templates, we compare their meaning. Each signature template is turned into a vector embedding, a point in a high-dimensional space where semantically similar messages sit close together. We then cluster those vectors, so signatures that describe the same underlying failure mode, even with different phrasing, land in the same group.
Two complementary techniques run here. Density-based clustering groups nearby embeddings without forcing a fixed number of clusters, which matters because we don't know in advance how many distinct failure modes exist in the fleet. Alongside it, a topic model over the token distributions of each cluster surfaces the words that most distinguish one group from another, giving each cluster an interpretable label rather than an opaque ID. The output is a set of topics, each one a coherent theme like "camera initialization," "connectivity dropouts," or "weight-sensor calibration," with its member signatures attached.
Clustering runs as a periodic batch job rather than on the hot path. New signatures are assigned to their nearest existing cluster cheaply in real time; the heavier re-clustering and topic re-estimation happens on a schedule, so the model improves over time without slowing down ingestion.
Figure 3 — Topic modelling groups semantically related signatures into canonical issues, even when their wording differs.

Step 5: canonical issue formation
A canonical issue is the final, human-facing object, and it's assembled from everything upstream. It owns a topic cluster, the set of signatures within it, a stable issue identifier, and a generated title drawn from the cluster's most distinctive tokens. To that derived core we attach the metrics that make it actionable: how many devices are affected, when it was first and last seen, and how its volume is trending.
We keep a hard line between derived data and human data. Everything computed from logs (signatures, clusters, counts) is rebuildable and can be regenerated by replaying raw events. Everything authored by people (issue status, assignees, triage notes) lives separately and is never overwritten when the pipeline recomputes. That separation is what lets us safely re-run signature extraction or re-train the topic model without losing a single engineer's annotation.
Serving it back
On the read side, pre-aggregated rollups of issue counts over trailing windows are served from a fast key-value store, so the default view of "what's broken across the fleet" is effectively instant. Ad-hoc queries and deep dives drop down to live aggregations over the searchable index, and an issue detail view drills from a canonical issue all the way back to the individual raw log lines that fed it. The engineer reads meaning at the top and ground truth at the bottom, with every layer in between fully reconstructable.
Why this design holds up
The whole pipeline is really one idea applied repeatedly: at each stage, throw away what's volatile and keep what's invariant. Normalization removes formatting noise. Signature extraction removes interpolated values. Fingerprinting removes the last bits of lexical variation. Topic modelling removes differences in phrasing. By the time a line reaches the top, all that's left is meaning, and meaning is what an engineer actually wants to triage. Because every layer is derived from immutable raw events, the model is never frozen: better templating rules or a smarter topic model are one replay away.
Key takeaways
- Treat raw log events as the immutable source of truth and everything else as a rebuildable view.
- Signature extraction recovers the format string behind a log line by masking variable tokens into a stable template.
- Fingerprints give each signature a compact, deterministic identity that's independent of device or runtime values.
- Topic modelling groups signatures by meaning rather than spelling, merging differently-worded reports of the same failure.
- Canonical issues separate derived data (rebuildable) from human-authored triage data (preserved), so the pipeline can be recomputed safely.