Identifying Dogs by Facial Landmarks: Building a Multi-Stage Vision Pipeline

How we are building a dog facial recognition system from scratch using landmark alignment, metric learning, and a custom-trained embedding model
The Problem
EverBowl is Hoomanely's precision healthcare deivce for dogs. The bowl monitors eating and drinking habits, ocular temperature, sounds and behavioral patterns over time, turning routine visits to the bowl into a continuous health signal for pet owners.
This works well for single-pet households. But a portion of our users have two or more dogs sharing the same bowl. When multiple pets use the same device, the data becomes ambiguous: we know something happened, but not which dog caused it. Tracking individual health metrics in a multi-pet household requires knowing, per visit, which dog is at the bowl.
The naive approach of attaching a classifier to the camera breaks down immediately. A classifier requires a fixed set of known dogs at training time, but users add new pets, households change, and the system needs to work without retraining every time. We needed identity-based recognition, not classification.
That meant building a face recognition pipeline for dogs.
Why Not Just Use a Pretrained Model?
Dog face recognition is not a solved problem the way human face recognition is. Models like FaceNet have no dog equivalent with comparable quality and generalization. The few public datasets that exist (like the Zenodo DogFaceNet dataset) are helpful for pretraining but do not capture the visual conditions our cameras produce: fisheye distortion, overhead angles, low-contrast infrared-adjacent imagery, and dogs positioned very close to the lens.
We had to build most of this ourselves.
System Overview
The system has three distinct stages, each triggered at a different point in the product lifecycle, all sharing the same preprocessing pipeline.
Training runs infrequently -- only when we need to improve or retrain the embedding model. It processes labeled image collections from known pets through the preprocessing pipeline to produce face crops, then trains the model on those crops combined with public data.
Gallery building runs whenever a new pet needs to be handled by the system. It takes the already-trained model and embeds that pet's face crops into a mean identity vector, then appends it to the gallery file. No retraining is required. Adding a new pet takes seconds.
Inference runs in real time on every new camera frame. It pushes the frame through the same preprocessing pipeline, embeds the resulting crop with the trained model, and matches it against the gallery to identify which pet is at the bowl.
The preprocessing pipeline is the shared foundation for all three stages. Getting it right is what makes everything else work.
The Shared Preprocessing Pipeline
All three stages start here. Raw camera frames are messy: motion blur, lighting changes, partial occlusions, profile poses, and multiple dogs in frame. We built a seven-step pipeline to filter and extract only good frontal face crops.
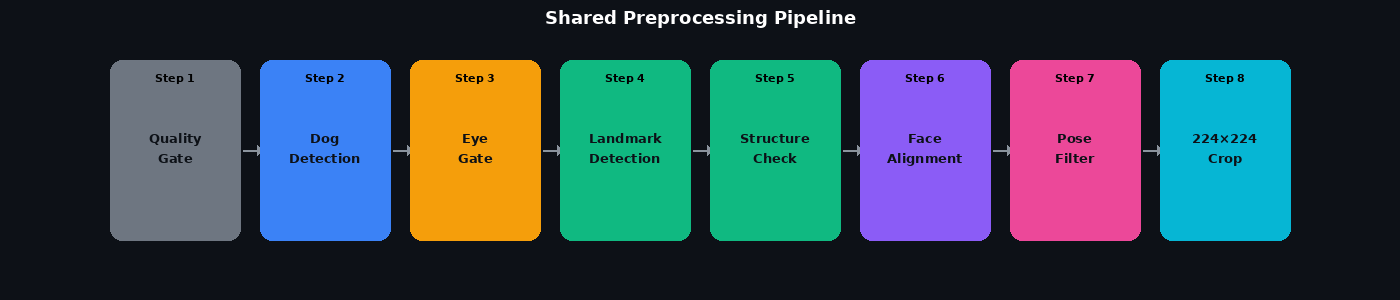
Step 1: Quality gate. Every frame is rejected if the Laplacian variance (a proxy for sharpness) is below threshold, or if mean brightness is too dark or overexposed. This removes a large fraction of nighttime and fast-motion frames before any model runs.
Step 2: Dog detection. YOLOv8-nano (pretrained on COCO) detects the dog bounding box from our bowl camera images. We take only the highest-confidence detection per frame and add a 15% margin around the box to give downstream models full context.
Step 3: Eye gate. We reuse the eye segmentation model already trained as part of EverBowl's ocular temperature pipeline. That model runs on the dog crop and validates a geometrically plausible pair of eyes: the pair must be horizontally aligned (vertical ratio below 0.6), at least 15px apart, with both eyes in the upper half of the crop. This is a fast gate: frames with no valid eye pair are skipped without running the slower landmark model.
Step 4: Landmark detection. A 46-point TFLite landmark model runs on the dog crop at 384x384 resolution and returns normalized (x, y) coordinates for four anatomical groups: outer head and ear periphery (points 0-5), cheek and face boundary (6-11), eyes (12-23), and nose and muzzle (24-45).
Step 4a: Structure check. Before alignment, a rotation-invariant check confirms the raw landmarks form a coherent dog face structure. The eye cluster centroid and nose cluster centroid must be meaningfully separated, each cluster must be internally compact relative to that separation, and the two sub-centroids of the eye cluster (split left/right) must be far enough apart to confirm both eyes are visible. Profile views, where only one eye is visible, are rejected.
Step 5: Face alignment. A similarity transform (rotation + uniform scale + translation, no shear) maps the detected left-eye centroid, right-eye centroid, and nose centroid to a fixed canonical template: eyes at (0.30, 0.38) and (0.70, 0.38), nose at (0.50, 0.62). OpenCV's estimateAffinePartial2D gives us the matrix; warpAffine produces a 224x224 crop. If more than 20% of output pixels are black fill (meaning the face was far off-canon), the frame is rejected.
Step 6: Pose filter. On the aligned 224x224 landmarks, we check coverage (landmark bounding box must span at least 30% of the crop on both axes) and yaw symmetry (left and right spread of eye landmarks must not differ by more than 4x). Frames that fail are discarded.
Step 7: Output. The 224x224 crop exits differently depending on the stage: in training and gallery building it is saved to disk organized by pet identity; in inference it is passed directly to the embedding model.
The image below shows a typical annotated frame: the green box is the YOLO dog detection, red dots are the validated eye pair, and the inset shows the 46 landmark points color-coded by group on the aligned face crop.

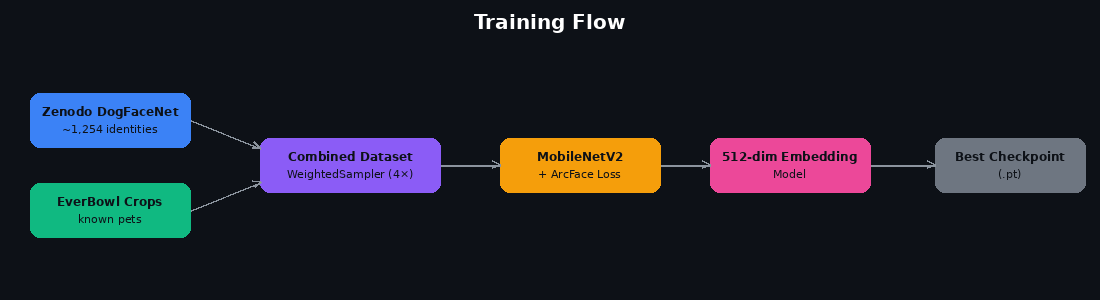
Training Flow
Building the Dataset
The preprocessing pipeline runs on all images from known pets captured by EverBowl cameras, saving one 224x224 aligned face crop per passing frame per pet. We also combine this with the public Zenodo DogFaceNet dataset, which provides approximately 1,254 additional dog identities to improve the embedding model's general discriminability.
Here is what the resulting training set looks like for our pets: rows are individual dogs, each column is one aligned 224x224 crop.

Training the Embedding Model
Architecture. MobileNetV2 pretrained on ImageNet serves as the backbone. The classification head is replaced with a linear projection to 512 dimensions followed by batch normalization and L2 normalization. The output is a unit-norm embedding vector.
Loss function. We use ArcFace (Additive Angular Margin Loss) with scale s=64 and angular margin m=0.5 radians. ArcFace adds a fixed angular penalty to the target class logit during training, which forces the model to learn a much tighter angular separation between identities than standard softmax would. At inference time the classification head is discarded entirely and identity matching is purely cosine similarity between embedding vectors.
Handling data imbalance. The Zenodo dataset is roughly 12x larger than our EverBowl crops, which would cause the model to underfit on our actual pets. We use a WeightedRandomSampler that gives EverBowl identities a 4x sampling boost, ensuring they appear frequently in every batch.
Augmentation. Training applies random horizontal flips, color jitter, and small random rotations. Validation uses only resizing and normalization.
Training loop. We run 60 epochs with AdamW (lr=1e-3, weight decay=1e-4) and cosine annealing to lr=1e-5. Every 5 epochs we evaluate rank-1 nearest-neighbor retrieval on two held-out validation sets: Zenodo identities held out at the identity level (open-set evaluation), and EverBowl identities with two images held out per pet. The checkpoint with the best EverBowl rank-1 accuracy is saved as the production model.
Gallery Building
Gallery building is triggered independently of training -- any time a new pet joins a household, or when we want to refresh a pet's embeddings after collecting more photos.
For each pet, we run all their aligned face crops through the trained embedding model and average the resulting 512-dimensional vectors into a single mean embedding, which is then L2-normalized. This mean embedding represents that pet's identity in the embedding space the model has learned.
The gallery is stored as a .pt file that maps each pet name to its mean embedding. It is completely separate from the model checkpoint. Adding a new pet means running their crops through the existing model and appending one vector to the gallery file -- no retraining, no disruption to existing identities.
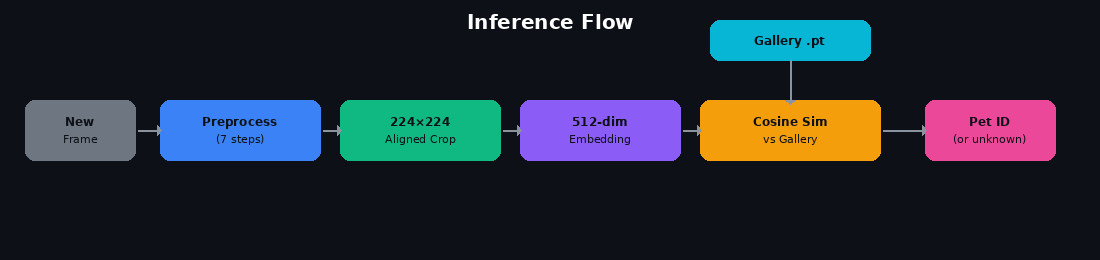
Inference Flow
Inference runs on every new camera frame and has two stages.
Stage 1: Preprocessing (same pipeline)
The new camera frame runs through the same seven-step pipeline described above. If any step fails (blurry, no dog, no eye pair, landmark structure failure, alignment failure, pose failure), the frame produces no identification result and the failure stage is logged.
Stage 2: Matching Against the Gallery
For any frame that passes preprocessing, the aligned 224x224 crop is embedded by the model to produce a 512-dimensional unit-norm vector. We compute cosine similarity between this vector and every mean embedding in the gallery. The highest similarity wins if it clears a configurable threshold (default 0.50); frames below threshold are marked as unknown.
What Is Next
This post covers the pipeline design and approach. In the next post, we will share results on our own EverBowl dataset: identification accuracy, failure mode breakdown by stage, threshold calibration, and where the system currently struggles.
This pipeline is the first step toward making EverBowl work for multi-pet households.