Improving LLM Output Quality Through Pet-Scoped Document Ingestion

A pet parent opens EverWiz chat and asks, “Is Milo overdue for his rabies booster?”
A generic LLM can write a thoughtful essay about rabies vaccination schedules. What it cannot do out of the box is look at this pet's actual vaccination card and give a real answer.
That gap between plausible and grounded is the gap we needed to close. The user's own documents—the ones they already trusted enough to upload to PawVault—were the missing input. Once we treated those documents as a first-class signal feeding every chat response, the assistant stopped sounding like a search engine and started sounding like someone who actually knew the pet.
The Problem in Three Parts
Before any of the engineering, the problem decomposed into three sub-problems:
- Documents arrive messy.
Users upload phone camera photos of vaccination cards, multi-page PDFs from vet portals, blurry scans of handwritten dosage notes, and the occasional DOCX. None of this is structured data.
- Pets are scoped, users are not.
A household can have multiple pets. Milo's records cannot leak into Luna's answers, ever. Scoping is a correctness property, not a UX nicety.
- Chat is a real-time surface.
Whatever we extract from a document has to be available at chat time in milliseconds, not seconds. The user is mid-conversation; the assistant cannot stall.
A single solution had to satisfy all three.
Design Principles
Several principles shaped the architecture from the beginning:
• Decouple ingestion from inference. Extraction is heavy and occasional; chat is light and constant. They should never share a critical path.
• Treat pet identity as a hard boundary. Every artifact downstream of ingestion—every extracted field and every embedding—carries the pet ID it belongs to.
• Prefer structured fields where the answer is a field. Not everything needs similarity search. “What is Milo's weight?” deserves a lookup, not a vector match.
• Fail open on enrichment, never on the user. If something breaks in ingestion or retrieval, the chat still responds, just with less context.
• Stream everything the user is waiting on. Token-by-token response delivery avoids unnecessary waiting.
Capturing the Document Cleanly
The mobile client's only responsibility is to get the document into the system without corrupting it.
Two design choices mattered here:
Direct-to-storage uploads
The application fetches a short-lived signed URL and uploads the file directly into object storage. Heavy file uploads never pass through our API layer.
This gives us:
• Predictable latency
• Independent scaling
• Reduced backend load
• Smaller failure surface area
On-device preprocessing
Phone photos are downscaled and re-encoded on a background thread before upload.
Enough resolution remains for downstream OCR, while the user experiences significantly faster uploads.
Once the file lands in storage, the mobile application's job is complete and the backend pipeline takes over.
Extracting Structure from Unstructured Files
A storage event triggers an asynchronous extraction workflow.
This process is intentionally fire-and-forget. Users are never blocked waiting for extraction to complete.
The workflow follows four stages:
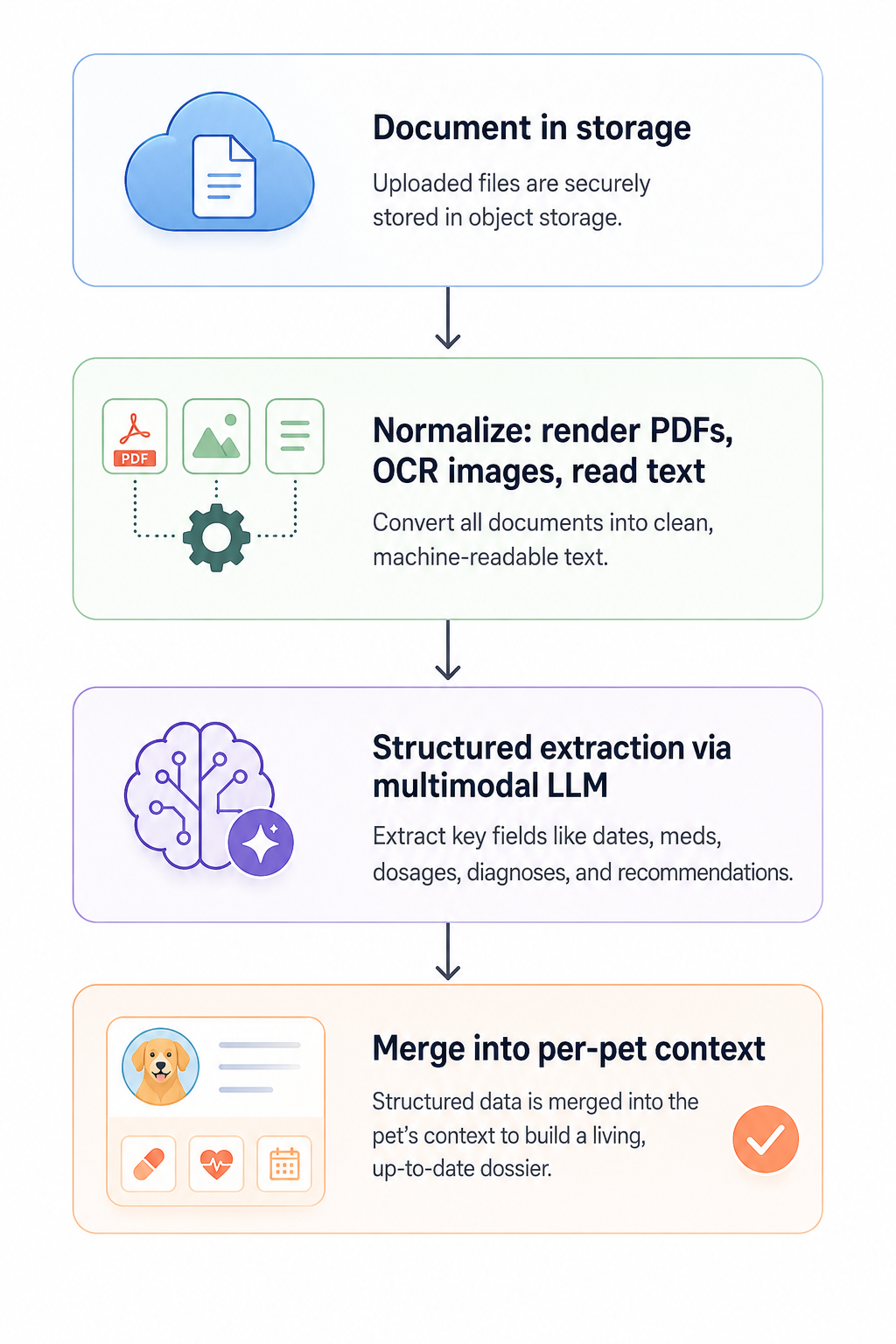
The extraction step is constrained rather than free-form.
Instead of asking the model to generate a summary, we ask it to extract specific fields that a pet-care assistant can rely on.
Examples include:
• Document type (vaccination card, lab report, discharge summary, prescription)
• Clinic, veterinarian, and visit date
• Vaccinations, administration dates, and due dates
• Medications, dosages, and treatment durations
• Diagnoses and recurring conditions
• Recommendations and follow-up actions
This distinction is important.
Free-form summaries create text. Field-based extraction creates data that downstream systems can reason about.
Pet Context as a First-Class Store
The extracted findings are not stored as an isolated blob of text.
Instead, they are merged into a structured per-pet record called Pet Context.
Pet Context contains information such as:
• Name
• Breed
• Age
• Weight
• Allergies
• Current medications
• Medical history
• Document-derived findings
Over time, this becomes a living dossier for each pet.
Pet Context exists before any retrieval system becomes involved.
This allows simple questions such as “What does Milo weigh?” to be answered through structured lookup rather than semantic retrieval.Structured data and retrieval solve different problems. We intentionally keep both.Indexing for Semantic LookupWhile structured extraction is occurring, the raw text also enters an indexing pipeline.
Two decisions matter here.
Adaptive Chunking
A single-page vaccination card and a six-page discharge summary should not be chunked the same way.
Chunking strategies are selected based on document type to preserve meaning while maintaining retrieval precision.
Pet-Scoped Metadata
Every chunk carries the identity of the pet it belongs to.At query time, filtering occurs before similarity search.
This ensures retrieval is scoped to a single pet and makes cross-pet data leakage impossible by design.
Composing the Prompt at Chat Time
When the user submits a question, the backend constructs a layered prompt.
The final prompt contains four layers:
System Layer
This includes:
• Pet profile
• Medical history
• Current medications
• Allergies
• Document-derived findings
This layer answers the question:
“Who is this pet?”
Memory Layer
Conversation history is summarized hierarchically.Recent messages remain verbatim.Older conversations become summaries.Even older summaries are condensed further.This preserves long-term continuity without exhausting the model's context window.
Retrieval Layer
This contains document passages returned by semantic search.Only chunks belonging to the current pet are eligible for retrieval.
User Layer
This contains:
• The user's current question
• Recent conversation turns
Together, these layers provide enough context for grounded and personalized responses.Responses are streamed token-by-token back to the application so users see answers appear in real time.
Designing for Imperfect Extraction , No extraction system is perfect.We designed the architecture assuming that.Extracted findings are treated as evidence rather than truth.
The assistant is informed that these findings came from uploaded documents rather than being unquestionable facts.Conflicting records are surfaced instead of silently merged.
If two documents contain different medication dosages, the assistant highlights the discrepancy rather than selecting one arbitrarily.Empty retrieval results are also valid.When no relevant document chunk exists, the system can still answer using structured pet context and general knowledge.
Date-sensitive information such as vaccine due dates and prescription windows is computed against the current date rather than relying on static model knowledge.
Most importantly, every layer is optional.If embeddings fail, pet context still works.If pet context is incomplete, retrieval still works.The experience degrades gracefully rather than breaking completely.
What Changed for the User
None of this complexity is visible to the pet parent.They upload a vaccination card on Tuesday.On Saturday morning, while standing inside a veterinary clinic, they ask:
“Is Milo due for anything?”
The assistant responds with:
• The actual vaccine
• The administration date
• The clinic that issued it
• The recommended due window
The answer is grounded in their pet's records rather than a generic vaccination schedule.The seam between them is intentionally small: a signed URL going in and a streaming response coming out.Everything else happens behind the scenes.
How This Supports Hoomanely's Mission
At Hoomanely, our goal is to help pet parents make more informed decisions through technology.Per-pet document ingestion is a foundational capability in that vision.Rather than acting as a generic chatbot, EverWiz becomes a personalized assistant that understands a pet's actual history, records, medications, and care journey.
The result is a more trustworthy and useful experience for pet parents, built on information that already belongs to them.
Key Takeaways
- Decouple ingestion from inference:Heavy asynchronous extraction and lightweight streaming chat should never share the same critical path.
- Constrain extraction to fields, not summaries : Field-based extraction produces structured records that downstream systems can trust.
- Use structured pet context for field-shaped questions and retrieval for passage-shaped questions.Each mechanism should solve the problem it is best suited for.
- Make pet scoping a property of the data model: Correctness should be enforced by architecture, not remembered through application logic.
- Layer the prompt: Identity, memory, evidence, and user intent should each have a dedicated role.
- Design enrichment layers to be optional: If one layer fails, the user should still receive a useful answer.
The quality may degrade, but the experience should never break.