Keeping a Wearable Alive: Watchdogs and Boot-Spin Guards

A pet wearable has one job above all others: be awake when something happens. A dog doesn't schedule its zoomies, and a collar that has quietly wedged itself into an infinite loop is, for all practical purposes, dead — it just hasn't fallen off the dog yet. The cruel part is that these hangs rarely look like crashes. There's no smoke, no error code; the device simply stops making progress while the battery keeps draining. At Hoomanely, we treat liveness — the guarantee that firmware keeps making forward progress — as a first-class feature, not a happy accident. This post is about the small, unglamorous habits that keep an always-on collar responsive: bounding every wait, yielding inside every tight loop, and respecting the watchdog that's quietly judging us.
The Concept: Liveness Is a Feature You Build
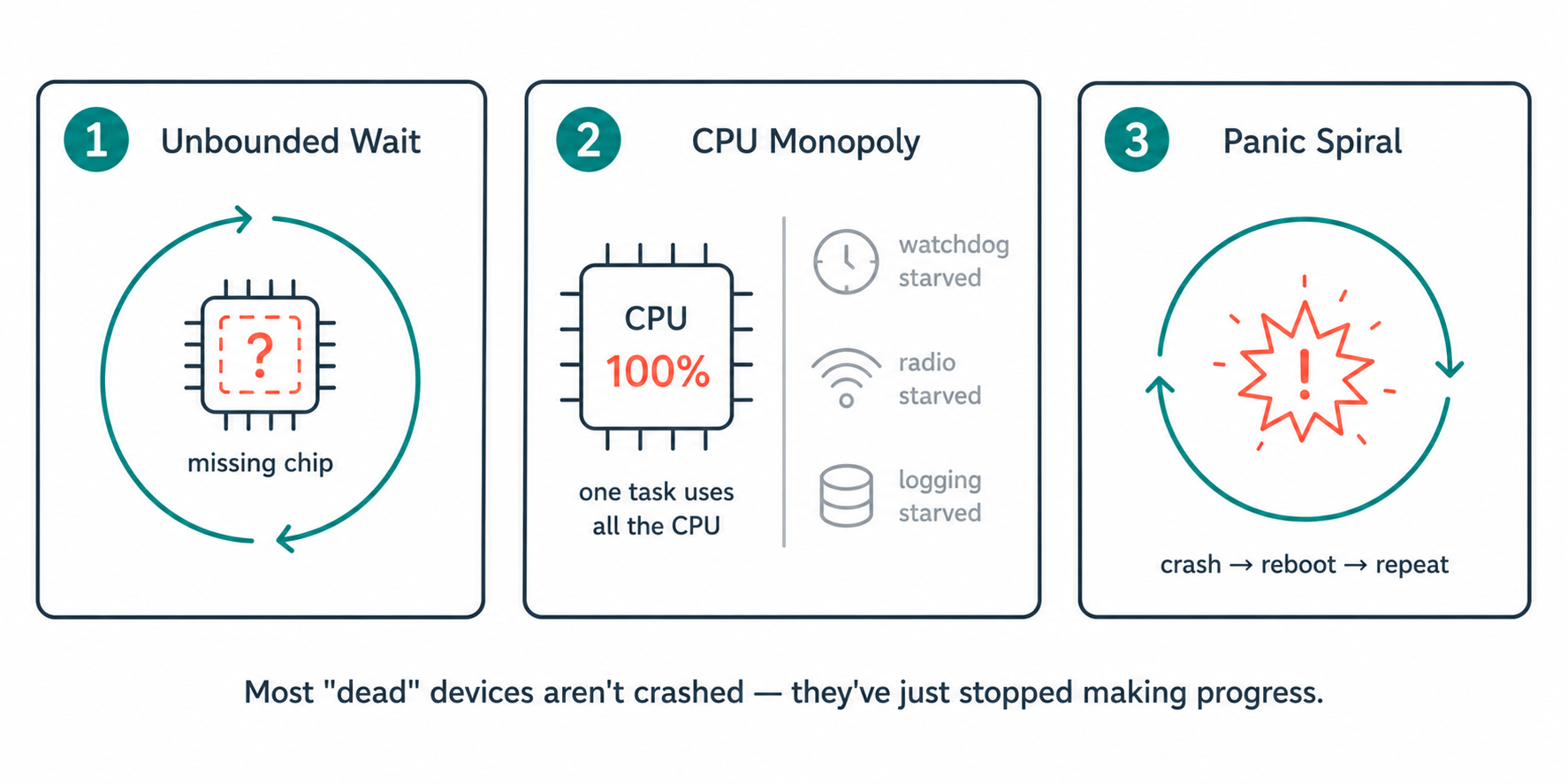
Most embedded bugs that take a device offline aren't logic errors — they're progress errors. The code is technically correct but waits forever for something that will never arrive, or hogs the CPU so completely that nothing else runs.
Three failure shapes account for almost all of them. The first is the unbounded wait: a loop that retries an operation with no exit, spinning until the end of time on a peripheral that isn't there. The second is the CPU monopoly: a tight loop that does real work but never lets lower-priority tasks — including the system's idle housekeeping — get a turn. The third is the panic spiral: code that responds to a transient failure by rebooting, only to hit the same failure again and reboot forever.
Designing against all three is what "liveness engineering" actually means in firmware.
Why It Matters
For a consumer gadget, a hang means an annoyed user power-cycles it. For a continuous health monitor, a hang means a gap in the medical record — a missing afternoon of activity, an undetected event, a trend line with a hole in it. Worse, the device gives no signal that it failed; it looks online while silently recording nothing.
The watchdog is the safety net of last resort. A task watchdog is a timer that expects to be "fed" regularly by the system's lowest-priority idle task; if the idle task never gets to run for several seconds, the watchdog assumes the system is stuck and forces a reset. That's a blunt instrument — a reset is data loss — so the real goal is never to need it. The watchdog should be the thing that catches a bug we missed, not a routine part of normal operation.
How It Works: Four Habits That Keep Us Alive
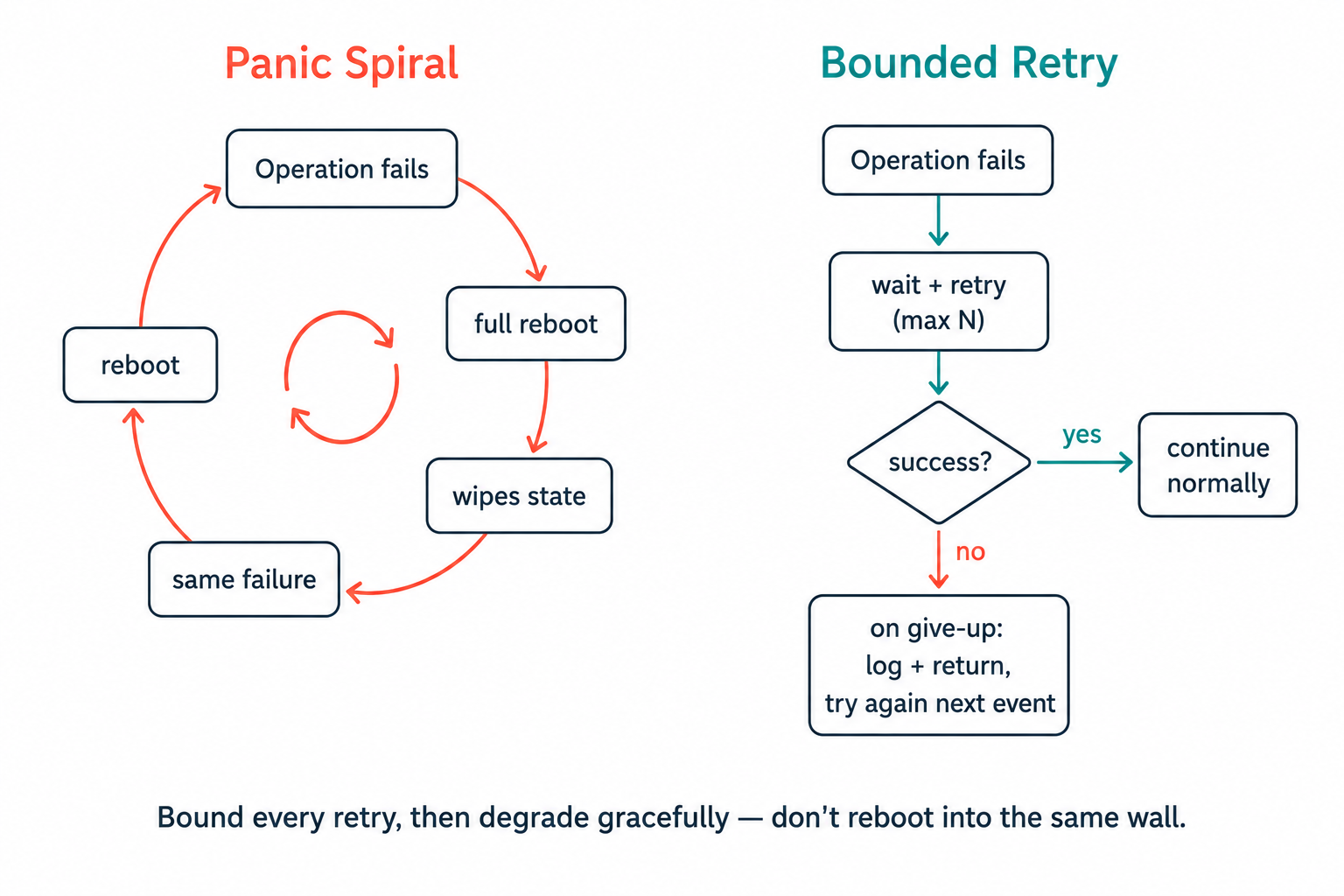
1. Never reboot your way out of a transient failure
Our hardest-won lesson came from the wireless advertising path. An early version called a full system restart whenever it failed to start advertising. Under heavy connect/disconnect churn from a phone, that failure was transient — the radio controller's memory pool was briefly full — but the restart wiped all in-RAM state and hit the same condition again, producing an endless reboot loop.
The fix was to bound the retries and, critically, to fail gracefully instead of fatally:
703 for (int i = 0; i < 20; i++)
704 {
705 rc = ble_gap_adv_set_fields(&fields);
706 if (rc == 0)
707 break;
708 ESP_LOGW(TAG, "Error setting advertisement fields: %d, attempt %d/20", rc, i + 1);
709 vTaskDelay(pdMS_TO_TICKS(500));
710 }
711 if (rc != 0)
712 {
713 ESP_LOGE(TAG, "Could not set advertisement fields (rc=%d) — staying silent until next disconnect cycle", rc);
714 return; // Do NOT esp_restart(); next disconnect will retry advertising.
715 }
Notice the vTaskDelay between attempts — the loop sleeps, giving the radio time to recover and other tasks time to run, rather than busy-spinning. And on persistent failure it simply logs and returns; the next natural disconnect event will try again. A bounded retry with a clean give-up beats an aggressive reset every time.
2. Give every wait an exit
The same discipline applies to hardware that may simply be absent. When the device tries to mount its external storage, it doesn't loop forever hoping the chip appears — it tries, falls back to an internal partition, and if even that fails, it gives up cleanly with a loud log line:
216 // Step 2: if the external mount didn't take, fall back to the internal
217 // "storage" partition declared in partitions.csv.
218 if (active_label == NULL)
219 {
220 if (mount_fatfs(INTERNAL_FALLBACK_PARTITION_LABEL))
221 {
222 active_label = INTERNAL_FALLBACK_PARTITION_LABEL;
223 active_partition_label = INTERNAL_FALLBACK_PARTITION_LABEL;
224 ESP_LOGI(TAG, "Mounted internal fallback partition at %s", MOUNT_POINT);
225 }
226 else
227 {
228 ESP_LOGE(TAG, "All flash mount attempts failed.");
229 flash_mounted = false;
230 return;
231 }
232 }
The device boots and runs in a degraded-but-alive state instead of hanging at startup. A monitor that comes up with reduced storage still captures data; one that spins forever at boot captures nothing. Boot must always terminate — into success or into a known, logged fallback.
3. Yield inside every tight loop
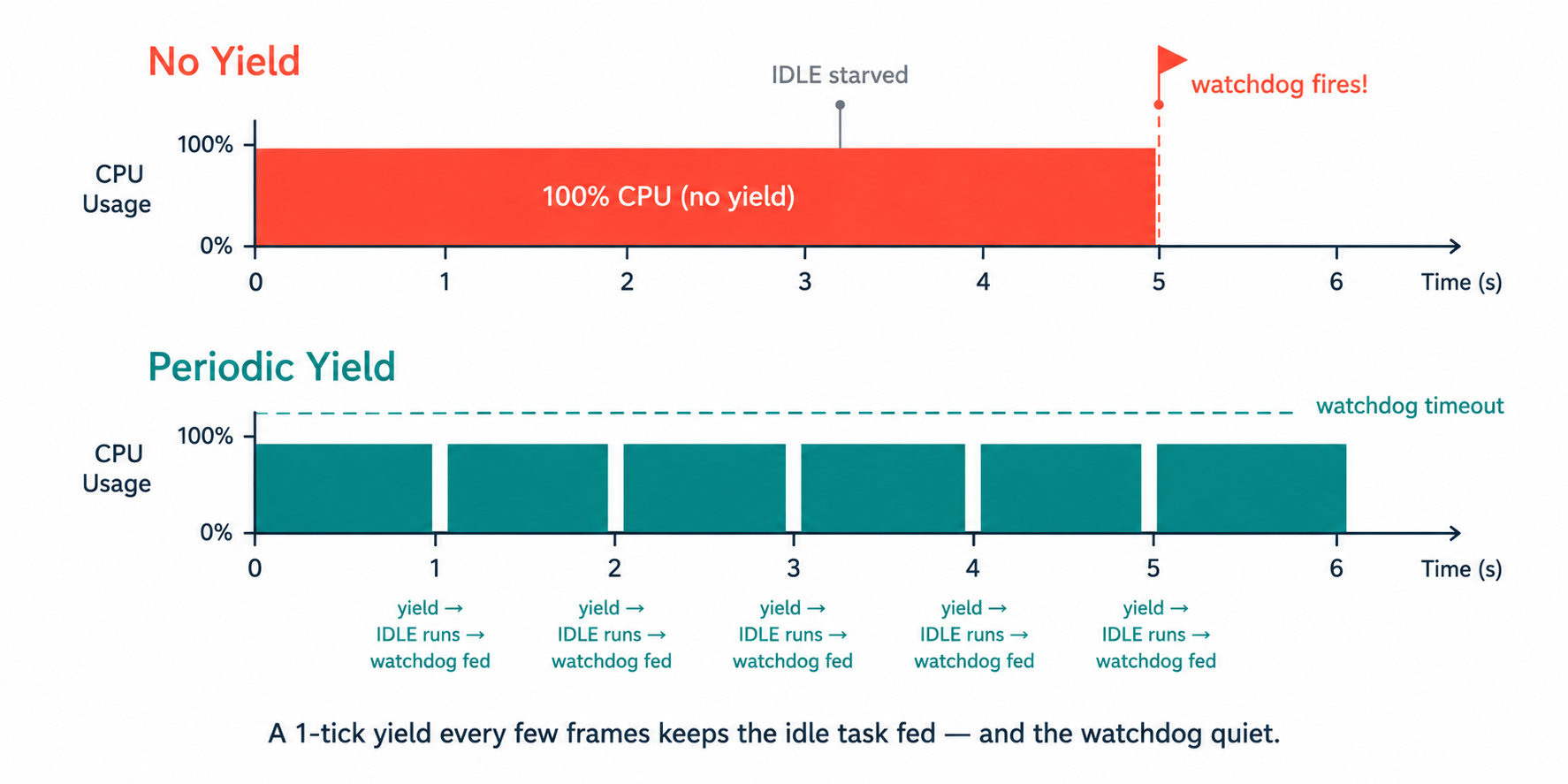
Bounded waits keep us from hanging forever; cooperative yielding keeps us from starving everything else right now. Our flash-spill task can, during an audio burst, receive frames faster than it writes them — and a naive while loop draining that queue will peg a CPU core at 100% for seconds, which is exactly what trips the watchdog.
So the loop yields on a fixed cadence:
506 spill_one_frame(buf, got);
507 frames_written++;
508 if ((frames_written % YIELD_EVERY_N) == 0) {
509 // 1-tick delay = portTICK_PERIOD_MS (default 10 ms) on
510 // this build. Long enough for IDLE to run, short enough
511 // that we still drain the ring well above the producer
512 // rate (8 frames per 10 ms = 800 fps headroom).
513 vTaskDelay(1);
514 }
The reasoning is right there in the code comments we live by: "Yield periodically so the IDLE task on this core gets CPU time and the FreeRTOS task watchdog doesn't fire on it… without an explicit yield this loop pegs CPU 0 at 100% for the duration of the clip and IDLE never runs for >5 s." The trick is calibrating the yield so the watchdog is satisfied while throughput stays far above the data rate — here, draining headroom of ~800 frames/second against a producer doing ~95.
4. Feed the watchdog even when you're busy
Sometimes a loop genuinely needs to do heavy, sustained math. The pattern is the same — a single deliberate yield per iteration hands the scheduler a window to run the idle task and reset the watchdog timer:
139 void intensiveCPUTask()
140 {
141 while (1)
142 {
143 for (int i = 0; i < 1000000; i++)
144 {
145 volatile int result = sqrt(i) * log(i);
146 }
147 vTaskDelay(1); // Small delay to prevent watchdog timer from resetting
148 }
149 }
One line — vTaskDelay(1) — is the difference between a busy task and a hung device. The rule we apply everywhere: if a loop can run longer than the watchdog timeout, it must contain a yield.
Why It Matters at Hoomanely
Hoomanely is reinventing healthcare for pets — moving from a reactive, imprecise, stressful model of care toward continuous, clinical-grade monitoring that catches problems early. Our devices form a Physical Intelligence ecosystem: interconnected sensors fused at the edge, feeding the Biosense AI Engine that turns raw signals into personalized, preventive insights.
That word continuous is a promise, and liveness is how we keep it. An AI engine can only find the early warning signs of pain, anxiety, or illness if the edge device beneath it is reliably awake and recording. Every bounded retry, every yield, every refusal to reboot into a loop is a small guarantee that the data stream never silently goes dark.
Our guiding principle is that every signal matters and every detail counts. In firmware, honoring that means engineering for the un-glamorous failure — the loop that would have spun forever, the burst that would have starved the scheduler — so the device is still there, still listening, the moment the pet needs it to be.
Key Takeaways
- Liveness is a designed property, not a default. Most "dead" devices are simply stuck making no progress while looking online.
- Bound every wait. A retry loop needs a maximum count and a clean give-up path; a boot sequence must always terminate into success or a logged fallback.
- Never reboot out of a transient error. A reset that wipes state and re-hits the same failure becomes an infinite reboot loop — degrade gracefully and retry on the next natural event.
- Yield inside tight loops. If a loop can outlast the watchdog timeout, it must contain a deliberate yield so the idle task runs and the watchdog stays fed.
- Treat a watchdog reset as a bug, not a feature. It's the last line of defense, never part of the normal flow.
These habits live throughout the firmware of the collar-worn tracker that anchors Hoomanely's Physical Intelligence ecosystem — in the wireless advertising path, the storage-mount sequence, and the high-rate flash-drain loop. None of it shows up on a spec sheet. But it's the quiet, load-bearing engineering that lets us say a pet is being watched over continuously — and actually mean it.