Making Power-Up Feel Instant Without Rushing Hardware

Designing perceived responsiveness while respecting electrical reality
Users rarely judge a product by how fast the hardware actually becomes fully ready.
They judge it by how quickly the product appears alive.
That difference matters.
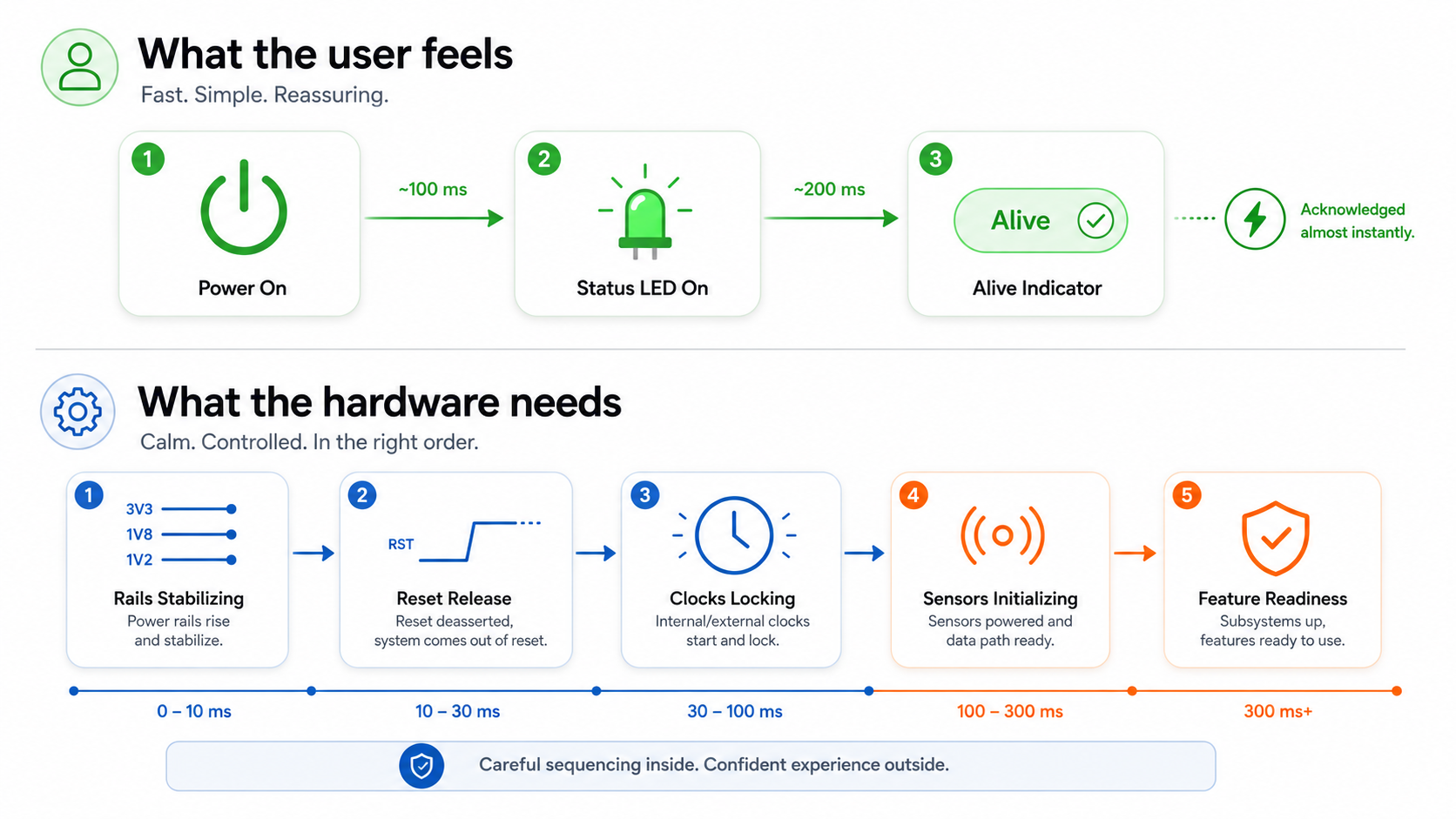
A device may need several hundred milliseconds, or even a few seconds, before every rail is stable, every sensor is initialised, every clock is locked, every interface is configured, and every subsystem is ready for real work. But the user does not see regulator ramp time, oscillator settling, sensor reset timing, bootloader checks, or bus enumeration.
The user sees only one thing:
Did the product respond?
In embedded hardware, this creates a design tension. If we rush the hardware, we risk unstable startup, random feature failures, corrupted state, noisy interfaces, and unpredictable resets. If we wait until everything is fully initialised before showing any response, the product feels slow—even if it is electrically correct.
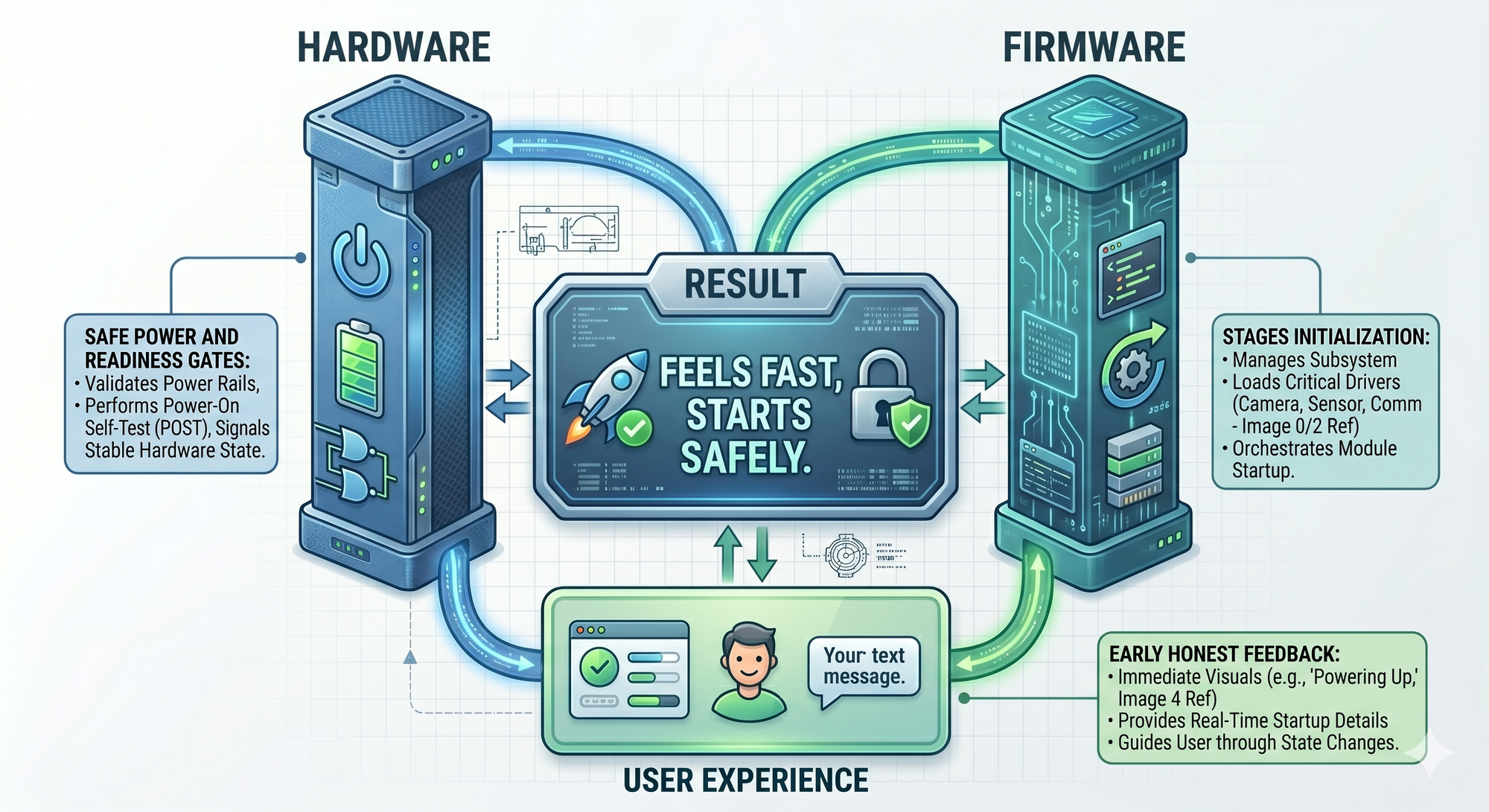
At Hoomanely, we treat power-up responsiveness as a system architecture problem, not just a firmware optimisation task.
The goal is not to make every subsystem start faster.
The goal is to make the product feel responsive while allowing the hardware to come up safely, quietly, and in the right order.
That distinction is the heart of good product-grade embedded design.
Instant Feeling Does Not Mean Instant Readiness
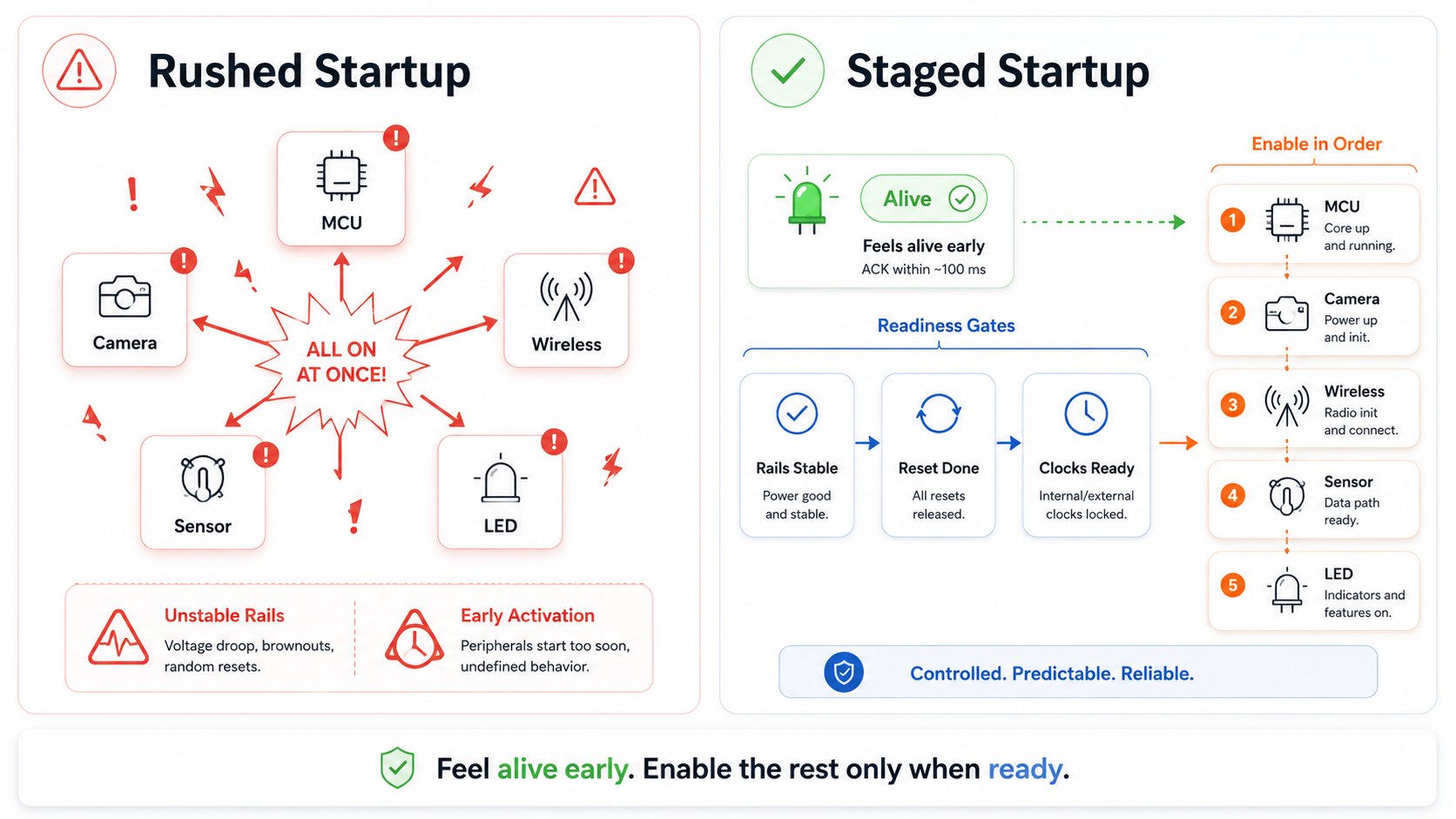
A common mistake is trying to make the whole system ready immediately after power is applied.
This usually leads to fragile startup behavior.
The MCU starts configuring GPIOs while rails are still settling. Sensors come out of reset before their supplies are stable. A camera clock begins before the image sensor is ready. Communication interfaces start before level shifters are properly biased. A high-current feature turns on before the upstream regulator has enough margin.
The product may boot faster in the lab, but it becomes less predictable across temperature, supply variation, component tolerance, and manufacturing spread.
The better approach is to separate visible responsiveness from functional readiness.
A product can show that it is alive before it is fully operational.
For example, an early status LED, short boot tone, low-power indicator, or simple “wake acknowledgement” can happen quickly, while heavier subsystems continue their proper initialisation sequence in the background.
The system does not need to perform every function immediately.
It only needs to communicate that it has received power and is progressing intentionally.
Power-Up Has Multiple Truths
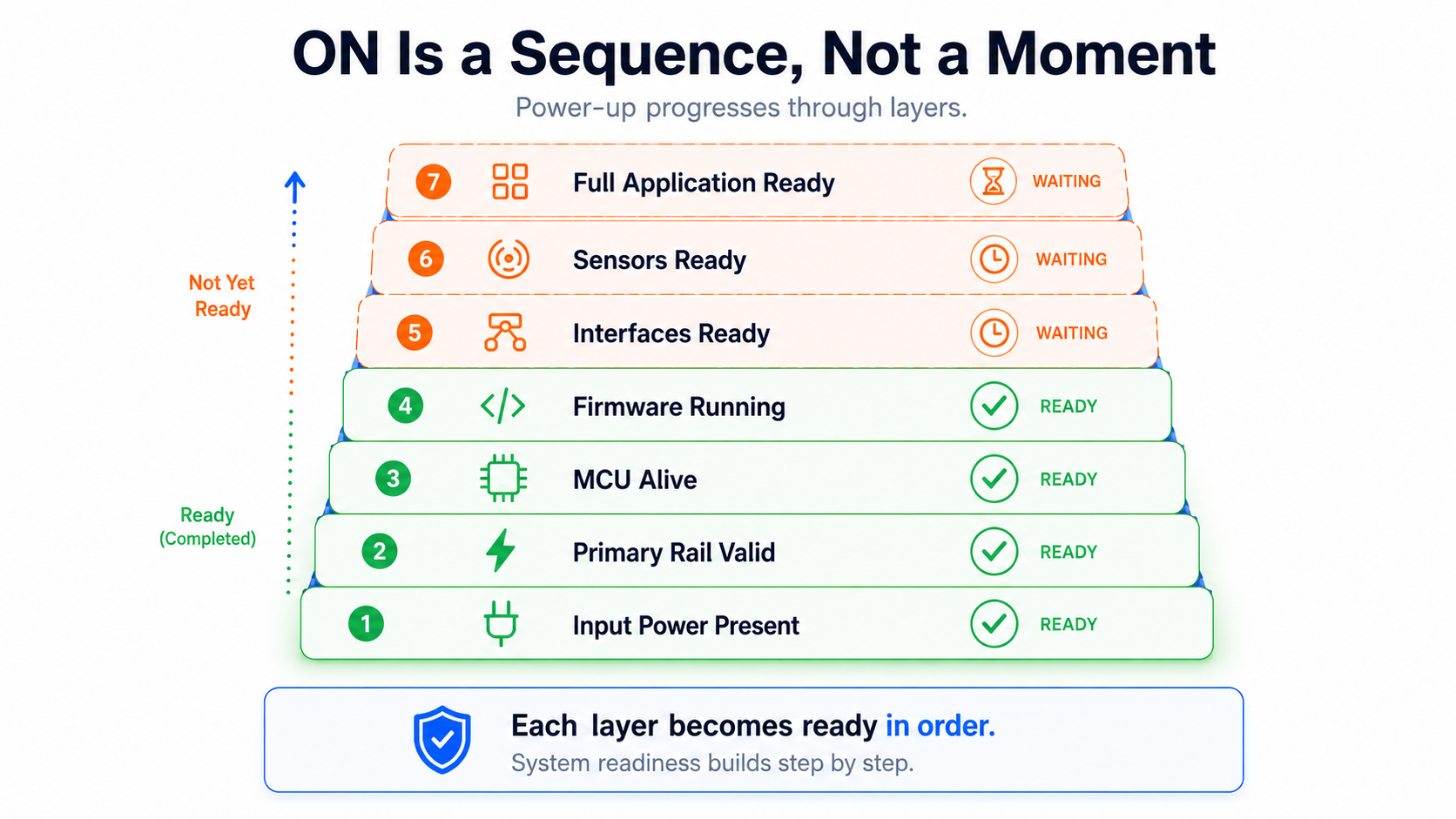
There is no single moment where a device becomes “on.”
Power-up is a sequence of truths.
The input supply may be present.
The primary rail may be valid.
The MCU rail may be stable.
Reset may be released.
Firmware may be executing.
The communication path may be alive.
Sensors may be initialised.
The full application may be ready.
Each of these stages has a different meaning.
A weak architecture treats all of them as one event: power on.
A mature architecture exposes them as separate states.
This is important because different parts of the product can safely respond at different stages. A simple user-visible indication may only require the primary rail and a small controller. A camera capture may require multiple sequenced rails, reset timing, clock validity, and memory availability. Wireless communication may require the main processor, radio calibration, storage readiness, and network state.
Trying to align all of these into one “ready” moment either delays the user experience or rushes the hardware.
Hoomanely-style architecture avoids that by designing a layered startup path.
The First Response Should Be Electrically Cheap
The first sign of life should be simple.
It should not depend on the most complex part of the system.
If the first user-visible response requires Linux to boot, sensors to enumerate, cloud connectivity to start, or multiple feature rails to activate, the product will feel slow and fragile.
A better first response is electrically cheap and architecturally independent.
That may be:
- a low-current status LED,
- a small MCU-controlled indicator,
- a simple power-good visual state,
- a short local acknowledgement,
- or a minimal always-safe output.
The important point is that this response should not disturb the rest of the power-up sequence.
It should not pull significant current.
It should not require high-speed clocks.
It should not depend on sensors.
It should not force feature rails on early.
It should not create false confidence that the whole system is ready.
Its job is not to say, “Everything is ready.”
Its job is to say, “The system is alive, and startup is under control.”
That small distinction improves perceived responsiveness without compromising electrical stability.
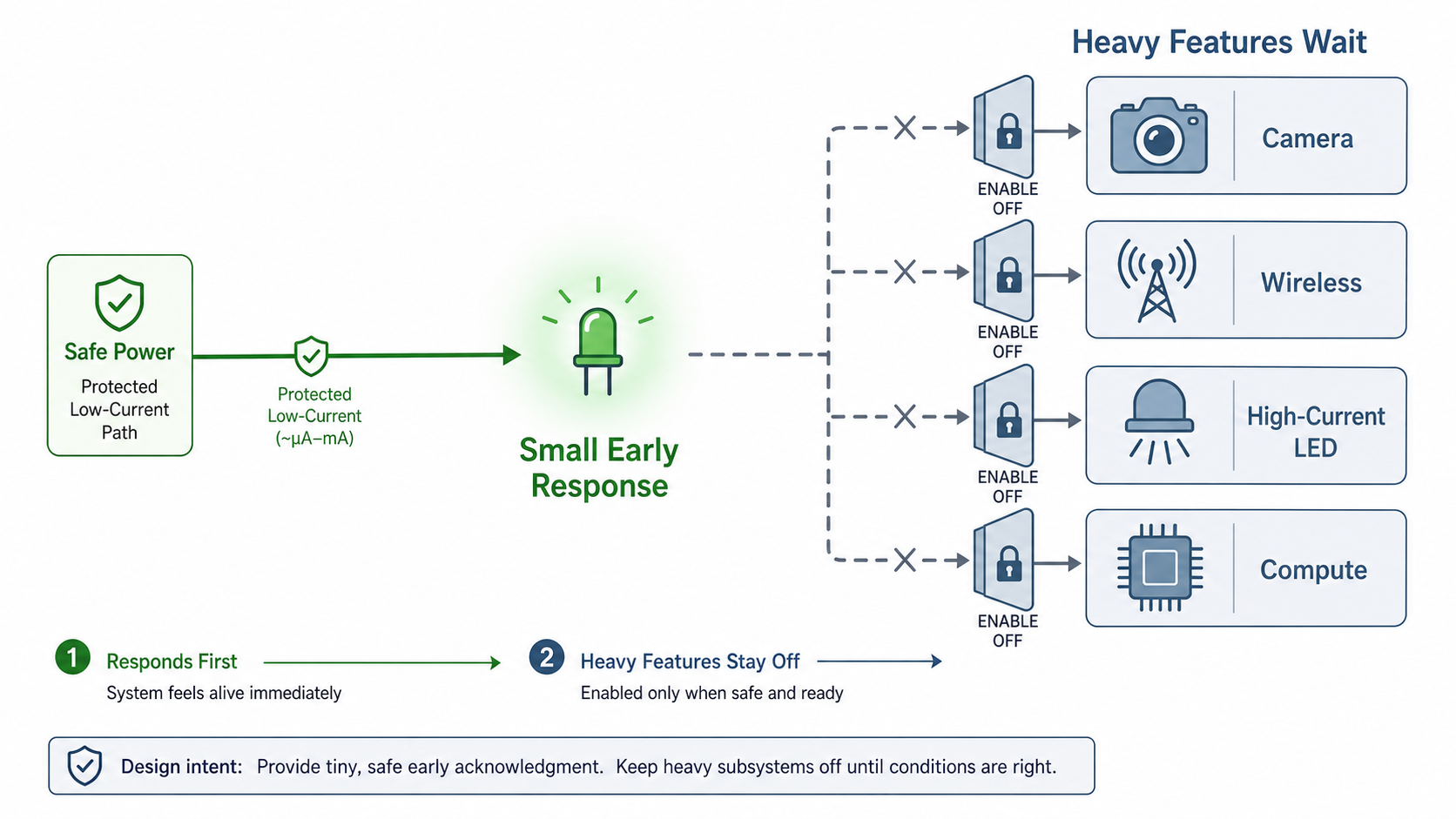
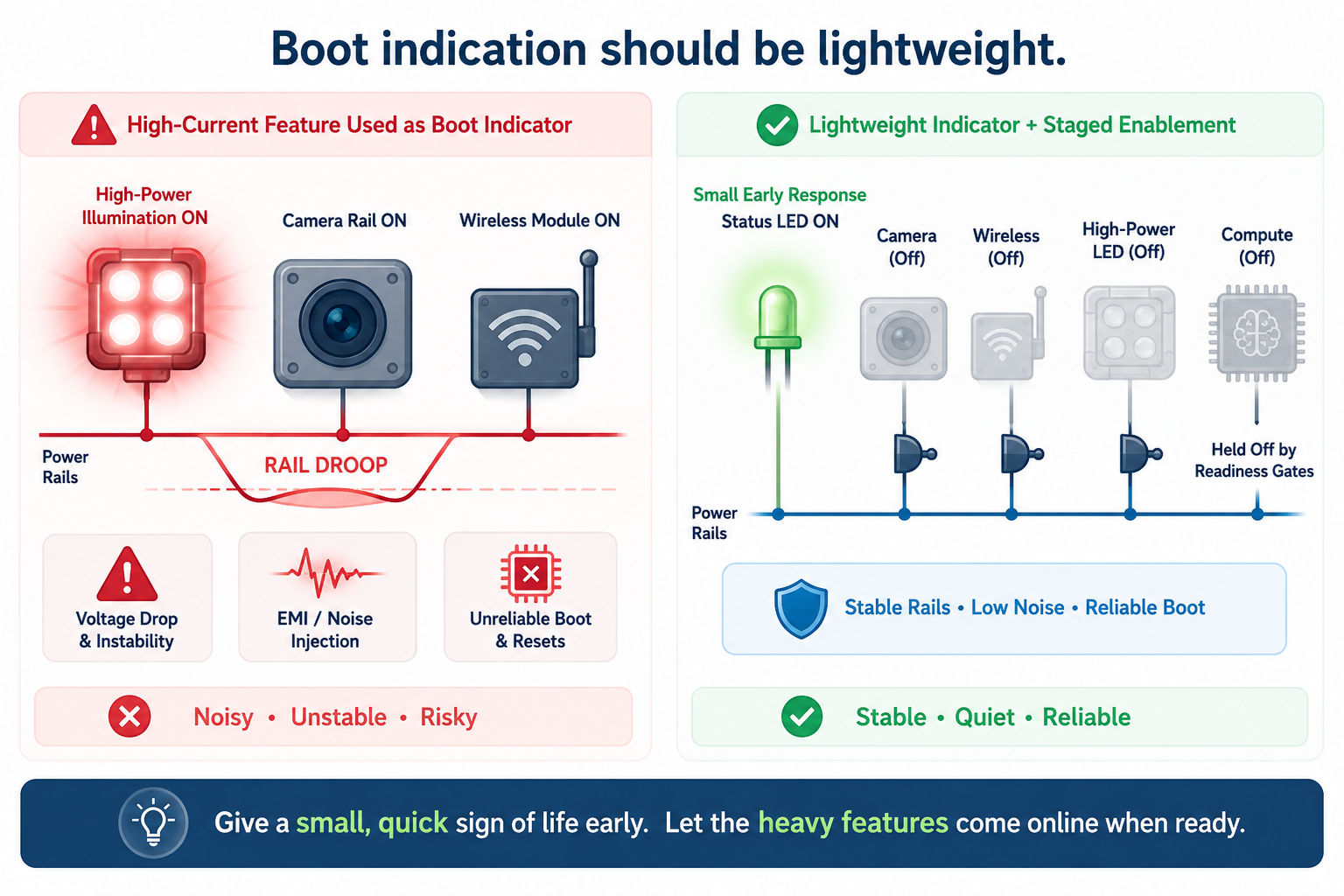
Do Not Use Heavy Features as Boot Indicators
It is tempting to use a major feature as a startup indicator.
Turn on the camera LED.
Pulse an illumination channel.
Start the speaker.
Wake the radio.
Spin up the main processor immediately.
These can make the product feel active, but they also increase startup risk.
Heavy features often introduce inrush current, rail droop, EMI, thermal effects, clock dependencies, and initialization complexity. If these features activate too early, they can interfere with the same startup process they are meant to announce.
In compact multi-sensor products, this becomes especially important.
A high-current illumination path, camera rail, wireless module, or compute subsystem should not be used merely to prove the product has powered up. Those features should wait until power budgeting, reset sequencing, and firmware ownership are valid.
The first response should come from the safest subsystem, not the most visible one.
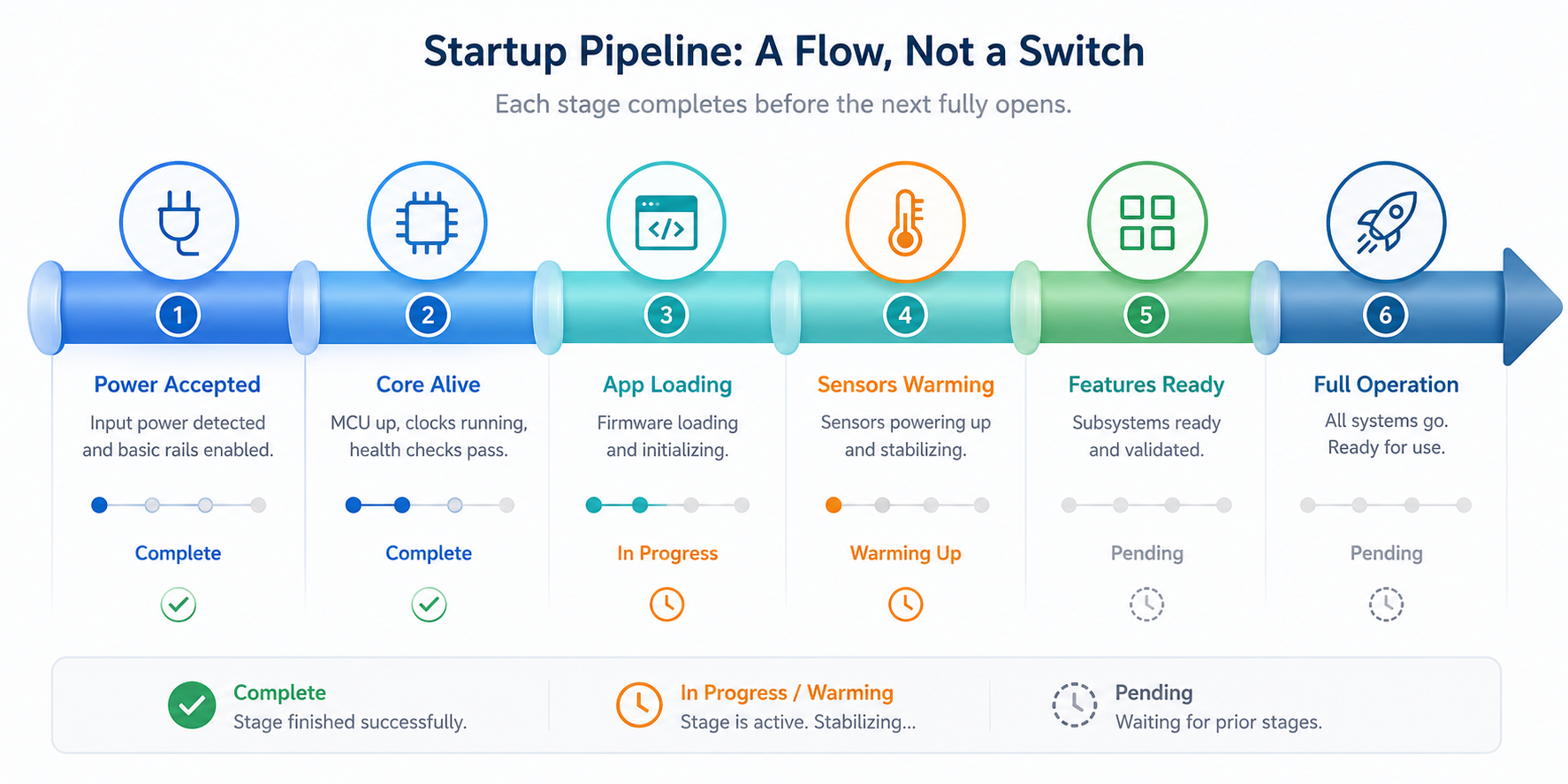
Startup Should Be a Pipeline, Not a Wall
Many products treat startup like a wall.
Nothing happens visibly until everything is ready.
Then suddenly the product becomes active.
This makes the device feel slower than it actually is.
A better startup feels like a pipeline. The system reveals progress in stages:
Power accepted.
Core alive.
Application loading.
Sensors warming up.
Features ready.
Full operation active.
Each stage is honest. Each stage reflects a real electrical or firmware milestone.
This also helps debugging and manufacturing. If the product always shows the same staged startup behaviour, engineers can identify where failures occur. If the device acknowledges power but never reaches sensor-ready state, the issue is different from a board that never reaches core-alive state.
Perceived responsiveness and diagnostics can share the same architecture.
That is the kind of design choice we value at Hoomanely: the user experience and engineering observability should support each other rather than compete.
Electrical Reality Still Owns the Sequence
No matter how much we care about responsiveness, some things cannot be rushed.
Regulators need time to stabilise.
Crystals and oscillators need time to settle.
Reset supervisors need valid thresholds.
Camera sensors need correct rail order.
Level shifters need both sides powered before passing signals safely.
Buses need defined idle states before traffic begins.
Storage needs a known-good state before writes occur.
Ignoring these requirements may make boot look faster for a few prototypes, but it creates intermittent failures later.
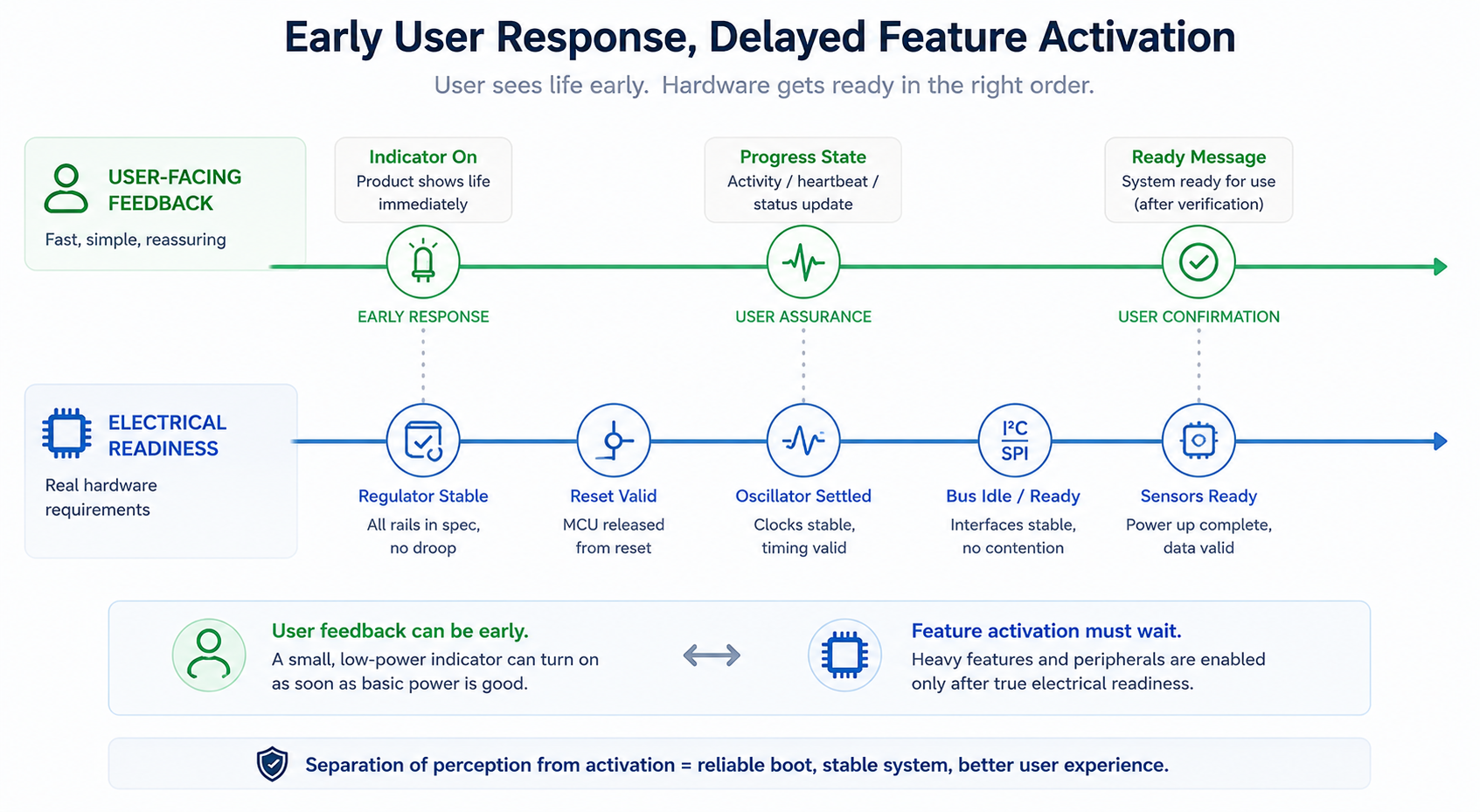
The architecture should therefore define two timelines:
The perception timeline shows what the user sees.
The electrical timeline defines what the hardware is allowed to do.
These timelines overlap, but they are not the same.
A product may show a soft indicator at 100 ms while waiting until 800 ms to enable a sensor rail. It may show a wake state immediately while delaying network activity. It may allow local status before allowing high-current features.
This is not fake responsiveness.
It is honest staged readiness.
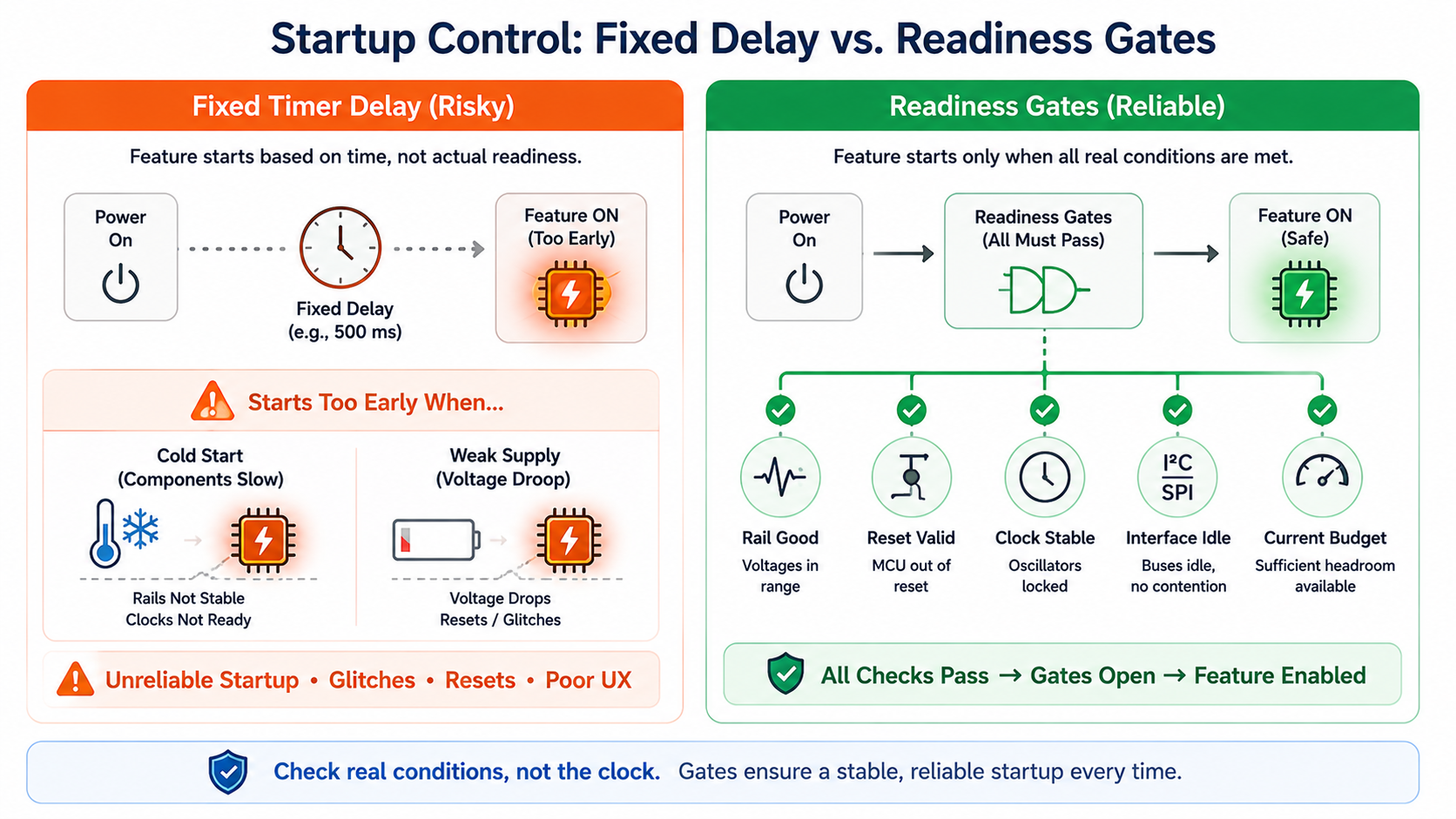
Use Readiness Gates Instead of Fixed Delays Alone
Fixed delays are common in startup code.
Wait 50 ms.
Wait 100 ms.
Wait 500 ms.
Delays are sometimes necessary, but they are a weak substitute for readiness.
A system designed around fixed delays assumes all boards, temperatures, supplies, and components behave identically. Real products do not.
A better design uses readiness gates.
A feature becomes available only when the conditions that matter are actually true:
- rail-good confirmed,
- reset released,
- clock valid,
- interface idle,
- firmware state ready,
- current budget available,
- subsystem acknowledged.
This prevents both early activation and unnecessary waiting.
If a rail stabilises quickly, the system can continue. If it takes longer under cold temperature or a weak input supply, the system waits safely.
Readiness gates make the startup both faster and safer because they remove guesswork.
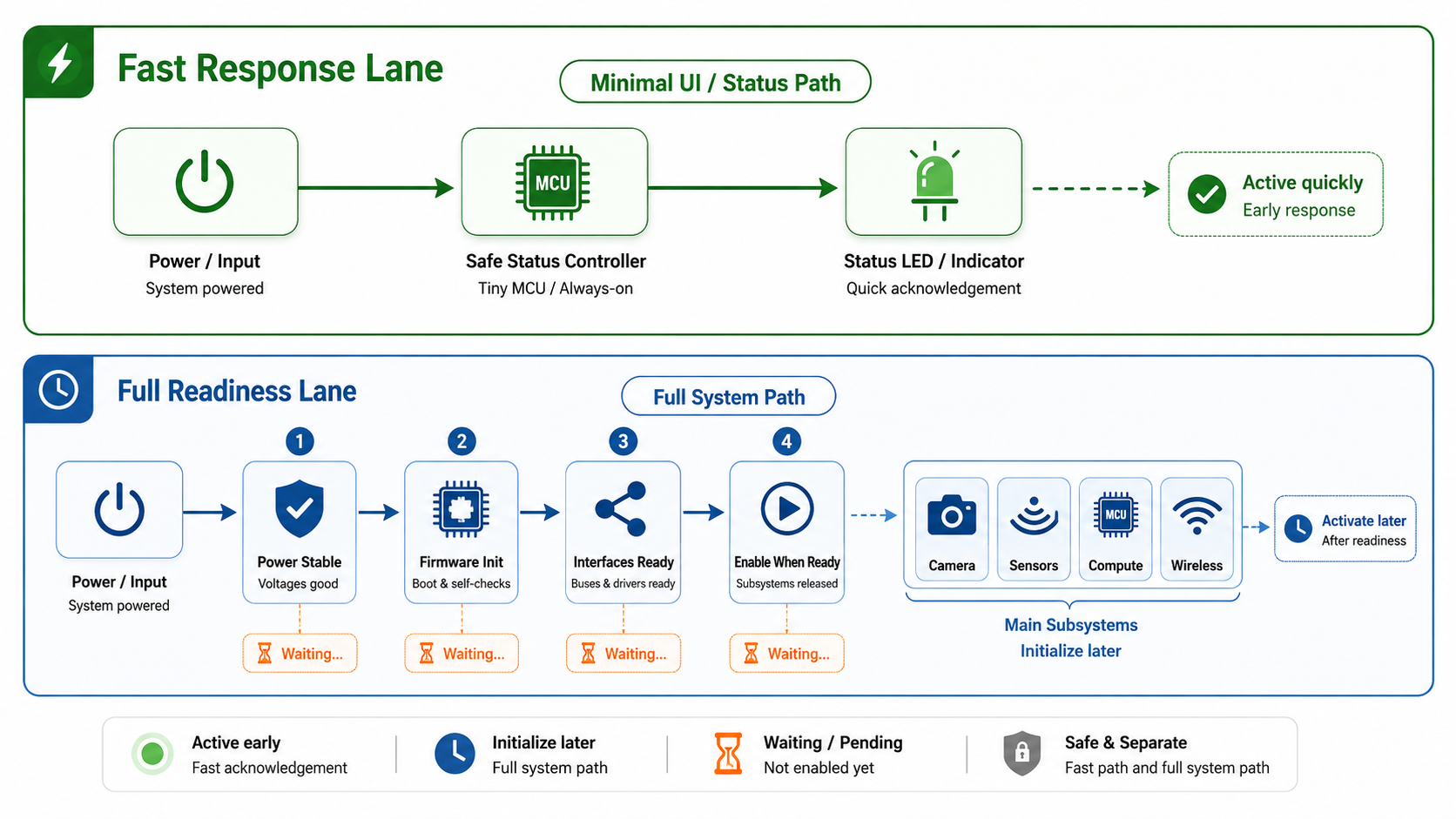
Keep the User Interface Decoupled From Full System Readiness
A product feels more responsive when the user interface is not fully dependent on the heaviest compute path.
This does not always require a dedicated UI processor. Sometimes it is simply a small early-boot state machine, an MCU-controlled status output, or a hardware-driven indicator.
The key is architectural decoupling.
A minimal response path should survive even when larger subsystems are still waking. It should not depend on camera initialisation, cloud connection, sensor calibration, or storage mounting.
This is especially useful during fault conditions.
If a sensor fails, the device should still be able to indicate that it is alive. If the main application is delayed, the product should not appear completely dead. If the system enters a degraded mode, the user should receive some indication rather than silence.
The first response path becomes both a UX tool and a recovery signal.
Feature Availability Should Be Progressive
Not every feature needs to become available at the same time.
In fact, forcing every feature to become ready together often creates worse power and timing behaviour.
A progressive availability model is cleaner.
Basic status becomes available first.
Core control becomes available next.
Low-power sensors become available after rail validation.
High-speed interfaces come later.
High-current features wait until the power budget is stable.
Cloud or compute-heavy features can follow after local readiness.
This allows the product to respond quickly without pretending that all features are immediately ready.
It also protects the hardware from concurrency spikes. Instead of multiple subsystems turning on at once, the system can stagger activation based on electrical priority and user need.
The device feels alive early, but the hardware still receives the time it needs.
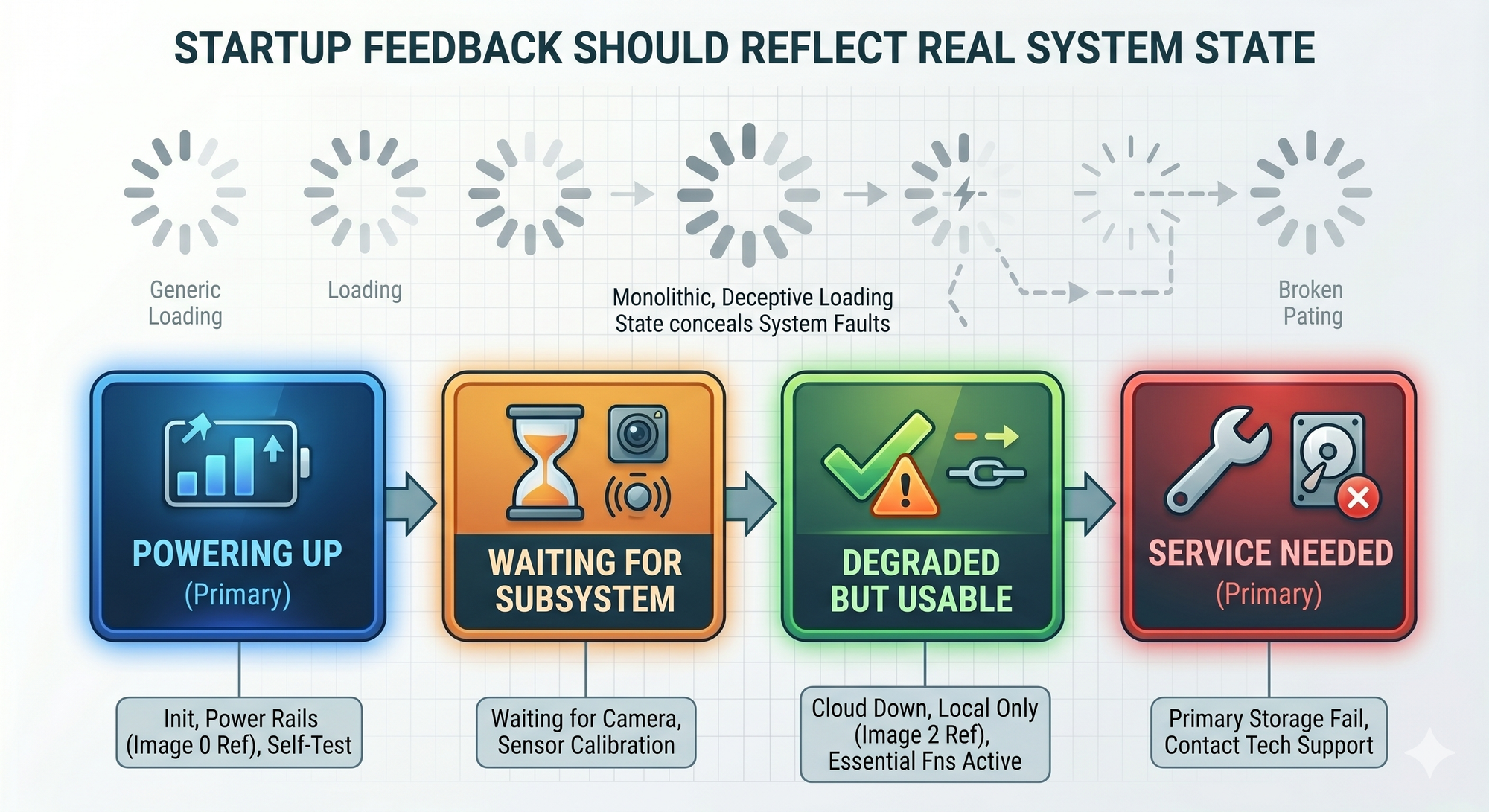
Do Not Hide Real Startup Failures Behind Animation
There is one trap in perceived responsiveness: using animation or indicators to hide real startup problems.
A blinking LED or loading pattern is useful only if it corresponds to actual system progress.
If the product displays the same “starting” behavior during a healthy boot, a sensor failure, a power rail fault, and a firmware hang, the indicator becomes decoration rather than information.
A good startup experience should be informative.
The user does not need engineering-level detail, but the system should distinguish between:
- powering up,
- waiting for a subsystem,
- degraded but usable,
- failed and needs service.
This is also helpful for support. A simple staged indicator can reduce confusion when diagnosing field units.
Responsiveness should not mean pretending everything is fine.
It should mean communicating system state early and clearly.
Hoomanely’s View: Responsiveness Is a Contract
At Hoomanely, we think of power-up responsiveness as a contract between hardware, firmware, and user experience.
Hardware promises not to expose unstable features too early.
Firmware promises to stage initialisation based on readiness, not convenience.
The product experience promises to acknowledge the user quickly without lying about full readiness.
This contract is especially important in modular systems where sensor boards, carrier boards, compute modules, power domains, and communication paths may all wake at different speeds.
A good architecture does not rush them into one artificial “on” event.
It lets each subsystem become ready when it is electrically safe, while giving the user confidence that the product is alive and progressing.
That is the balance.
Fast enough to feel responsive.
Disciplined enough to remain reliable.
Final Thoughts
Making power-up feel instant is not about forcing hardware to boot faster than it safely can.
It is about designing the startup experience around the real electrical sequence.
The product should acknowledge power quickly, but it should not activate heavy features prematurely. It should show progress early, but it should not hide faults. It should feel alive within moments, while still respecting rails, resets, clocks, buses, sensors, storage, and power budgets.
The best embedded products do not make the user wait for every internal detail.
They also do not ignore those details.
They separate perceived responsiveness from full readiness and connect them through a disciplined architecture.
That is how hardware can feel instant without being rushed.
And in real product engineering, that is often the difference between a device that feels polished and a device that only works well on the bench.