Motion Wakes the Mic: Fusing IMU and Audio on a Collar

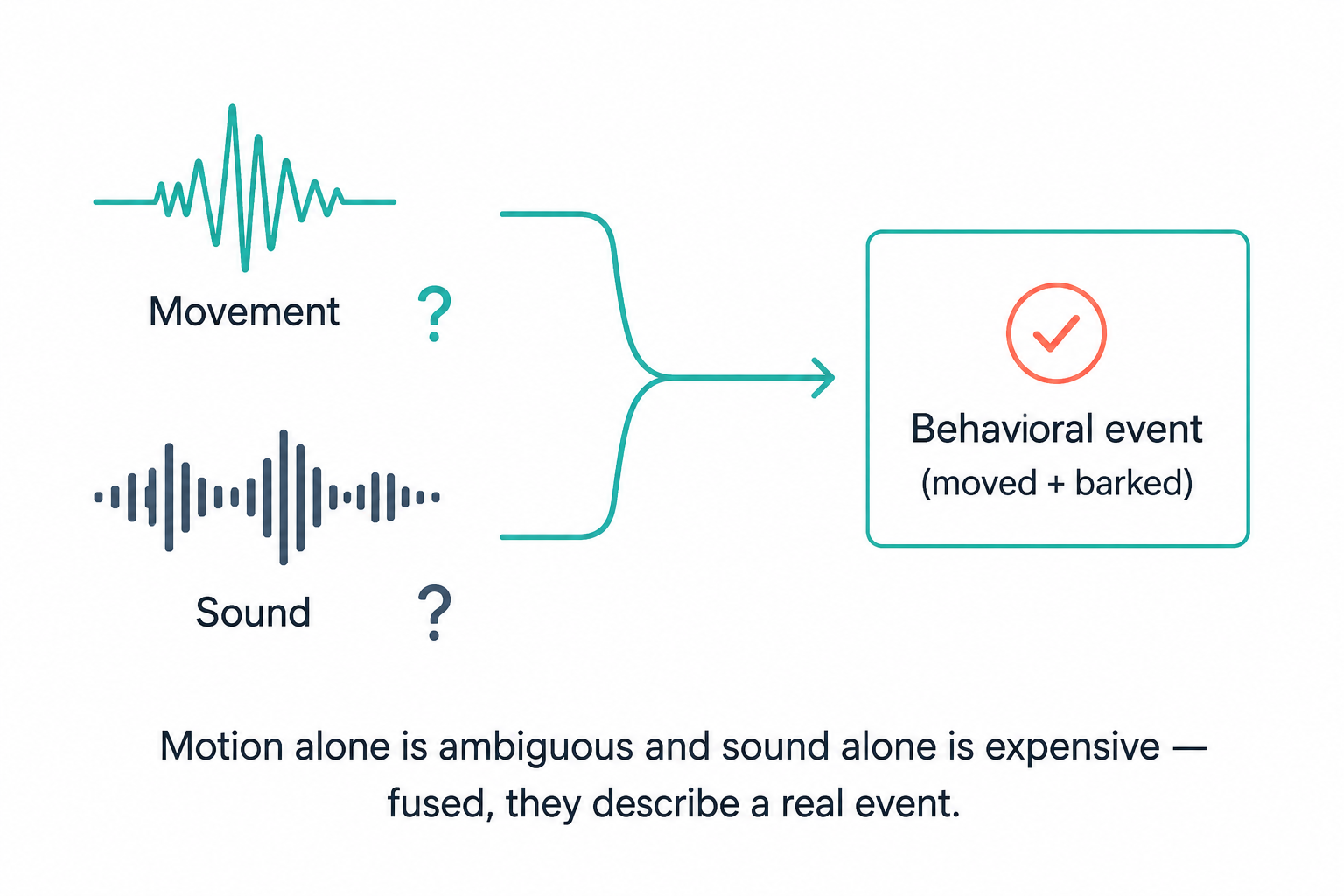
A barking dog tells you something. A lunging, barking dog tells you a lot more. On a battery-powered pet collar, the two most informative senses are motion and sound — but you can't run a microphone flat-out all day, and a motion sensor alone can't tell a bark from a yawn. So our tracker treats them as one system: the inertial sensor watches for movement continuously and cheaply, and when something happens, it wakes the microphone to record a short, context-rich clip. The two streams are then stitched back together by a shared timestamp so the backend sees a single event — "the dog moved, and here's exactly what it sounded like." This post walks through how that motion-triggered, preroll-buffered, time-correlated audio capture actually works in firmware.
The Problem: Two Senses, One Tiny Power Budget
A collar's inertial measurement unit (IMU) is happy to run all day — it's low-power and its motion data feeds the pedometer regardless. A microphone is a different beast. Recording, compressing, storing, and shipping 48 kHz audio is expensive in CPU, flash, and radio time, so it can't be always-on.
The naive fixes both fail. Record continuously and you flatten the battery and drown the wireless link. Record only on a fixed timer and you miss the moments that matter while capturing hours of silence.
There's a subtler trap too. Even if you trigger audio on an event, a microphone that starts recording when it detects the event has already missed the event's beginning — the sharp onset of a bark is over in tens of milliseconds, long before any trigger fires. And once you have a clip and a motion record, you still have to prove they describe the same moment. Getting all of this right is what turns two raw sensors into one behavioral signal.
The Approach: Let Motion Be the Trigger
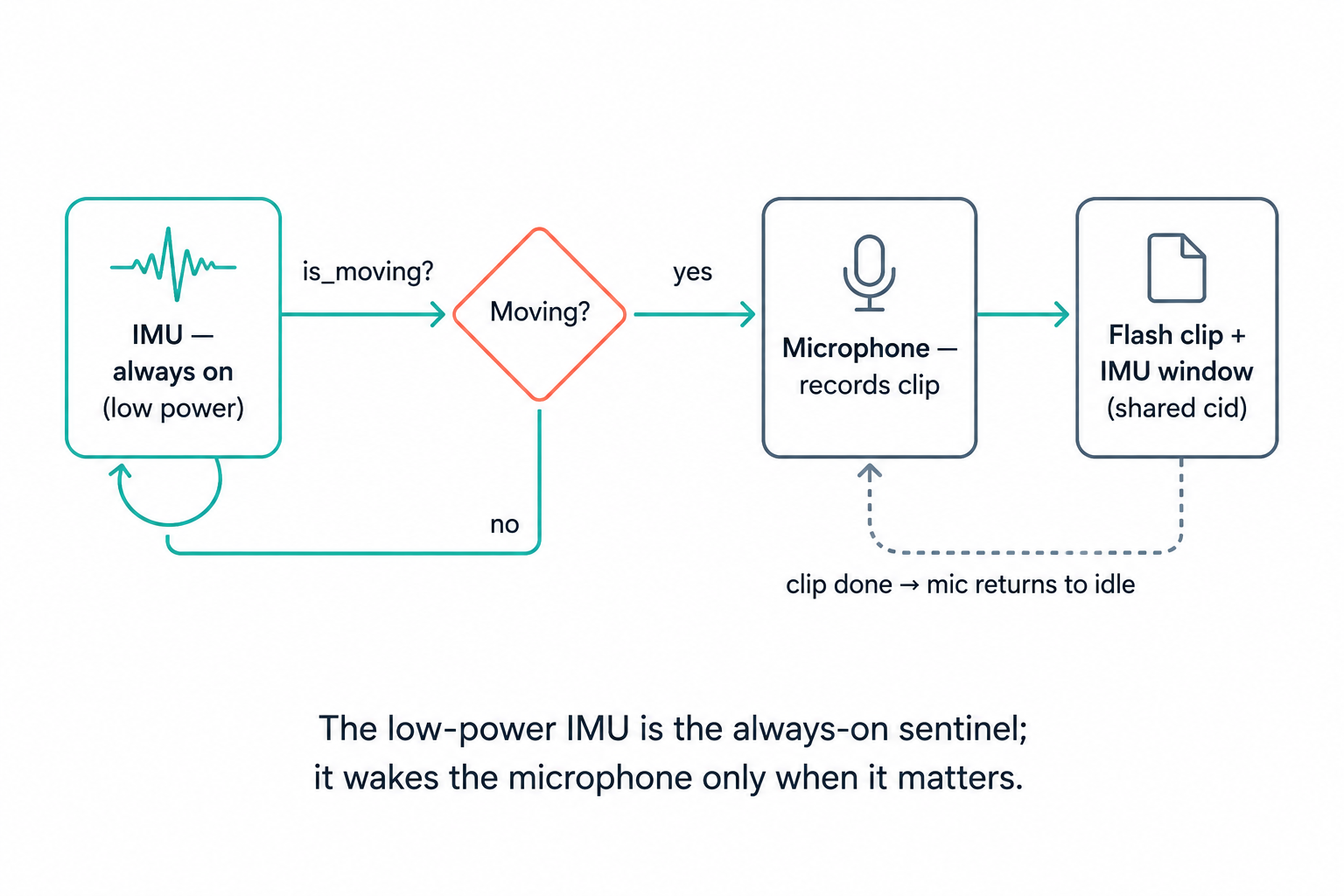
The design principle is simple: the cheap sensor gates the expensive one. The IMU runs continuously and acts as the always-on sentinel; the microphone stays idle until motion arms it. That keeps average power low while ensuring the mic is recording whenever there's something worth hearing.
To make that robust, the motion detector can't just look at raw acceleration magnitude — a collar at rest still reads ~1 g of gravity, and a tilt isn't motion. Instead we track the peak-to-peak swing of the acceleration magnitude over a short rolling window, which captures dynamic movement while ignoring static orientation. A glitch guard then requires the threshold to hold across consecutive reads, so a single noisy IMU sample can't fire the mic on its own:
653 extern "C" bool accelorometer_is_moving(void)
654 {
655 float p2p = accelorometer_motion_p2p();
656 if (p2p < 0.0f) return false;
657 /* Glitch guard: require the threshold to hold for >=2 consecutive reads so a
658 * single duplicate/garbage IMU sample (the stream has occasional ones) can't
659 * arm a clip on its own. is_moving() is polled ~once per audio block. */
660 static int over = 0;
661 if (p2p > ACCEL_MOTION_P2P_G) { if (over < 2) over++; }
662 else { over = 0; }
663 return over >= 2;
664 }
This single boolean — "is the dog moving?" — is the bridge between the two subsystems. The audio capture loop polls it roughly once per encoded audio block and arms a clip the moment it goes true (or when the hub forces a one-shot capture for a labeled dataset).
The Process: Preroll, Arm, and Correlate
Catching the onset with a preroll ring. To solve the "the bark is over before we trigger" problem, the encoder is always writing its most recent compressed audio blocks into a small circular look-back buffer, even while idle. When motion finally arms a clip, we flush that ring into the front of the recording — so the clip begins a couple of seconds before the trigger:
229 static int preroll_flush_to_clip(void)
230 {
231 if (!s_preroll) return 0;
232 int oldest = (s_preroll_head - s_preroll_count + PREROLL_BLOCKS) % PREROLL_BLOCKS;
233 for (int i = 0; i < s_preroll_count; ++i) {
234 clip_write_block(s_preroll[(oldest + i) % PREROLL_BLOCKS]);
235 }
236 return s_preroll_count;
237 }
The cost is tiny — a few kilobytes of heap holding pre-compressed blocks — and the payoff is that the onset that triggered capture sits at the head of the clip, not lost to trigger latency.
Arming and the shared correlation key. When motion (or a forced command) fires, the capture loop opens a clip and, crucially, stamps a capture id (cid) derived from the wall-clock millisecond timestamp — the same clock the IMU stamps onto its own sample frames. It then tells the sensor-frame writer to tag every concurrent IMU frame with that id:
1119 ESP_LOGI(TAG, "clip armed by motion (%.2f g) cid=%llu",
1120 motion_g, (unsigned long long)clip_id);
1121 /* Bound the IMU tagging window to the requested duration: clear
1122 * the capture_id at arm + N s even if clip_close is delayed by
1123 * transfer contention, so the IMU tagged with this cid spans
1124 * exactly the N-second interval, not the record+transfer window. */
1125 cid_deadline_ms = ts_ms + (uint64_t)(target_blocks / AUDIO_BLOCKS_PER_SEC) * 1000ull;
1126 clip_arm_ms = ts_ms;
1127 file_operations_set_capture_id(clip_id); /* tag concurrent IMU frames */
From that moment, the IMU producer writes the cid into every motion frame it emits, so the backend can join the audio clip with the exact window of motion that accompanied it:
283 mpack_start_map(&w, cap_id ? 5 : 4);
284 mpack_write_cstr(&w, "p");
285 mpack_write_cstr_or_nil(&w, pckt_id);
286 mpack_write_cstr(&w, "n");
287 mpack_write_u32(&w, this_seq);
288 if (cap_id) {
289 mpack_write_cstr(&w, "cid");
290 mpack_write_u64(&w, cap_id);
291 }
Notice the discipline around the tagging window. The cid is cleared after exactly the clip's intended duration, even if shipping the clip over the radio is delayed — so the motion tagged with a given clip spans precisely the recorded interval, never the longer record-plus-transfer window. That keeps the fused event clean: the IMU samples sharing a clip's cid are only the ones that happened during the audio.
The Results
The combined behavior is a collar that hears the right things at the right times. Average power stays low because the mic sleeps through stillness; clips are dense with signal because they only open on movement; and each clip arrives with its bark onset intact and a window of synchronized motion attached. A still-but-vocal dog is the one tricky case, which is exactly why the trigger was designed as a hybrid that can also arm on sound — motion is the primary gate, but the architecture leaves room for an acoustic onset.
Just as important, the fusion costs almost nothing. The bridge between subsystems is a single boolean and a 64-bit id; there's no shared buffer to lock, no second clock to reconcile, and no heavyweight message bus. One sensor polls a flag, the other stamps an integer, and the join happens later on a far larger machine. That's the kind of cheap, robust coupling a milliwatt budget demands.
Why It Matters at Hoomanely
Hoomanely is reinventing healthcare for pets — replacing reactive, imprecise care with continuous, clinical-grade monitoring that catches problems early. Our devices form a Physical Intelligence ecosystem: sensors fused at the edge, feeding the Biosense AI Engine that turns raw signals into personalized, preventive insights.
Behavior is where many health issues first surface, and behavior is inherently multimodal. Separation anxiety looks like restless motion and sounds like whining; pain can show up as a change in gait and a change in vocalization. A motion stream and an audio stream analyzed in isolation each tell half the story; correlated by a shared cid, they let the Biosense engine reason about a complete event — what the dog did and what it sounded like, in the same moment.
Our guiding principle is that every signal matters and every detail counts. Waking the microphone with the IMU, capturing the onset with a preroll, and binding the two streams with one timestamp is how we honor that — turning two cheap sensors into a behavioral signal a clinician can trust.
Key Takeaways
- Let the cheap sensor gate the expensive one. An always-on IMU as a motion sentinel keeps the power-hungry microphone idle until there's something worth recording.
- Detect motion, not tilt. Triggering on peak-to-peak swing over a short window — with a consecutive-read glitch guard — separates real movement from gravity and sensor noise.
- Preroll captures the onset. Continuously buffering recent compressed audio and flushing it on trigger puts the bark's beginning at the head of the clip instead of losing it to latency.
- Correlate with a shared key. Stamping audio clips and IMU frames with the same timestamp-derived
cidlets the backend join the two streams into one behavioral event. - Bound the tagging window. Clearing the correlation id after the clip's true duration keeps the fused motion window precise, independent of transfer delays.
Author's Note
This motion-gated audio pipeline runs on the collar-worn tracker that anchors Hoomanely's Physical Intelligence ecosystem. The IMU keeps watch, the microphone captures the moment with its onset intact, and a single shared id ties them together for the Biosense AI Engine. It's a small amount of firmware glue — a boolean and an integer — doing the quiet work of turning motion and sound into one trustworthy picture of how a pet is really doing.