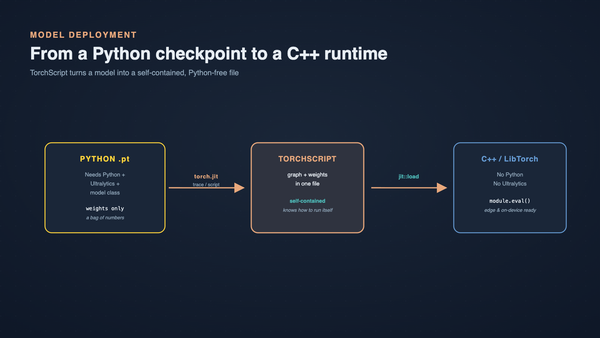
Ports That Compile, Run, and Quietly Lie

A port that compiles and produces plausible output is not the same as a correct port. The hardest bugs in an ML migration don't crash. They degrade gracefully.
After porting the Everbowl device's image and inference pipeline from Python to C++, we discovered three of them. None failed loud. None logged. All passed visual inspection. The pipeline was producing wrong answers for weeks and the test suite couldn't tell.
We weren't moving the math — same models, same weights, same arithmetic. The port was a deliverable change, not an algorithmic one. Which is why what happened next surprised us.
This post is about how three silent divergences slipped past every standard test — and the methodology that finally caught them.
The bugs that didn't fail loud
Three failures. All caught long after they'd been quietly running. The common pattern: nothing alerted on them. Nothing crashed. The output looked roughly right. The downstream consumer of each stage handled the corrupted data gracefully — which is to say, it produced subtly wrong answers without complaining.
Fisheye correction quietly stopped happening. The Python pipeline called OpenCV's undistortion routine to flatten the wide-angle camera output. The C++ port called what looked like the same function. The step still ran. The framing still looked roughly correct. Most of the image showed no visible difference. Only the corners betrayed the bug — and by then, downstream models that depended on edge geometry had been quietly losing accuracy for weeks.
A rotation that looked identical. Camera frames got rotated 90° as part of preprocessing. Python used a NumPy operation; C++ used OpenCV. On square test crops they produced visually identical outputs. The first time a rectangular frame went through, accuracy collapsed downstream — and the bug surfaced as "the model got worse," not "the rotation is broken."
A temperature overlay that vanished. A thermal reading is drawn onto each frame as text. Python rendered it with Pillow. C++ used OpenCV's text primitive. Both produced an annotation in roughly the right place. The rendered quality differed enough that downstream OCR — tuned against the Python output — started returning different values. Nothing in the chain noticed.
Why this class of bug is invisible
ML pipelines fail gracefully. Wrong-but-plausible output is still output. There's no segfault, no exception, no log line — the next stage consumes the corrupted data and produces its own slightly-degraded result, and so on down the chain. By the time the degradation is visible to a human, the root cause is several layers upstream and the signal has been smeared by everything that ran after it.
Unit tests aren't built to catch this. They check interfaces. They assert that a function returns the right type, handles edge cases, doesn't crash on bad input. They don't assert that two implementations of "the same" operation produce numerically equivalent results. And the assumption that they do — because the function is called the same thing in the same library — is the trap.
The deeper truth: the Python bindings of these libraries are not the same as the C++ APIs. Same name. Same project. Different behavior.
The Python binding makes choices the C++ API doesn't:
- Default flag values the C++ caller has to specify explicitly.
- Implicit memory-layout conversions between NumPy arrays and the library's native types.
- Convenience behaviors — anti-aliasing, automatic type promotion, sensible argument ordering — that the C++ API treats as the caller's responsibility.
None of these are bugs. They're conveniences. They become bugs the moment you assume a port inherits them.
The methodology that caught them all
Three bugs of the same shape was enough. The test suite couldn't be trusted to catch the next one. The fix wasn't a better test. It was a different kind of test.
Checkpoint every stage of the working Python pipeline. Not just inputs and outputs — every intermediate frame, every mask, every tensor one stage hands to the next. On a fixed input set, those checkpoints become the golden reference.
Run the same inputs through the C++ pipeline. Capture the equivalent intermediates at every stage.
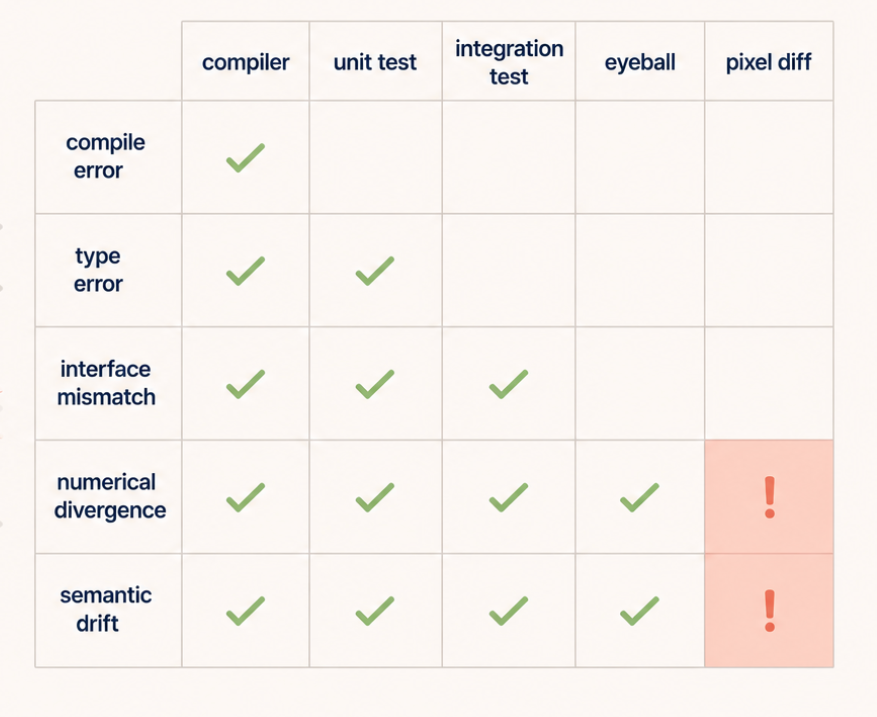
Numerically diff each stage. Not visually. A pixel-level absolute-difference computation with an epsilon threshold to absorb harmless floating-point drift. Anything above the threshold is a real divergence.
Localize the bug by the first divergent stage. This is the part that pays for itself. Endpoint diffs tell you something is wrong somewhere. Per-stage diffs tell you exactly which operation introduced the divergence. Each of the three bugs would have taken days to find from the endpoint alone. With per-stage diffing, each was localized in under an hour.
The methodology is conceptually trivial. Operationally, it changes the migration from "ship it and hope" to "every stage proves itself against a known-good reference."

What the fixes actually revealed
The three bugs looked different on the surface — one in geometry, one in pixel layout, one in text rendering. They reduced to the same root cause: the Python code was relying on behavior that wasn't part of any documented contract.
The undistortion bug: a default flag the Python binding sets implicitly was being left at its (different) default in C++. The rotation bug: the Python operation assumed row-major NumPy semantics that the OpenCV C++ Mat doesn't share by default. The result was a rotation that produced the same pixel data in a different memory layout — invisible on square frames, catastrophic on rectangular ones. The overlay bug: Pillow anti-aliases text with sub-pixel positioning by default; OpenCV's text drawing doesn't. The pixel-level statistics of the annotated region were different enough to throw off downstream OCR tuned against the Python output.
In each case, the Python code wasn't doing anything wrong. It was doing something more than the C++ port could observe by reading the code. The behavior was in the binding, not the call.
What we'd tell other teams
- A passing port isn't a correct port. "Compiles and runs" tells you almost nothing about whether the math is the same. Numerical parity is a separate test target.
- Pixel-diff the stages, not the endpoints. Endpoints tell you there's a bug. Stages tell you where.
- "Same library" across languages is a polite fiction. Re-derive every default flag, every memory-layout assumption, every rendering primitive. Trust nothing inherited.
- Add golden-image regression on day zero. Not after the first bug. By the first bug it's already in the field.
- Don't trust your eyes. Every bug in this post passed visual inspection. The next ones will too.
The thing to internalize: a Python-to-C++ ML port isn't really a port. It's a rebuild against an unspecified contract you have to re-derive by hand. The library names match. The behavior doesn't.