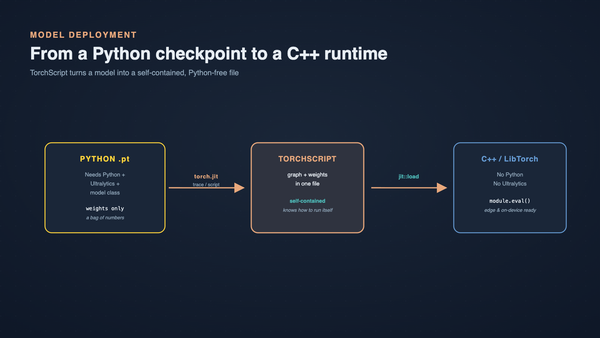
What Porting an ML Pipeline to C++ Actually Changed
Every Everbowl device sits in someone's home. It watches a dog eat, drink, move, and breathe — tracking feeding patterns, drinking patterns, eye temperature, and ambient sound to keep a quiet, continuous check on the pet's health. It is expected to run reliably for years, update silently in the background, and never bother the owner.
For a long time, the brain of that device was a Python pipeline. The math was fine. The models produced good outputs. Inference quality was not the problem.
The problem was that every fleet rollout was a slow-motion ordeal. Some percentage of devices ended up in a half-updated state. Cold starts took seconds of Python imports. Disk filled with virtualenvs. The application code itself was reliable, but the artifact we were shipping wasn't.
That's the lesson this post is about. The bug was never in the model. The bug was that we were shipping a runtime — and a runtime is not the same kind of thing as an app.
What "shipping Python" actually means
A Python application is rarely just code. It's an interpreter, a virtual environment, a tree of pip-installed wheels, and — often — compiled native extensions that have to match the device's exact architecture.
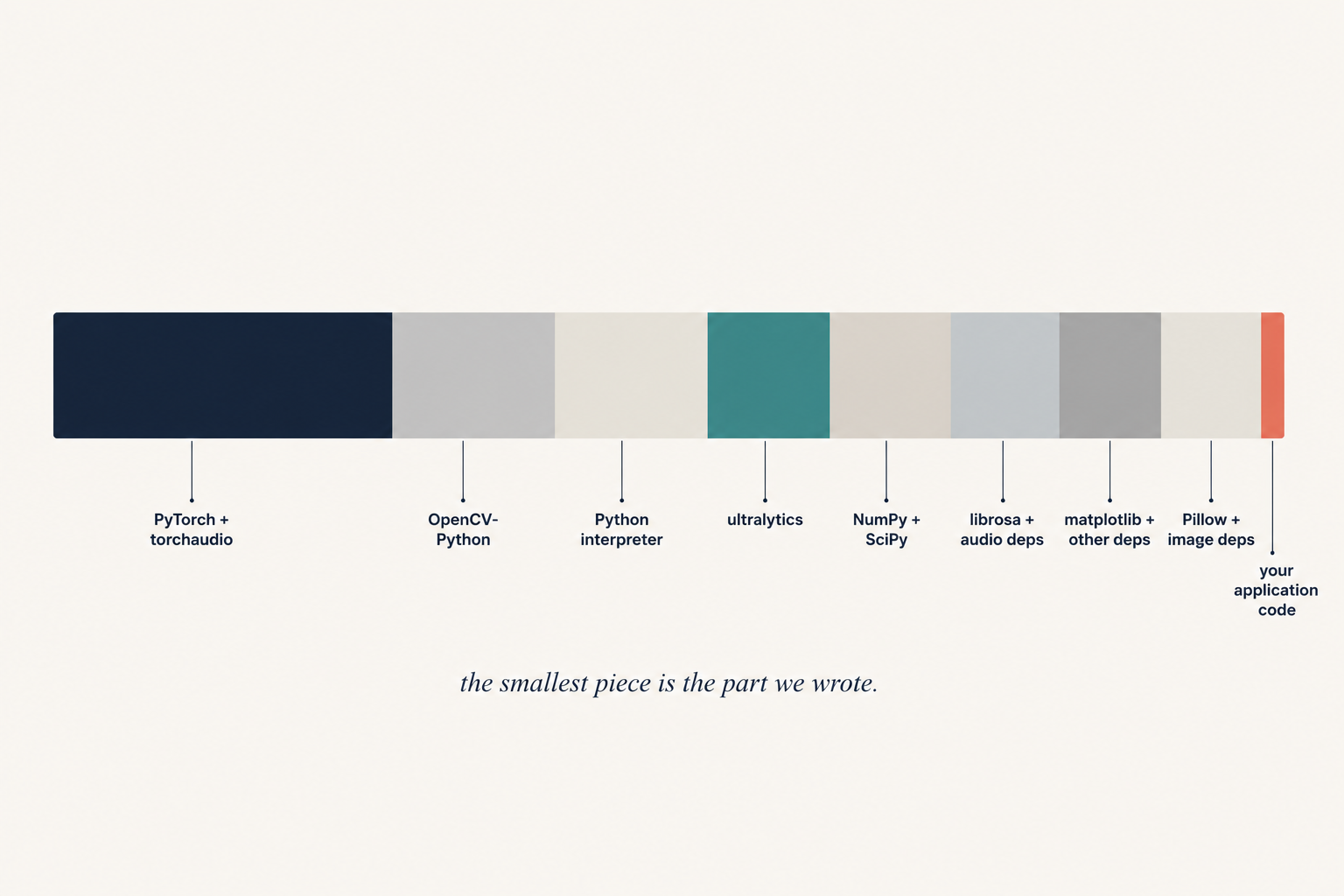
Our pipeline's dependency list read like a research notebook: NumPy, OpenCV, Pillow, PyTorch, torchaudio, librosa, SciPy, scikit-learn, matplotlib, sounddevice, webrtcvad, rawpy, psutil, requests, ultralytics. Each carried its own transitive native dependencies. The model weights themselves — the actual machine learning part — were a rounding error next to everything else.
For research code, this is fine. Pip resolves it, the engineer runs it, the result is correct, everyone is happy. For a fleet of devices in customers' homes, every one of those files was something that could be missing, corrupt, drift between machines, or refuse to import cleanly after a minor version bump somewhere upstream.
What broke at fleet scale
Three categories of pain. None were performance problems in the academic sense. All were operational — the kind of thing you don't notice until you're deploying to many devices instead of one.
Versioning that doesn't stay frozen. A pip lockfile is a promise the index doesn't always keep. Wheels get re-uploaded. Platform-specific builds resolve differently on slightly different ARM variants. The Pillow that built on our CI host was not always byte-identical to the Pillow that resolved on a particular device. With enough devices, "the same code" stops meaning the same code.
Updates that aren't atomic. A Python deploy meant rsyncing files, sometimes recreating the venv, occasionally recompiling native extensions in place. Any disk pressure or network hiccup mid-install left a device in a state nobody could reason about. Half-updated devices are worse than non-updated ones — you can't even roll back cleanly, because you don't know what you're rolling back from.
The import tax. Importing the ML stack on a constrained device takes seconds, not milliseconds. The Everbowl wakes in response to sensor triggers; every spawn paid the full Python import cost before doing a millisecond of useful work. That's a latency floor you can't optimize past without leaving the runtime entirely.
The shape of the alternative
The fix was conceptually simple and operationally large: stop shipping a runtime. Ship binaries.
The entire pipeline was ported to C++. OpenCV was linked statically. libtorch carried the ML inference. Each stage of the original Python pipeline — demosaicing, thermal processing, image inference, event enqueueing, file registration, upload — became a small, single-purpose native binary. Each does exactly one thing, can be invoked independently, and can be tested in isolation.
The deployment artifact stopped being a directory and started being a tarball you can checksum. A device is either on version N or it isn't. There is no half-state. There is no "did the venv finish recreating itself" question to investigate. There is no transitive dependency surface to drift.
The architecture didn't change. The pipeline stages are the same. The event contracts are the same. The storage queue, the upload protocol, the trigger semantics — all preserved. What changed was how each stage gets onto the device.
What it bought us in production
The wins were dramatic — and almost entirely operational:
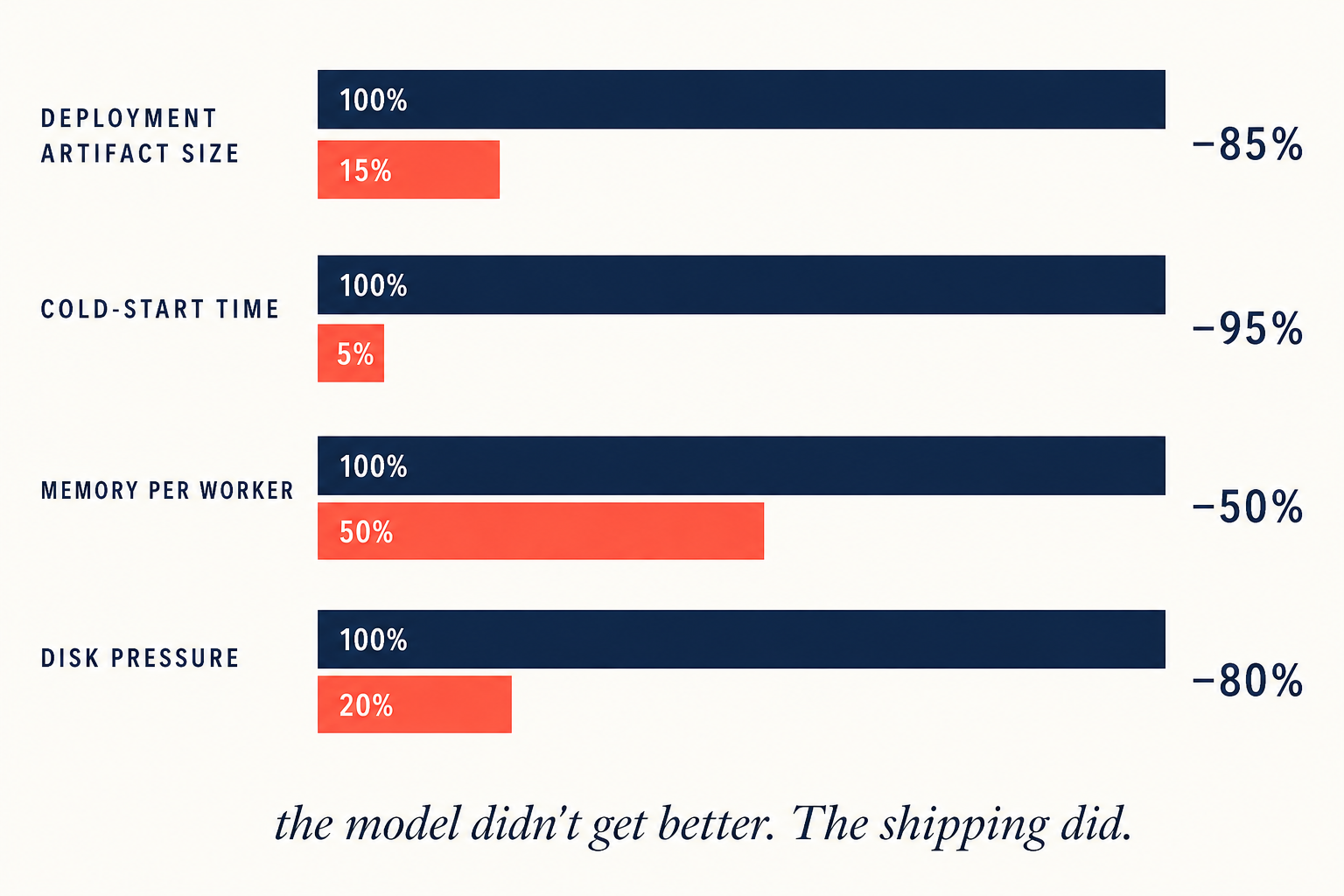
- Deployment artifact size: roughly 85% smaller. The interpreter and its dependency surface are gone; only the application and the libraries we explicitly chose remain.
- Cold-start time: roughly 95% faster. Loading a native binary and its statically-linked OpenCV is not in the same league as importing the Python ML stack from scratch.
- Memory footprint per worker: substantially lower. Each Python worker carried a fresh interpreter heap; native binaries share state through the OS in ways Python can't.
- Disk pressure: the venv plus its wheels was a meaningful fraction of available storage on the device. Reclaiming it changed what we could keep in the offline event queue before being forced to drop data.
- Versioning visibility: "what version is this device on?" became a question with a one-line answer. Fleet reporting went from "mostly the same" to "exactly this."
The recurring theme across every metric: none of the wins were about the math. Inference accuracy was unchanged. Raw inference latency improved modestly — the underlying math was already running through optimized native code beneath Python's surface — but the transformative gains were upstream of the model entirely.
What it didn't fix
Worth being honest about what going native didn't do.
It didn't make the model more accurate. Same weights, same outputs, same thresholds.
It didn't make inference dramatically faster on its own. The math was already C-bound underneath Python; we got a clean improvement on startup and worker spawn, but the inference hot path itself moved only modestly.
It also introduced new costs: longer build times, harder cross-compilation, a different debugging story for engineers used to interactive Python. Some things that used to be a one-line script became a multi-hour exercise in build flags. None of that is free.
The point isn't that native is universally better. The point is that for a fleet device, the deliverable is not the same shape as the algorithm. Optimizing the algorithm without optimizing the deliverable is a category mistake — and one that's easy to make, because the algorithm is the part everyone is paid to think about.
What we'd tell other edge teams
- At the edge, deployability is a feature. A pipeline that runs in 50 ms but takes 10 minutes to install reliably isn't actually fast.
- The runtime is part of the deliverable. Treat the interpreter and its dependencies as application surface, not as ambient infrastructure.
- One artifact, one version. Atomic deployments require atomic artifacts; you can't rsync a guarantee.
- "It works on my machine" gets worse with fleet size. A thousand devices is a thousand machines that all need to agree — and they won't unless your artifact makes disagreement impossible.
- Optimize the boundary, not just the inner loop. Most of the wins from going native were upstream of the math. The math was usually fine.
- Use Python where Python belongs. Research, prototyping, server-side glue. Not the binary you ship to a device sitting on someone's kitchen counter.