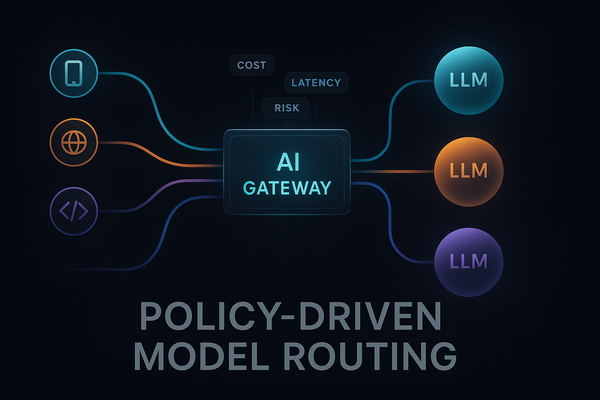
Software
Shadow RAG: Observation Layer
If you’ve ever shipped a RAG system into production, you already know the uncomfortable truth: these systems don’t fail dramatically. They fail quietly. No alarms. No error stacks. No catastrophic crashes. One day the answers simply aren’t as sharp as they used to be. The assistant feels