DMA-First Pipelines: Let Models Wait, Not Sensors


Introduction
Most edge AI pipelines are accidentally model-first. We optimize inference time, shave milliseconds off convolution layers, and debate INT8 versus INT4—while silently dropping sensor frames upstream. By the time the model runs, the data it sees is already compromised.
On constrained hardware like STM32-class processors, this mistake is expensive. Sensors don’t wait. Cameras keep streaming. DMA keeps filling buffers. And if your pipeline isn’t designed around that reality, you lose data long before YOLOv8n-seg even gets a chance to run.
In this post, we walk through a DMA-first pipeline design we used to run YOLOv8n segmentation on an STM32 processor, why we chose to let the model wait instead of the sensor, and what changed when we flipped that priority. We’ll look at sensor data loss, model idle time, and end-to-end latency—numbers that actually matter on edge devices.
The Hidden Cost of Model-First Pipelines
A typical edge vision pipeline looks harmless:
- Capture frame
- Copy frame to RAM
- Preprocess
- Run model
- Postprocess
The assumption is simple: the model drives the system. In reality, the sensor does.
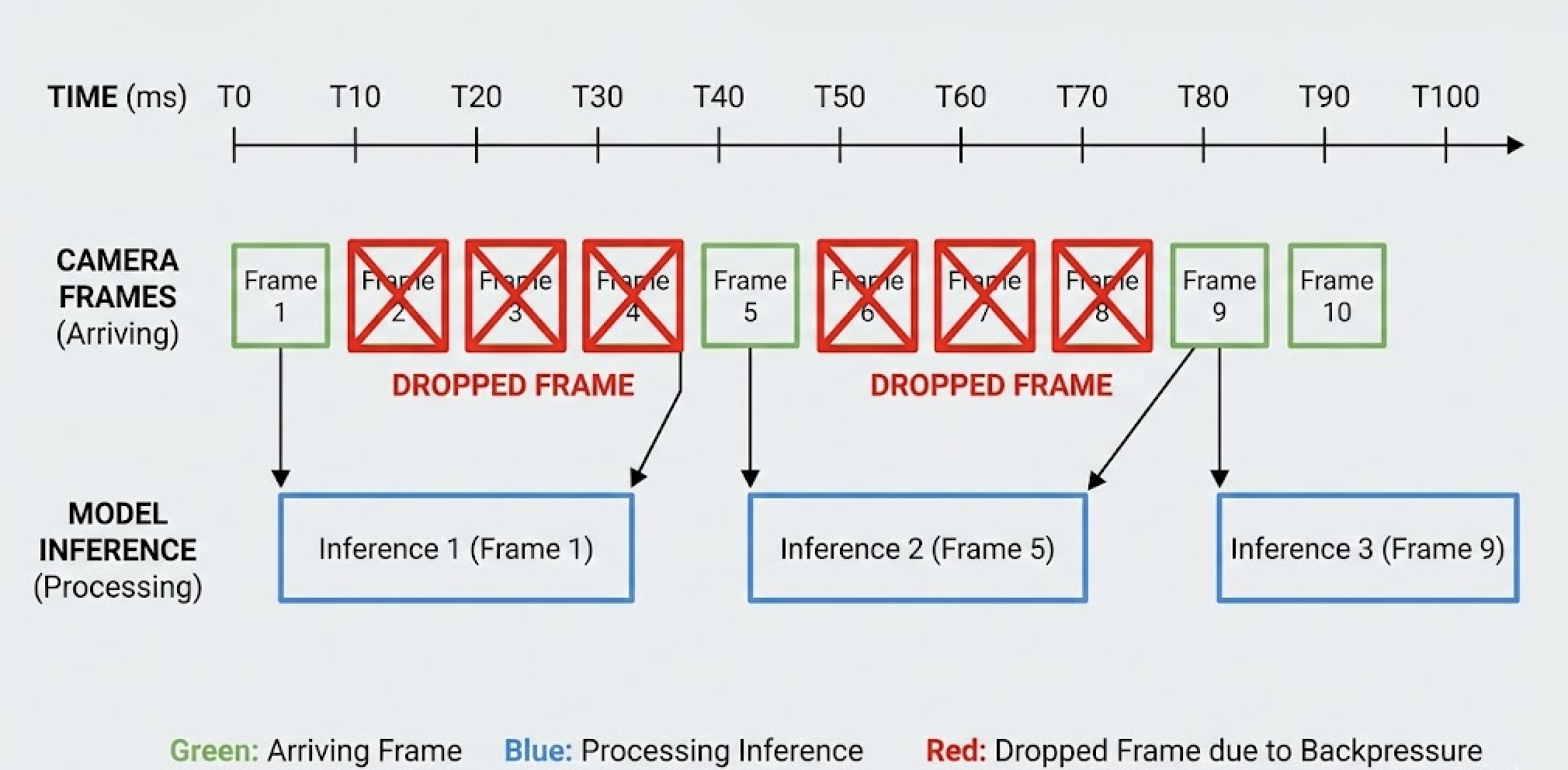
On STM32, camera peripherals stream continuously. DMA writes pixel data whether your CPU is ready or not. If inference takes longer than a frame period and buffers aren’t managed correctly, one of two things happens:
- Frames get dropped silently
- DMA overwrites buffers still being processed
In early tests, our YOLOv8n-seg model appeared stable. FPS looked fine. But segmentation masks would randomly miss objects. The bug wasn’t in the model—it was upstream. We were losing sensor data before inference even began.
Sensor-Priority Thinking
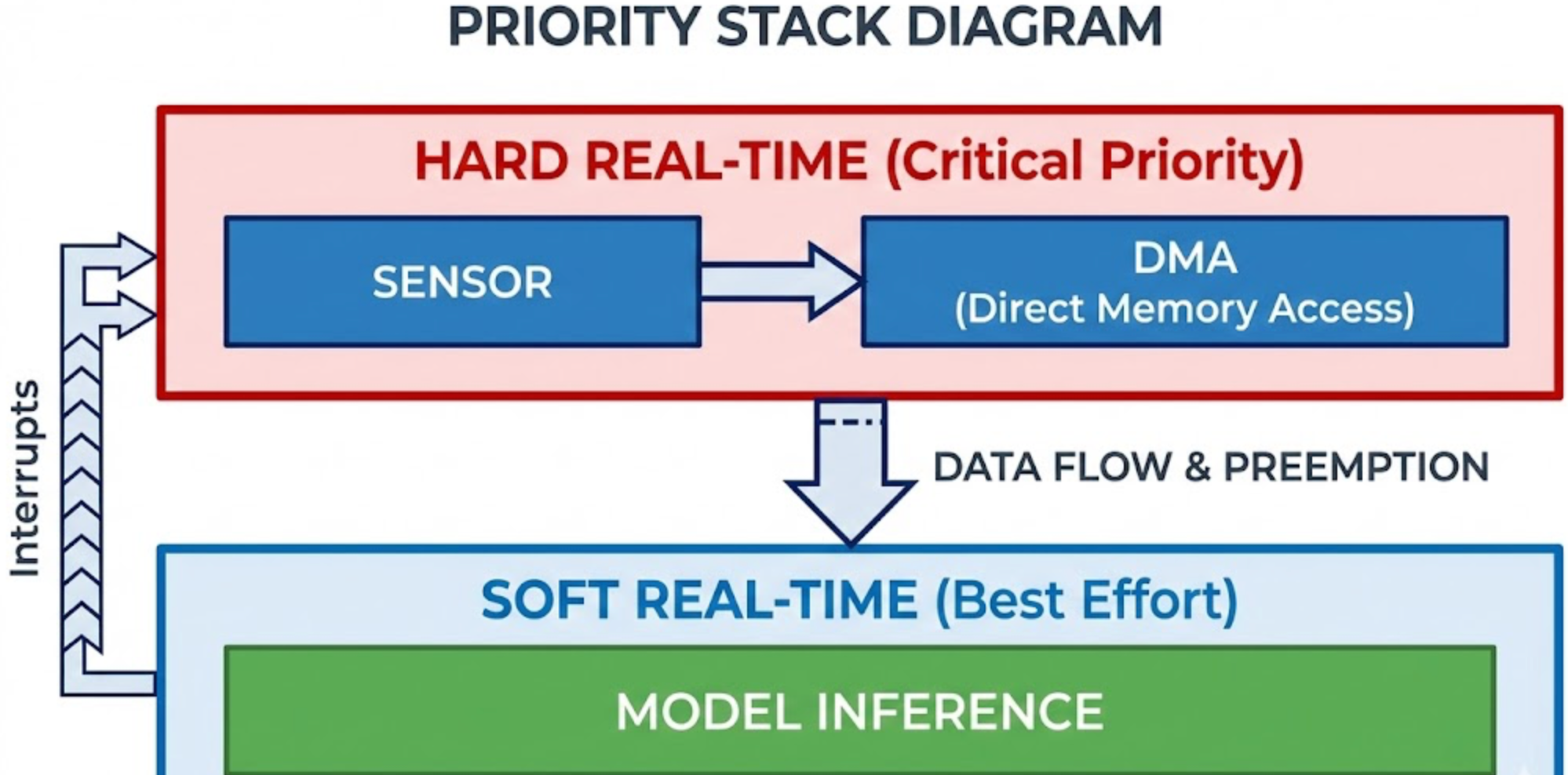
The key shift was conceptual: treat sensors as real-time, models as best-effort.
Sensors are deterministic. They produce data at fixed intervals. Models are variable. Their runtime fluctuates based on cache state, memory contention, and background tasks.
So instead of asking, “How fast can the model run?” we asked:
- How do we never block DMA?
- How do we never overwrite unread sensor data?
- How do we make the model consume data when available, not demand it on schedule?
This is what we mean by DMA-first pipelines.
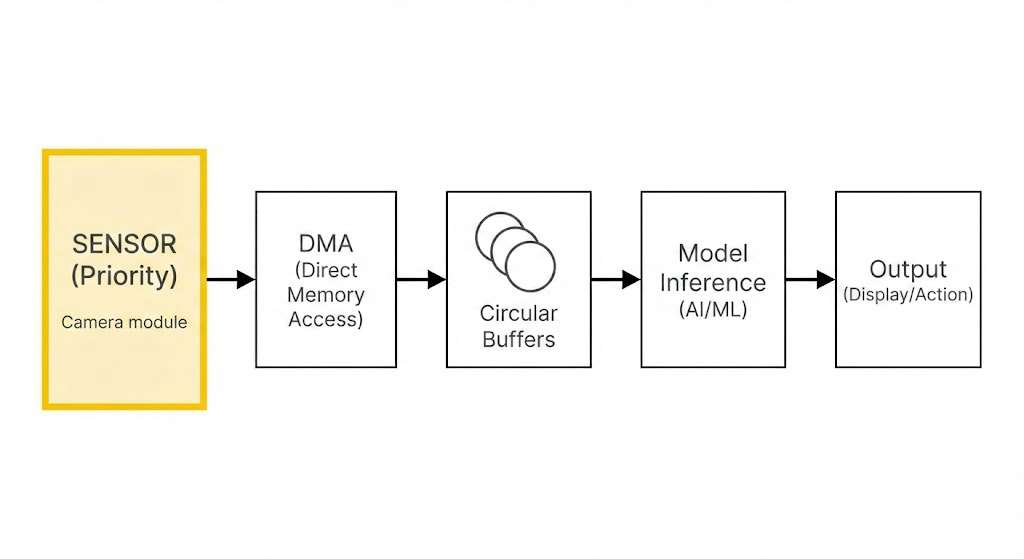
DMA-First Pipeline Architecture
Here’s the architecture we settled on for YOLOv8n-seg on STM32:
1. DMA-Owned Circular Buffers
Camera frames land directly into a ring buffer via DMA. The CPU never copies raw pixel data. DMA writes, CPU reads—never the other way around.
We used:
- 3–4 frame circular buffers
- DMA half-transfer and full-transfer interrupts
- Explicit buffer state flags: FREE → FILLING → READY → CONSUMED
DMA is always allowed to advance to the next free buffer. If none are available, the oldest READY buffer is dropped, not the incoming frame.
This single rule eliminated unpredictable corruption.
2. Decoupled Inference Scheduling
Inference is triggered only when a buffer is marked READY.
No blocking waits. No tight loops checking flags. The model task simply sleeps until signaled.
If inference is slow, buffers queue up. If buffers fill, old data is discarded—but always intentionally.
This means:
- Sensor timing stays stable
- DMA never stalls
- Model latency becomes variable, but predictable
3. Zero-Copy Preprocessing
YOLOv8n-seg preprocessing (resize, normalize) was done in-place or into small scratch buffers, never full-frame copies.
Key tricks:
- Line-by-line DMA reads for resize
- Fixed-point normalization
- Reusing scratch buffers across frames
This kept memory bandwidth low and avoided cache thrashing.
Measuring What Actually Matters
We tracked three metrics throughout development:
1. Sensor Data Loss %
Percentage of frames dropped before inference.
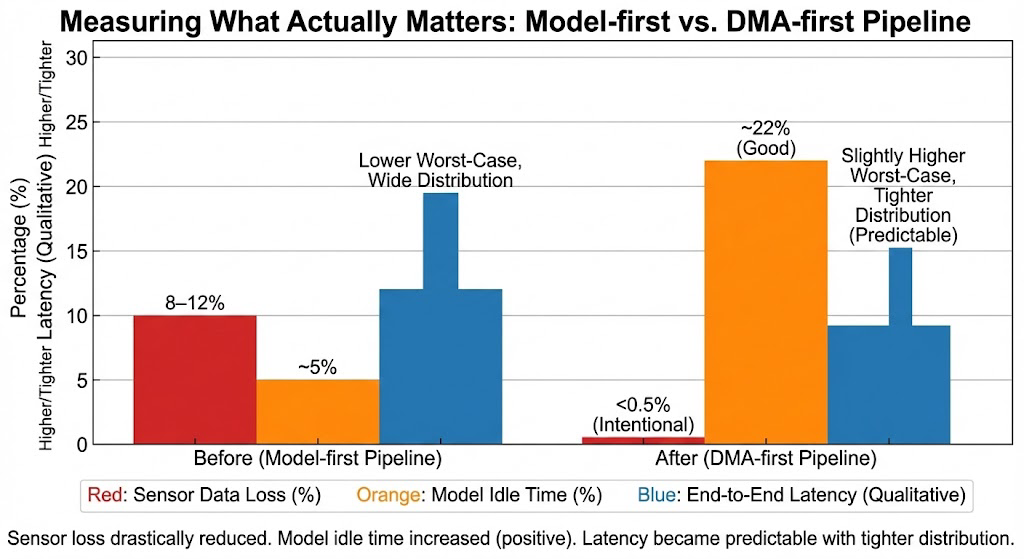
- Model-first pipeline: 8–12% loss under load
- DMA-first pipeline: <0.5% (intentional drops only)
This alone explained most of the visual instability we saw earlier.
2. Model Idle Time %
Time the model spent waiting for data.
- Increased from ~5% to ~22%
- This is good. Idle means the model is not blocking the system.
3. End-to-End Latency
Time from sensor exposure → segmentation output.
- Slightly higher worst-case latency
- Much tighter latency distribution
The system became predictable, which matters more than raw speed.
Why This Matters for YOLOv8n Segmentation
Segmentation is sensitive to partial frames and timing jitter. A missed frame doesn’t just reduce FPS—it breaks temporal consistency.
With DMA-first design:
- Masks stopped flickering
- Edge artifacts reduced
- Debugging became easier because failures were deterministic
YOLOv8n-seg didn’t change. The pipeline did.
Common Pitfalls
A few lessons we learned the hard way:
- More buffers isn’t always better: increases memory pressure
- Never let DMA and CPU write the same memory
- Avoid frame-locked inference loops
- Measure drops explicitly—don’t infer from FPS



