How Edge AI Is Redefining Real-Time Intelligence


How AI models are shrinking without losing their minds.
Many of our real-time models - from detecting dog motion to analyzing eating patterns - run directly on embedded systems.
At Hoomanely, we combine lightweight CNNs (like MobileNet) with quantization and pruning to achieve low-latency inference without sacrificing reliability. The ability to process data locally makes our smart bowl and camera systems faster, private, and power-efficient.
The smarter the edge, the more responsive and trustworthy our pet-tech becomes. Models that once lived comfortably on cloud servers are being pushed onto tiny edge devices: drones, wearables, cameras, and IoT sensors. The challenge? Deliver real-time intelligence without the luxury of GPUs or large memory.
This post walks through edge inference - how models are optimized to run efficiently on limited hardware. We’ll explore lightweight architectures like MobileNet, and optimization techniques such as quantization, pruning, and knowledge distillation that make AI possible in the wild.
What Is Edge Inference Anyway - And Why Do We Need It?
Imagine fitting AI intelligence into something as small as a dog bowl - that’s edge inference in action. It means running models right on local devices instead of sending data to the cloud, giving gadgets like cameras, drones, and pet sensors the ability to act on their own.
Why does this matter? Because milliseconds count. A drone can’t wait for the cloud to decide where to turn, and your dog’s health tracker shouldn’t need Wi‑Fi to notice a change in eating habits. Edge inference lets devices decide where the action happens - fast, private, and in real time.
What makes it powerful:
- Low latency: Real‑time response without waiting on servers.
- Privacy: Sensitive data (like video or health patterns) never leaves the device.
- Offline capability: Keeps working even when the network drops.
- Energy efficiency: Less transmission means longer battery life.
The challenge? Edge devices live with tight compute, memory, and power budgets. Building AI that thrives under those limits takes smart architectural design and some serious optimization tricks.
Lightweight Model Architectures
MobileNet: Efficiency by Design
When you think of AI on small devices - like a camera that recognizes your dog or a drone that navigates obstacles - it’s probably powered by something like MobileNet. Built by Google, MobileNet became the go-to blueprint for edge inference because it rethought how convolutions should work.
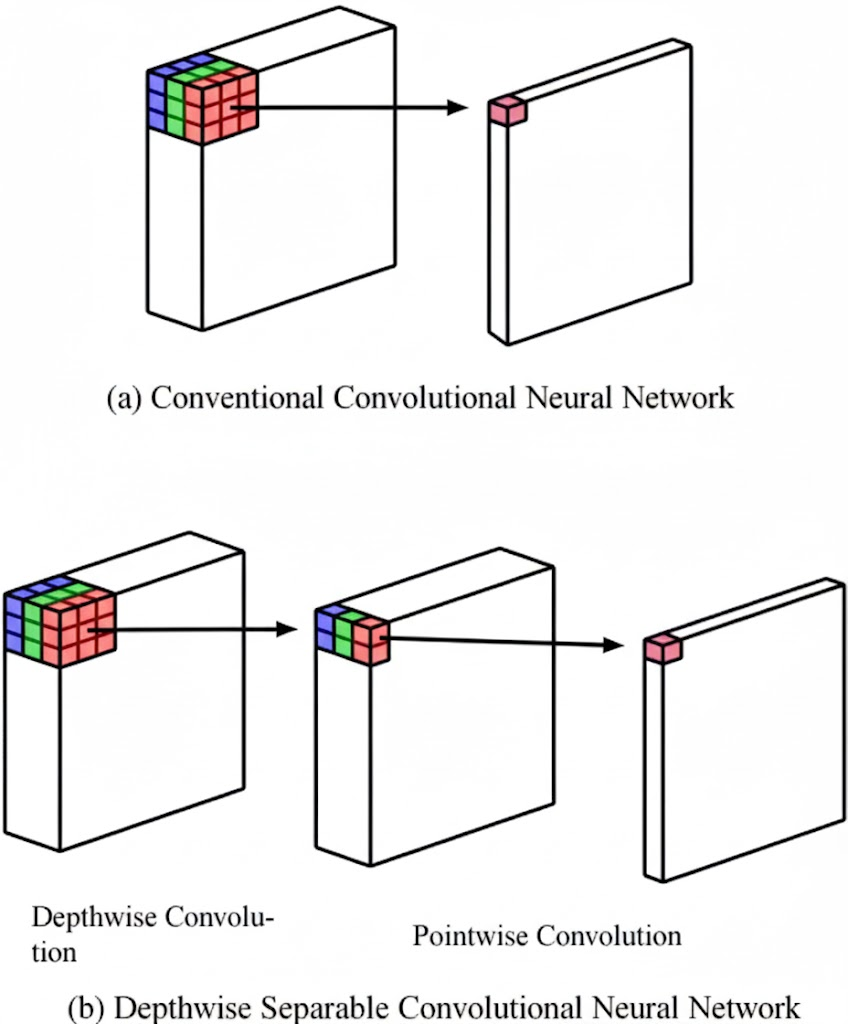
A normal convolution mixes and merges all pixels across all channels - powerful, but painfully slow. MobileNet breaks that into two lighter steps:
- Depthwise convolution: Each filter looks at just one channel (color or feature map) - learning local patterns.
- Pointwise convolution (1×1): Combines those patterns across channels to form meaning.
This simple split - called a depthwise separable convolution - slashes computations by nearly 8–9× while keeping accuracy surprisingly high.
MobileNet didn’t stop there:
- V1 (2017): Introduced depthwise separable convolutions.
- V2 (2018): Added inverted residuals - skipping unnecessary expansions - and linear bottlenecks to prevent overfitting.
- V3 (2019): Used neural architecture search and squeeze-and-excitation attention to fine‑tune what really matters.
So instead of brute‑forcing power, MobileNet chose to be clever - do less work, but do it smartly.
🧠 Memory tip: MobileNet = Split the work, save the power - efficient brains for edge AI.
And while MobileNet laid the foundation for efficient design, we can push performance even further with techniques that tune these models after training - making them leaner, faster, and ready for real‑time deployment.
Model Optimization Techniques
Even with lightweight architectures, further optimizations are needed for real-time edge inference. Here are the three most impactful ones:
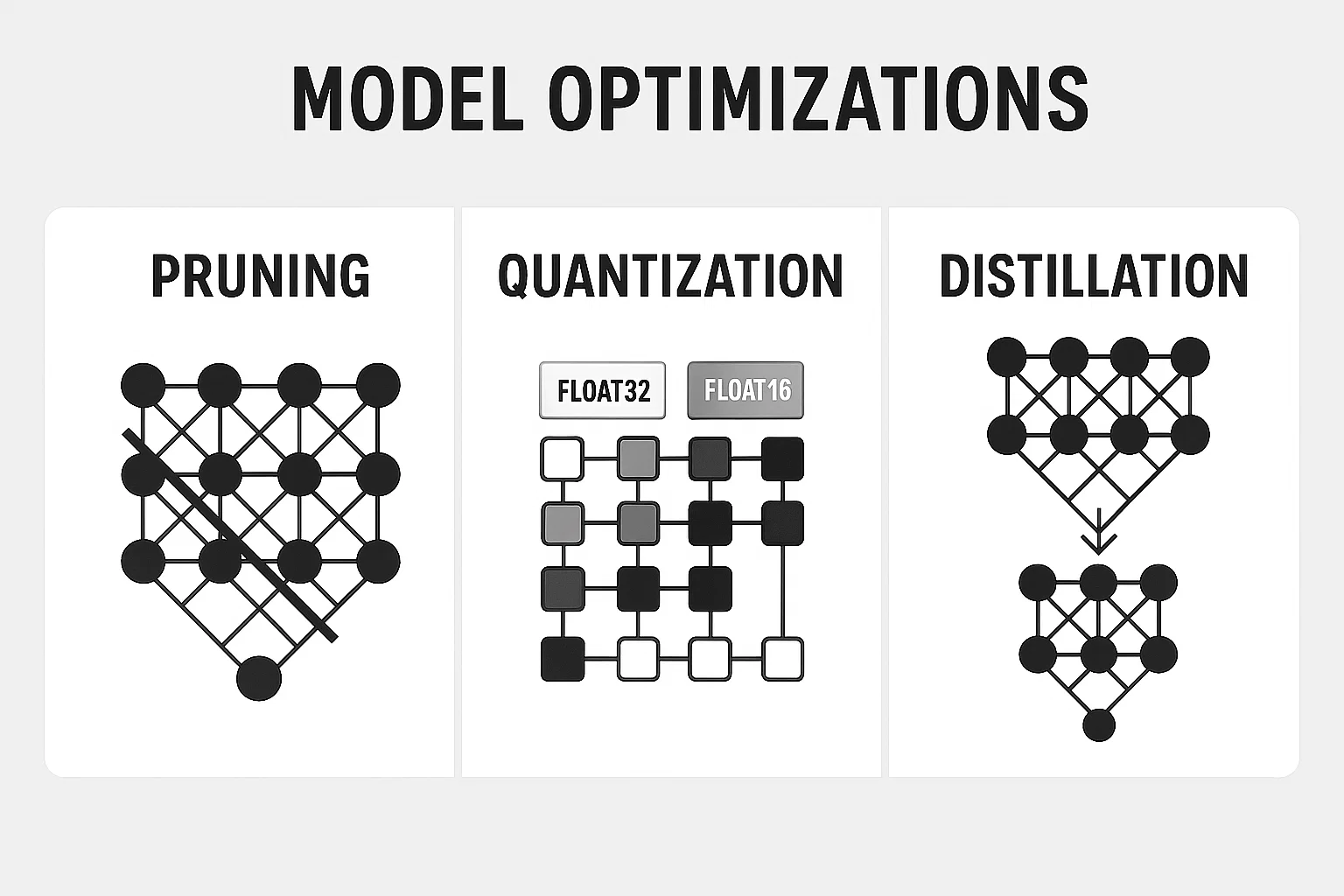
1. Quantization: Shrinking the Numbers
Most neural networks use 32-bit floating-point (FP32) weights. Quantization converts them to smaller representations like INT8 or FP16 - reducing both memory and computation.
- Post-training quantization (PTQ): Convert after training.
- Quantization-aware training (QAT): Train the model while simulating quantization noise for better accuracy.
Once quantized, the new weights are stored and loaded into the model graph - either via conversion tools like TensorFlow Lite’s converter or PyTorch’s torch.quantization APIs. This means the same trained network can now run using low-precision math on edge hardware with minimal accuracy drop.
Benefits:
- 2–4× smaller model size
- Faster inference (especially on CPUs and NPUs)
Example: TensorFlow Lite and PyTorch Mobile use INT8 quantized models for mobile CPUs.
2. Pruning: Cutting the Fat
Not all neurons are equally important. Pruning removes unimportant weights or channels while retaining most of the model’s accuracy.
- Unstructured pruning: Remove individual weights (good for sparsity).
- Structured pruning: Remove whole filters or channels (better for hardware acceleration).
In practice, pruning is applied during or after training using libraries like PyTorch’s torch.nn.utils.prune or TensorFlow Model Optimization Toolkit. The model is retrained for a few epochs afterward to fine-tune remaining weights - much like trimming a tree and letting it regrow stronger.
Result: Fewer parameters → smaller model → faster inference.
Analogy: Pruning a tree - you cut the weak branches, the tree stays strong.
3. Knowledge Distillation: Learning from a Mentor
Introduced by Geoffrey Hinton, knowledge distillation trains a smaller student model to mimic a larger teacher model’s outputs.
Typically, both models run on the same dataset - the teacher provides soft probability outputs, which guide the student during training. The student learns from these softened targets (controlled by a temperature parameter) instead of hard labels, transferring nuanced patterns from the teacher.
Frameworks like PyTorch Lightning and TensorFlow make this process straightforward by combining loss from both teacher and student predictions.
Student = fast and small, but wise beyond its size.
Putting It All Together
In real-world edge AI systems, multiple techniques are stacked:
| Technique | Purpose | Typical Gain |
|---|---|---|
| MobileNet / EfficientNet | Lightweight architecture | 5–10× faster inference |
| Quantization (INT8) | Reduce compute precision | 2–4× smaller, faster |
| Pruning | Remove redundant weights | 20–50% size reduction |
| Knowledge Distillation | Retain teacher accuracy | +1–3% accuracy recovery |
Combining them can deliver up to 20× efficiency improvements over the baseline model - enabling complex models like object detection or speech recognition to run on microcontrollers and smartphones.
Emerging Trends
- Neural Architecture Search (NAS): Automatically designs models optimized for edge hardware (e.g., MobileNetV3, EfficientNet-Lite).
- Mixed precision inference: Dynamic use of FP16 + INT8 for speed/accuracy trade-offs.
- Edge accelerators: Hardware designed for inference (Google Edge TPU, NVIDIA Jetson, Apple Neural Engine).
These advancements blur the line between cloud and edge - intelligence is now distributed.
Key Takeaways
- Edge inference brings AI to where data lives - on-device.
- Lightweight architectures (MobileNet, EfficientNet) make deep learning practical for constrained devices.
- Quantization, pruning, and distillation are essential post-training tricks to shrink and speed up models.
- The future of edge AI lies in hybrid optimization - combining architectural innovation with hardware-aware design.
In short: The edge isn’t just catching up to the cloud - it’s redefining what “smart” means.



