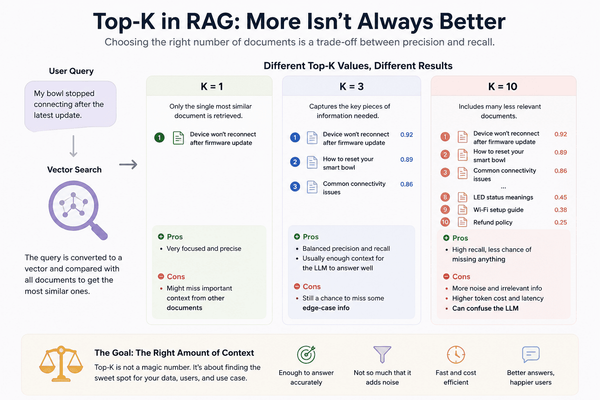
Top-K in RAG: Why Retrieving More Documents Doesn't Always Help
Every RAG tutorial follows almost the same flow: convert the user's query into an embedding, retrieve the Top-K most similar documents, and pass them to the LLM. The part that's usually skipped is a simple question: Why K? Why retrieve 3 documents instead of 1? Why