How We Teach Machines to Hear: The Journey from Waves to Meaning


Introduction
We’re building technology that helps us understand pets better - not just through visuals, but through sound. Dogs communicate through subtle cues: the rhythm of a chew, a quiet gulp, or a bark that changes tone when they’re anxious.
At Hoomanely, our smart bowls and monitoring systems use advanced audio processing to turn raw noise into structured understanding.
In this post, we’ll explore how we teach machines to listen - how sound becomes numbers, how the Fourier Transform reveals hidden frequencies, why it falls short for real-world sounds, how Short-Time Fourier Transforms (STFTs) and Mel Scales close those gaps, and how modern models like Mel-CNNs and Conv-TasNet take sound understanding even further.
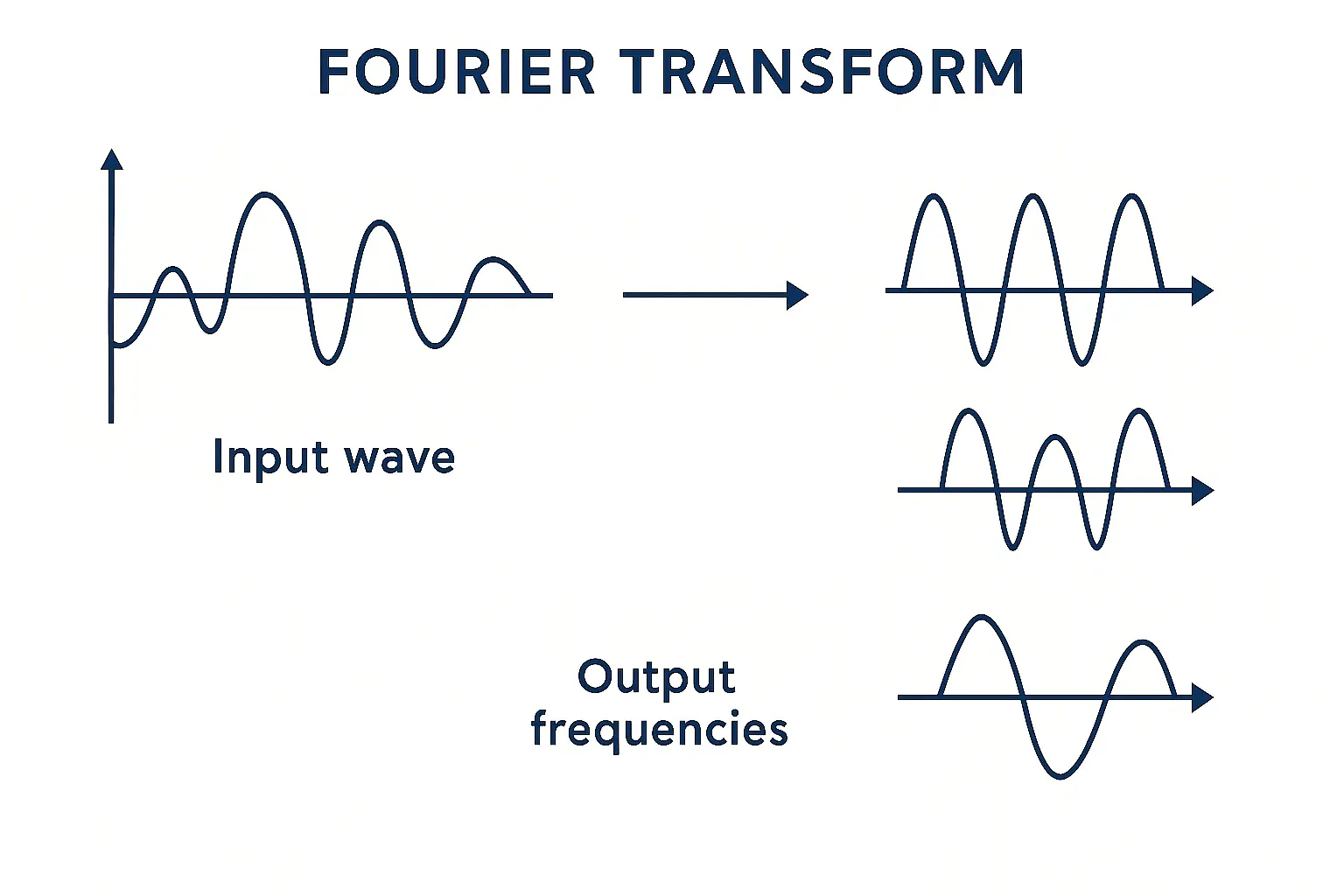
Breaking Down Sound - The Fourier Transform
Imagine recording a dog barking once and then chewing quietly. In the waveform, both look like squiggly lines - but the patterns alone don’t tell us which is which. We need to know what frequencies make up those sounds.
The Fourier Transform (FT) helps with that. It breaks a complex sound into simpler parts pure tones (sine waves). It shows how strong each frequency is, like creating a list of ingredients for the sound.
For example, if a bark has strong energy around 2000 Hz and chewing around 300 Hz, the Fourier Transform reveals those hidden patterns.
But there’s a limitation. The FT assumes the sound’s content stays the same over time - what engineers call stationary. Real-world sounds like barking don’t follow that rule. A bark starts loud, fades fast, and disappears; chewing repeats in short bursts. The FT tells us what frequencies exist but not when they happen.
Example: It’s like knowing the ingredients of a song (bass, drums, guitar) but not when each starts or stops playing.
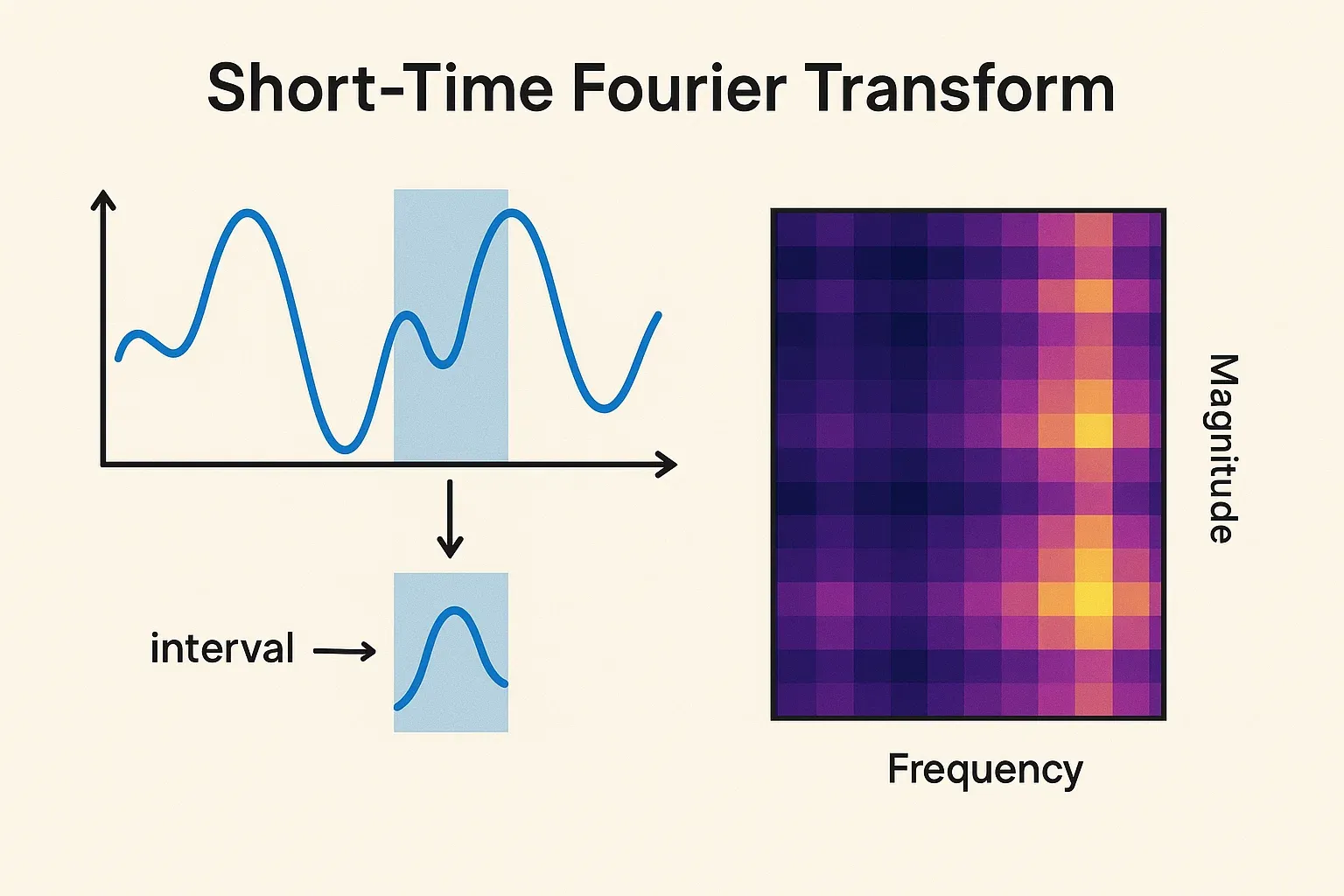
When Timing Matters - The Short-Time Fourier Transform (STFT)
To understand sound as it changes, we need to know both what frequencies exist and when they occur. That’s where the Short-Time Fourier Transform (STFT) helps.
STFT chops the sound into tiny overlapping pieces (say 25 milliseconds long), applies the Fourier Transform to each, and slides the window forward. This helps capture how sound frequencies evolve over time - giving us both timing and frequency information in one view. However, the output at this stage is still not in a form that neural networks can easily process; that’s where the Mel Scale comes in, converting this information into a compact image-like encoding that models can learn from.
Hearing Like Humans - The Mel Scale
Our ears don’t hear every frequency equally. We’re more sensitive to changes in lower pitches than in high ones. For instance, a change from 200 to 400 Hz sounds big, but 5000 to 5200 Hz barely registers. To mimic this, researchers created the Mel Scale, which spaces frequencies the way we perceive them - closely at low tones, widely at high ones.
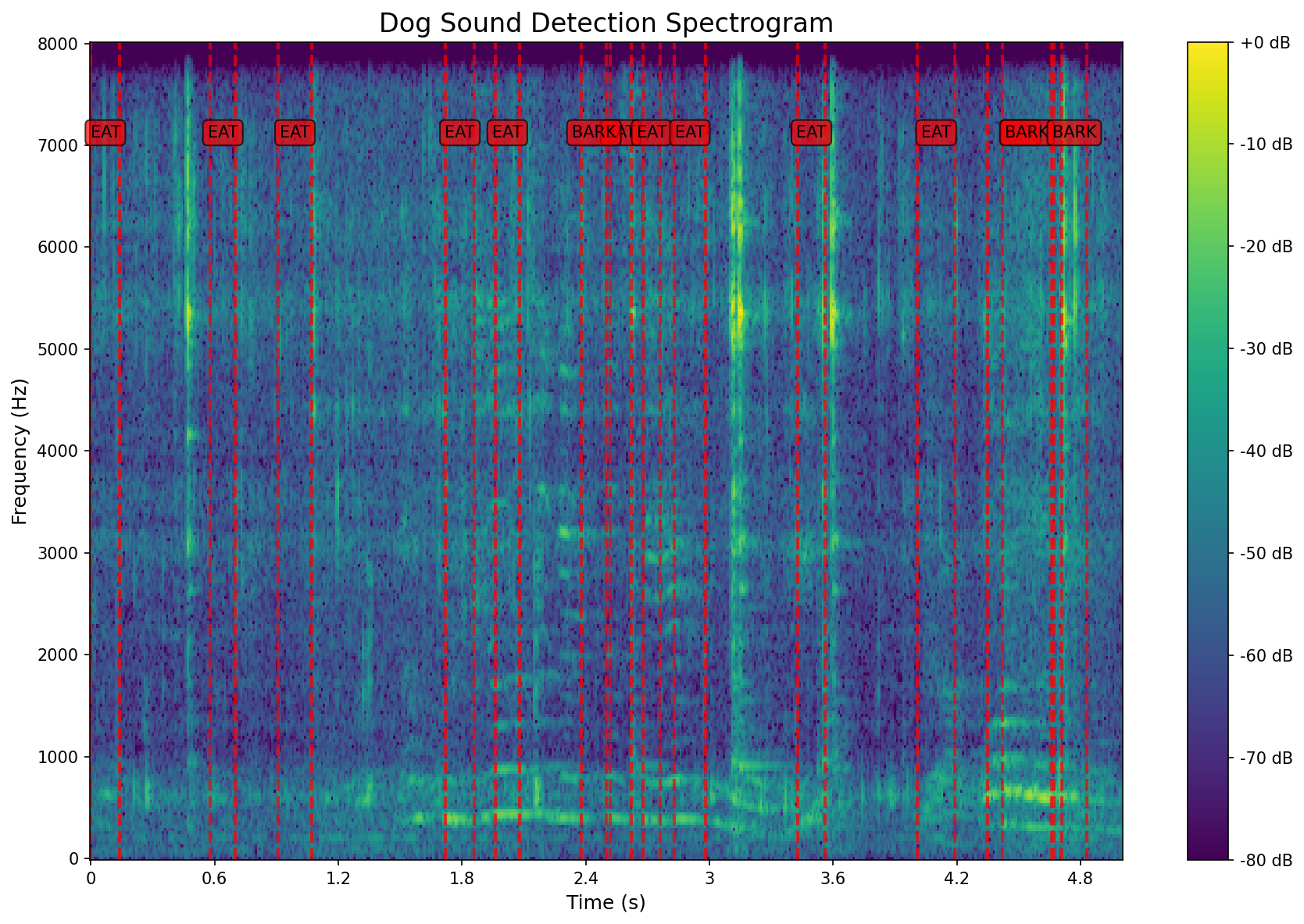
When we apply this scale to a spectrogram - which is a visual map of how sound energy changes over time and frequency - we get a Mel Spectrogram, an image-based encoding that groups frequencies by how we naturally hear them and can be easily consumed by Convolutional Neural Networks (CNNs).
Example: Think of it as a piano keyboard where the lower notes take up more keys because our ears can tell their differences better.
The Mel Spectrogram is easier for machines to process - fewer features, less noise, and a focus on what really matters for perception. In essence, it’s a way of encoding sound data for neural networks to learn from. However, this transformation loses some information - specifically, phase, which carries fine timing details of the original waveform.
Seeing Sound - How Mel-CNNs Learn
Once we turn sound into a Mel Spectrogram, it looks like a picture: colors changing over time and frequency. So why not treat it like an image? That’s where Mel-CNNs (Convolutional Neural Networks) come in.
A Mel-CNN scans these images for patterns - smooth waves for chewing, sharp spikes for barking - just like it would detect edges or textures in a photo. Over time, it learns to tell one sound from another.
Example: Imagine training a camera to recognize dog breeds - except here, it’s recognizing sound shapes instead of fur patterns.
Why Mel-CNNs fit our use case:
- Lightweight enough to run on small devices.
- Effective even with modest data.
- Works great for clear event detection like chew, gulp, or bark.
Its main limitation? It needs precomputed spectrograms and can’t capture tiny timing details (phase). But for identifying sounds, it’s more than enough.
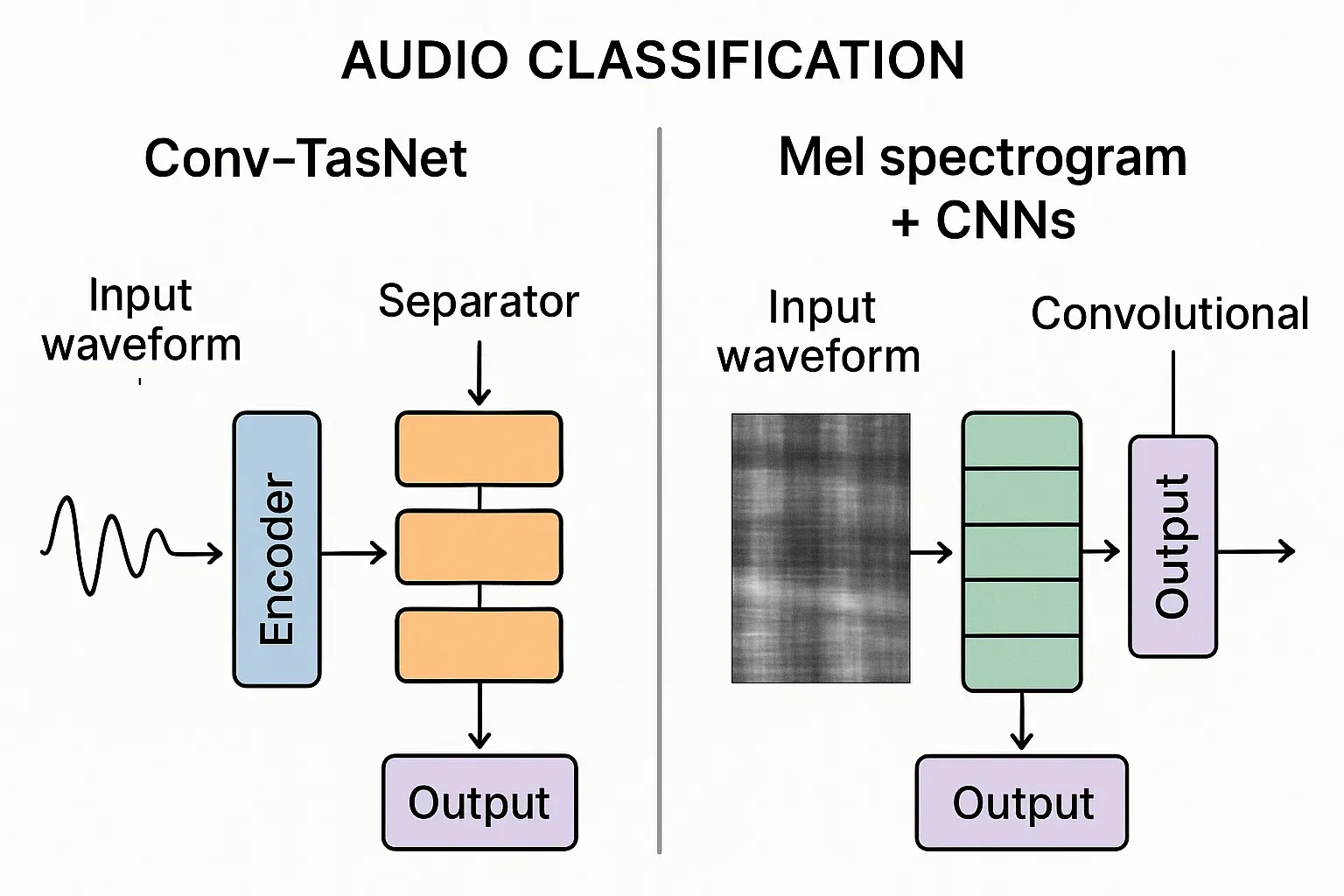
Going Straight to the Source - Conv-TasNet
While Mel-CNNs start with prepared spectrograms, models like Conv-TasNet skip all that and learn directly from the sound wave itself.
Conv-TasNet (Convolutional Time-domain Audio Separation Network) teaches itself how to hear. It learns its own way to split and rebuild sounds without ever using a Fourier Transform.
It has three main steps:
- Encoder: Learns its own filters (like a custom-built Fourier Transform).
- Separator: Finds which parts belong to each sound (chewing, barking, or background noise).
- Decoder: Recreates clean, separated sounds.
Example: Think of it as teaching a dog to recognize toys without labeling them - it figures out which sound belongs to what by listening repeatedly.
Conv-TasNet keeps all the fine details (phase and timing) and produces clearer separations. It’s ideal for cleaning noisy recordings or generating training data - though it’s heavier and needs more data than a Mel-CNN.
For simple event detection like chewing or barking, Mel-CNNs are a better fit because they’re lightweight and efficient. For cleaning noisy audio or separating overlapping sounds, Conv-TasNet works best due to its detailed time-domain processing.
Picking the Right Tool
| Goal | Best Approach |
|---|---|
| Detect chewing or barking | Mel-CNN |
| Remove background noise | Conv-TasNet |
| Real-time on-device inference | Mel-CNN |
| Clean training data generation | Conv-TasNet → Mel-CNN distillation |
Together, they give us clean, smart, and efficient listening - perfect for understanding dogs in real-world conditions.
Why It Matters
Every sound a dog makes carries meaning. Fast gulping can hint at anxiety, uneven chewing might show dental pain, and barking tone shifts can reveal mood. By capturing and decoding these sounds, we help pet parents spot early signs of discomfort.
At Hoomanely, our goal is simple: to help humans understand dogs better — not by adding microphones, but by adding intelligence to what those microphones hear.
We’re not just recording; we’re interpreting the language of dogs.



