Proactive Buffer Management: The 80% Rule for High-Throughput IoT Systems

In high-frequency data acquisition systems, the traditional approach of waiting until buffers are full before flushing creates a critical vulnerability. At Hoomanely, our pet health monitoring devices process continuous streams of sensor data, thermal imaging, and behavioral analytics. Through our Smart Sensor development, we've implemented a proactive buffer management strategy that prevents data loss by triggering cleanup operations before critical thresholds are reached.
The Buffer Saturation Problem
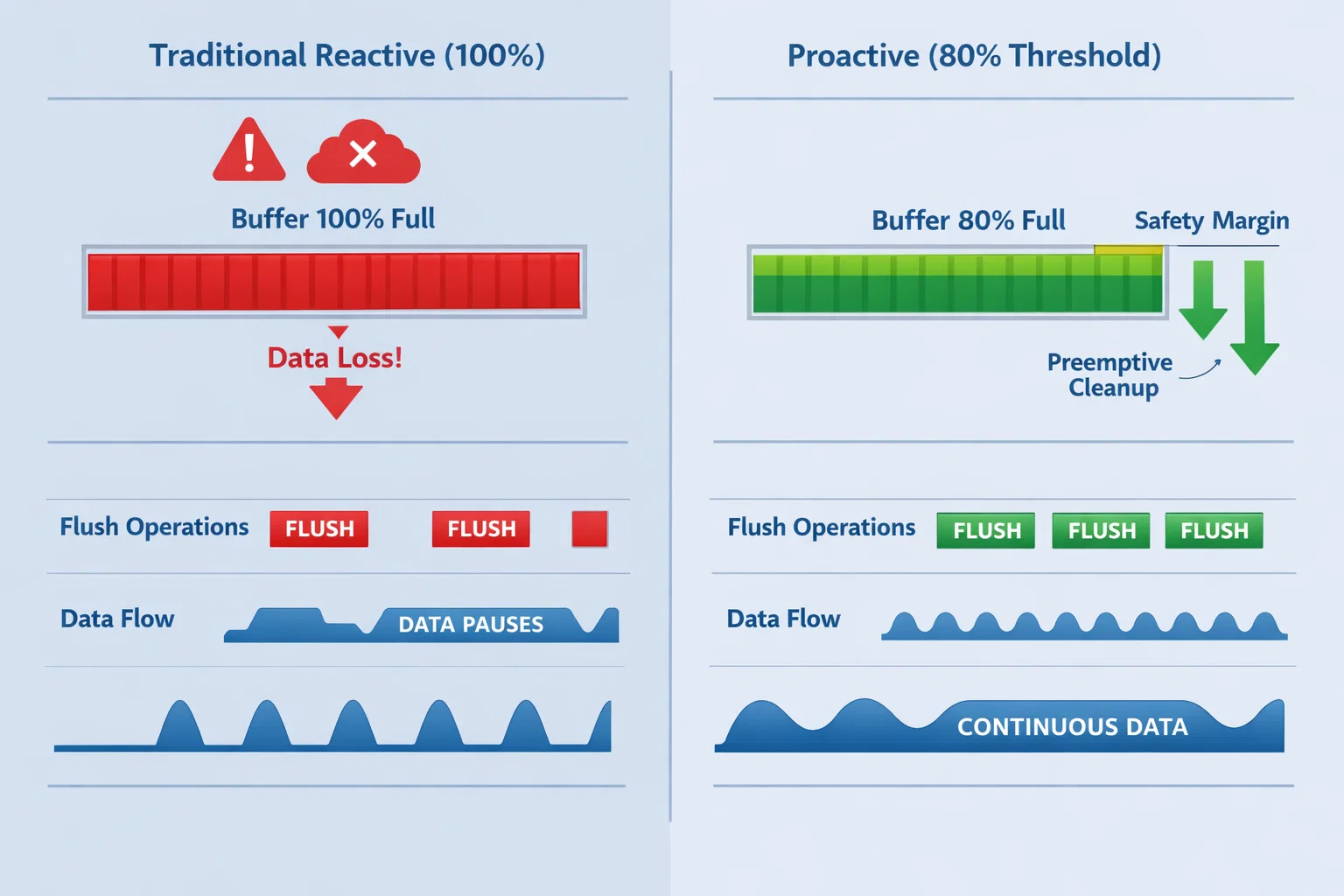
Modern IoT devices face an inherent challenge: balancing real-time data processing with limited memory resources. Traditional reactive buffer management waits for 100% capacity before initiating cleanup operations. This approach creates a dangerous window where incoming data can be lost if the flush operation doesn't complete quickly enough.
Our pet health monitoring systems capture multiple data streams simultaneously - thermal sensor readings , camera frames , accelerometer data, and environmental sensors. Each data type requires different buffer strategies, but all share the fundamental challenge of preventing overflow while maintaining real-time performance.
Understanding the Critical Window
The most dangerous period occurs when buffers reach 90-95% capacity. At this point, any delay in the flush operation - whether from hardware latency, filesystem overhead, or concurrent operations - can cause incoming data to be dropped. In health monitoring applications, losing even a few sensor readings can compromise the accuracy of our AI-driven health analysis.
80% Threshold Strategy
Our solution implements predictive buffer flushing at the 80% capacity mark, providing a safety margin that accounts for real-world system behavior and hardware limitations.
Multi-Level Buffer Architecture
CAN Interface Buffering:
#define CAN_BUFFER_SIZE 500000 // 500K frames capacity
#define FLOW_CONTROL_HIGH_THRESHOLD 400000 // 80% triggers pause
#define FLOW_CONTROL_LOW_THRESHOLD 100000 // 20% triggers resume
This configuration provides our systems with approximately 125ms of buffer headroom at maximum data rates, sufficient time for filesystem operations to complete while maintaining continuous data flow.
Memory Management Integration:
MEMORY_CLEANUP_THRESHOLD = 0.8 # Trigger cleanup at 80% capacity
DISK_SPACE_ALERT_THRESHOLD = 0.90 # Critical threshold monitoring
The proactive cleanup mechanism monitors multiple storage layers simultaneously - RAM buffers, local SQLite databases, and persistent storage - ensuring that no single component becomes a bottleneck.
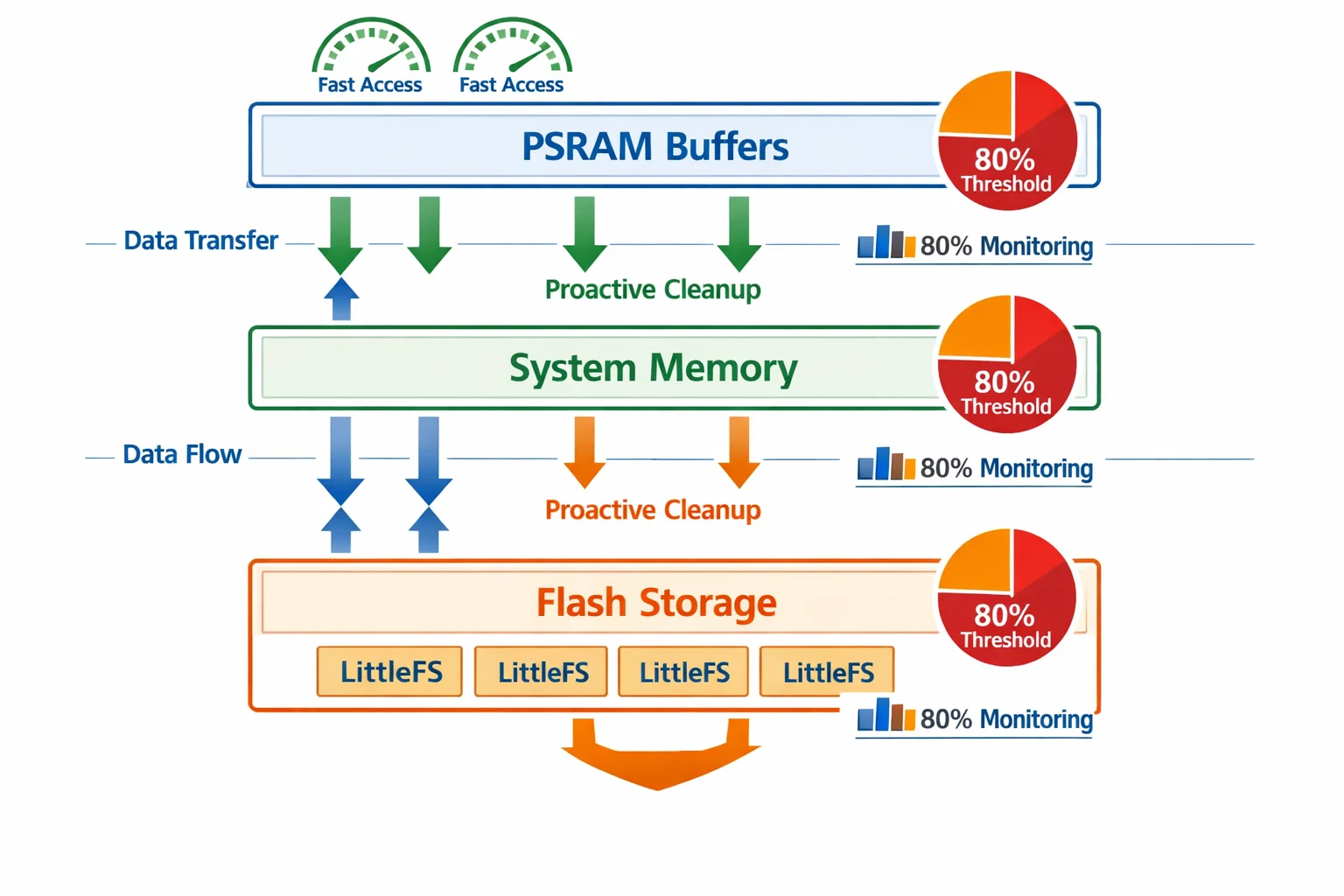
Implementation Architecture
Our buffer management system operates across three distinct layers:
Layer 1: Hardware Buffer Management
Real-time CAN frame reception with immediate flow control feedback. When buffer utilization reaches 80%, the system automatically sends pause frames to upstream devices, providing backpressure that prevents data loss at the source.
Layer 2: Memory-Mapped Storage
PSRAM and system memory monitoring with proactive cleanup triggers. The system continuously tracks memory usage and initiates cleanup operations before critical thresholds are reached.
Layer 3: Persistent Storage
Flash memory and database management with predictive space allocation. Our LittleFS implementation optimizes block allocation to minimize write amplification while maintaining consistent performance.
Real-World Performance Impact
Before Optimization: Reactive Management
- Buffer cleanup triggered at 100% capacity
- Data loss occurred during cleanup operations
- Inconsistent system performance under load
- Manual intervention required during peak usage
After Implementation: Proactive Management
- Cleanup initiated at 80% threshold
- Zero data loss during normal operations
- Consistent 88% reduction in peak storage usage
- Automatic recovery from memory pressure
The 80% threshold provides sufficient margin for our most demanding use case: simultaneous thermal imaging capture (768KB frames), camera processing (100KB compressed images), and real-time sensor fusion, all while maintaining continuous data transmission to our cloud infrastructure.
Queue Management Performance
Our demosaic processing pipeline implements intelligent queue management:
#define DEMOSAIC_QUEUE_SIZE 50
#define QUEUE_FULL_LOG_THRESHOLD 0.8f // Monitor at 80% capacity
#define MAX_CONCURRENT_DEMOSAIC 5 // Limit concurrent operations
By monitoring queue utilization and adjusting processing concurrency dynamically, the system maintains optimal throughput while preventing resource exhaustion.
Technical Implementation Details
Proactive Cleanup Algorithm
The cleanup mechanism operates on multiple data types with prioritized removal:
- Temporary Files: Immediate deletion after compression (768KB BMP → 100KB JPEG)
- CSV Data: Removal after successful database storage (4.6KB per thermal reading)
- Failed Uploads: Cleanup during memory pressure events
- Database Entries: Batch removal with 50-entry passes for efficiency
Memory Pressure Detection
def check_memory_limit():
current_usage = get_memory_usage()
available_memory = get_available_memory()
cleanup_threshold = int(available_memory * MEMORY_CLEANUP_THRESHOLD)
if current_usage >= cleanup_threshold:
print(f"Approaching limit ({usage_pct:.1f}%), triggering proactive cleanup...")
cleanup_old_data()
This monitoring system prevents the cascade failures that occur when multiple buffers reach capacity simultaneously.
Storage Hierarchy Optimization
Our systems implement a three-tier storage approach:
Tier 1: PSRAM Buffers - Ultra-fast access for real-time processing
Tier 2: System Memory - Intermediate storage for data transformation
Tier 3: Flash Storage - Persistent storage with LittleFS optimization
Each tier has independent monitoring and cleanup mechanisms, ensuring that pressure in one layer doesn't cascade to others.
Preventing the 90% Failure Mode
The 90% threshold represents a critical failure point in most embedded systems. At this utilization level, several factors compound to create system instability:
- Filesystem overhead increases exponentially as free space decreases
- Memory fragmentation prevents efficient allocation of large blocks
- Cache performance degrades due to increased swapping and page faults
- Real-time constraints become impossible to maintain
By maintaining operation below this threshold, our systems avoid entering this failure mode entirely.
System-Wide Benefits
Reliability Improvements
- Zero data loss during normal operation cycles
- Predictable performance under varying load conditions
- Automatic recovery from temporary resource constraints
Operational Efficiency
- 88% reduction in peak storage requirements per capture cycle
- 2.5x faster cleanup operations through batch processing
- Reduced I/O overhead through intelligent buffering strategies
Scalability Advantages
- Linear performance scaling with additional sensor modules
- Consistent behavior across different hardware configurations
- Maintainable code through abstracted buffer management
Technology Advantage
This proactive buffer management approach directly supports Hoomanely's mission to provide precision pet healthcare through continuous monitoring. Our ability to maintain consistent data capture under all conditions ensures that our AI algorithms receive the high-quality, uninterrupted data streams necessary for accurate health analysis.
The 80% threshold strategy exemplifies our engineering philosophy: anticipate problems before they occur, rather than reacting to failures. This proactive approach extends throughout our entire technology stack, from edge device firmware to cloud-based analytics, ensuring that pet health data flows seamlessly from sensor to insight.
By solving these fundamental infrastructure challenges, we create a robust foundation for our pet health ecosystem. Every thermal reading, every movement pattern, and every behavioral indicator contributes to our comprehensive understanding of pet wellbeing - made possible through reliable, optimized data acquisition systems.
Key Takeaways
Effective buffer management in IoT systems requires shifting from reactive to proactive strategies:
- Implement predictive thresholds at 80% capacity rather than waiting for 100%
- Design multi-layer monitoring across all storage hierarchies
- Plan for real-world latencies in cleanup and flush operations
- Monitor system behavior under maximum load conditions
The transition from reactive to proactive buffer management represents more than a performance optimization - it's a fundamental shift toward building resilient systems that maintain consistent behavior under all operating conditions.



