Secure RAG for ML/AI Systems: Prompt Injection Defense, Retrieval Allow-Lists, and Citations

Retrieval-Augmented Generation has become the default architecture for practical AI systems because it separates reasoning from knowledge freshness. Models no longer need to contain every fact at training time; instead, they can retrieve relevant information from search indices, document stores, internal knowledge bases, and user-generated corpora at runtime. That architectural shift improves relevance and reduces hallucination, but it also creates a new security boundary: the model is now influenced by content it did not generate, content it does not control, and content whose trustworthiness may vary dramatically.
In most real deployments, retrieval is not limited to a pristine internal corpus. It spans approved documentation, semi-curated reference material, connector-fed data, tool outputs, support content, and sometimes community or user-submitted text. Once those sources enter the answer path, the attack surface expands beyond the user prompt. Prompt injection, policy shadowing, instruction override, citation laundering, tenant boundary leakage, and unsupported factual synthesis become system-level risks rather than isolated model failures.
Secure RAG, therefore, is not a prompt template. It is an enforceable architecture. The central design objective is straightforward: retrieved content must contribute evidence, but it must never acquire control authority. That objective affects indexing strategy, metadata design, retrieval filtering, prompt assembly, citation generation, evaluation, and operations. When implemented correctly, it transforms RAG from a probabilistic convenience layer into a bounded and auditable subsystem.
At Hoomanely, this matters because AI value depends on trust as much as relevance. As AI systems connect to broader product workflows and mixed-trust data surfaces, retrieval has to be governed as carefully as inference itself.
Threat Model for Secure RAG
The failure mode in naive RAG systems is not simply that irrelevant content may be retrieved. The more serious issue is that retrieved content can alter model behavior. This can happen through explicit prompt injection, but in production systems it often happens in subtler ways:
- retrieved text contains instruction-shaped language that competes with system prompts
- low-trust documents are ranked highly because they match the query semantically
- parser artifacts or connector metadata introduce control-like tokens into the prompt
- tool responses are injected into the context without provenance or schema constraints
- the model produces confident synthesis beyond what the retrieved evidence supports
- citations are attached post hoc, creating the appearance of grounding without real support
This is why Secure RAG must be modeled as a control-boundary problem. The question is not only whether a malicious phrase appears in a chunk, but whether the system allows that chunk to participate in behavior formation. A system that retrieves first and interprets trust later is already too permissive.
A robust threat model should include four attack classes:
Instructional attacks attempt to override system policy through retrieved content.
Authority attacks make low-trust content appear operationally important or normative.
Context poisoning attacks degrade ranking quality or bias synthesis through noisy but relevant text.
Evidence laundering attacks cause the model to make unsupported claims while still appearing cited.
Secure RAG architecture is effective only if it constrains all four.
Trust Segmentation in the Retrieval Layer
The first implementation decision is to eliminate the notion of a single undifferentiated corpus. In secure deployments, documents must carry enforceable trust semantics before retrieval occurs. A practical segmentation model usually includes:
- Trusted: internally approved, versioned, reviewed, policy-bearing content
- Constrained: curated external or partner sources with limited authority
- Untrusted: public, community, user-generated, or weakly governed content
This segmentation should exist at two levels:
Logical segmentation via metadata fields such as trust_tier, source_class, document_state, tenant_id, and content_policy_profile.
Physical segmentation via separate indices, namespaces, collections, or routing policies for higher-assurance isolation.
Metadata-only trust separation is useful, but in high-sensitivity systems it is not sufficient on its own. Physical separation reduces accidental cross-pollination and simplifies policy enforcement. For example, a feature that serves operational guidance may query only a trusted index, while a broader research or discovery feature may query trusted plus constrained indices with downgraded authority rules.
This shift changes retrieval design from “find the top-k relevant chunks” to “find the top-k eligible chunks under policy.” Eligibility is determined before ranking, not after.
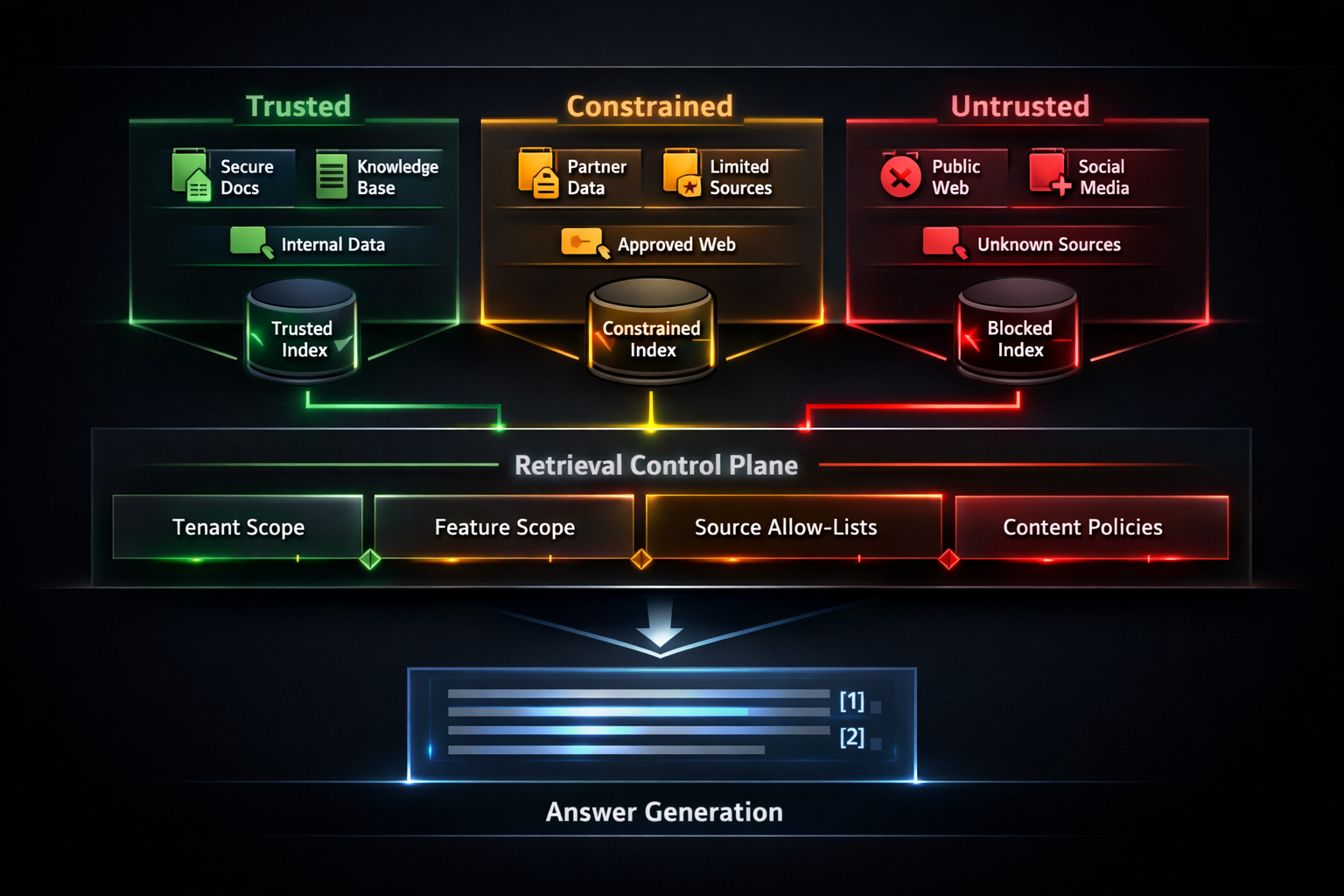
Retrieval Allow-Lists as a Control Plane
Allow-listing is often described as a filter, but in Secure RAG it is more accurate to think of it as a retrieval control plane. The role of this layer is to define, for each product feature or answer surface, the exact content classes that are eligible to participate in generation.
In implementation terms, a retrieval policy may be keyed by:
- feature or endpoint
- tenant or account scope
- user role or permission level
- allowed source repositories
- trust tier ceiling/floor
- document lifecycle state
- modality restrictions
- retention or version constraints
A simplified policy object might look conceptually like this:
feature: support_assistant
allow:
trust_tiers: [trusted, constrained]
source_classes: [kb, runbook, approved_partner]
document_states: [published, approved]
tenant_scope: strict
deny:
source_classes: [community, raw_import, debug_dump]
metadata_flags: [quarantined, parser_failed, review_pending]
generation_mode:
cite_required: true
untrusted_assertions: false
The important architectural pattern is deny by default. Newly indexed content should not automatically become retrievable. Eligibility should be granted explicitly by policy. This prevents a common class of incidents in which a new connector or ingestion path silently expands the answer surface without corresponding review.
Index partitioning and metadata filtering are complementary here. Metadata filtering gives precision; index partitioning reduces blast radius. Together they ensure that relevance scoring operates only within a bounded search universe.
This becomes especially valuable when multiple experiences rely on a shared search substrate. The same index infrastructure can serve several AI surfaces, but the retrieval contract for each surface must remain independently enforceable.
Evidence Serialization and Prompt Boundary Design
The next design boundary is prompt assembly. A common weakness in naive RAG systems is that retrieved text is appended as raw context. Even when the system prompt explicitly says “use the context below,” the formatting often makes retrieved text look operationally adjacent to trusted instructions.
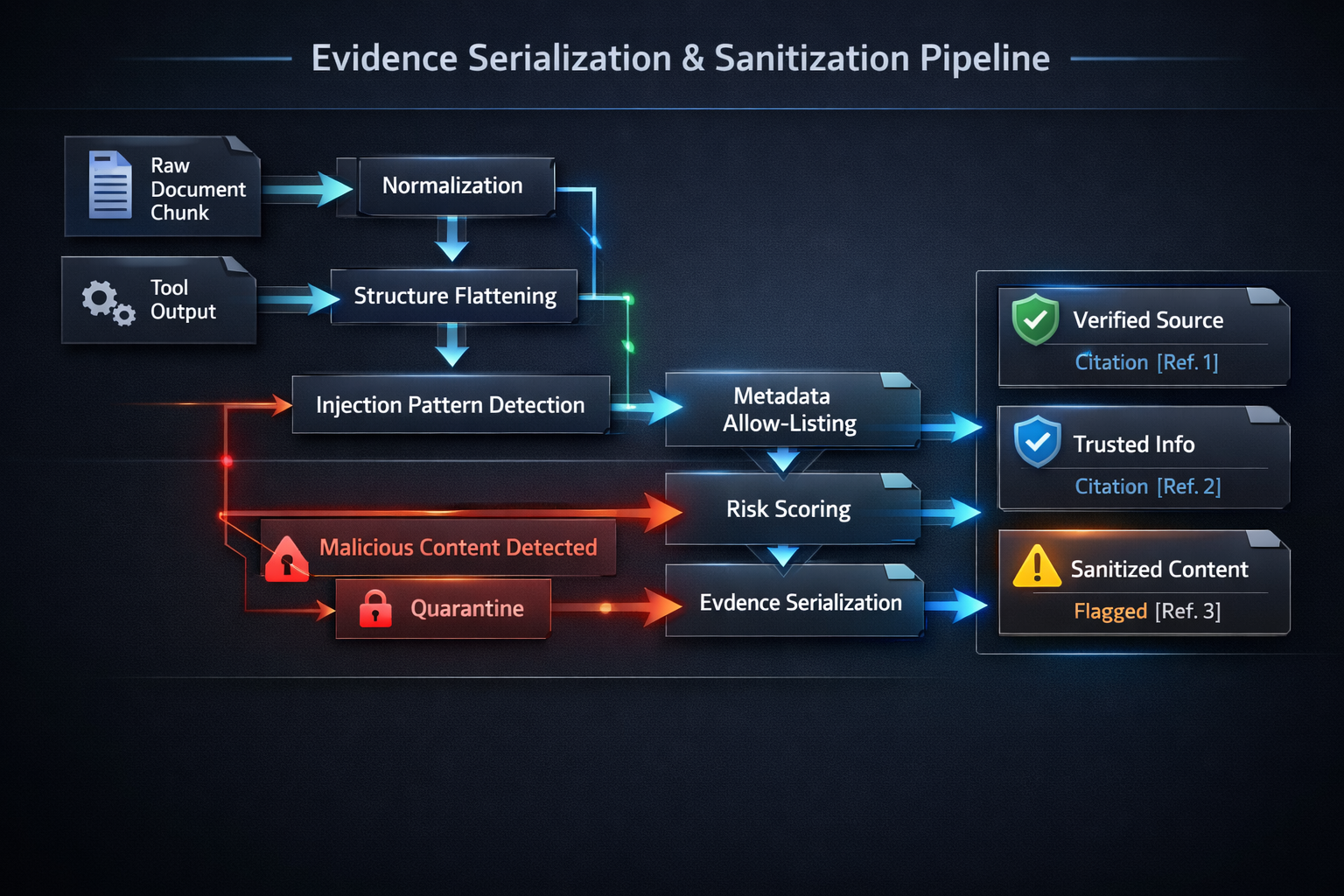
Secure RAG avoids that ambiguity by serializing retrieval outputs as evidence objects rather than free-form context. These objects should preserve provenance and constrain interpretation. A typical evidence schema might include:source_id, chunk_id, document_title, source_class, trust_tier, retrieval_score, content, sanitization_flags, citation_ref
This is not a cosmetic change. It establishes a strict semantic boundary: system instructions define behavior; evidence objects provide candidate factual support. The model should never interpret evidence as instruction-bearing authority.
In practice, this means prompt construction should separate:
- system and policy instructions
- task framing
- structured evidence
- output contract, including citation rules and unsupported-claim handling
When these concerns are blended together, the model is forced to infer hierarchy from wording. When they are separated explicitly, the system does more of the control work upstream.
Retrieval Sanitization and Injection Neutralization
Sanitization is often misunderstood as pattern filtering. In reality, the goal is narrower and more important: reduce the chance that retrieved content is interpreted as procedural guidance rather than evidence.
A secure sanitization stage typically includes:
- normalization of whitespace, encodings, and hidden characters
- removal or neutralization of role-like wrappers and instruction-shaped delimiters
- stripping or flattening HTML, markdown, or serialized artifacts that imply privileged structure
- truncation of oversized or anomalous metadata payloads
- detection and flagging of suspicious phrases or control-like constructs
- quarantine or downranking of chunks exceeding a risk threshold
This stage should not attempt to “understand malicious intent” perfectly. That approach is brittle. Instead, it should enforce safe formatting and reduce instruction-like affordances. Chunks that still appear risky after normalization can be tagged, deprioritized, or excluded.
A practical pattern is to propagate sanitization outcomes into the evidence schema. That way, downstream generation and observability can both see whether a chunk was altered, flagged, or partially suppressed.
Tool outputs deserve identical treatment. Search connectors, data services, profile APIs, and enrichment layers often enter the prompt with more implied trust than retrieved documents. They should be transformed into safe evidence payloads with schema allow-lists and provenance tags before prompt assembly.
Citation Semantics and Claim Binding
Citations are only useful if they constrain assertions. In many weak implementations, citations are attached after text generation based on approximate similarity between answer spans and retrieved chunks. That produces attractive output but weak accountability. The model can still synthesize beyond the evidence while appearing grounded.
A stronger design treats citation as part of the answer contract. The model should generate within explicit rules such as:
- non-trivial factual claims require one or more evidence references
- evidence from untrusted tiers cannot support normative assertions
- constrained-tier evidence may support qualified summaries but not policy-like recommendations
- unsupported claims must be omitted, caveated, or explicitly marked unknown
This produces a more disciplined answer surface. Instead of generating a fluent paragraph and finding citations later, the model is guided to compose from evidence-aware units. Post-generation validation can then verify:
- every citation points to an actual retrieved chunk
- the cited chunk materially supports the claim
- unsupported spans are rejected or rewritten
- citation coverage meets a threshold for the feature
This is where Secure RAG materially improves user trust. The system stops treating citations as a visual trust layer and starts using them as a runtime constraint.
In production, this also supports better debugging. When an answer is challenged, teams can inspect not only what was retrieved, but which evidence units were allowed to support which claims. That turns failures into diagnosable events rather than vague model behavior.
Graceful Degradation for Unsupported Answers
Secure systems should not be forced into binary behavior where every weak-evidence case becomes a full refusal. The better pattern is controlled degradation. If retrieval support is partial, the answer should narrow itself to what the evidence actually supports.
This requires the generation contract to distinguish:
- supported assertions
- partially supported synthesis
- unsupported or ambiguous claims
- opinion or community-derived observations that cannot be elevated to fact
The answer style in such cases becomes more precise:
- confirm what is supported
- isolate what is not established
- avoid implicit completion of missing details
- preserve provenance when trust is mixed
This is particularly important in mixed-trust corpora. Untrusted or semi-trusted sources may still be useful as signals, but their authority must remain bounded. A secure system does not discard all weak-trust content universally; it controls what that content is allowed to do.
Security Evaluation and Operational Controls
Secure RAG is not complete when the architecture diagram looks correct. It becomes durable only when its boundaries are continuously tested under change. Evaluation should therefore target the retrieval layer and answer contract directly, not only adversarial user prompts.
A meaningful evaluation suite includes:
- adversarial documents embedded in retrievable corpora
- authority-shaped but low-trust content designed to outrank trusted sources
- malformed connector outputs and metadata payloads
- tenant isolation regression cases
- citation support validation tests
- unsupported-answer degradation scenarios
The most useful production metrics are operational, not cosmetic:
- blocked retrieval count by source class
- suspicious chunk detection rate
- percentage of answers meeting citation coverage thresholds
- unsupported-claim rejection rate
- tool payload schema rejection rate
- false positive rate for sanitization
- retrieval-policy violations prevented upstream
These measurements are essential because Secure RAG can drift without obvious breakage. A new parser may preserve hidden markup. A ranking change may overexpose constrained-tier content. A connector may start returning new fields. A prompt revision may unintentionally weaken evidence discipline. Metrics and regression suites surface that erosion before it becomes a product incident.
At Hoomanely, this operating model is as important as the initial design. Trustworthy AI is not achieved at launch; it is preserved through continuous enforcement.

Implementation Trajectory
A realistic implementation path for Secure RAG can usually be delivered incrementally over 60–90 days without replatforming the entire AI stack.
Stage 1: introduce trust-tier metadata, source classification, and deny-by-default retrieval policies.
Stage 2: partition high-risk corpora and add feature-level allow-lists enforced before ranking.
Stage 3: replace raw prompt context with structured evidence serialization and sanitization.
Stage 4: enforce citation-bound generation with unsupported-claim degradation and post-generation validation.
Stage 5: operationalize adversarial retrieval testing, regression gating, and metric-driven monitoring.
This sequencing matters. The most impactful improvements usually occur before advanced detection logic. Once content eligibility, trust separation, and evidence boundaries are in place, the model has far less opportunity to be steered by unsafe retrieval.
At Hoomanely, AI systems are valuable only if they remain grounded as they interact with broader knowledge surfaces and product workflows. Secure RAG strengthens that foundation by making provenance enforceable, keeping mixed-trust content within explicit behavioral boundaries, and ensuring that citation-backed answers are truly supported. That is not just a security enhancement; it is a reliability requirement for production AI.
Key Takeaways
- Secure RAG is fundamentally an architecture problem, not a prompt-engineering problem.
- Trust segmentation and retrieval allow-lists should constrain eligibility before ranking occurs.
- Retrieved content must be serialized as evidence, not appended as raw prompt context.
- Sanitization should reduce instruction-like affordances and enforce schema boundaries.
- Citations should bind claims to evidence, not decorate generated text after the fact.
- Mixed-trust corpora require bounded authority, not uniform treatment.
- Operational metrics and regression suites are necessary to prevent guardrail drift.



