Sliding Window vs Event Triggering: What Reduced Our False Alerts

TL;DR: False alerts in production ML systems are not always caused by bad models. A single 12-second real-world event can produce 8 to 10 alerts through sliding-window inference, which runs continuously over overlapping windows, generating alert storms, duplicate alerts, and broken timelines until users stop trusting notifications. Event-triggered inference solves this by introducing lightweight gates, including energy thresholds, motion deltas, sensor state changes, and heuristic pre-filters, invoking the heavier ML model only when a meaningful precondition is met. A hybrid strategy combining event triggers with short internal sliding windows delivers high recall, low alert spam, and clean alert lifecycles. The core insight: inference strategy is a product decision, not just a modeling one.
The Problem We Kept Chasing
When we first rolled out alerts in production, the system technically worked - models were firing, dashboards were lighting up, notifications were flowing. And yet, something felt off.
We were seeing too many alerts.
Not because the world suddenly became chaotic, but because our inference strategy was.
False alerts are expensive in a quiet way:
- Users stop trusting notifications
- Teams start muting channels
- Real events get buried under noise
This post is about a decision that reduced our false alerts significantly, moving from a pure sliding-window inference strategy to event-triggered inference, and the trade-offs we learned along the way.
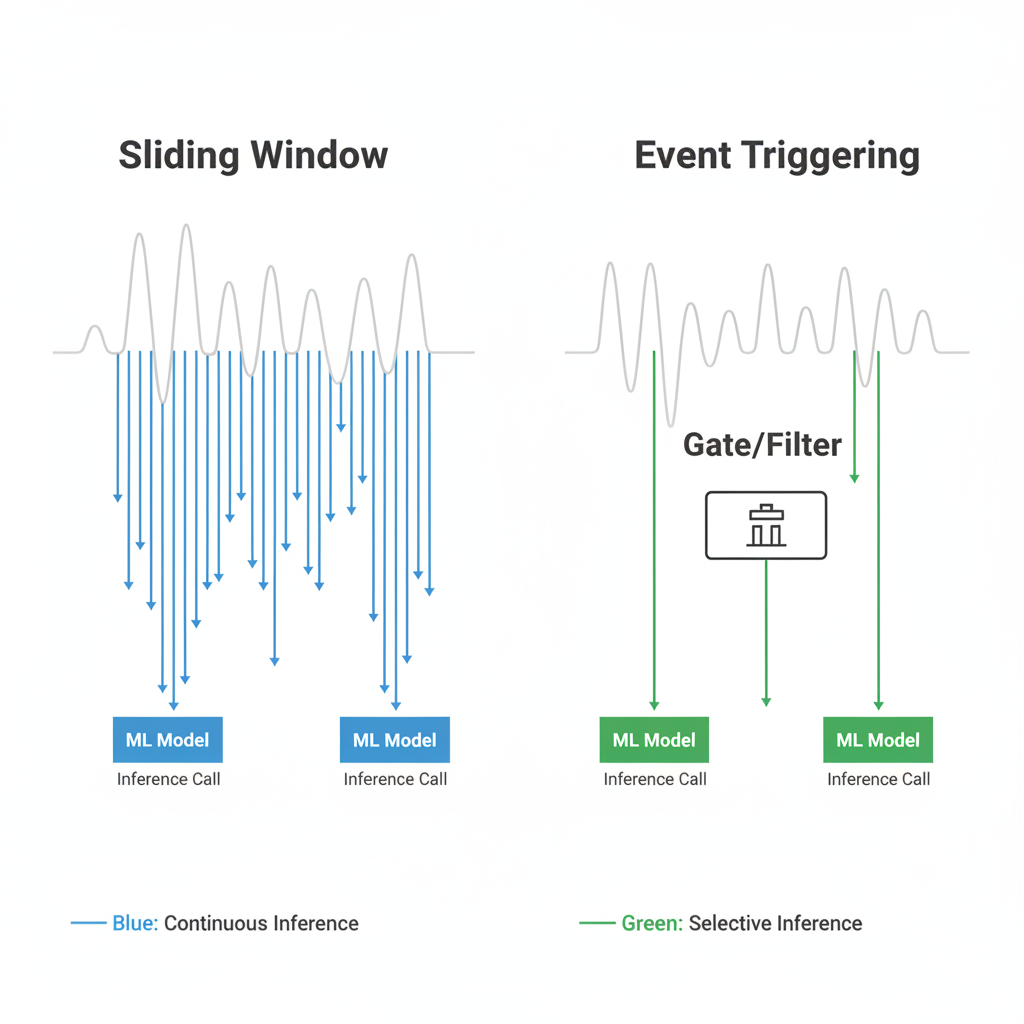
Sliding Window Inference: Always Watching
In sliding-window inference, the model runs continuously over overlapping windows of data.
For example:
- Audio: every 1 second, run inference on the last 5 seconds
- Vision: every frame batch, re-evaluate the scene
- Sensors: fixed cadence regardless of change
This approach has a comforting property: nothing is missed.
Why We Started Here
Sliding windows are the default for a reason:
- Simple mental model
- Easy to implement
- Great for offline evaluation
- High recall by design
If something happens, odds are the model will see it - often multiple times.
Where It Broke in Production
Reality, however, is noisy.
In production we observed:
- Minor fluctuations triggering alerts
- The same event firing repeatedly across overlapping windows
- Alert storms from a single real-world action
A single 12-second real event could easily produce:
- 8–10 alerts
- Slightly different confidence scores
- No clear start or end
The system was technically correct, but operationally unusable.
Event-Triggered Inference: Wait for a Reason
Event-triggered inference flips the model:
Don't ask the model continuously if something happened.
Ask the model only when something plausibly happened.
Instead of running inference on every window, we introduced lightweight gates:
- Energy thresholds
- Motion deltas
- Sensor state changes
- Heuristic pre-filters
Only when a gate fired did we invoke the heavier ML model.
What Changed Immediately
Three things improved almost overnight:
- Alert volume dropped
- Duplicate alerts disappeared
- Alert boundaries became cleaner
We stopped detecting possibilities and started detecting events.
The Metrics That Actually Mattered
Offline accuracy didn't tell this story. Production metrics did.
We tracked three things obsessively:
1. Alerts per Day
Sliding window inference inflated alert counts simply due to overlap.
Event-triggered inference collapsed multiple detections into a single alert.
Result: alerts/day dropped sharply without reducing true positives.
2. False Alert Percentage
False alerts weren't always wrong predictions - many were technically correct but semantically useless.
Examples:
- One real event → 6 alerts
- Short noise bursts → full alerts
- Borderline windows firing independently
Event triggering reduced these by:
- Requiring a meaningful precondition
- Enforcing temporal coherence
Result: false alert percentage reduced substantially.
3. Mean Alert Duration
Sliding windows fragmented reality.
A single continuous event appeared as:
- Many short alerts
- Broken timelines
- Confusing UX
Event-triggered inference naturally aligned alerts with real-world duration.
Result: mean alert duration increased - a good sign.
Longer alerts meant fewer, clearer, more meaningful events.
Trade-offs We Had to Accept
This wasn't a free win.
Sliding Window Strengths:
- Excellent recall
- Simple to reason about
- Robust to gate failures
Event Triggering Costs:
- Requires careful gate tuning
- Risk of missing subtle events
- Harder offline evaluation
- More system complexity
The key realization was this:
Inference strategy is a product decision, not just a modeling one.
A perfect classifier wrapped in a noisy inference loop still creates a bad user experience.
The Hybrid Model That Finally Worked
We didn't fully abandon sliding windows.
We combined both:
- Event triggers to decide when to run inference
- Short sliding windows inside the event to refine predictions
This gave us:
- High recall
- Low alert spam
- Clean alert lifecycles
The model waited.
The system listened.
Alerts became intentional.
Final Takeaway
If your production system is drowning in alerts, don't retrain the model first.
Look at:
- When you run inference
- Why you run it
- How often the same reality is being re-evaluated
Sometimes the biggest gains don't come from better models - they come from asking the model fewer, better questions.



