Why Smarter Chunking Matters More Than Bigger LLMs


Introduction
In specialized fields, smarter systems are the goal. While scaling large language models (LLMs) is popular, real improvements often come from optimizing the backend. Retrieval-Augmented Generation (RAG) pipelines, particularly chunking, are crucial for performance.
At Hoomanely, we faced issues with irrelevant responses due to poor chunking. Instead of using larger LLMs, we improved our chunking strategy. By switching to a dynamic approach, we preserved context and increased accuracy without higher costs. This post explores why smarter chunking is more effective than simply scaling up, how we implemented it, and the results that show its importance.
The Problem: Why Traditional Chunking Falls Short in RAG
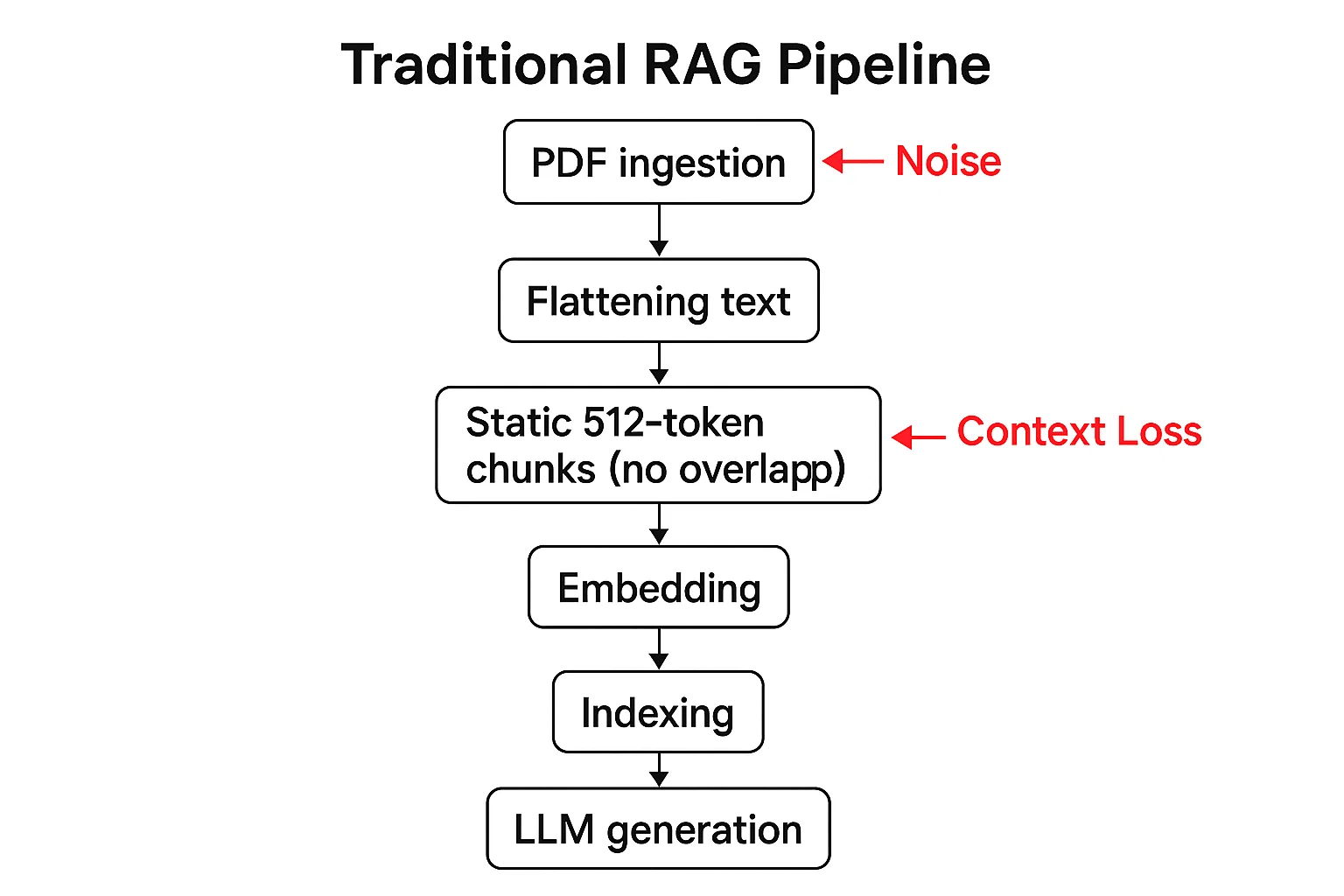
RAG pipelines are vital for chatbots using large knowledge bases, like our 2,796 veterinary PDFs. The process retrieves document chunks, feeds them to an LLM, and generates responses. Our initial setup had issues:
- Noisy and inflexible chunking: We used fixed 512-token blocks with no overlap, keeping messy elements like image placeholders and headers, which diluted content and lost context.
- Embedding and indexing limitations: Our Neural Sparse Encoder with HNSW indexing was fast but struggled with deep semantics in veterinary texts, leading to noisy and inaccurate responses.
- Benchmarks showed mediocre NDCG@10 scores: Without context, the LLM guessed connections. Scaling to a bigger LLM might hide these flaws but ignores the root cause - poor data prep. As datasets grow, inefficient chunking increases storage costs and slows queries. We needed smarter chunking, not just bigger models.
Our Approach: A Revamped RAG Pipeline with Dynamic Chunking
To address this, we implemented a new rechunking and reindexing strategy based on document processing best practices. We used GCP Document AI for clean parsing, advanced embeddings like NV-Embed-v2, and improved indexing. The key change was switching from static to dynamic chunking, which adapts to content semantics for meaningful, context-rich chunks.
Our process includes pre-ingest parsing, structure extraction, dynamic chunking, filtering, and embedding/indexing. This approach is scalable for our large veterinary corpus, focusing on adaptability. Dynamic chunking finds natural breaks, unlike static chunks that ignore content boundaries.
This new pipeline is cost-effective and tailored for technical content, reducing hallucinations by providing the LLM with cleaner, more contextual chunks.
The Process: Step-by-Step Breakdown
Let's walk through how we built this, with a deep focus on the dynamic chunking strategy that stole the show.
1. Pre-Ingest Stage: Cleaning the Source
We started with raw PDFs, using GCP Document AI for parsing. This tool extracts structured JSON with paragraphs, headings, tables, forms, and figures - far better than simple text flattening.
- Key Steps:
- Extract fields like page_num, paragraph.text, layout.confidence, table.cells, and bounding boxes.
- Clean: Join wrapped lines, normalize Unicode (e.g., "μg" to "ug"), remove headers/footers, but keep casing and units (e.g., mg/kg).
- Tag quality: Flag ocr_low if confidence < 0.6.
This processed our 1.44M pages at ~$2,200 (covered by credits), yielding clean inputs free of noise like base64 placeholders.
2. Structure Extraction: Building Meaningful Units
From the JSON, we extracted:
- Narratives: Merge paragraphs under headings for flow (e.g., full disease treatment sections).
- Tables: Convert to Markdown/JSON (e.g., dosage tables preserved as structured data).
- Forms: Flatten key-value pairs (e.g., "Drug: Amoxicillin, Dosage: 10mg/kg").
- Captions: Attach to nearby text for context.
This ensures chunks aren't arbitrary slices but logical units.
3. Dynamic Chunking: The Heart of the Strategy
Here's where we diverged from static methods. Instead of fixed 512-token chunks with 10% overlap, we implemented a dynamic approach using semantic embeddings and adaptive boundaries. The goal: Create chunks that respect content semantics while staying within size limits for efficient retrieval.
- Window Settings: We defined profiles like "512-cap" with MIN=380, TARGET=480, MAX=512 tokens. This gives flexibility without wild variance.
- Unit Preparation:
- Split paragraphs into sentences using SpaCy or blingfire.
- Generate sentence embeddings with
bge-small-en(fast, outperforms older models like all-MiniLM). - Compute adjacent similarities: For each sentence i,
sim[i] = cosine(mean(emb[i-2:i]), mean(emb[i+1:i+3])). This detects topic drifts over short spans.
- Candidate Identification:
- Evaluate cut points only in [MIN, MAX] (e.g., 380-512).
- Handle sub-MIN: Delay cuts and boost overlap to 18-20% (≤80 tokens) for continuity.
- Atomic exceptions: For tables/forms starting before MIN, cut early but re-balance by borrowing ≤80 tokens from prior chunks.
1 - cosine_sim: Prioritizes topic drifts (weight 0.6).structure_boost: +1.0 for headings, +0.2 for paragraph ends.cue_boost: +0.3 for words like "However" or "Conclusion".length_penalty: Favors targets near 480 tokens.
- Local Re-balancing: Use a 3-chunk rolling window to adjust boundaries:
- Ensure lengths in [MIN, MAX].
- Maximize total scores; limit shifts to ≤80 tokens per boundary, ≤120 total.
- Commit oldest chunk and slide forward.
- Trigger re-balancing for short chunks: Borrow from previous if possible; else, increase overlap.
- Overlap Policy:
- Default: 10-15% (≤80 tokens).
- Strong boundaries: 5-10%.
- Weak: 15-20%.
- Tables/forms: 0% (replicate headers if split).
- Atomic Rules:
- Keep tables intact; split rows if oversized, replicate headers.
- Forms: Minimal overlap (≤5%).
- Figures: Attach captions.
- Metadata: Each chunk gets tags like doc_id, token_len, is_table, boundary_score, rebalanced.
Boundary Scoring: Use this formula for each candidate c:
score = 0.6 * (1 - cosine_sim) + structure_boost + cue_boost - 0.2 * ((len_c - TARGET) / TARGET)**2
Thresholds: Strong shift if cosine < 0.78; sharp drop if Δcosine > 0.15. Pick the highest score; fallback to paragraph ends if none.
This dynamic method ensures chunks are semantically coherent - e.g., a veterinary procedure isn't split awkwardly - while adaptive overlap prevents context loss. Compared to static, it's more compute-intensive upfront (due to embeddings) but yields superior retrieval.
4. Pre-Index Filtering
Drop junk: Boilerplate, short text (<180 chars), poor OCR (<0.55 confidence), empty tables. Penalize low-quality; promote headings and numeric tables.
5. Embedding & Indexing
- Model: NV-Embed-v2 (4096 dims, cosine similarity). Why? Tops MTEB benchmarks, Mistral-7B base, self-hostable.
- Indexing: HNSW with M=32, ef_construction=200-400, ef_search=128.
- Metadata: Includes ocr_conf, section_path.

Results: Measurable Improvements and Benefits
Switching to this pipeline, especially dynamic chunking, transformed our RAG performance.
| Aspect | Static Chunking | Dynamic Chunking (with Adaptive Overlap) | Benefit |
|---|---|---|---|
| Chunk Size | Fixed (e.g., 512 tokens) | Variable (e.g., 380–512 tokens) based on topic shifts | Captures natural section boundaries |
| Overlap | None or fixed (0–10%) | Adaptive (10–20%) depending on boundary confidence | Preserves context across related chunks |
| Boundary Logic | Cuts by length only | Cuts at semantic transitions detected via embeddings | Reduces topic mixing and noise |
| Embedding Use | Only for retrieval | Also for boundary detection | Ensures content and retrieval are semantically aligned |
| Context Quality | May split sentences or sections mid-flow | Keeps coherent ideas intact | Improves readability and retrieval precision |
| Implementation Effort | Simple to set up | Moderate (requires sentence embeddings and scoring) | Higher upfront effort, better long-term accuracy |
| Best Used For | Quick prototypes, uniform datasets | Production RAG systems with diverse document structures | Scales better with complex or mixed content |
Benefits: Cleaner chunks cut hallucinations; dynamic boundaries boost recall for veterinary queries (e.g., full dosage tables retrieved intact). Scalable for 1.44M pages, with consistency from re-balancing.
Key Takeaways
Smarter chunking isn't just a tweak - it's a force multiplier for RAG systems. By going dynamic, we proved that refining data prep outperforms scaling LLMs alone. For engineers: Start with semantic embeddings for boundaries and adaptive overlap; it pays off in accuracy. In veterinary AI, this means reliable answers for real-world use. Next time you're tempted by bigger models, ask: Is your chunking smart enough?
Note: This strategy evolved from hands-on iteration - try it on your corpus!



