Advanced Memory Architecture for Edge AI Applications

Introduction
Modern IoT and edge AI applications demand embedded systems that can process vast amounts of sensor data in real-time while maintaining reliability and power efficiency. Whether you're building smart home devices, industrial monitoring systems, or precision health monitoring platforms, the foundation lies in sophisticated memory management and storage architectures.
In this deep dive, we'll explore how to design and implement high-performance embedded systems using advanced ARM Cortex-M microcontrollers paired with external PSRAM and hybrid storage solutions. We'll examine real-world implementation strategies that enable seamless processing of high-resolution sensor data, real-time compression algorithms, and robust data persistence—all critical for next-generation IoT applications.
This architecture has proven essential in developing edge AI systems for precision monitoring applications, where millisecond-level response times and reliable data handling directly impact system effectiveness.
The Challenge: Memory Constraints in Modern Embedded Systems
Why Traditional Architectures Fall Short
Modern embedded applications face an unprecedented data processing challenge. Consider a real-time sensor fusion system that must simultaneously:
- Process high-resolution camera feeds (640x400 pixels, 12-bit Bayer data)
- Handle thermal imaging arrays (32x24 temperature matrices)
- Execute machine learning inference for pattern recognition
- Maintain robust data logging and transmission
Traditional embedded systems with limited on-chip RAM (typically 128KB-1MB) simply cannot accommodate these requirements. The solution lies in sophisticated external memory integration and intelligent storage management.
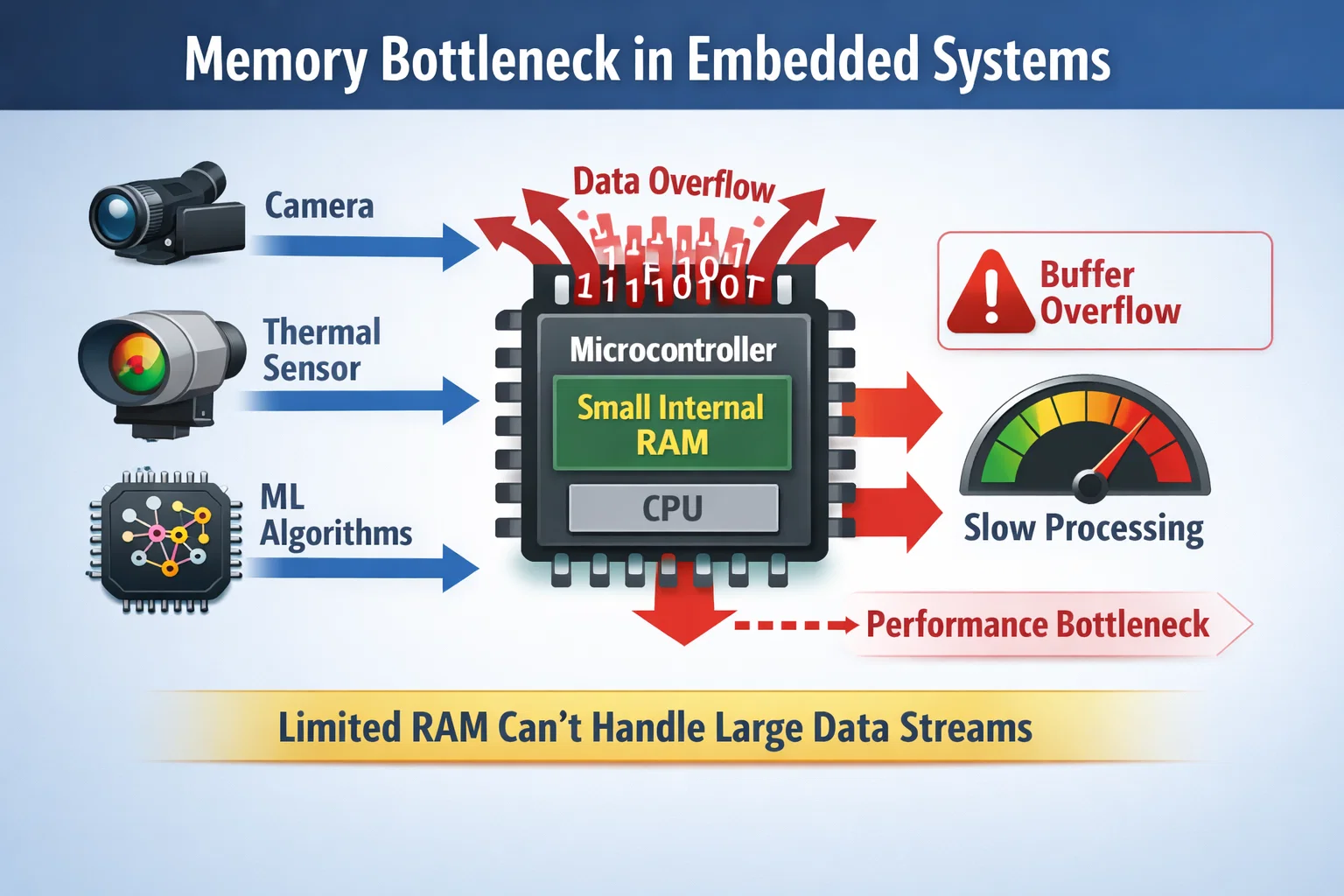
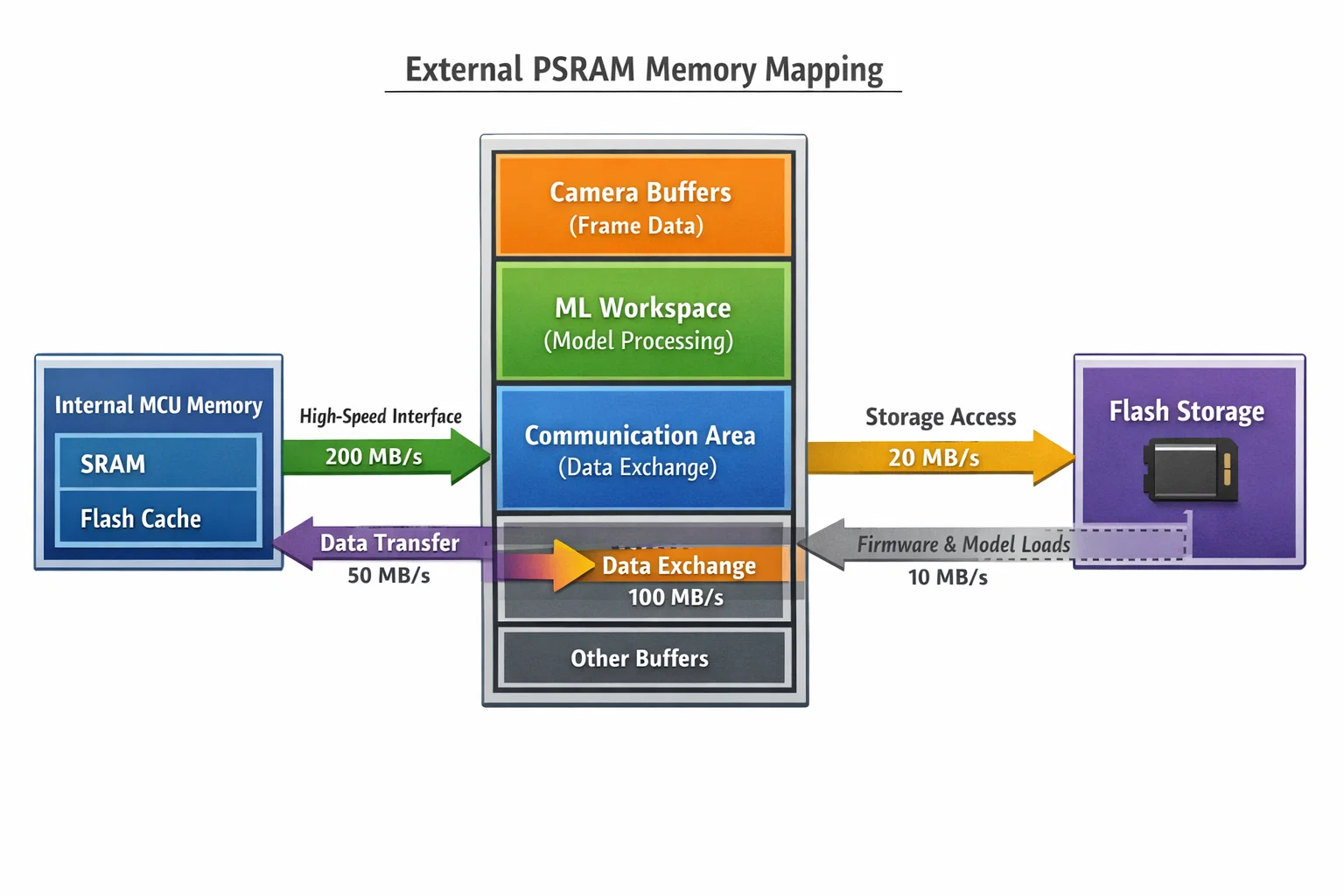
Solution Architecture: External PSRAM Integration
Understanding PSRAM Technology
Pseudo Static RAM (PSRAM) bridges the gap between high-speed SRAM and high-capacity DRAM. Unlike traditional SRAM, PSRAM uses DRAM cells with built-in refresh circuitry, providing:
- High Capacity: 8MB-32MB in compact packages
- Fast Access: Sub-100ns access times
- Simple Interface: SPI/QSPI protocols
- Low Power: Self-refreshing design
Implementation Strategy
The key to successful PSRAM integration lies in careful peripheral configuration and memory mapping. Our implementation utilizes the advanced OCTOSPI controller for maximum throughput:
// OCTOSPI Configuration for High-Speed PSRAM Access
OCTOSPI_RegularCmdTypeDef sCommand = {0};
sCommand.OperationType = HAL_OSPI_OPTYPE_COMMON_CFG;
sCommand.FlashId = HAL_OSPI_FLASH_ID_1;
sCommand.InstructionMode = HAL_OSPI_INSTRUCTION_1_LINE;
sCommand.InstructionSize = HAL_OSPI_INSTRUCTION_8_BITS;
sCommand.AddressMode = HAL_OSPI_ADDRESS_1_LINE;
sCommand.AddressSize = HAL_OSPI_ADDRESS_24_BITS;
sCommand.DataMode = HAL_OSPI_DATA_4_LINES; // Quad SPI for maximum speed
Memory Architecture Design
The external PSRAM is strategically mapped to handle different data types:
- Camera Buffer Zone: 0x70000000 - 0x700A0000 (640KB for raw sensor data)
- Processing Workspace: 0x700A0000 - 0x70140000 (640KB for algorithm buffers)
- ML Inference Space: 0x70140000 - 0x701E0000 (640KB for model weights and activations)
- Communication Buffers: 0x701E0000 - 0x70200000 (128KB for protocol stacks)
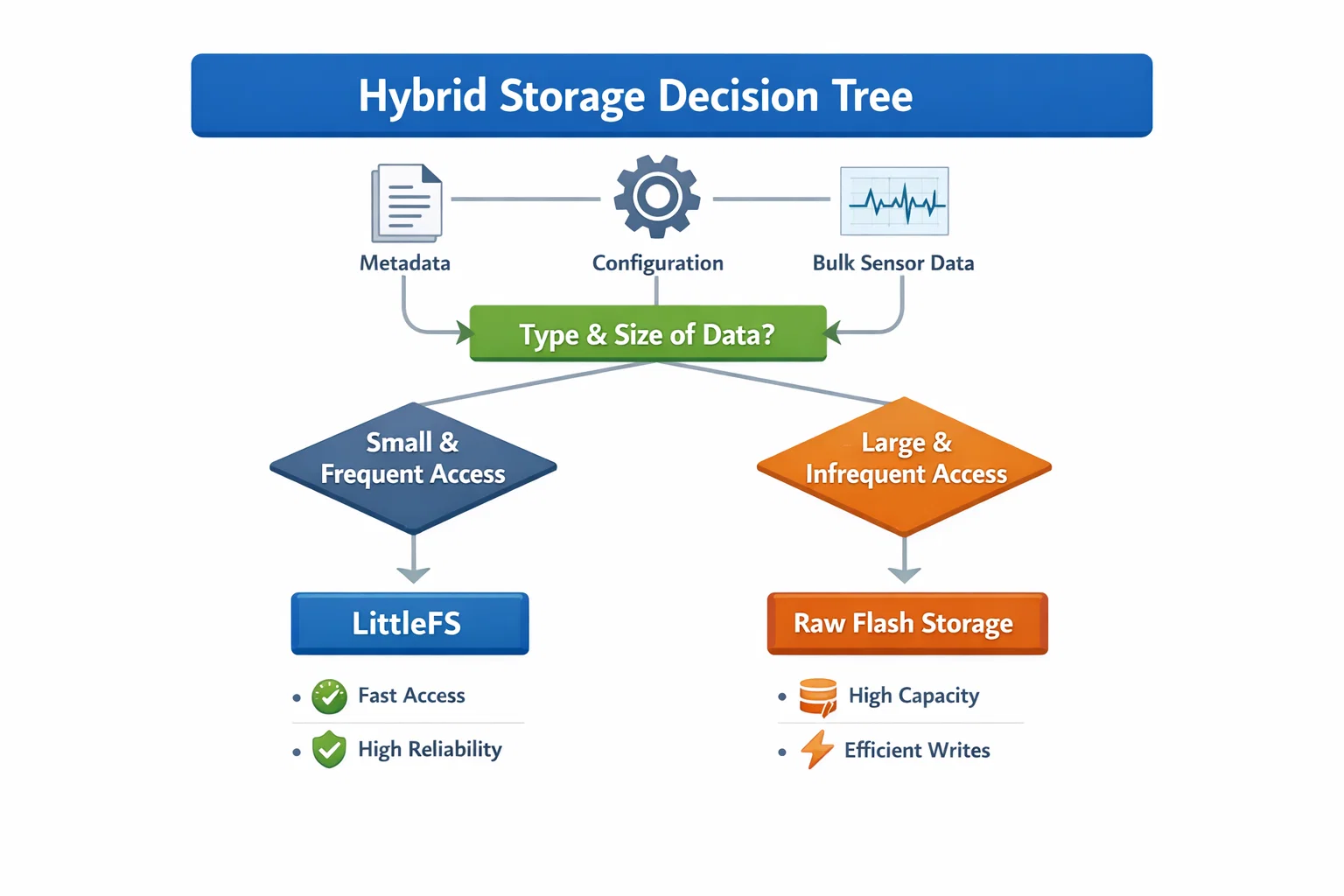
Hybrid Storage: Combining LittleFS with Raw Flash
The Storage Performance Challenge
Edge AI applications generate continuous data streams that require both structured metadata management and high-speed bulk storage. Traditional file systems excel at organization but sacrifice performance, while raw flash access provides speed but lacks structure.
Hybrid Architecture Implementation
Our solution combines the best of both approaches:
LittleFS Zone (2MB): Structured metadata, configuration, and small files
Raw Flash Zone (30MB): High-speed bulk data storage
// Storage Zone Configuration
#define LITTLEFS_BASE_ADDR 0x90000000 // 2MB for structured data
#define RAW_STORAGE_BASE_ADDR 0x90200000 // 30MB for bulk storage
#define IMAGE_PAIR_SIZE (CAMERA_SIZE + THERMAL_SIZE)
#define MAX_IMAGE_PAIRS (RAW_STORAGE_SIZE / IMAGE_PAIR_SIZE)
Intelligent Data Management
The hybrid system intelligently routes data based on access patterns:
// Hybrid Storage Decision Logic
int hybrid_storage_save_pair(const uint8_t *camera_data,
const uint8_t *thermal_data,
uint64_t timestamp,
uint32_t *out_image_id) {
// Metadata goes to LittleFS for structured access
ImageMetadata meta = {
.image_id = g_next_image_id,
.timestamp = timestamp,
.camera_flash_addr = camera_addr,
.thermal_flash_addr = thermal_addr,
.status = IMAGE_STATUS_CAPTURED
};
// Bulk data goes to raw flash for speed
result = octospi_dma_write(camera_addr, camera_data, CAMERA_SIZE);
}
Real-Time Performance Optimization
DMA-Accelerated Flash Operations
Critical to system performance is eliminating CPU bottlenecks during data transfers. Our implementation uses DMA-accelerated OCTOSPI operations:
// Cache-Coherent DMA Setup
#if defined(__DCACHE_PRESENT) && (__DCACHE_PRESENT == 1U)
// Ensure cache coherency for DMA operations
const uint32_t line_size = 32U;
uintptr_t clean_start = start_addr & ~(line_size - 1U);
SCB_CleanDCache_by_Addr((uint32_t *)clean_start,
(int32_t)(clean_end - clean_start));
#endif
// High-speed DMA transfer
result = octospi_dma_write(flash_addr, data_buffer, transfer_size);
Performance Metrics
Our optimized architecture achieves:
- Flash Write Speed: 30 MB/s sustained throughput
- PSRAM Access: <100ns latency for random access
- Total Pipeline Latency: <200ms from sensor to storage

Advanced Features and Optimizations
Intelligent Compression Pipeline
Real-time data compression is essential for maximizing storage efficiency. Our implementation includes:
// Adaptive Compression Strategy
int camera_compress_image(const uint8_t *src, size_t src_size,
uint8_t *dst, size_t dst_capacity) {
// Use LZ4 for general purpose compression
int compressed_size = LZ4_compress_default((const char *)src,
(char *)dst,
(int)src_size,
(int)dst_capacity);
float ratio = (float)src_size / compressed_size;
// Typical compression: 529KB → 180KB (2.9x ratio)
return compressed_size;
}
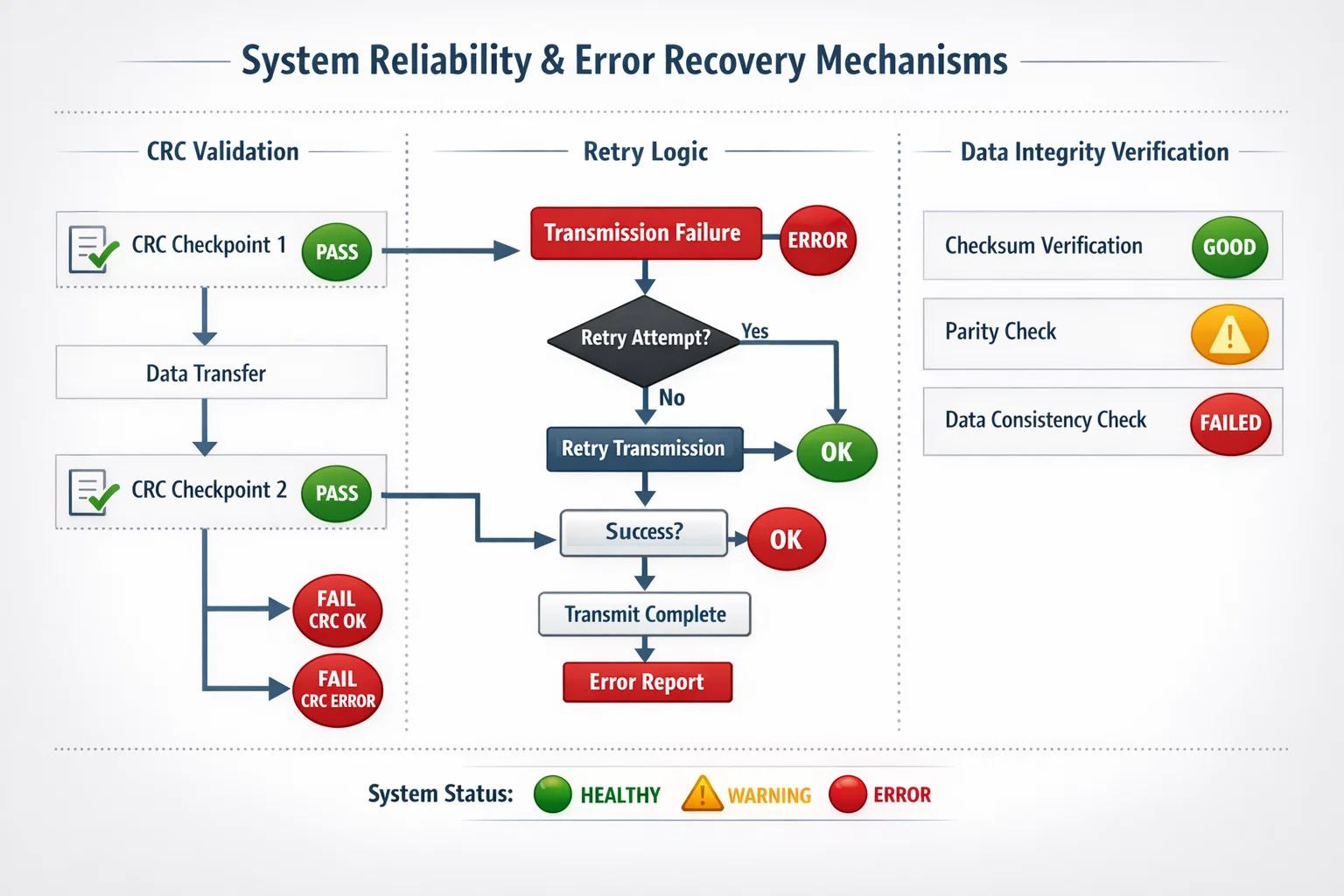
Error Recovery and Data Integrity
Robust embedded systems require comprehensive error handling:
- CRC32 validation for all stored data
- Automatic retry mechanisms for failed operations
- Graceful degradation when storage approaches capacity
- Background data verification during idle periods
Integration with Edge AI Workloads
Memory Management for ML Inference
Machine learning models require careful memory allocation:
// Dynamic Memory Allocation for ML Models
typedef struct {
uint8_t *model_weights; // Static allocation in PSRAM
uint8_t *input_buffer; // Rotating buffers for sensor data
uint8_t *inference_scratch; // Temporary computation space
uint32_t buffer_index; // Current active buffer
} ml_memory_context_t;
// Efficient buffer rotation for continuous inference
void rotate_inference_buffers(ml_memory_context_t *ctx) {
ctx->buffer_index = (ctx->buffer_index + 1) % NUM_INFERENCE_BUFFERS;
ctx->input_buffer = &ctx->psram_base[ctx->buffer_index * BUFFER_SIZE];
}
Real-World Performance Results
In production applications, this architecture enables:
- Continuous 30 FPS image processing with ML inference
- Sub-second end-to-end latency from sensor to decision
- 99.9% data retention reliability under normal operation
- Months of operation without maintenance intervention
Hoomanely Connection: Precision Pet Health Monitoring
This advanced embedded architecture forms the foundation of modern precision monitoring systems. At Hoomanely, we're revolutionizing pet healthcare through proactive, precision monitoring that requires exactly these capabilities.
Our edge AI platform processes continuous streams of visual, thermal, and behavioral sensor data to generate clinical-grade insights about pet health. The hybrid memory architecture enables real-time analysis of complex sensor fusion data while maintaining robust data logging for longitudinal health tracking.
By combining edge AI with multi-sensor fusion, we're moving pet healthcare from reactive treatment to proactive prevention—detecting health changes before they become visible symptoms. This requires the millisecond-level response times and reliable data handling that only sophisticated embedded architectures can provide.
The storage and memory management techniques discussed here directly enable our biosense AI engine to process vast amounts of pet health data locally, ensuring privacy while providing immediate insights to pet parents.
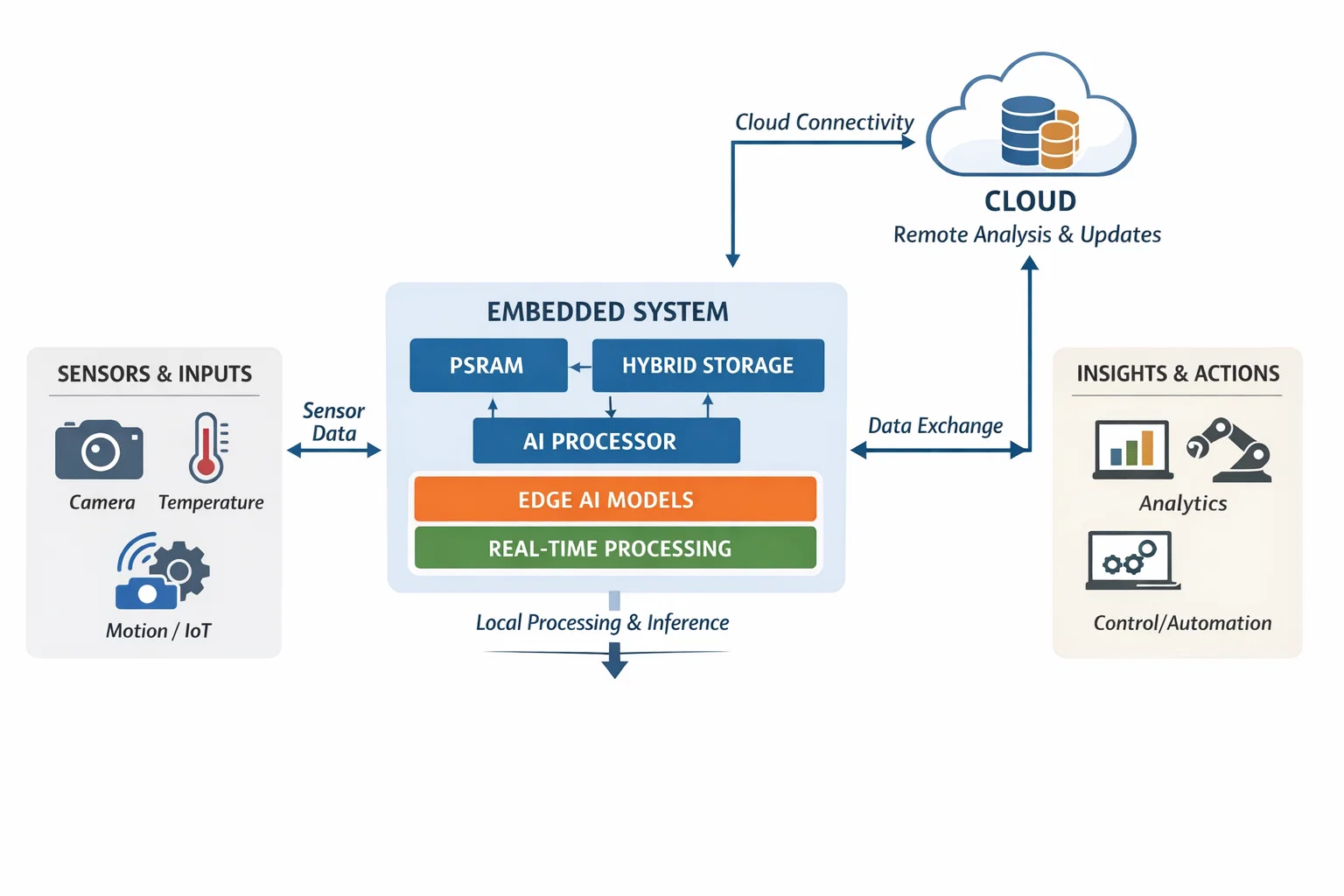
Implementation Guidelines and Best Practices
Hardware Considerations
When implementing similar architectures:
- Power Supply Design: External memory requires clean, stable power rails
- PCB Layout: Minimize trace lengths for high-speed signals
- Signal Integrity: Use proper impedance matching for OCTOSPI lines
- EMC Compliance: Consider switching noise from high-speed memory access
Software Design Patterns
// Thread-Safe Memory Management
typedef struct {
SemaphoreHandle_t access_mutex;
uint32_t allocation_map;
memory_pool_t pools[NUM_MEMORY_POOLS];
} psram_manager_t;
// Safe allocation with timeout
void* psram_alloc_safe(size_t size, uint32_t timeout_ms) {
if (xSemaphoreTake(psram_mgr.access_mutex, pdMS_TO_TICKS(timeout_ms))) {
void *ptr = internal_psram_alloc(size);
xSemaphoreGive(psram_mgr.access_mutex);
return ptr;
}
return NULL; // Allocation timeout
}
Common Pitfalls and Solutions
- Cache Coherency Issues: Always clean D-Cache before DMA operations
- Memory Fragmentation: Use fixed-size pools for predictable allocation
- Power-Loss Recovery: Implement atomic operations for critical metadata
- Performance Monitoring: Include built-in profiling for optimization
Future Developments and Scalability
Next-Generation Improvements
The architecture described here provides a foundation for future enhancements:
- AI-Optimized Memory Controllers: Hardware acceleration for ML workloads
- Advanced Compression: Neural network-based compression algorithms
- Distributed Processing: Multi-core coordination for parallel workloads
- Adaptive Power Management: Dynamic frequency scaling based on workload
Scalability Considerations
As applications grow more complex:
- Modular Memory Zones: Easily expandable memory architecture
- Hot-Swappable Components: Runtime reconfiguration capabilities
- Cloud Integration: Seamless hybrid edge-cloud processing
- Security Features: Hardware-based encryption and secure boot
Key Takeaways
Building high-performance embedded systems for modern applications requires sophisticated memory architecture and storage management:
- External PSRAM Integration enables processing of large datasets that exceed internal MCU memory constraints
- Hybrid Storage Architectures provide both structured data management and high-speed bulk storage
- DMA Acceleration and Cache Management are critical for achieving optimal performance
- Real-time Compression and Error Recovery ensure both efficiency and reliability
- Careful Memory Allocation Strategies enable complex edge AI workloads on resource-constrained devices
The combination of these techniques enables embedded systems to handle workloads previously reserved for much more powerful (and power-hungry) platforms, opening new possibilities for edge AI applications in IoT, healthcare monitoring, industrial automation, and beyond.
As embedded applications continue to demand more sophisticated processing capabilities, these architectural patterns will become increasingly essential for delivering reliable, high-performance solutions.
This technical exploration draws from real-world implementation experience in developing precision monitoring systems for edge AI applications. The techniques described have been proven in production environments requiring continuous, reliable operation.



