App-Driven Adaptive Sampling for Wearables

Adaptive sampling turns your wearable into a system that feels alive—delivering the right data at the right moment while preserving battery for when it matters. Instead of locking sensor rates in firmware, we set behavior at the app layer with a small, transparent policy engine. The device advertises capabilities; the app selects named profiles (ULP, Balanced, Hi-Fi, Burst) based on motion, battery, link quality, and user intent. This keeps firmware simple, makes iteration fast (via remote config/A/B), and aligns data fidelity with product goals—better models, longer life, happier users. In this post we’ll walk through the architecture, a declarative policy table, burst capture around key moments, observability that guides tuning, and rollout patterns that teams can adopt quickly across wearables, pet tech, and sensor-rich IoT.
Problem
Fixed sensor rates are tidy in a spreadsheet but rarely optimal in the real world. User behavior is bursty, link quality fluctuates, and battery state changes across a day. Always-high rates waste energy when the device is idle; always-low rates miss sub-second events that matter to detection pipelines. Worse, baking rate logic into firmware slows iteration—every threshold change becomes a rebuild and rollout.
What we want instead:
- High fidelity when it matters (run starts, impacts, tremor-like motion).
- Low power when it’s safe (sleep, desk work, stationary bowl/collar).
- Fast iteration through app-side policy updates, not firmware reflashes.
- Observability so decisions are explainable and tunable.
Approach
Principles
- Capabilities in firmware; behavior in the app. The device exposes what it can do (supported rates/modes). The app picks what it should do now.
- Profiles + policy. Bundle sensor modes into a few named profiles; a small policy engine selects among them based on context.
- Atomic application. Profile changes apply at safe boundaries with explicit acknowledgments and echoed effective rates.
- Observability from day one. Log decisions, reasons, apply latency, and dwell times.
- Remote config & A/B. Treat policy as data. Ship it safely and roll back instantly.
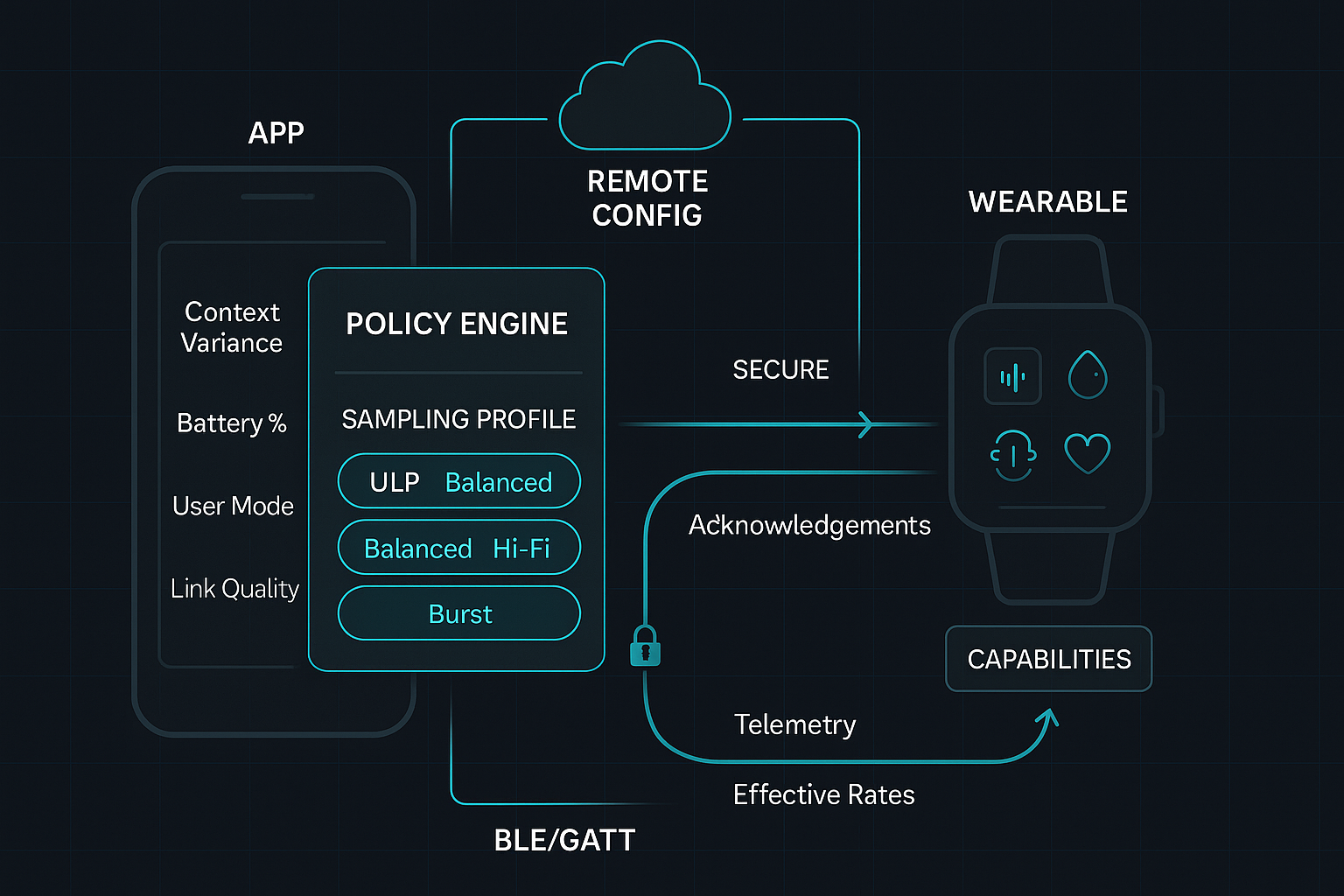
Reference Architecture
- Mobile app (Flutter or native):
- Policy engine evaluating context every 10–30 s.
- Remote config loader (flags, policy table, dwell/hysteresis).
- BLE/GATT client (or TCP/MQTT if applicable) to send “apply profile”.
- Telemetry logger (decisions + acknowledgments).
- Wearable firmware:
- Capabilities descriptor (supported rates per sensor, limits).
- Profile interpreter (maps profile → driver settings).
- Atomic apply at frame boundaries, with ack + echo of effective config.
- Backend:
- Feature flags/remote config store.
- Analytics for A/B, dwell distributions, and guardrail monitoring.
- Optional “risk window” hints pushed to app.
Process
Think of adaptive sampling as a small control system: we define stable states (profiles), observe a handful of signals, add hysteresis so we don’t chatter, and record every decision.
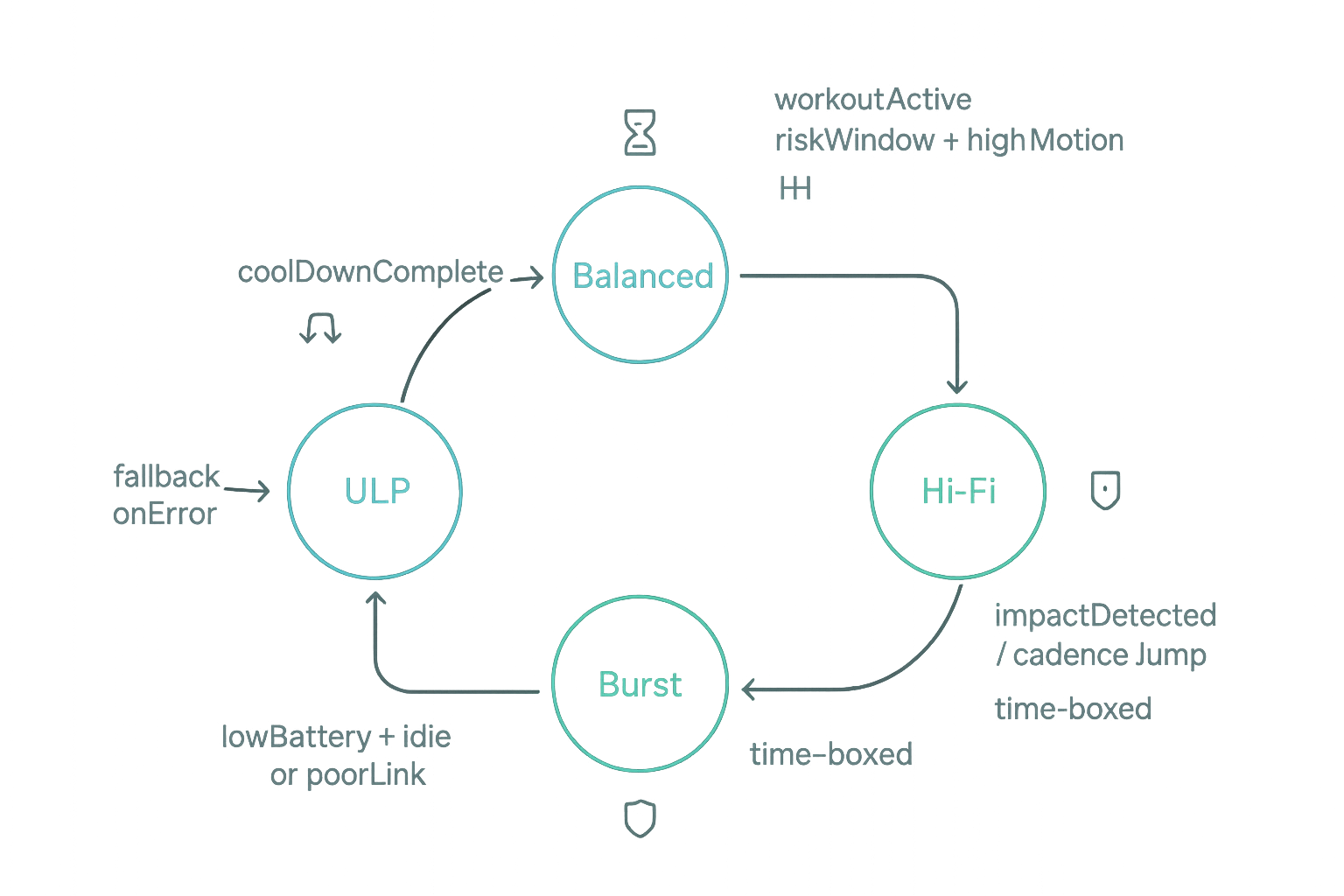
1) Define four pragmatic profiles
Profiles must be explicit, atomic, and cheap to apply. Start with:
- ULP (Ultra-Low Power): IMU 12.5 Hz, baro 0.1 Hz, HR off, GPS off; BLE batching every 30–60 s.
- Balanced: IMU 25–50 Hz, baro 0.5 Hz, HR 0.5 Hz; BLE batching every 10–20 s.
- Hi-Fi: IMU 100 Hz, baro 1 Hz, HR 1 Hz; streaming or short batches.
- Burst (time-boxed): IMU 200 Hz for 10–30 s around detected onsets (impacts, cadence jumps), then taper.
If your device tops out at 100 Hz IMU, adjust Hi-Fi/Burst accordingly. Explicitly budget bursts (e.g., ≤2 min/hour) so battery models stay honest.
App-side config (remote-updatable):
profiles:
ulp: { imu_hz: 12.5, baro_hz: 0.1, hr_hz: 0, gps: off, ble_batch_s: 45 }
balanced: { imu_hz: 50, baro_hz: 0.5, hr_hz: 0.5, gps: ondemand, ble_batch_s: 15 }
hi_fi: { imu_hz: 100, baro_hz: 1.0, hr_hz: 1.0, gps: ondemand, ble_batch_s: 5 }
burst: { imu_hz: 200, duration_s: 20 }
2) Choose robust context signals
You don’t need a large model to get big wins. Start with interpretable features:
- Motion intensity: Rolling variance of |a| over 3–10 s, with hysteresis.
- Cadence buckets: From steps/zero-crossings—distinguish stroll vs. run.
- Battery: SoC tiers (<25%, 25–60%, >60%) and slope (Δ%/hr) to catch fast drains.
- Link health: RSSI bands and recent write/notify error counts.
- User modes: Explicit workout/sleep/DND toggles—intent always trumps heuristics.
- Risk windows (optional): Server-pushed periods where missing events is costly.
- On-device activity (optional): Tiny classifier (still/walk/run/vehicle) to gate upshifts.
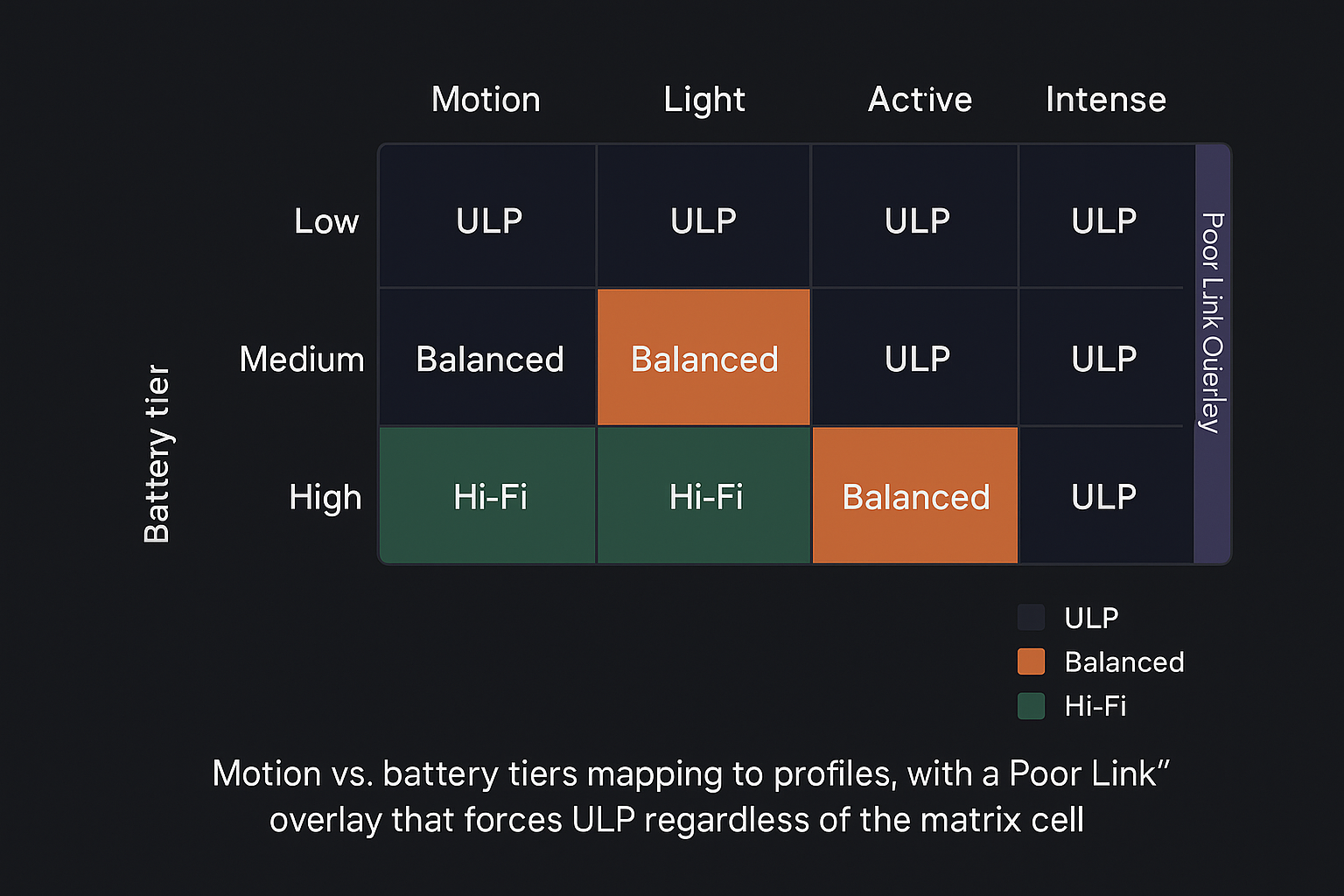
3) Express decisions in a declarative policy table
Policies age poorly when scattered across if/else ladders. Keep them centralized and data-driven.
dwell_seconds: 15
hysteresis:
motionVar: { up: 0.15, down: 0.10 }
rules:
- when: { workoutActive: true } # user intent dominates
then: hi_fi
- when: { riskWindow: true, motionVar: ">0.8" } # high risk + high motion
then: hi_fi
- when: { poorLink: true }
then: ulp
- when: { soc: "<25", isCharging: false, motionVar: "<0.1" }
then: ulp
- default: balanced
Why this works: Dwell prevents flip-flop; hysteresis removes edge thrash; rules stay readable and testable; remote config lets you ship safely.
4) Build the policy engine
Keep it deterministic and loggable. Evaluate on a fixed cadence (e.g., every 15 s) or on significant context change.
enum Profile { ulp, balanced, hiFi, burst }
class Context {
final double motionVar; // 0..1 normalized variance over last N seconds
final int soc; // battery %
final bool isCharging;
final bool workoutActive;
final bool poorLink; // RSSI/packet loss heuristic
final bool riskWindow; // from server
const Context(...);
}
Profile pickProfile(Context c) {
if (c.workoutActive) return Profile.hiFi;
if (c.riskWindow && c.motionVar > 0.8) return Profile.hiFi;
if (c.poorLink) return Profile.ulp;
if (!c.isCharging && c.soc < 25 && c.motionVar < 0.1) return Profile.ulp;
return Profile.balanced;
}
5) Design the command path and acknowledgments
Use one characteristic for “apply profile.” Send idempotent, tiny commands:
- Profile ID (1 byte), params (e.g., burst duration), policy version, txn id.
- Apply at a safe boundary (e.g., next 250 ms tick).
- Device echoes effective rates + result code (OK/Unsupported/Busy) and increments a segment counter for downstream analytics.
Future<void> apply(Profile p) async {
final cmd = switch (p) {
Profile.ulp => [0x01, 0x0C, 0x00, 0x00], // id + encoded params
Profile.balanced => [0x02, 0x32, 0x05, 0x05],
Profile.hiFi => [0x03, 0x64, 0x0A, 0x0A],
Profile.burst => [0x04, 0xC8, 0x14, 0x00], // 200 Hz for 20 s
};
await ble.write(characteristic: SAMPLING_CHAR, value: cmd, withResponse: true);
// Expect ack within ~300 ms on 2M PHY; log reason + latency
}
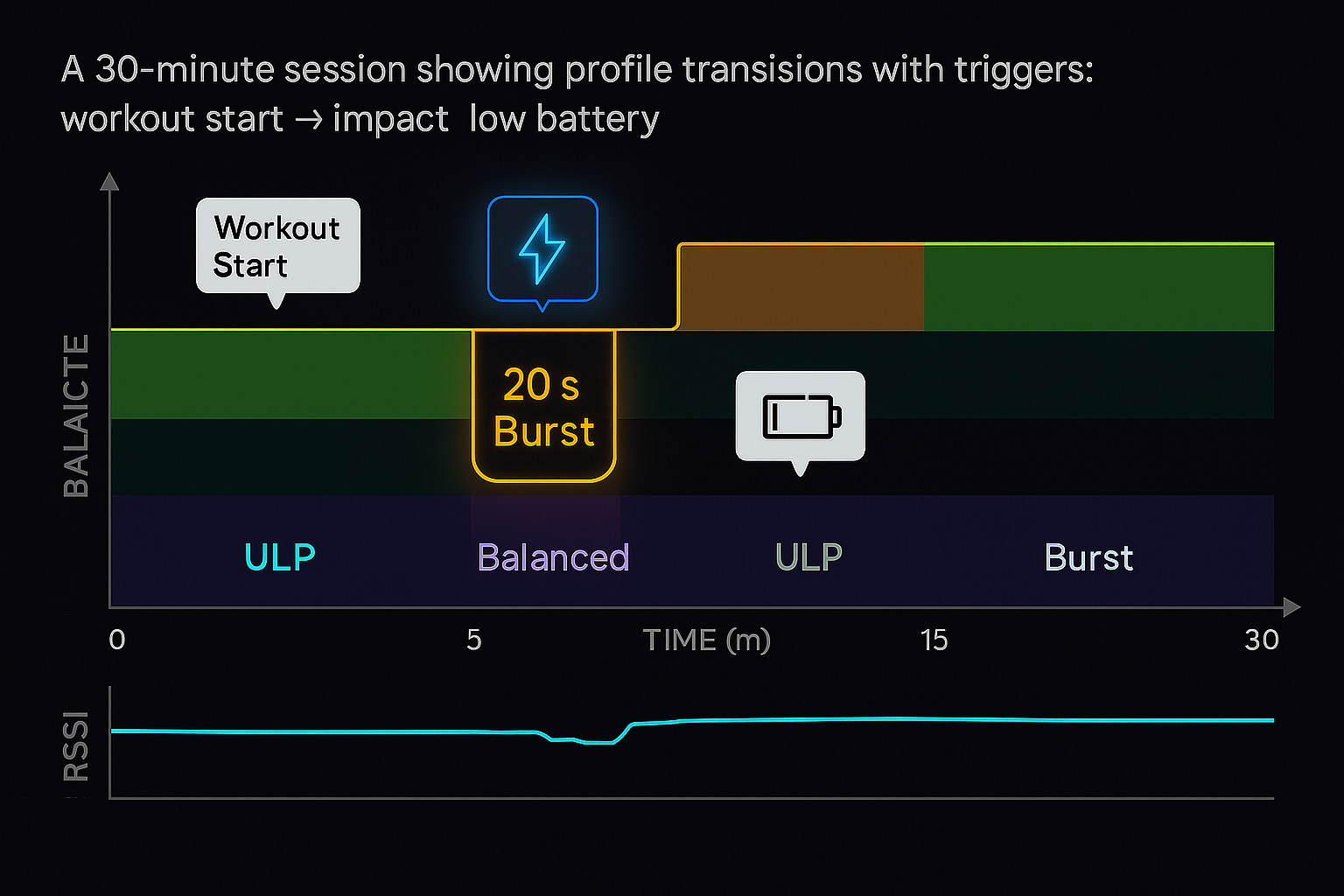
6) Implement burst capture for high-value moments
Burst is how you “pay only when you must.”
- Triggers: impulse peaks, cadence jumps, workout start, sharp orientation change, server-hinted windows.
- Duration: 10–30 s to capture onset and settle.
- Guardrails: cap bursts/hour and daily budget; cool-down between bursts; cancel on brown-out or persistent poor link.
- Tagging: profile ID + burst sequence for alignment; crucial for training/validation pipelines.
7) Balance streaming vs. batching
- Hi-Fi/Burst: stream or use small batches for low latency.
- Balanced/ULP: batch to reduce radio wakeups.
- Compression: delta-RLE and fixed-point quantization often yield 3–5× savings with negligible model impact in steady states.
- Priorities: sensor payloads > metrics/logs. Throttle non-critical telemetry during poor link.
8) Observe it like a control loop
Log and chart:
timestamp, before→after profile, reason predicates, policy_version, txn_id- Apply latency (ms) and ack code
- Profile dwell per day
- Packet loss/retx near transitions
- Battery slope before/after policy changes
Build a small dashboard (PostHog or custom) for cohort views by app build, device revision, and region. When someone asks “Why did it flip to ULP at 3:12 PM?”, show the reason stack—don’t guess.
9) Ship via remote config + A/B
Policies are product levers. Treat them as such:
- Cohorts: by device rev/app build/geography/opt-in.
- Guardrails: max flips/hr, total burst budget/day, kill-switch to force ULP.
- Dry-run evaluate: preview how a new policy would have behaved over yesterday’s telemetry before you expose users.
- Rollout discipline: 5–10% → 25% → 50% → 100% with guardrails and dashboards watching.
10) Add a tiny activity model (when ready)
A 1–2 kB linear/trees model (still/walk/run/vehicle) prunes noise and reduces flip-flops around thresholds. Ship heuristics first; add the model once you have reliable observability.
11) Engineer for safety and simplicity
- Fail-safe ULP: brown-outs, thermal throttles, or repeated apply failures immediately force ULP with a visible reason code.
- Idempotent commands: re-applying the same profile is a no-op.
- Atomic apply: all or nothing with clear errors.
- Backward-compatibility: unsupported profile → “Unsupported,” stay put, report capability mismatch.
Results
Adaptive systems earn trust with numbers and method, not anecdotes. Measure deliberately.
What to measure (and how)
- Battery life
- Metric: hours from 100% → 10% SoC under real daily use.
- Method: A/B matched cohorts over ≥5 days; segment by device rev and climate; exclude obvious hardware faults.
- Guardrails: watch for heavy outliers; track ambient temperature and screen-on time (phone) as covariates.
- Event fidelity
- Metric: precision/recall or detection latency for short events (e.g., <2 s impact, sprint onset, tremor bursts).
- Method: scripted sessions or labeled field snippets; compare static Balanced vs. adaptive with Burst.
- Data volume
- Metric: MB/day per device and per profile dwell.
- Method: combine app logs with backend ingestion stats; attribute reductions to Balanced/ULP batching and compression.
- UX stability
- Metric: profile flips/hour, apply-latency percentiles, command failure rate.
- Method: telemetry pipeline; aim for <6 flips/hour for steady users and median apply latency <300 ms on BLE 2M PHY.
Example outcome frame (replace with your data)
- Battery life: +28–42% median improvement in mixed-use cohorts after adopting ULP for sedentary windows and batching in Balanced.
- Event recall: 3–5× better recall for sub-2 s events when Burst triggers on motion spikes.
- Data reduction: 35–55% lower daily upload without degrading primary model accuracy.
- Stability: <2% command failures across 10k device-days; median apply 180–300 ms; low chatter with 15 s dwell.
If your results fall short, inspect thresholds (too tight), dwell (too low), burst budget (too high), and link heuristics (forcing ULP too often due to conservative RSSI bands).
Applications
This pattern travels well across domains:
- Fitness wearables: Hi-Fi during structured workouts; Burst on sprints; ULP for desk hours; Balanced for casual walks.
- Safety pendants: Stay in Balanced/ULP; Burst on high impulse + orientation change; escalate to Hi-Fi on persistent activity.
- Asset trackers: Duty-cycle GPS; wake only on movement; batch sensors when stationary; adapt to link quality in warehouses vs. outdoors.
- Pet wearables: Raise IMU/baro during play and feeding windows; drop to ULP overnight or when the collar is stationary.
- Smart bowls: Around detected feeding events, temporarily increase sampling for weight/IMU fusion; otherwise stay Balanced with long BLE intervals.
Only the triggers change; profiles + policy stay the same.
Common Issues & Fixes
- Profile chatter (flip-flopping): Increase dwell, widen hysteresis, smooth motionVar (EMA), set a post-Burst cool-down.
- Apply lag feels slow: Align changes to sensor ticks; tighten connection interval; use 2M PHY; keep command payloads tiny; avoid main-thread stalls in the app.
- Data gaps at switches: Double-buffer on device; flush old buffer before apply; tag segments with a monotonic counter.
- Policy drift across versions: Include policy_version in each decision and in the device echo; alert on mismatches.
- Remote-config foot-guns: Server-side validate rules; dry-run on yesterday’s telemetry; maintain a global kill-switch.
- Over-bursting: Cap bursts/hour and per-day; require clear triggers AND cool-down; monitor burst dwell and budget burn-rate.
In Hoomanely’s mission is to keep pets healthier with thoughtful, privacy-aware technology. Adaptive sampling strengthens that mission by extending battery life (more days between charges for wearables and smart bowls) and capturing moments that matter (feeding episodes, unusual activity) without overwhelming storage or analytics systems. By driving behavior from the app, teams can tune quickly, measure responsibly, and keep user experience first—across EverSense-style wearables and EverBowl-class devices, and beyond.
Takeaways
- Keep capabilities in firmware and behavior in the app.
- Model rates as a few named profiles—ULP, Balanced, Hi-Fi, Burst.
- Select profiles with a declarative policy plus dwell and hysteresis.
- Use Burst for short, high-value windows; keep steady states low-rate and sticky.
- Instrument decisions, reasons, apply latency, dwell; iterate via remote config and A/B.
- Publish measured outcomes; let the data speak.



