Breaking the Feed Scaling Wall: Insights from Re-architecting a Production Social Feed

Every social application eventually hits the "Feed Scaling Wall." It usually happens when your first power user follows their 500th account, and your once-snappy SELECT * query starts taking 200ms. Then 500ms. Then timeouts.
To preempt this bottleneck at Hoomanely, we architected our system for scale from Day One. We recognized that optimizing for Write simplicity (saving a post) invariably penalizes Read performance. In a production environment where reads outnumber writes 100:1, a traditional "Pull" approach is a liability.
Instead, we established an asynchronous Fan-out on Write Model as our core foundation, leveraging MongoDB’s high-throughput capabilities to pre-compute feeds. This architectural choice ensured we bypassed the scaling wall entirely.
This architectural deep-dive covers why we abandoned the naive approach, the specifics of our Schema Design (including our specific use of Denormalization), and how we achieved predictable P99 read latencies at scale.
The Read Amplification Bottleneck
Social systems are aggressively read-heavy. A single post is written once but read thousands of times.
Optimizing for write efficiency (simply inserting a row) creates technical debt on the read path. Every feed load forces the database to:
1. Index Scan: Lookup thousands of user_ids (the following list).
2. Random Access: Fetch disparate pages from disk for those users' posts.
3. In-Memory Sort: Merge and sort the result set before returning the top 10.
This is a classic O(N) operation where N is the number of followed users multiplied by their post frequency. It’s computationally expensive and cache-hostile. We needed to invert this relationship.
Why MongoDB?
We didn't choose MongoDB for "hype"; we chose it for specific architectural properties:
1. Schema Polymorphism: A "Post" is rarely uniform. It can be a Poll, Video, Article, or an SOS Alert. Relational tables struggle with this variance (often resorting to EAV patterns or JSON blobs). MongoDB's BSON document structure handles this variance natively.
2. Atomic Arrays & Counters: Features like likes, comments, and view_counts require high-concurrency atomic updates ($inc, $addToSet). Doing this in SQL often demands row-level locking or side-tables.
3. Write Throughput & Sharding: The "Fan-out" pattern generates a massive write multiplier (1 post = 1000 inserts). MongoDB's efficient B-Tree writes and native horizontal scaling (Sharding) allow us to absorb these spikes without creating a bottleneck.
The Approach: Fan-out on Write
We shift the computational load from Read Time to Write Time.
When a user publishes content, we treat it as an event that triggers a "Fan-out" process. We preemptively distribute the post ID to the feed of every follower.
1. The Design Pattern
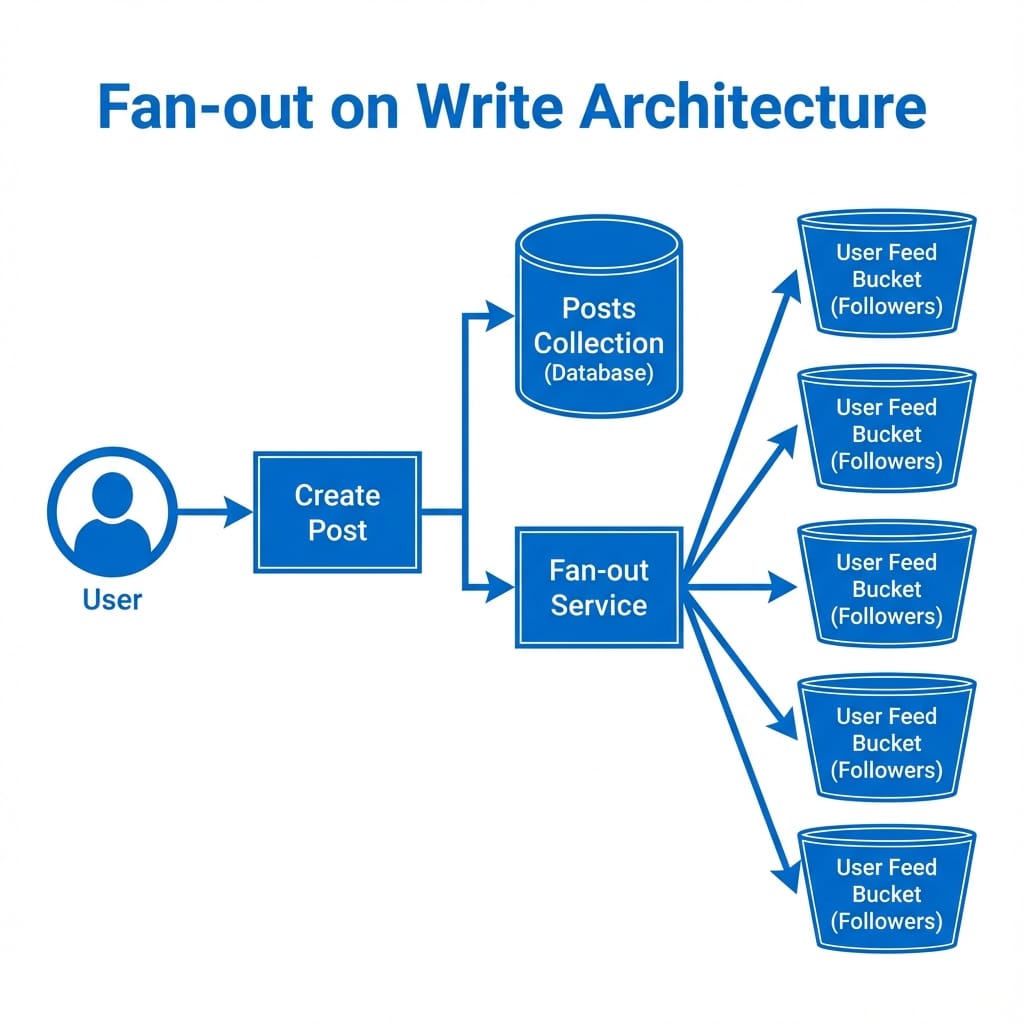
When a user publishes a post:
1. Core Write: The full post object (content, media URLs, location) is saved to the posts collection.
2. Fan-out: We identify the user's followers and insert a lightweight reference into a dedicated personalisedposts collection for each follower.
This incurs Write Amplification: 1 User Post -> 1,000 Follower Inserts.
While this increases storage and write-IOPS, it ensures O(1) Access Time for reads. Since our Read-to-Write ratio is >100:1, trading write complexity for read latency is the correct optimization.
2. The Schema Design
The secret sauce isn't just the architecture; it's the schema. We use two main collections.
The Heavyweight: Post
This holds the actual content. It’s normalized (mostly).
class Post(BaseModel):
id: str # TimeUUID
user_id: str
content: str
media_links: List[str]
location: Location
created_at: datetime
# ... comments, likes, tagsThe Lightweight: PersonalisedPost
This is our "pointer" collection. It is denormalized specifically for feed generation.
class PersonalisedPost(BaseModel):
user_id: str # The FOLLOWER (Viewer)
post_id: str # Reference to the actual Post
priority_post_id: str # The "Smart" Sorting Key
timestamp: datetime
Why this works:
The PersonalisedPost document is tiny. We can fit millions of them in RAM. The priority_post_id is a clever compound key we use for status management.
3. Strategic Denormalization
In distributed systems, strict normalization is often an anti-pattern. We embrace controlled data duplication to minimize "Join" latency.
- Immutable Attributes: We store the author's
nameandavatardirectly on thePostdocument. This eliminates the need to look up theUsercollection during feed rendering. - Eventual Consistency: If a user updates their profile picture, we don't update all their past posts immediately. We accept that historical data may be slightly stale. This trade-off significantly reduces write pressure on the
postscollection. - Cache Locality: By keeping the
PersonalisedPostcollection small (just IDs), we ensure that the "Working Set" for active users' feeds fits entirely in RAM (WiredTiger cache), preventing disk page faults during scrolling.
Optimizing for Scale
While the current architecture handles high load, we have a clear roadmap for the next 10x growth:
- Capped Allocations: Infinite scrolls are rarely infinite. Realistically, users only care about the last 500-1000 posts. We can use TTL (Time-To-Live) indexes on the
personalisedpostscollection to automatically prune old entries, keeping our storage footprint constant per user. - The "Celebrity" Edge Case: For users with 1M+ followers, fanning out 1M writes is too slow. We will implement a Hybrid Model:
- Normal Users: Push-based (Fan-out).
- Celebrities: Pull-based. When you load your feed, we merges your "Push" bucket with "Pull" queries from the celebrities you follow.
- Sharding Strategy: We can shard the
personalisedpostscollection byuser_id. This ensures that all feed entries for a specific user live on the same physical shard, making retrieval a single-server operation even at petabyte scale.
Results & Takeaways
By moving to this Write-Optimized schema, we achieved:
- Consistent Read Latency: Feeds load in <50ms, whether you follow 5 people or 5,000.
- Simplified Pagination: No complex offset queries. We just paginate through the linear
personalisedpostslist. - State Management: "Unread" status is handled without extra lookups.
Trade-offs?
Yes. Writing is slower. Creating a post for a celebrity with 1M followers would require 1M inserts. In those "Celebrity" edge cases, we would likely fall back to a "Pull" model (hybrid approach), but for a community-driven platform like Hoomanely, this architecture provides the perfect balance of performance and complexity.



