Beyond Pitch Shifting: Deep Learning for Smarter Audio Augmentation

Building robust AI models for the real world has a dirty secret: it’s rarely about the model architecture anymore. It’s almost always about the data. In the realm of audio, specifically event detection like identifying a dog’s cough versus a bark, data is noisy, scarce, and incredibly expensive to label.
Traditional data augmentation (adding white noise, shifting pitch, or stretching time) is useful but limited. It creates distorted versions of the original sound, not new ones. You aren't teaching the model what a "different dog" sounds like; you're teaching it what "the same dog on a bad microphone" sounds like.
At Hoomanely, we took a different path. We leveraged Latent Diffusion Models (LDMs) to generate rich, semantically varied audio augmentations. Instead of just distorting data, we dream new variations of it. Here’s a look at the engineering behind our approach.
The Problem: The "Same Dog" Trap
Imagine you are training a model to detect dog anxiety (panting/pacing). You might have 50 clips of Golden Retriever panting. If you use standard augmentation:
- Pitch Shift: It sounds like a smaller Golden Retriever.
- Add Noise: It sounds like a Golden Retriever in the rain.
- Time Stretch: It sounds like a slow Golden Retriever.
In all cases, the underlying timbre and statistical structure remain largely the same. The model overfits to the specific acoustic signature of those 50 dogs. When a Poodle shows up in production, the model fails. We needed a way to produce variations that mimic the natural diversity of real-world recordings.
The Approach: Class-Specific Latent Diffusion
We built a pipeline that uses Generative AI not to create sounds from scratch (text-to-audio), but to create variations of existing samples. This technique allows us to expand our dataset horizontally (more variety) rather than just vertically (more noise).
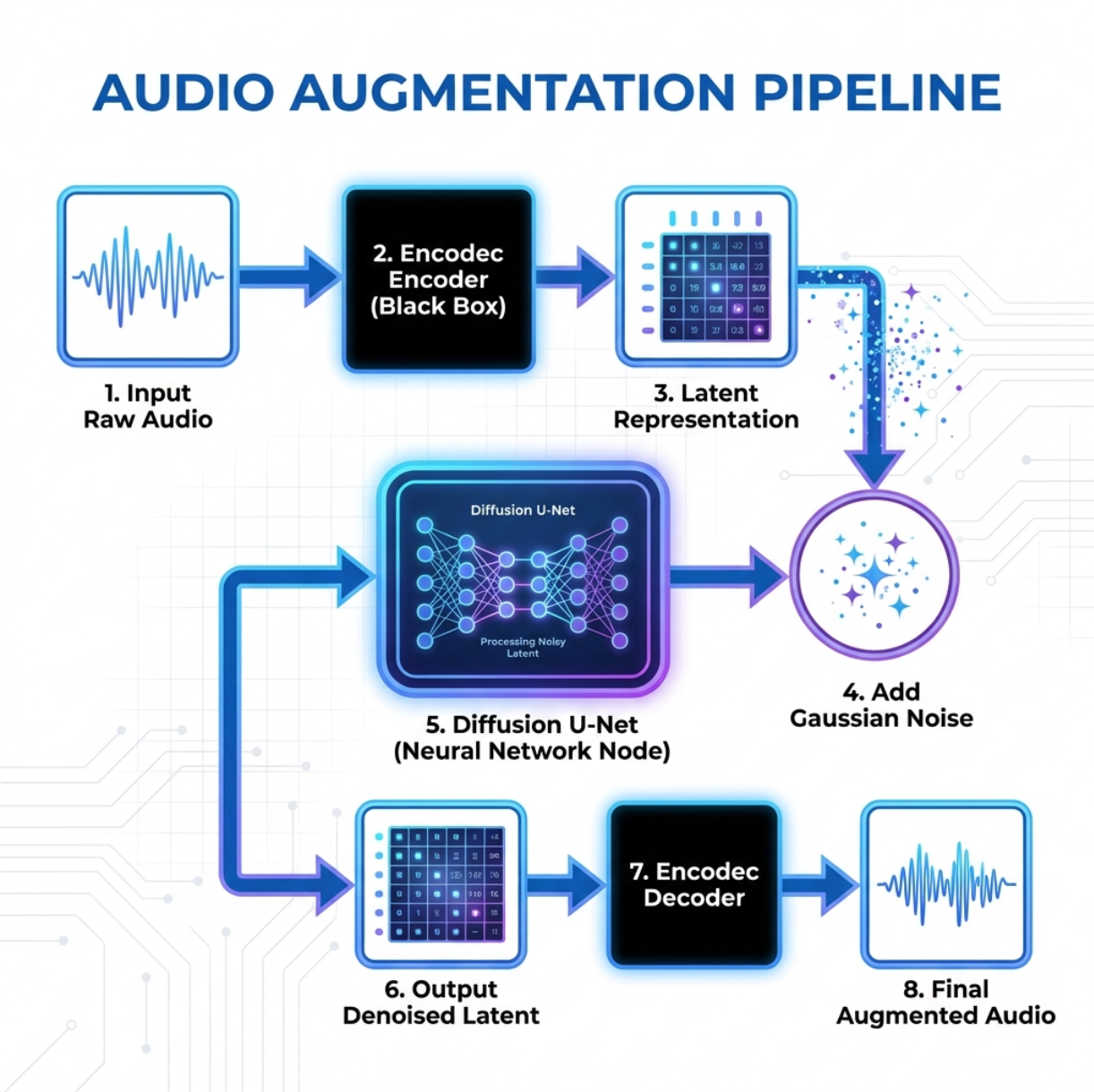
1. Moving to Latent Space (Efficiency First)
Raw audio is high-dimensional (e.g., 24,000 samples per second). Training diffusion models directly on raw waveforms is computationally expensive and slow.
We solve this using Encodec, a state-of-the-art neural audio codec:
- Input: Raw audio (WAV)
- Process: The encoder compresses the audio into a compact latent representation (a sequence of vectors).
- Why it matters: This latent space captures the content and texture of the sound without the heavy redundancy of the raw waveform, allowing diffusion models to train ~10× faster.
2. The Specialist Strategy
Instead of training one massive, general-purpose model, we trained lightweight, class-specific U-Nets:
- A dedicated diffusion model for
bark - Another for
sneeze - Another for
growling
This architectural choice is crucial. By narrowing the domain, each model becomes a highly tailored expert on that specific sound’s texture. A bark model doesn’t need to know how to reconstruct a sneeze, allowing it to focus all its capacity on generating realistic, high-fidelity variations.
3. Variation via Denoising (The SDEdit Method)
This is the core of our augmentation logic. We don’t ask the model to generate a sound from pure random noise (which can be unpredictable). Instead, we use an audio-to-audio approach inspired by SDEdit:
- Start with a real sample: An existing recording of a dog eating.
- Add noise: Corrupt its latent representation with Gaussian noise, destroying fine details while preserving high-level structure (e.g., rhythm and envelope).
- Denoise: Use the trained diffusion model to reconstruct the latent.
- The magic: Because diffusion is probabilistic, the output is not a copy of the original, but a plausible sibling—the same event with slightly different tonal characteristics.
The result is effectively indistinguishable from a different real-world recording of the same event.
Why This Works Better
In our experiments, traditional DSP-based augmentation improved robustness primarily against environmental changes (background noise, microphone quality, room acoustics).
Diffusion augmentation, however, improved robustness against subject variation. By perturbing latent features, we simulate different identities—different dogs, vocal tract sizes, and subtle behavioral differences.
This significantly improved False Positive Rate (FPR) performance. The classifier learned to better reject almost-but-not-quite sounds, reducing spurious alerts while maintaining sensitivity.
Better Ears for Better Care
At Hoomanely, our mission is to extend the lifespan of pets through proactive monitoring. Our Everbowl and home monitoring systems rely on accurate acoustic detection to identify health-related events like reverse sneezing, coughing, or anxiety behaviors.
A model that confuses a human cough with a dog bark is annoying.
A model that misses a dog’s distress signal is unacceptable.
By investing in deep technical approaches like diffusion-based augmentation, we build AI systems that are robust, reliable, and sensitive enough to catch subtle signals that pet parents might otherwise miss.
Takeaways for Engineers
- Don’t diffuse raw data: Use VAEs or neural codecs (e.g., Encodec) to operate in a compressed latent space—it’s cheaper and often better structured.
- Constrain your problem: With labeled data, class-conditional or class-specific models are easier to train and control than fully unconditional ones.
- Perturbation > generation: For augmentation, denoising corrupted real samples often provides a stronger training signal than generating purely synthetic data from scratch.



