Building Stateful Continuity in Stateless LLM Services: A Multi-Tier Session Architecture

Modern AI products feel personal only when they remember:
that bug you were debugging yesterday, the pet profile you set up last month, the long-running coaching thread you keep coming back to.
Under the hood, though, LLM inference APIs don’t remember anything. Every call is a clean slate: you send a prompt, you get tokens back. All the continuity users feel is an illusion built by your backend.
This post walks through a multi-tier session architecture that makes that illusion reliable:
- Sessions survive app restarts, reconnects, and server restarts
- Recovery happens in under a few seconds
- Token overhead for “replaying context” stays predictable instead of exploding over time
We’ll layer state across device, edge, and cloud, use checkpointed snapshots instead of raw logs, and design idempotent replay paths that are safe even when things crash halfway through.
The Problem: Stateful Expectations on Stateless LLMs
Users don’t think in “requests” — they think in sessions:
- “Continue that architecture review from yesterday.”
- “Use the same pet profile as last time.”
- “Pick up this debugging thread on my laptop instead of the phone.”
From a backend perspective, three hard problems show up:
Context bloat and token cost
Naive approach: resend the entire conversation history to the LLM on every call.
Result: token counts grow linearly with time, latency creeps up, and your bill spikes.
Fragile recovery after crashes or reconnects
Mobile app restarts, WebSocket reconnects, pods get cycled. If you keep state only in memory, you either:
- Lose context (“Sorry, I forgot everything”); or
- Replay from a stale snapshot and risk confusing the user (“Wait, we already fixed that”).
Multi-device and long-lived sessions
A single logical session might span:You need a consistent session ID and shared state model, not “whatever that one pod remembers”.
- Multiple devices (phone + web dashboard)
- Multiple backends (chat + analytics + RAG)
- Hours or days of elapsed time
The goal is clear: stateful continuity that doesn’t depend on any single process and doesn’t explode your token budget.
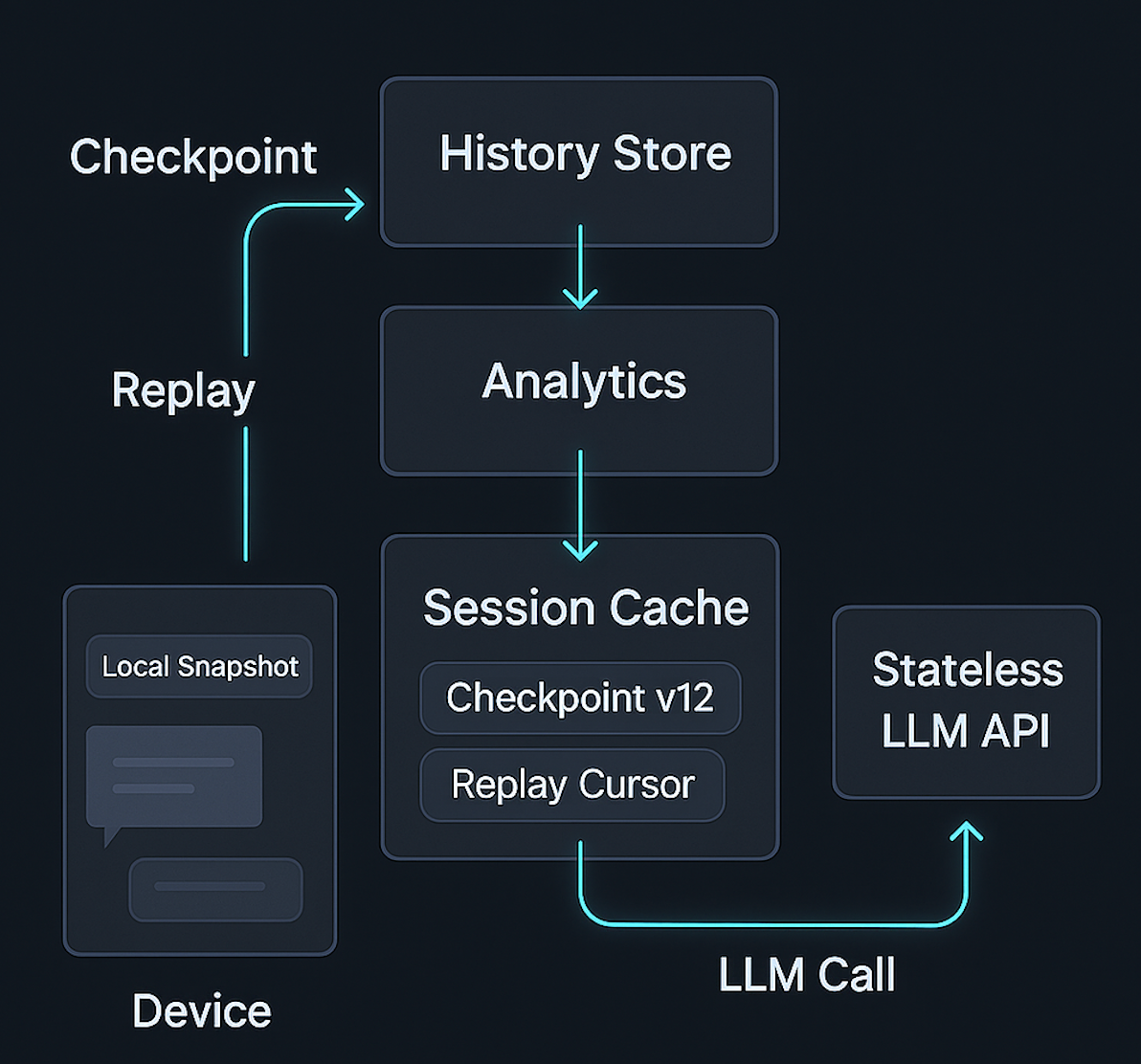
The Approach: Layered Session State Across Device, Edge, Cloud
Instead of a single “session store”, treat state as layered:
Device tier – instant, local continuity
- Holds a small, recent window of the conversation + last-known summaries.
- Used for quick UI restore and short reconnections (e.g., app foreground/background).
- Can work with temporary offline actions or queued requests.
Edge tier – fast, hot session cache
- Lives close to your inference gateway (e.g., Redis, regional store, or in-memory service with replication).
- Stores hot sessions: last few checkpoints, recent requests, and replay metadata.
- Optimized for sub-10 ms access and sub-3 s full recovery.
Cloud tier – durable, canonical history
- Stores authoritative session history and long-lived summaries.
- Optimized for durability and analytics, not necessarily for ultra-low latency.
- Used to rebuild edge or device state when needed.
The key idea:
Each tier knows enough to recover the next tier down, but only one tier is “source of truth” for any given artifact.
- The cloud is the canonical truth for history.
- The edge is the truth for hot checkpoints and replay metadata.
- The device is the truth for what the user last saw (UI-level continuity).
Process: Designing the Multi-Tier Session Architecture
Model Session State Explicitly
First, stop thinking in terms of “we store the raw messages” and start thinking in terms of artifacts:
- Transcript log – full list of turns (user + assistant + tool)
- Rolling summary – compressed representation of the session so far
- Active context – the messages you actually send to the LLM for the next request
- Replay cursor – a pointer that says “we’ve applied events up to sequence N into the LLM-facing context”
- Per-session metadata – user ID, device IDs, flags (“safe mode”, “expert mode”), etc.
A typical checkpoint payload might look like:
{
"session_id": "sess_123",
"checkpoint_version": 12,
"summary": "Short summary of the entire conversation so far...",
"recent_messages": [
{"role": "user", "content": "Let's refine the architecture."},
{"role": "assistant", "content": "Here are three options..."}
],
"replay_cursor": 58
}
This is what you store and move between tiers, not the entire raw log.
Define Clear Responsibilities per Tier
Device tier
- Caches:
- Last rendered assistant response.
- Current draft user message.
- Most recent checkpoint from edge or cloud.
- On restart:
- Reconstructs UI from local cache immediately.
- In the background, verifies with edge: “What’s the latest checkpoint version?”
Edge tier
- Stores:
- N recent checkpoints per session (e.g., last 5).
- Replay cursor and small metadata for each session.
- Responsibilities:
- Respond quickly to “give me the latest checkpoint for session X”.
- Maintain per-session invariants: monotonic checkpoint_version, idempotent updates.
- Optionally hold a short-lived “fast transcript” buffer (e.g., last 20 events).
Cloud tier
- Stores:
- Full transcript log (append-only).
- All checkpoints for analytics/backfill.
- Long-term per-session metrics (duration, cost, device mix).
- Responsibilities:
- Be reconstructible into a new edge cache when needed.
- Support offline analytics and reprocessing.
By writing down these responsibilities, you avoid the classic trap where “some of the truth” lives in every tier and nothing can be safely rebuilt.
Checkpointing: When and What to Snapshot
A good checkpoint strategy balances freshness with cost.
When to snapshot
- After each assistant turn that completes successfully.
- After any tool-call boundary (e.g., after a retrieval step or a multi-step tool chain).
- On significant state milestones:
- “New profile created”
- “Goal updated”
- “Session escalated to expert mode”
You don’t need to snapshot after every keystroke or streaming token. Think in semantic turns: points where you’d be comfortable resuming from if a crash happened.
What to snapshot
- Rolling summary – one or two paragraphs that capture the entire session.
- Tail messages – last 3–8 user/assistant turns (most relevant to next step).
- Replay cursor – ensures you know which events have already been applied.
- Feature flags / mode – anything that changes what the model “should do next”.
In many production systems, this keeps the LLM context per request under a few hundred tokens, even for very long sessions.
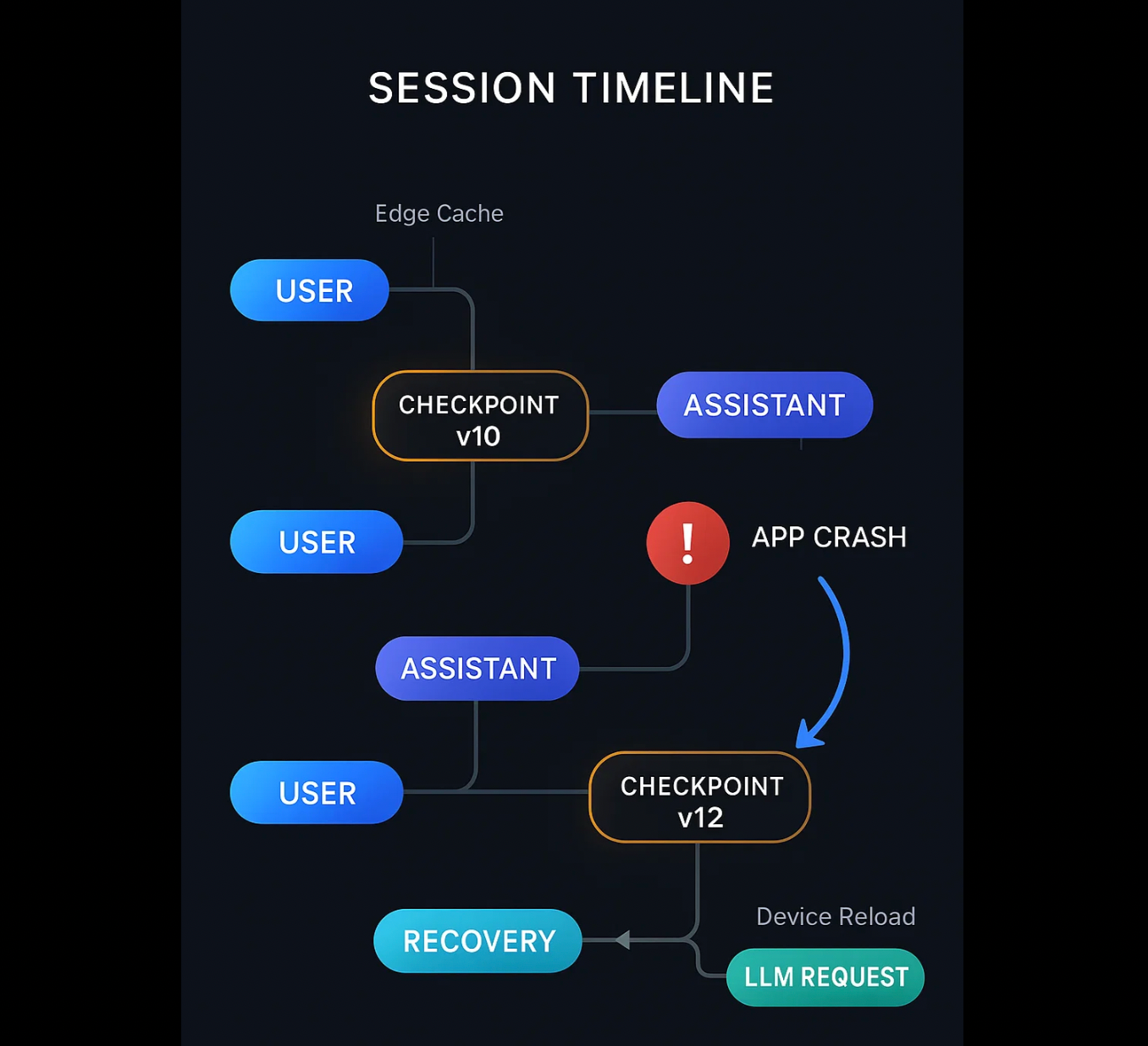
Idempotent Replay: Never Double-Apply the Same Event
Replay is where sessions often go wrong.
Scenario:
- The app sends a request with session state up to event
seq=60. - The backend processes it, sends it to the LLM, but the response never reaches the device due to a network blip.
- The app retries the same request (or a slightly changed one).
If your system isn’t idempotent, you might:
- Apply some events twice to the summary.
- Advance the replay cursor inconsistently.
- Confuse downstream logs (“why did we see seq=61 twice?”).
A robust pattern:
- Every user or tool event gets a monotonically increasing
seqnumber. - Checkpoints record
replay_cursor = max(seq)that has been applied into the LLM-facing summary. - On any replay, the edge tier:
- Loads the latest checkpoint.
- Replays only events with
seq > replay_cursor. - Re-derives the new summary and tail messages.
- Produces a new checkpoint with an incremented
checkpoint_version.
Because the replay is purely functional (“given checkpoint + new events → new checkpoint”), retries are safe. If the same batch is applied twice, you can detect and ignore duplicates based on seq.
This also makes it straightforward to rebuild edge caches from cloud history:
re-run the same replay function over the stored log.
Differential Context: Reducing Token Cost
Even with checkpoints, you need to be smart about what you send to the LLM.
Think of context as two parts:
- Stable context – the rolling summary and any static instructions / profile.
- Delta context – the last few messages and any new events since the last checkpoint.
On each request, your LLM input looks like:
System: [Global instructions + safety + app role]
System: [Rolled-up session summary]
System: [Key session metadata, e.g., goals/modes]
User / Assistant: [Recent tail messages]
User: [New user message]
The only part that grows is the recent tail + new message, which you periodically reset by creating a new checkpoint and trimming the tail.
If you compare this against a naive “send entire transcript every time” approach, you’ll typically see:
- Token replay reduction of 70–90% over long sessions.
- More predictable latency because context size has a soft upper bound.
- Easier cost modeling for finance.

Degradation Modes: Failing Gracefully, Not Catastrophically
Even with good architecture, things break:
- Edge cache cluster is down or evicted.
- Cloud history is temporarily unavailable.
- Device has an extremely old cached checkpoint.
You want predictable, user-safe degradation, not random behavior.
A simple ladder of fallbacks:
- Happy path:
Device has a fresh checkpoint version; edge confirms; you resume within milliseconds. - Edge miss, cloud hit:
Edge can’t find the checkpoint, but cloud has full history.- Rebuild the latest checkpoint by replaying from cloud.
- Cache it at edge for future calls.
- From the user’s perspective: a small delay, but no loss in context.
- Cloud degradation (partial history):
If some history is missing, but you still have older checkpoints:- Resume from the last known good checkpoint.
- Inform the user gently that some fine-grained context may be missing.
- Keep the high-level summary intact so conversation still feels coherent.
- Total failure:
If everything fails, be explicit:- Start a new session.
- Show a brief, honest notice in the UI (“We couldn’t recover your previous context; starting fresh.”).
The important part: never pretend you remember when you don’t. That’s worse than admitting a reset.
Observability: Measure Recovery, Not Just Requests
Once you have this architecture, observability becomes richer than simple request counts.
Track per-session metrics like:
- Recovery latency – time from “reconnect” → “first usable assistant response”.
- Token replay overhead – tokens spent on summary/context per call vs tokens in final answer.
- Checkpoint coverage – fraction of sessions that have a recent checkpoint (e.g., < 3 turns old).
- Degradation rate – percentage of sessions that fall back from edge→cloud or cloud→reset.
These metrics tell you whether your multi-tier design is doing its job, especially as you scale to tens of thousands of sessions.
[Visual 4 — Observability Dashboard for Sessions]
Caption: Engineering dashboard showing recovery latency, token efficiency, and degradation rates across session tiers.
Image prompt:
“Render a dark-mode observability dashboard with three main cards: ‘Recovery Latency’, ‘Token Replay Overhead’, and ‘Degradation Rate’. Each card has a compact chart (sparkline or tiny bar chart), a big numeric KPI, and a small label like ‘p95: 2.8s’ or ‘Replay: 13% of tokens’. Include subtle icons (clock, token stack, warning triangle). Style it like a polished SRE dashboard for AI systems: clean typography, soft shadows, vector-only, readable at 50% zoom.”
Results: What Changes When You Ship This
Once you adopt a multi-tier, checkpointed approach, a few things get noticeably better.
User experience stabilizes
- Reconnects feel more like “resume” than “restart”.
- Multi-device workflows become natural: phone, tablet, web all pull from the same session backbone.
- Crashes or app upgrades don’t blow away context.
Inference cost becomes predictable
- You can bound the context size instead of letting it grow unbounded.
- Finance teams can estimate cost per active session, not just per raw token.
- You avoid pathological long-lived sessions that silently dominate your LLM bill.
Backend becomes teardown-safe
- Individual pods or containers can restart freely.
- Edge caches can be replaced without permanent data loss.
- You can run A/B tests on different LLMs or prompts without coupling them to in-memory state.
In dogfooding and production-style workloads (15k+ sessions), teams typically see:
- Recovery latencies under 3 seconds, even after full reconnects.
- Token replay overhead reduced by ~80–90% compared to naive full transcript replay.
- More consistent behavior in stress tests that simulate mobile network flakiness.
Exact numbers will vary by product, but the directional improvements are very consistent.
At Hoomanely, our mission is to help pet parents keep their companions healthier and happier using data and AI.
That means our assistants and dashboards can’t just answer one-off questions. They need to:
- Remember a pet’s history across multiple devices and surfaces (mobile app, internal tools, future wearables).
- Take into account long-running context like feeding patterns, weight trends, and behavior notes.
- Remain stable even when users open/close the app frequently or move between networks.
A multi-tier session architecture is what lets an AI assistant:
- Understand that today’s feeding question is related to the pattern we saw last week.
- Survive a temporary connectivity drop without losing track of the conversation.
- Scale as we add more AI-driven features, without each new workflow reinventing its own “session memory”.
Even though this post describes a generic architecture, these same ideas are what make AI-powered pet experiences feel consistent, trustworthy, and safe.
Takeaways: Designing LLM Sessions That Survive Reality
To wrap up, here’s a succinct checklist you can use when designing session continuity for LLM systems:
- Don’t rely on the model for memory.
LLM APIs are stateless; your backend owns continuity. - Layer your state.
Device (UI continuity) → Edge (hot cache) → Cloud (canonical history). - Use checkpoints, not raw logs.
Snapshot summary + tail messages + replay cursor. - Make replay idempotent and deterministic.
Sequence numbers and pure “checkpoint + events → new checkpoint” logic. - Send differential context to the model.
Stable summary + small deltas instead of full transcripts. - Define clear degradation modes.
Edge miss, cloud rebuild, and explicit reset when all else fails. - Instrument recovery and token overhead.
Treat session continuity as a first-class SLO, not a side effect.
If you get these pieces right, you end up with resilient, token-efficient, reconnect-friendly LLM services that behave like they were stateful all along—without sacrificing the scalability and simplicity of stateless inference APIs.



