Choosing the Right Model Architecture for Production

Introduction
Choosing the right language model architecture for production is one of the most underrated engineering decisions teams make. Behind every AI feature - from a chatbot response to a search ranking - sits a strategic decision: Should we use an encoder-only model? A decoder-only model? Or a full encoder–decoder stack?
At Hoomanely, our systems power a multimodal pet-care platform where efficiency, latency, and precision directly affect product experience. For example, our EverWiz AI assistant runs on a decoder‑only model with a retrieval‑augmented pipeline, while our internal data analysis uses a BERT‑style encoder-only model for fast question classification. Two very different tasks, two very different architectures - chosen intentionally.
This post breaks down when each model type is the right tool, their strengths, common production use cases, and how teams like ours map tasks to architectures.
1. The Three Major Architecture Families
Encoder‑Only Models
Examples: BERT, RoBERTa, DistilBERT, MPNet
Best for: Classification, clustering, embeddings, search, tagging, semantic similarity.
Encoder‑only models are built to understand text deeply, not generate it. They excel at creating compact, high-quality representations of input text - making them ideal for downstream analytical or classification pipelines.
We use an encoder-only model to classify internal questions in our analytics systems. When users ask thousands of pet-care questions, we need fast categorization into topics like health, nutrition, behavior, etc. An encoder-only model gives us high accuracy with extremely low latency.
Decoder‑Only Models
Examples: GPT-family, LLaMA-family, Mistral, Gemini‑Flash-like architectures
Best for: Chatbots, assistants, long-form generation, reasoning, RAG.
Decoder‑only models generate text token-by-token, making them ideal for conversational AI and creative tasks. Their architecture naturally fits large-context reasoning and RAG workflows.
Our EverWiz assistant - the conversational AI answering pet‑parents - uses a decoder-only model combined with retrieval augmentation. The model reasons over context, blends retrieved knowledge, and produces helpful, consistent answers.
Encoder–Decoder Models
Examples: T5, FLAN‑T5, BART, mT5
Best for: Translation, summarization, structured generation, sequence transformation.
These models "encode" the input into a latent representation and then "decode" it into another sequence. They shine when the task requires transforming one type of text into another - compressing, rewriting, translating, or normalizing.
2. How These Architectures Actually Work
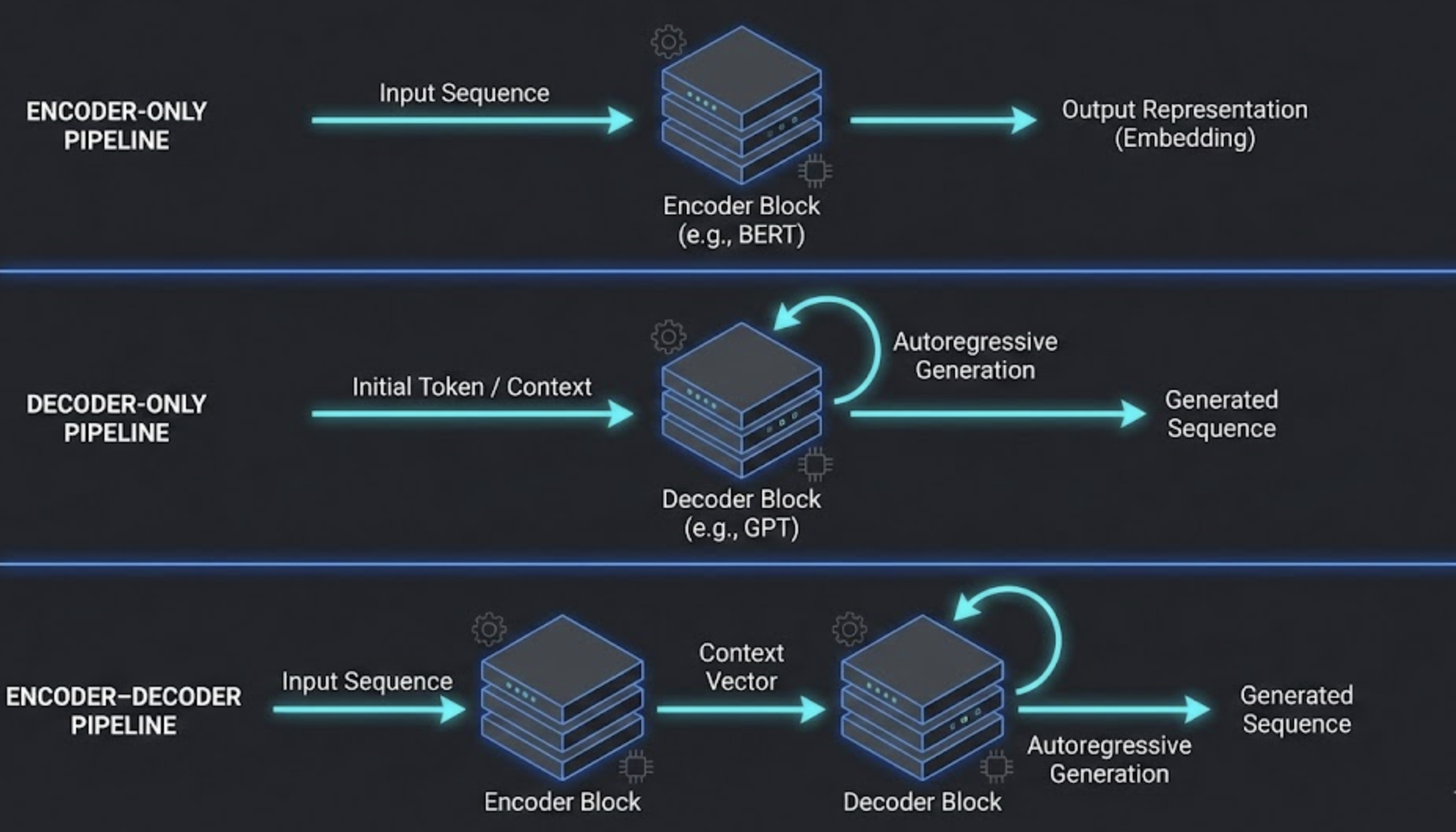
Understanding the architectural differences helps reveal why models behave the way they do.
Encoder‑Only
- Bidirectional attention (reads both left and right context)
- Learns contextual embeddings
- Cannot generate free text
Decoder‑Only
- Autoregressive (predicts next token)
- Excellent for creative or conversational tasks
- Can handle long contexts
Encoder–Decoder
- Encoder compresses meaning
- Decoder expands it in desired format
- Best for structured transformation
3. When to Use Which: A Practical Decision Framework
Encoder‑Only → When You Need Understanding
Use where text needs to be interpreted, classified, ranked, or embedded.
Applications:
- Search ranking
- Semantic similarity
- Intent detection
- Named entity recognition
- Topic classification
Production Benefits:
- Smaller models
- Lower latency
- Easy to fine-tune
- Cost-efficient at scale
Decoder‑Only → When You Need Generation or Reasoning
Use where the system must produce text or reason step-by-step.
Applications:
- Chat interfaces
- Email or content generation
- Code assistants
- Agents + tool use
- RAG systems
Production Benefits:
- Great long-context reasoning
- Smooth conversational behavior
- Easy to plug into RAG workflows
Encoder–Decoder → When You Need Transformation
Use when inputs must be converted into a structured or improved output.
Applications:
- Summaries
- Translations
- Grammar correction
- Style transfer
Production Benefits:
- Strong precision for transformation tasks
- Often more stable than decoder-only for structured output
4. A Simple Rule of Thumb
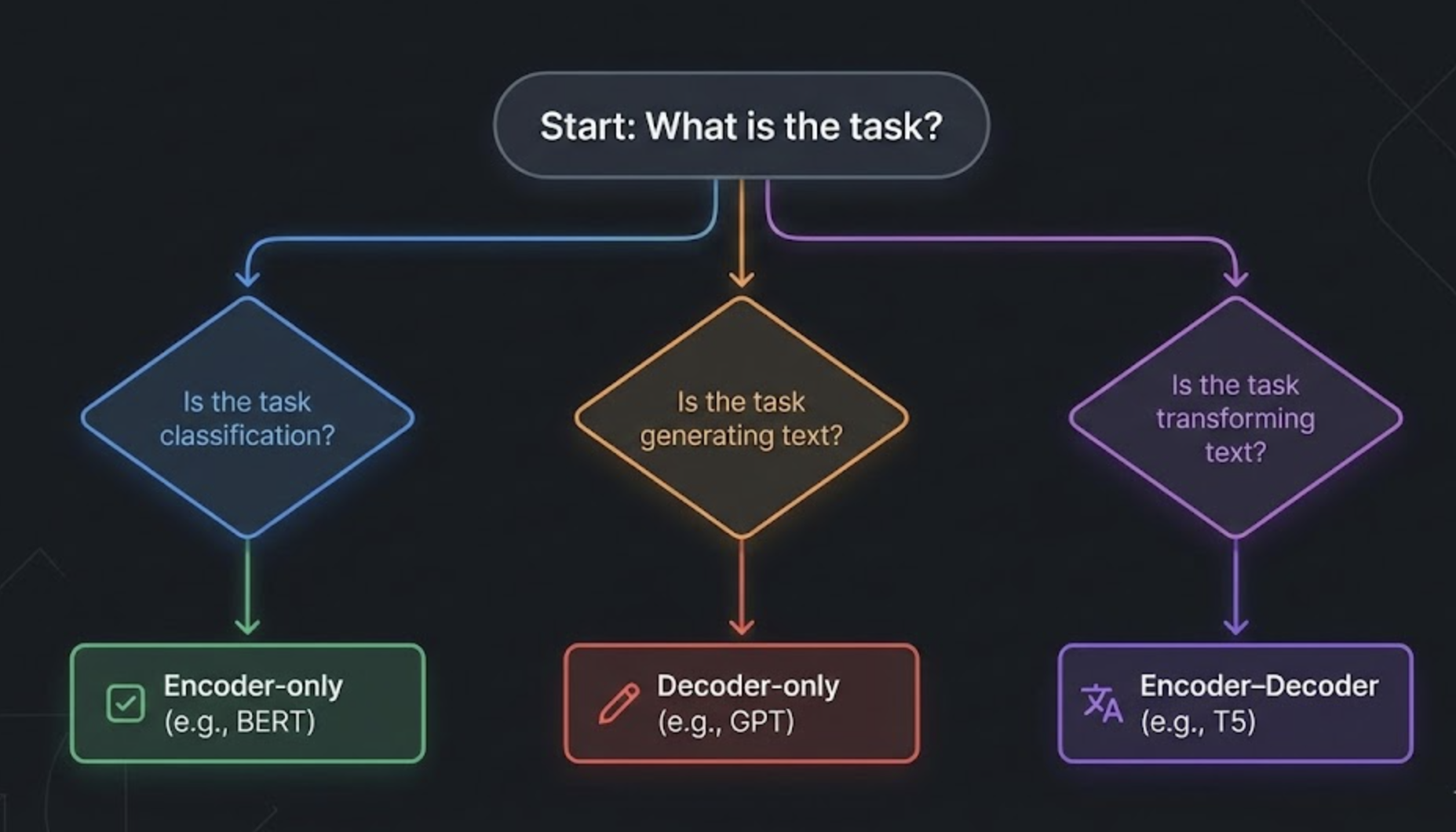
Here’s the quick map you can use:
| Task Type | Best Architecture |
|---|---|
| Classification | Encoder-only |
| Embeddings / Search | Encoder-only |
| Chat / Long-form answers | Decoder-only |
| Reasoning + RAG | Decoder-only |
| Translation | Encoder–decoder |
| Summarization | Encoder–decoder |
| Data transformation | Encoder–decoder |
5. How We Use This Framework at Hoomanely
1. Internal Data Analysis → Encoder‑Only
We use a BERT‑style encoder for classifying user questions into intent categories.
Why?
- Need fast inference
- Highly structured tasks
- Zero need for generation
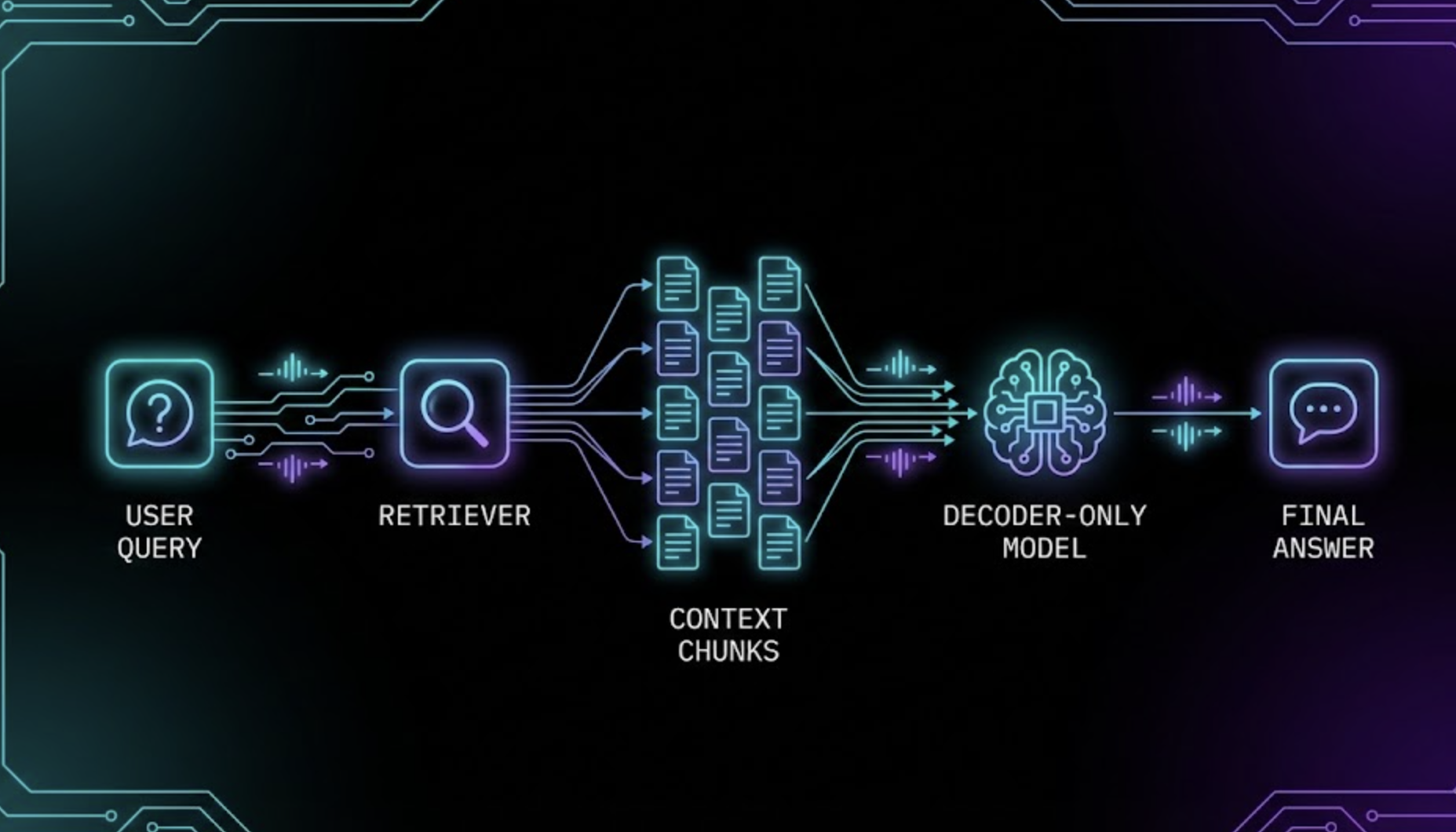
2. EverWiz Pet Assistant → Decoder‑Only
Our assistant relies on a decoder-only model paired with RAG.
Why?
- Needs long-context reasoning
- Must answer conversationally
- Must integrate retrieved knowledge
This combination lets the assistant:
- Read the user query
- Retrieve relevant pet-care knowledge
- Generate reliable advice
6. Cost, Latency & Scaling Considerations
Encoder‑Only
- Fast & light
- Scales cheaply across many requests
Decoder‑Only
- Heavier inference
- Requires batching or model distillation for scale
Encoder–Decoder
- Middle ground
- Great accuracy, moderate cost
If you’re deploying on edge devices, or need millions of queries per day, encoder‑only is usually the most cost‑effective. For conversational products, decoder‑only is the industry standard despite higher compute needs.
7. Takeaways
Choosing a model type is half architecture, half product strategy.
Encoder‑only → understanding
Decoder‑only → reasoning + generation
Encoder–decoder → transformation
Use this framework to build the right stack for your use case. At Hoomanely, this mapping keeps our products both efficient and user‑friendly - from EverWiz’s conversational intelligence to our internal analytics automation.



