Circular Buffer Wrap-Around: Elegant Mathematical Mastery

When data flows faster than it can be processed, efficient buffering becomes the backbone of responsive embedded systems. At the heart of high-performance IoT devices lies an elegant mathematical concept that transforms linear memory into infinite storage: the circular buffer wrap-around technique.
The Mathematical Foundation of Endless Data
In embedded systems handling continuous data streams—from thermal sensors capturing temperature grids to high-speed camera interfaces processing frame buffers—the challenge isn't just storing data efficiently, but managing memory boundaries with mathematical precision. The modulo operation (index + 1) % MAX_SIZE appears deceptively simple, yet it powers some of the most sophisticated data management systems in modern embedded applications.
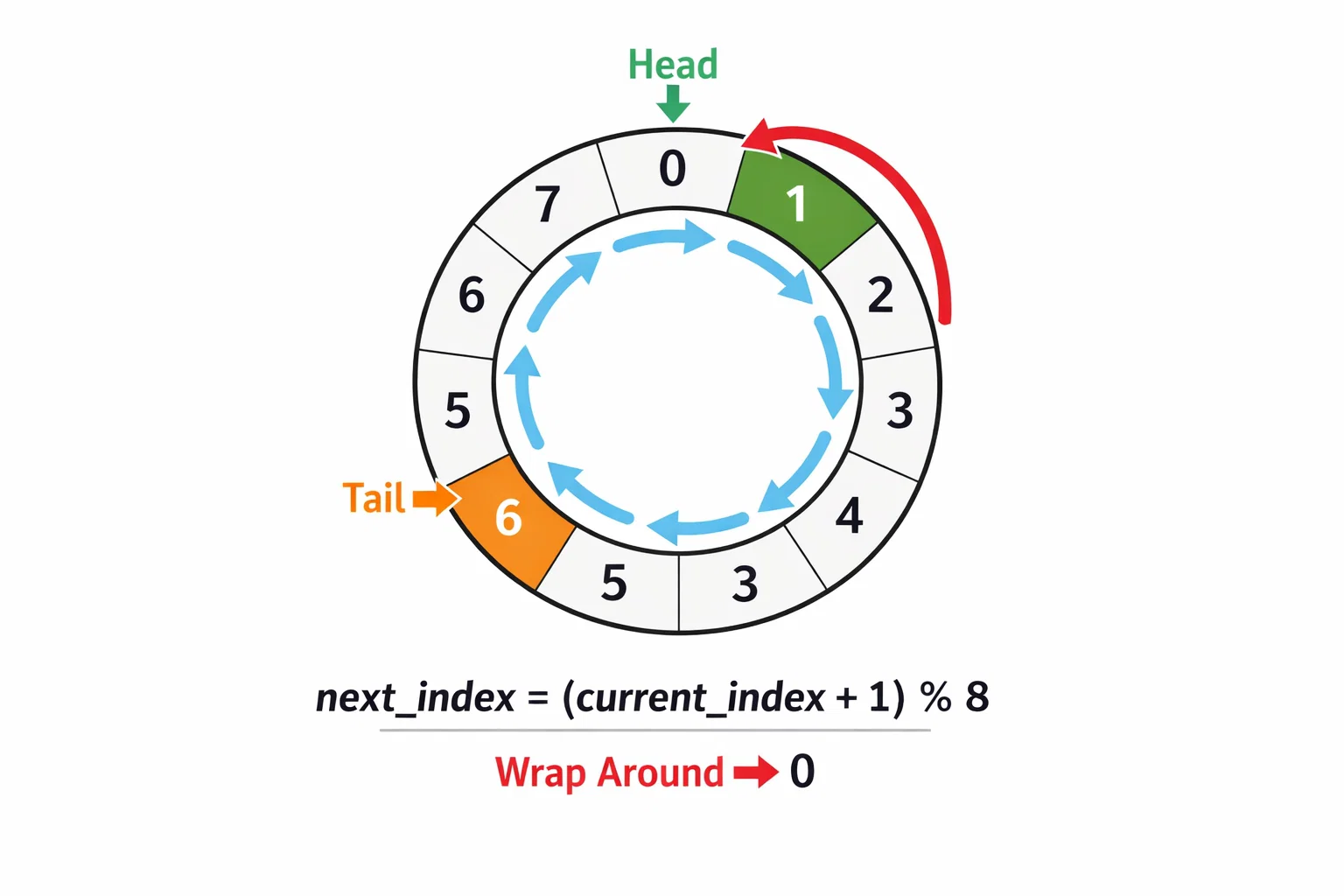
Real-World Implementation: Storage Management Excellence
Modern embedded systems demonstrate circular buffer mastery through multi-layered implementations. Consider a thermal imaging system that must continuously capture, store, and transmit temperature data without losing critical information. The storage manager implements circular buffering at the entry level:
// Elegant index management with mathematical precision
if (storage_mgr.circular_buffer_active) {
allocated_entry_index = storage_mgr.next_entry_index;
storage_mgr.next_entry_index =
(storage_mgr.next_entry_index + 1) % MAX_TABLE_ENTRIES;
}
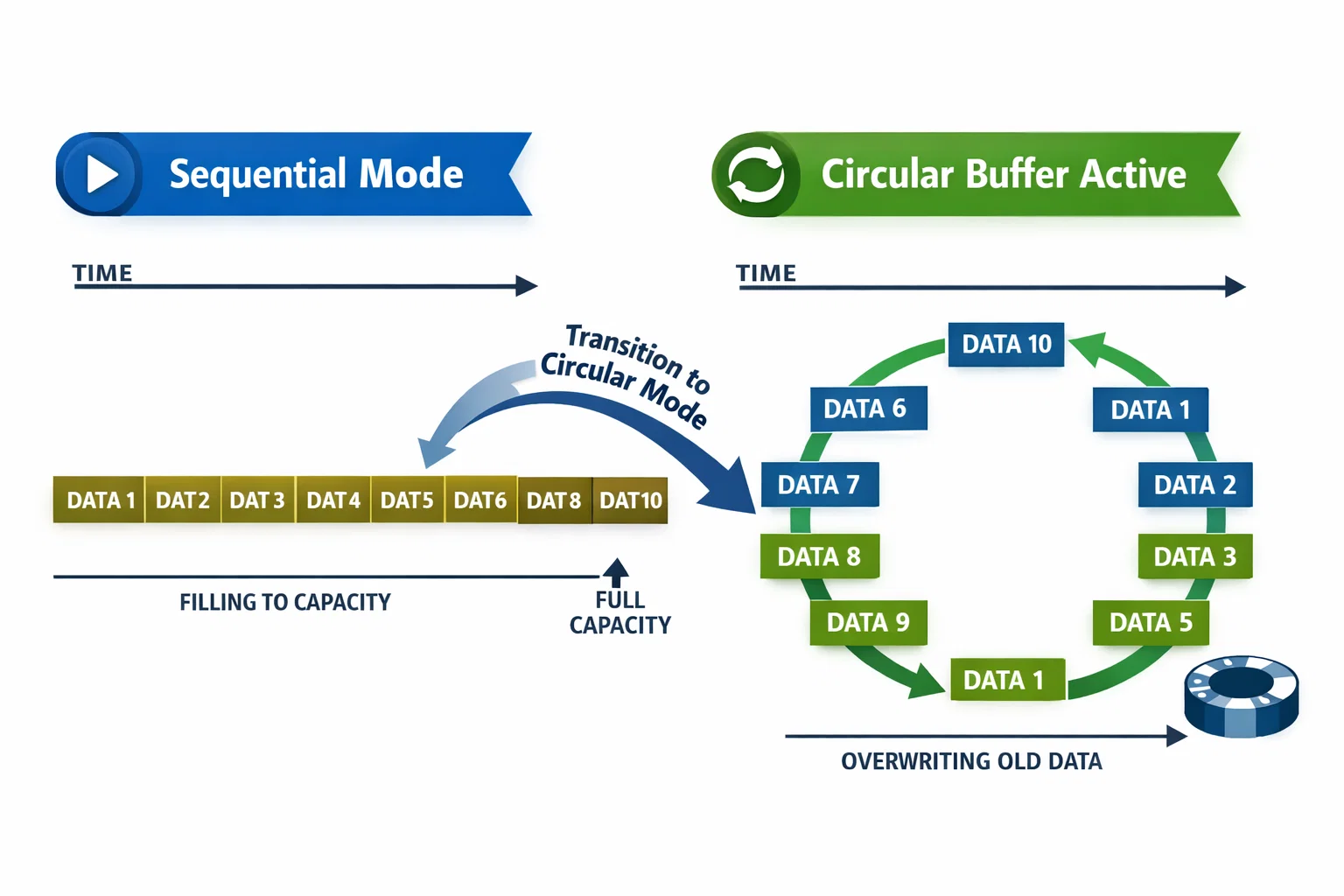
This implementation showcases the mathematical beauty where 5,000 table entries become an infinite stream through modulo arithmetic. When the buffer reaches entry 4,999, the next write operation wraps seamlessly to entry 0, creating continuous operation without memory reallocation or data copying.
The system automatically transitions from sequential mode to circular mode when storage capacity is reached, demonstrating adaptive buffer management that maintains data integrity while maximizing memory utilization.
Hardware-Level Circular Mastery: DMA Optimization
Beyond software-level buffering, modern microcontroller architectures implement circular buffering at the hardware level through sophisticated DMA (Direct Memory Access) systems. High-performance camera interfaces utilize linked-list DMA with circular configuration:
// Hardware circular buffer configuration
handle_GPDMA1_Channel7.InitLinkedList.LinkedListMode = DMA_LINKEDLIST_CIRCULAR;
HAL_DMAEx_List_SetCircularModeConfig(&DCMI_Queue, &DCMI_Node1);
This hardware-accelerated approach eliminates CPU intervention during buffer wrap-around, achieving zero-latency transitions between buffer boundaries. The DMA controller automatically handles pointer wrap-around using dedicated hardware circuits optimized for continuous data capture from high-speed peripherals.
The dual-buffer architecture creates a ping-pong mechanism where one buffer fills while the other processes, with circular linking ensuring seamless transitions. This implementation delivers deterministic performance critical for real-time imaging applications where frame drops are unacceptable.
Mathematical Optimization: Bit Manipulation Excellence
Advanced implementations leverage mathematical properties beyond simple modulo operations. Power-of-two buffer sizes enable bit manipulation optimizations that replace expensive division operations with lightning-fast bitwise AND operations:
// Mathematical optimization: buffer_size = 2^n allows bit masking
#define BUFFER_SIZE_MASK (BUFFER_SIZE - 1)
next_index = (current_index + 1) & BUFFER_SIZE_MASK;
This technique transforms computational overhead from O(log n) division to O(1) bitwise operations, crucial for embedded systems operating under strict timing constraints.
Multi-Dimensional Circular Buffering
Complex embedded systems often require multi-dimensional circular buffering where multiple data streams utilize independent circular indices. Thermal sensor arrays demonstrate this sophistication through chunk-based packet management:
// Multi-stream circular buffer management
static uint32_t packet_bitmap[3] = {0, 0, 0}; // Per-chunk tracking
static bool chunk_complete[3] = {false, false, false};
Each chunk maintains independent circular state while contributing to a larger data reconstruction process. This approach enables fault-tolerant data assembly where packet loss or reordering doesn't compromise system integrity.
The bitmap approach provides elegant duplicate detection—essential when dealing with unreliable communication channels where the same packet might arrive multiple times. Mathematical set theory concepts translate directly into bitwise operations for efficient packet tracking.
Memory Efficiency Through Mathematical Precision
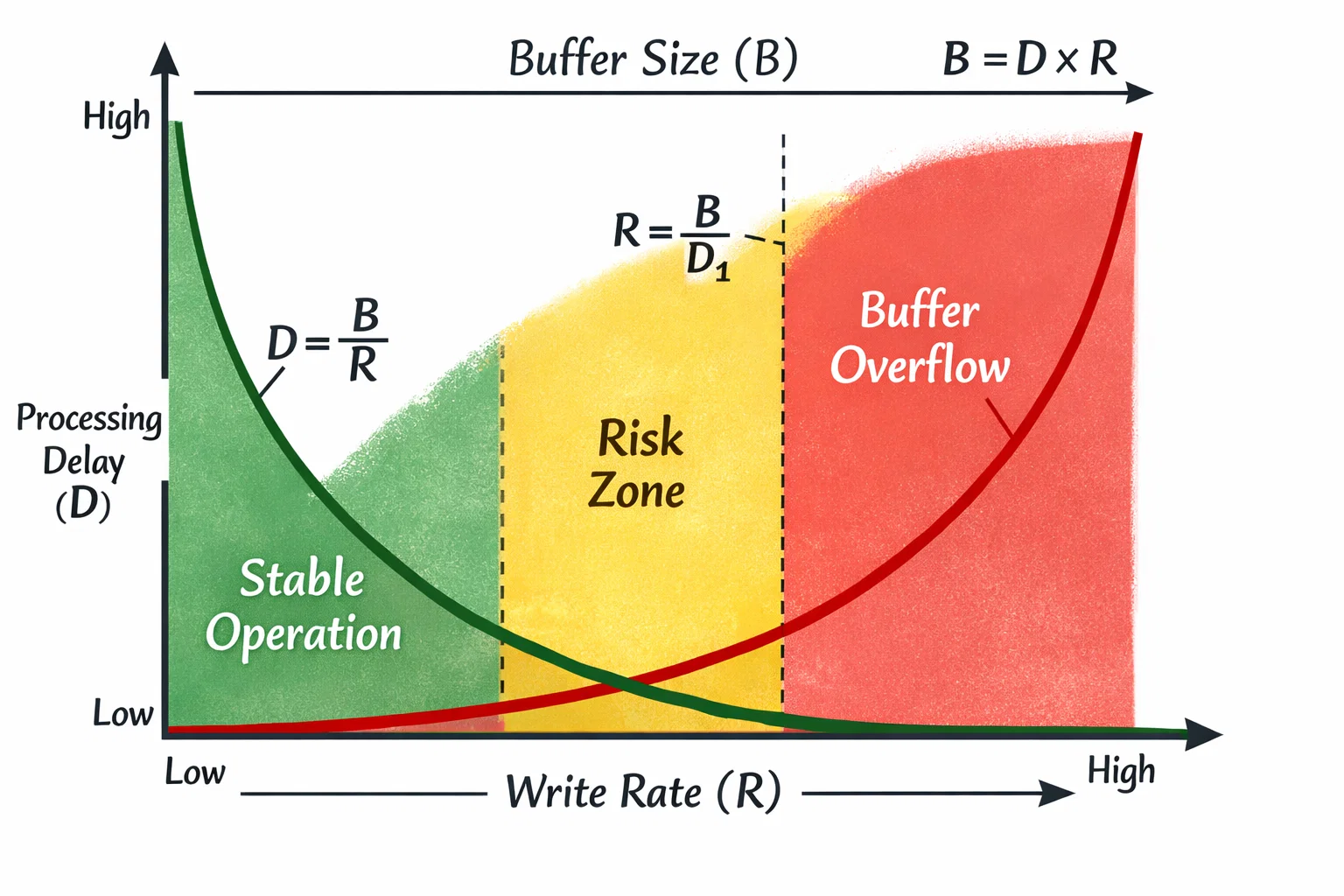
Circular buffers maximize memory utilization through precise mathematical relationships between buffer size, write speed, and read speed. The key insight: buffer size must exceed the maximum difference between write and read positions during peak load conditions.
For continuous data streams, the optimal buffer size follows the relationship:Buffer_Size ≥ (Write_Rate × Max_Processing_Delay) + Safety_Margin
This mathematical foundation ensures system stability while minimizing memory footprint—crucial for resource-constrained embedded environments where every byte matters.
Elegant Error Recovery and Boundary Conditions
Professional circular buffer implementations handle edge cases with mathematical rigor. Boundary condition management ensures system robustness:
- Overflow Protection: Mathematical validation prevents index corruption
- Underflow Handling: Empty buffer detection using pointer relationships
- State Consistency: Atomic operations ensure thread-safe index updates
The most elegant implementations use mathematical invariants to verify system correctness. For instance, maintaining the relationship (write_index - read_index) % buffer_size always represents valid data count, providing constant-time validation of buffer state.
Performance Impact: Mathematical Excellence in Action
Real-world performance data reveals the mathematical optimization impact:
- Zero-copy Operations: Circular buffers eliminate data movement overhead
- Constant-time Complexity: O(1) operations regardless of buffer size
- Memory Efficiency: 100% buffer utilization without fragmentation
- Deterministic Performance: Predictable timing critical for real-time systems
These characteristics make circular buffers essential for high-performance embedded applications where mathematical precision translates directly to system responsiveness.
Key Takeaways
Circular buffer wrap-around techniques represent mathematical elegance applied to embedded system constraints. The modulo operation's simplicity masks sophisticated optimizations that enable continuous data processing in resource-limited environments.
Modern embedded systems showcase circular buffer mastery across multiple layers—from hardware DMA controllers executing wrap-around in silicon, to software algorithms managing complex multi-stream data reconstruction. Each implementation demonstrates how mathematical precision transforms computational challenges into elegant solutions.
The next time you interact with a responsive IoT device processing continuous sensor data, remember the mathematical foundation enabling that seamless operation: elegant circular buffer wrap-around techniques working silently behind the scenes.
At Hoomanely, we specialize in developing sophisticated embedded systems that harness mathematical precision for optimal performance. Our thermal imaging and IoT solutions demonstrate these circular buffer techniques in production environments, where elegant algorithms meet real-world reliability requirements. This deep understanding of mathematical optimization allows us to create embedded systems that excel under challenging operational conditions while maintaining the efficiency and responsiveness our clients demand.



