Crash-Safe Flash Buffers: Surviving a Dying Battery

A collar-worn pet tracker lives in about the most hostile environment a storage engineer could design on purpose. The battery is tiny, the dog is unpredictable, and the wireless link to the hub drops every time the dog wanders behind the couch. Now picture the worst possible moment: the battery dies in the exact millisecond the firmware is writing a sensor frame to flash. Do we lose the whole file? Panic on the next boot? Silently replay garbage into the pet's health timeline? At Hoomanely, none of those are acceptable answers. This post is about the durability layer beneath our sensor queue, the part that decides what survives an outage, what survives a torn write, and, just as importantly, what we deliberately throw away.
The problem: two different ways to lose data
A continuous health monitor has to defend against two failure modes that look similar but are not.
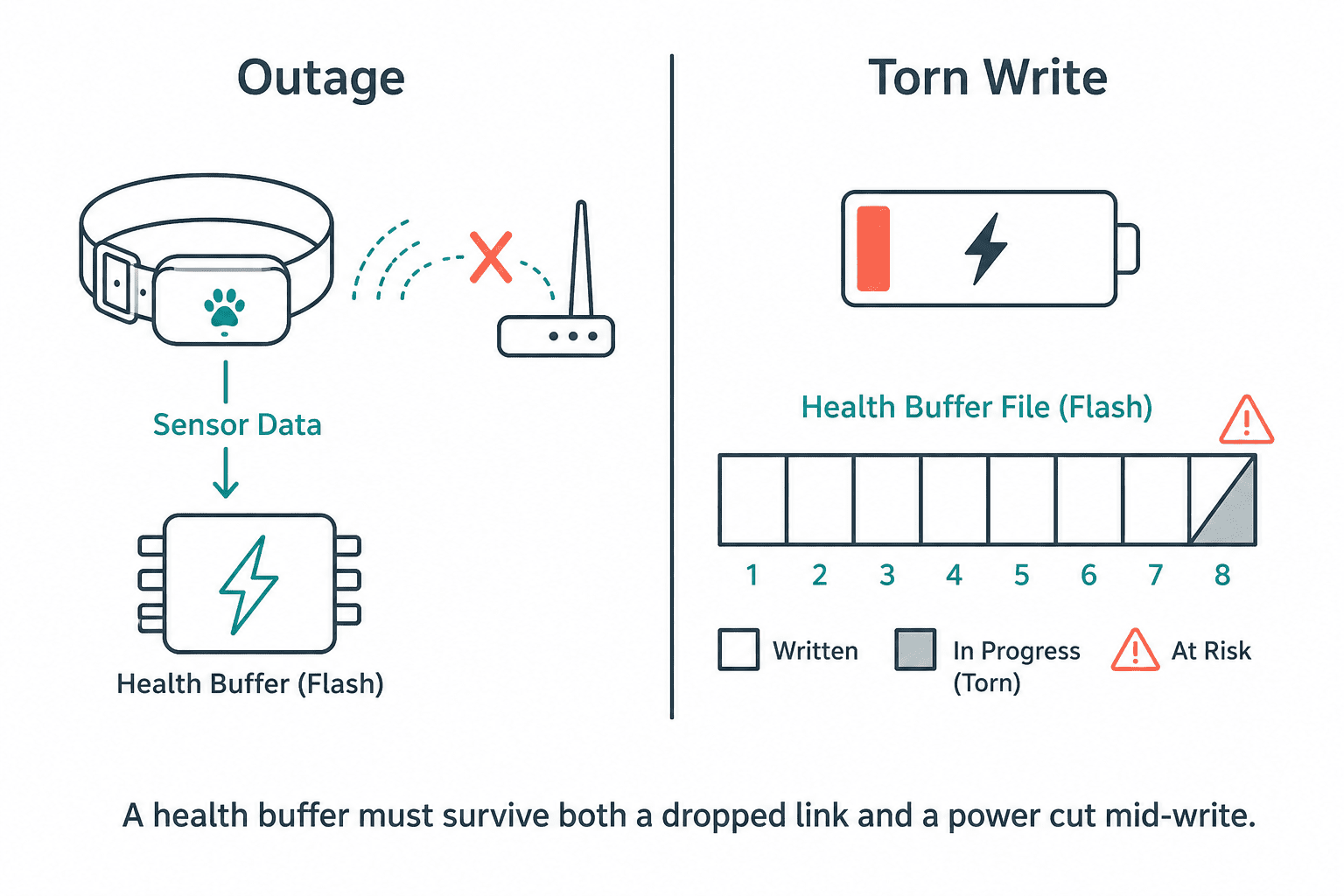
The first is an outage. The wireless link to the hub goes down, but the inertial sensor keeps producing motion data at a steady rate. That data has nowhere to go in real time, so it has to land somewhere persistent until the link returns, otherwise every walk behind the couch becomes a hole in the activity record.
The second is a torn write. Flash sits behind a FAT filesystem, and FAT was never designed for a power supply that can vanish mid-operation. If the battery dies halfway through appending a frame, the file can end with a half-written record, a length field with no payload, or a payload that runs off the end of the file. Read that back naively and you either crash or, worse, feed corrupted samples into the pet's timeline.
Two more constraints make it harder. Flash capacity is small and shared with other data, so the buffer cannot grow without bound. And the persistence path must never block the real-time capture loop, a sensor that stalls waiting on a slow flash write is a sensor that drops samples.
The approach: a self-describing spill file
Our tracker uses a two-tier queue: a small in-RAM ring for low-latency staging, and a flash spill file that is the real persistence layer. Here the focus is the flash file and why it's built to be corrupt-tolerant by design.
The core idea is that the spill file must be self-describing. We refuse to keep a separate index or offset table, because that index becomes a second thing that can get out of sync with the data after a crash. Instead, every frame is wrapped with its length recorded both before and after the payload, so a reader can walk the file forward or backward without any external bookkeeping.
The file is append-only, capacity-bounded, and validated on read. Those three properties, append-only writes, a hard byte cap, and defensive parsing, are what turn "flash plus FAT" into something a battery-powered medical-adjacent device can actually trust.
Four decisions that make it safe
1. One write per frame, and count only what fully landed. Each frame is assembled in a single contiguous buffer, leading length tag, payload, trailing length tag, and pushed to flash in exactly one write() syscall. We advance our running byte counter only if the full frame was written.
framed[0] = (uint8_t)(got & 0xFF);
framed[1] = (uint8_t)((got >> 8) & 0xFF);
memcpy(&framed[2], buf, got);
framed[2 + got] = (uint8_t)(got & 0xFF);
framed[2 + got + 1] = (uint8_t)((got >> 8) & 0xFF);
if (write(s_spill_fd, framed, got + 4) == (ssize_t)(got + 4)) {
s_spill_bytes += (long)(got + 4);
}The single-syscall write matters for more than speed. Three separate writes give a power cut three windows to tear a frame instead of one, and each FAT write grabs an internal lock, three per frame turned the spill task into the bottleneck under load. One write keeps the operation as close to atomic as the filesystem allows, and the dual tags let the reader later prove a frame is intact.
2. Flush before letting go. When the link comes back and the file changes hands from writer to reader, we don't just close the descriptor and hope the data reached the medium, we force it:
static void close_spill_fd(void)
{
if (s_spill_fd >= 0) {
fsync(s_spill_fd);
close(s_spill_fd);
s_spill_fd = -1;
}
}fsync() pushes any buffered data through to flash before the reader opens its own handle. Without it, the most recent frames could live only in a cache that a power cut would erase.
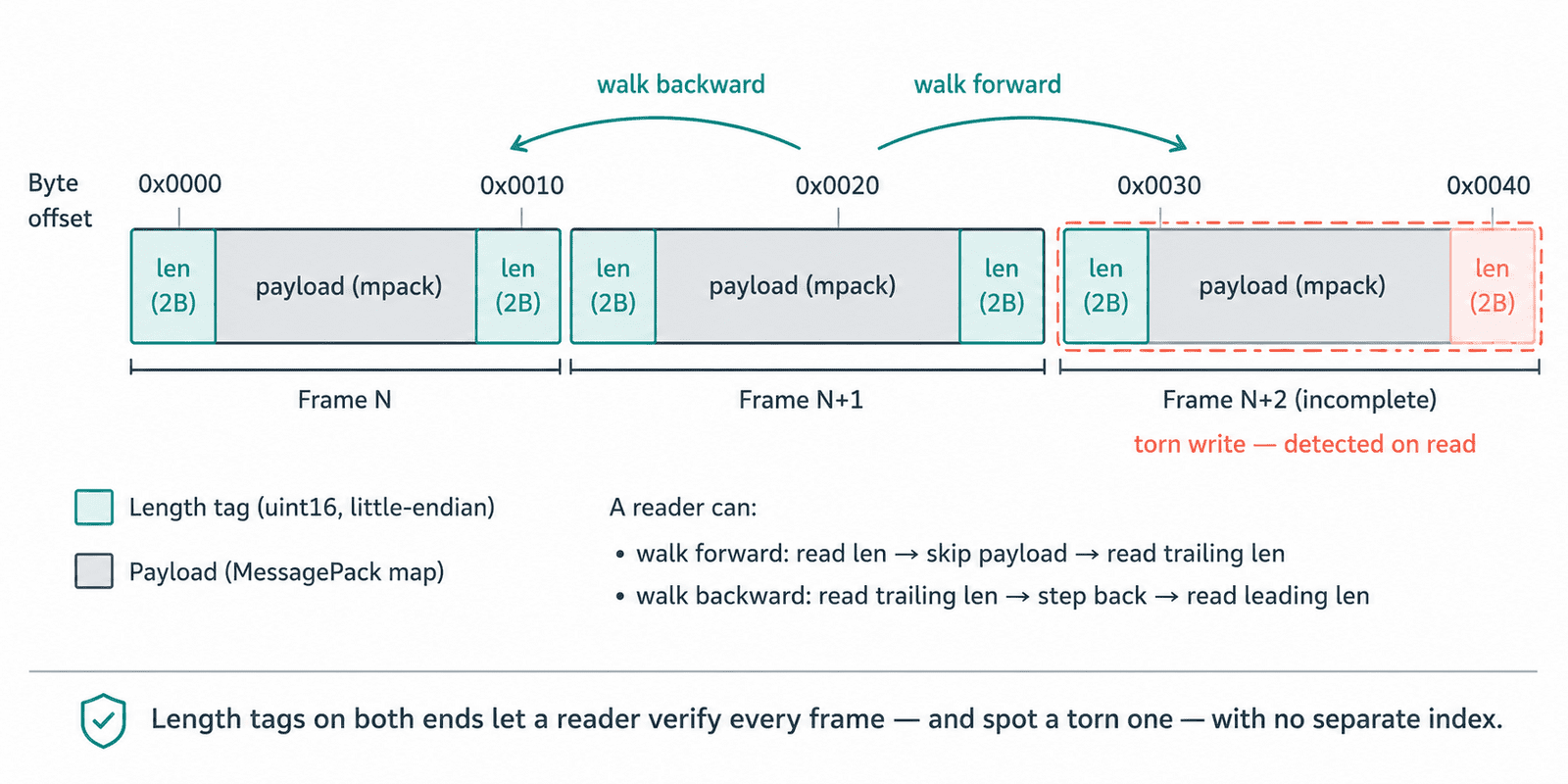
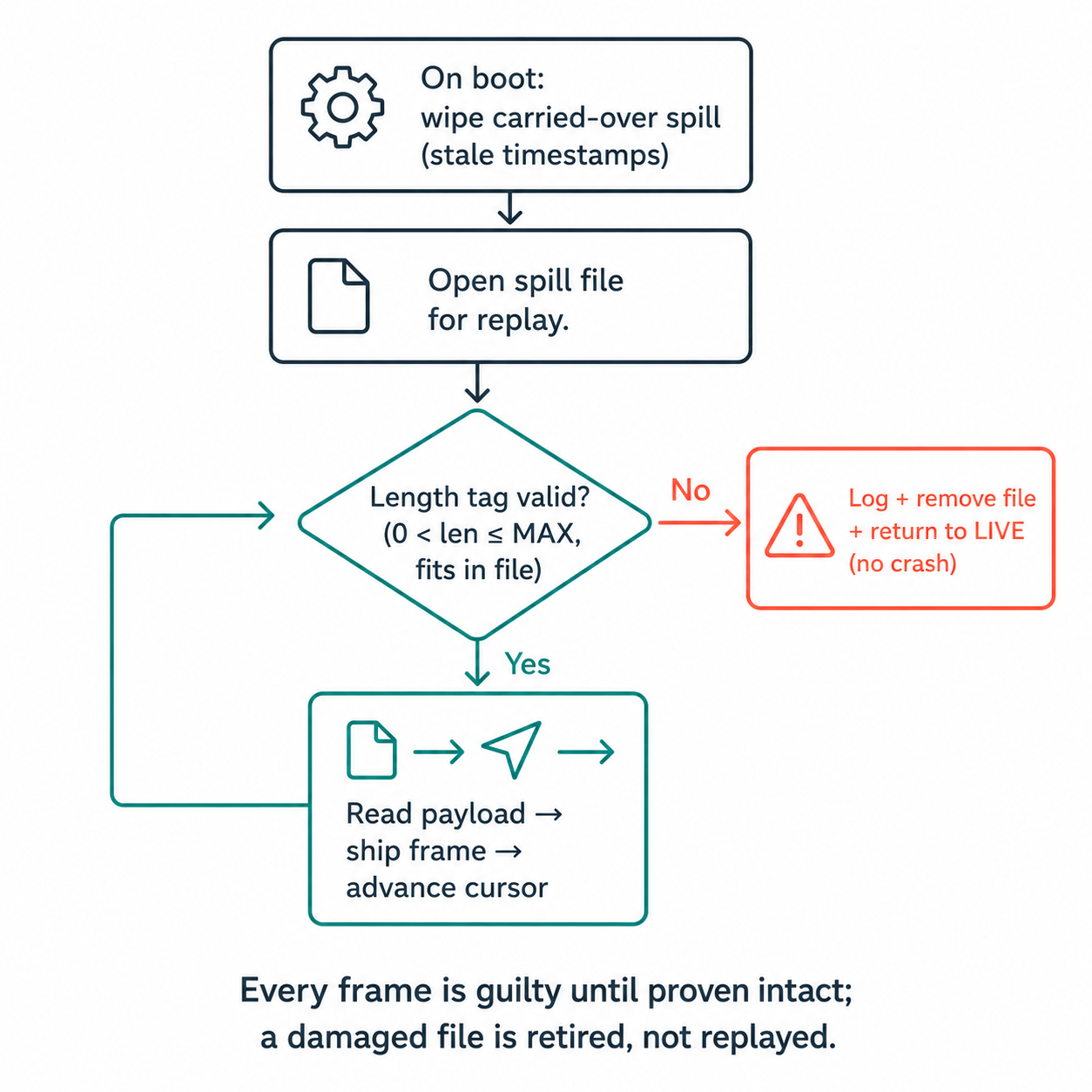
3. Assume the file is already damaged. The reader never trusts the bytes on disk. Before each frame it reads the leading length tag and sanity-checks it. A zero length, an impossibly large length, or a frame that would run past the file's captured end means the file is corrupt, almost always a torn final write from a power loss, so we abandon it cleanly instead of crashing:
uint16_t flen = (uint16_t)tag[0] | ((uint16_t)tag[1] << 8);
if (flen == 0 || flen > MAX_FRAME_BYTES) {
ESP_LOGE(TAG, "replay: bogus tag %u at pos %lld; abandoning file",
flen, (long long)s_replay_pos);
close_replay_fd();
remove(SPILL_PATH);
apply_mode(compute_mode());
goto out;
}We also capture the file's size once when we open it for reading, and treat any frame that claims to extend beyond that boundary as corrupt. The result: a torn frame is a logged, recoverable event, never a boot loop, never a panic, never a stream of garbage masquerading as the dog's movement.
4. Decide what is not worth keeping. This is the design decision I'm proudest of, because it's the one most teams get wrong by reflex. It's tempting to make the spill file durable across reboots, but the frames in it carry timestamps from a previous power session. Replaying day-old motion as if it were live would silently poison the health timeline. So on boot, we wipe it:
/* Wipe any spill carried over from a prior boot. Frames in there
* carry stale event_ts values from the previous session; replaying
* them on next BLE connect would inject obsolete samples into the
* timeline. The two-tier queue's job is real-time outage resilience,
* not cross-reboot durability. */
if (remove(SPILL_PATH) == 0) {
ESP_LOGI(TAG, "wiped stale spill from prior boot");
}Crash-safety is not "never lose a byte." It's "never let a surviving byte lie." A buffer that resurrects stale data after a reset is more dangerous than one that admits the gap.
The results
In practice this layer does three things reliably. It absorbs link outages up to a hard flash budget, so a dog out of range still has its activity recorded and re-delivered when the hub reconnects. It tolerates power loss at any instant: the worst a dying battery can do is leave one half-written frame, which the reader detects and discards on the next session. And it never stalls the sensors, because the durable write path runs on its own task and the producer never blocks on flash.
Equally important is what it refuses to do. It will not grow unbounded and starve other data. It will not crash on a corrupt file. And it will not replay yesterday's motion into today's record.
Why it matters at Hoomanely
That promise rests on a quiet assumption, that the data reaching the AI engine is complete and honest. A daily activity trend is only meaningful if a dropped wireless link didn't quietly erase an afternoon, and only trustworthy if a battery swap didn't replay stale steps into a fresh day. The crash-safe spill buffer is where that integrity is enforced, frame by frame, before any model ever sees the data.
Key takeaways
Distinguish an outage from a torn write, they're both data-loss risks but need different defenses. Make the file self-describing with dual length tags rather than a separate index that can drift out of sync. One write per frame keeps the operation close to atomic. Flush explicitly before handing a file off between writer and reader. Never trust bytes on disk, validate every frame on read and abandon corrupt files cleanly. And decide deliberately what should not survive a reboot, since stale data replayed as fresh is worse than a gap.