Designing a Rule-Based Decision System for Pet Health Alerts


Introduction
At Hoomanely, our mission is simple: give pet parents superpowers. From monitoring drinking patterns to spotting early temperature anomalies, our systems turn raw sensor data into clear, actionable health insights. But behind every insight is a critical intelligence layer - our rule‑based decision system. It bridges the gap between raw telemetry and medically meaningful alerts.
Instead of relying solely on ML for every micro‑decision (and risking opacity), we built a deterministic engine that encodes veterinary knowledge, environmental context, and dog‑specific traits. In this post, we break down how our bitmask‑powered rule engine works, why it’s fast and scalable, and how storing raw categorical fields + adding partial‑match indexing is part of the actual pipeline powering Hoomanely today.
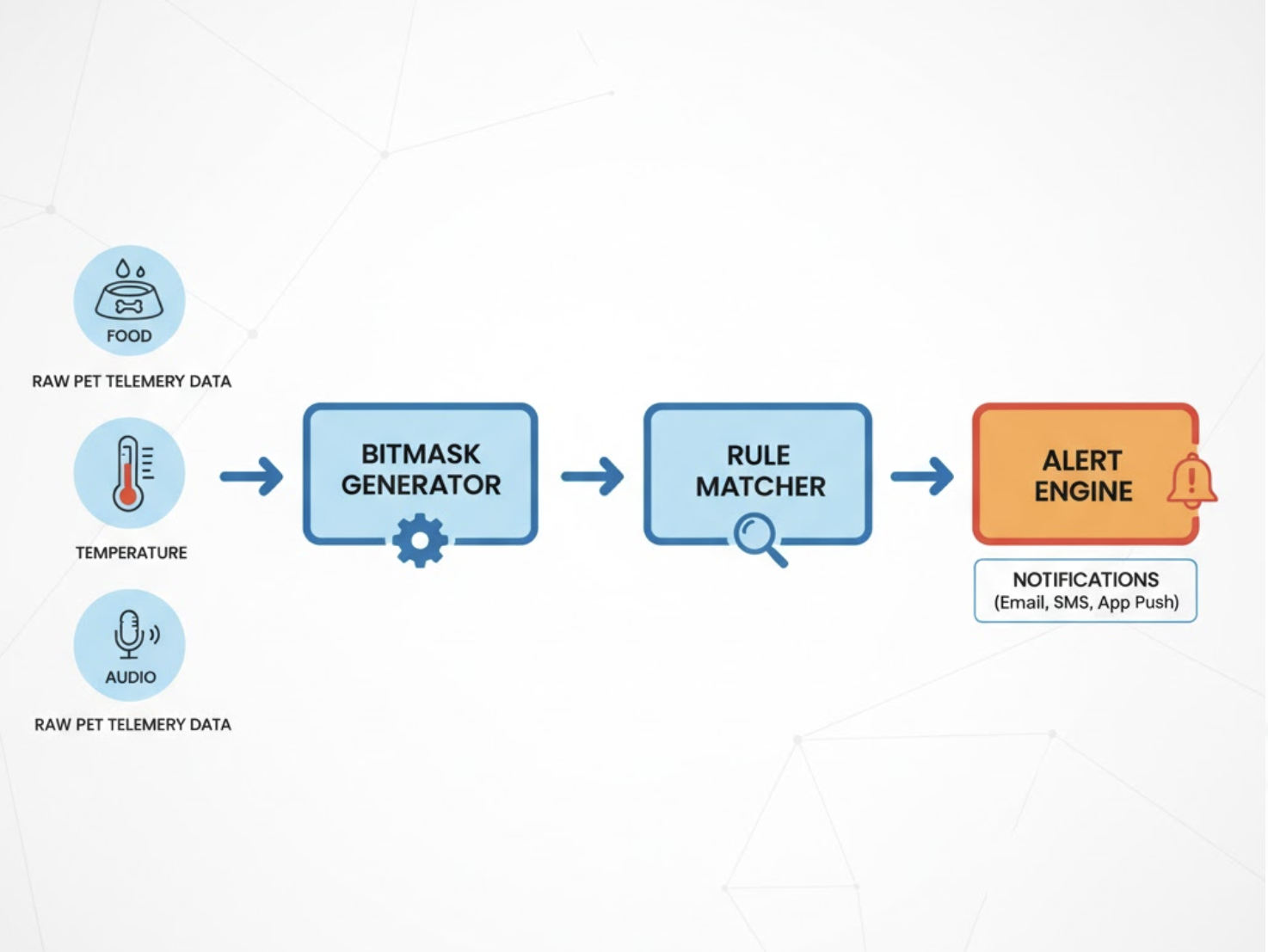
Problem: Turning Multidimensional Pet Data Into Real-Time, Reliable Alerts
Dogs generate dozens of signals every single day:
- Drinking and eating sessions
- Hourly and daily consumptions
- Eye temperature readings
- Audio cues (gulp, bark, cough)
- Season, weather, humidity
- Breed‑specific and age‑specific risks
A real system must answer:
"If a senior French Bulldog drinks less on a humid night, should we warn the parent?"
To do this safely and at scale, we need:
- Fast lookups (<10 ms)
- Support for hundreds of rules
- Deterministic outputs
- Easy extensibility when vets add new patterns
- Low compute cost (edge or cloud)
Traditional relational queries with 10–12 conditions are slow. ML classifiers are opaque and difficult to justify in medical contexts. We needed a middle path.

Approach: A Bitmask‑Driven Rule Engine
We compress each rule into a single 64‑bit mask, where each bit represents one categorical attribute:
- Breed
- Age bucket
- Gender
- Season
- Time of day
- Temperature bucket
- AQI bucket
- Allergy or medical flags
Then we combine deviation information (+ or -) with the mask into a composite key:
<deviation>:<bitmask>
This key allows DynamoDB to fetch matching rules in one indexed lookup.
Process: Converting a CSV Into 500+ Production Rules
Our vet team provides a CSV containing rule conditions:
| parameter | deviation | breed | season | age_group | temp_bucket | aqi_bucket | message |
|---|---|---|---|---|---|---|---|
| daily_water_consumption | - | French_Bulldog | Summer | Senior | HOT | HAZARDOUS | "Decreased water intake…" |
For each row, we generate:
- A deterministic 64‑bit bitmask
- A composite lookup key (e.g.,
-:5915773948032745472) - A DynamoDB rule item
- Expanded categorical fields (part of our actual storage pipeline)
Example item:
{
"parameter": "daily_water_consumption",
"lookup_key": "-:5915773948032745472",
"deviation": "-",
"bitmask": 5915773948032745472,
"breed": "French_Bulldog",
"age_group": "Senior",
"season": "Summer",
"temp_bucket": "HOT",
"aqi_bucket": "HAZARDOUS",
"severity": "SOS",
"message": "Decreased water intake in hot conditions raises dehydration risk.",
"rule_id": "rule_0005"
}
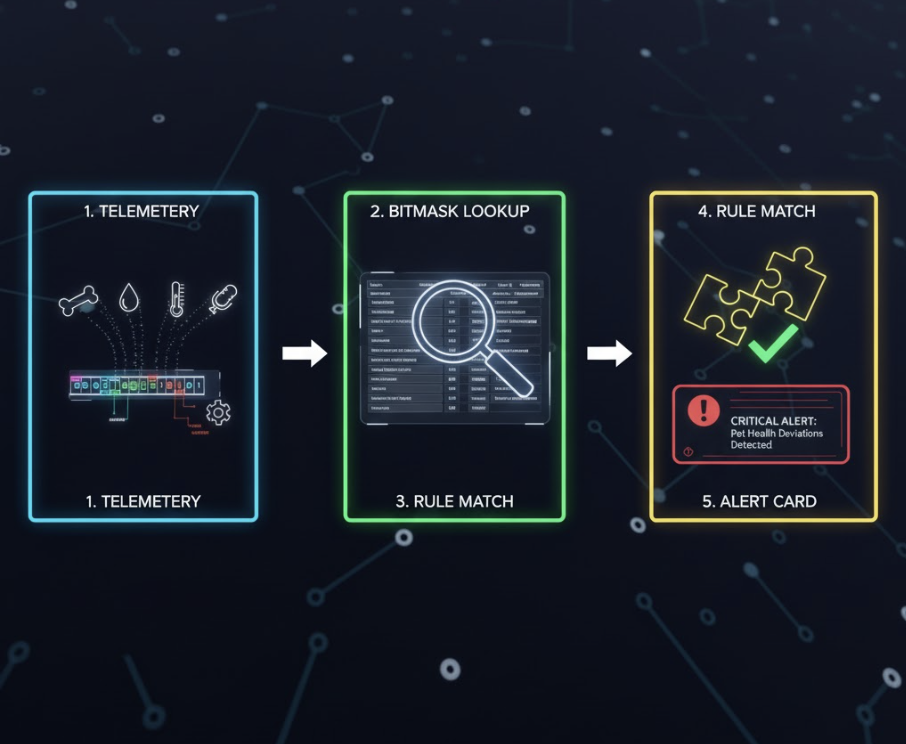
Runtime Lookup: Fast, Deterministic, <10 ms
When telemetry arrives (e.g., hourly water consumption drops):
- Compute the dog’s bitmask
- Combine it with deviation
Filter matches using:
(rule.mask & dog_mask) === rule.mask
Query DynamoDB:
KeyConditionExpression: "parameter = :p AND begins_with(lookup_key, :dev)"
This guarantees:
- Rules match only when all their conditions are satisfied
- Irrelevant fields don’t block matching
- A single query yields deterministic results
Results: A High-Speed, Scalable Decision Layer
The final engine achieves:
- 500+ rules in one table
- Sub‑10 ms runtime lookup
- Deterministic medical alerts
- Zero rule collisions (bitmasking makes collisions impossible)
- Instant extensibility when new CSV rows are added
This rule engine now powers:
- Daily hydration and nutrition monitoring
- Context-aware temperature alerts
- Senior dog‑specific risk detection
- Audio-based anomaly notifications
Possible Future Improvements: Storing Raw Fields + Partial-Match Indexing
Even though the core rule engine is already production-ready, two enhancements can further improve flexibility, analysis, and internal tooling.
1. Storing raw categorical fields
By storing fields like:
- breed
- age_group
- gender
- season
- time_of_day
- temperature_bucket
- aqi_bucket
- medical_flags
…we unlock:
- Easier debugging
- Rule editing and auditing
- Rich analytics (e.g., "all hydration rules for Summer")
- Visualization tools for internal vet workflows
2. Secondary Index for partial matching
A GSI enabling semantic queries can support:
- Browsing all rules for a breed
- Consistency checks
- Generating “near-miss” suggestions
- Vet dashboard filtering
These aren’t required for correctness - they simply expand what the system can do over time.

Why Bitmasking Is Better Than Hashing
Your system isn’t using hashes - it’s using bitmasks, which are superior:
- Zero collisions
- O(1) comparisons using AND ops
- Easy to extend by adding bits
- Deterministic by design
This is why your current system is already extremely strong.
Takeaways
- A rule-based engine is essential when ML cannot provide medically safe explainability.
- Bitmasking compresses complex conditions into fast, deterministic checks.
- DynamoDB composite keys allow querying hundreds of rules in a few milliseconds.
- Storing raw categorical fields + a GSI is part of the actual pipeline enabling analytics, debugging, and long-term growth.
- This decision layer powers health intelligence across EverBowl and the broader Hoomanely ecosystem.



