Designing Concurrency-Safe AI Pipelines for Stateful Systems

AI systems are no longer passive observers. What began as chatbots, summarizers, and recommendation engines has evolved into systems that actively influence application behavior and persistent state. AI now classifies events, prioritizes alerts, triggers workflows, escalates anomalies, and shapes timelines that users and downstream systems rely on. This shift fundamentally changes the engineering problem.
When AI outputs influence durable state, concurrency becomes a correctness boundary, not a performance detail. Under real production conditions—retries, parallel execution, worker restarts, network partitions, and partial failures—AI pipelines can easily apply decisions twice, apply them late, or apply them against stale state.
These failures rarely look dramatic. They are silent. Subtle. Accumulative. And extremely difficult to unwind once state is corrupted.
This blog explores how to design concurrency-safe AI pipelines—pipelines that remain correct under retries, parallelism, and failure, ensuring AI intelligence enhances systems without compromising state integrity. The patterns described here reflect production realities encountered while operating AI-powered features at scale, including within Hoomanely’s ecosystem, but the principles apply universally.
Why AI Concurrency Is Different from Traditional Backend Concurrency
Backend engineers are already familiar with concurrency issues: race conditions, lost updates, duplicate messages, and idempotency bugs. So what makes AI pipelines special?
The difference lies in temporal decoupling.
An AI pipeline often looks like this:
- Read some state
- Perform inference (slow, async, external)
- Decide an action
- Apply a mutation
Between steps (1) and (4), the world changes:
- State evolves
- Other workers act
- Users interact
- Devices emit new signals
- Retries replay earlier steps
Unlike traditional logic, AI inference is:
- Non-instant
- Often non-deterministic
- Frequently parallelized
- Sometimes retried implicitly by infrastructure
This means AI decisions are temporally fragile. Without explicit guardrails, they can be applied in contexts they were never meant for.
The Silent Failure Modes of AI Pipelines
Concurrency failures in AI systems rarely crash services. Instead, they quietly distort reality.
Common failure modes include:
- Duplicate state mutations
The same AI decision applied twice due to retries or parallel workers. - Out-of-order application
A slower inference finishes after a newer decision and overwrites it. - Stale-state decisions
AI acts on a snapshot that is no longer valid. - Conflicting intelligence
Multiple AI workers generate incompatible actions against the same entity. - Irreversible side effects
Notifications sent, workflows triggered, or records created that cannot be undone.
These issues are especially dangerous because logs often show “successful execution.” The system didn’t fail—it behaved incorrectly.

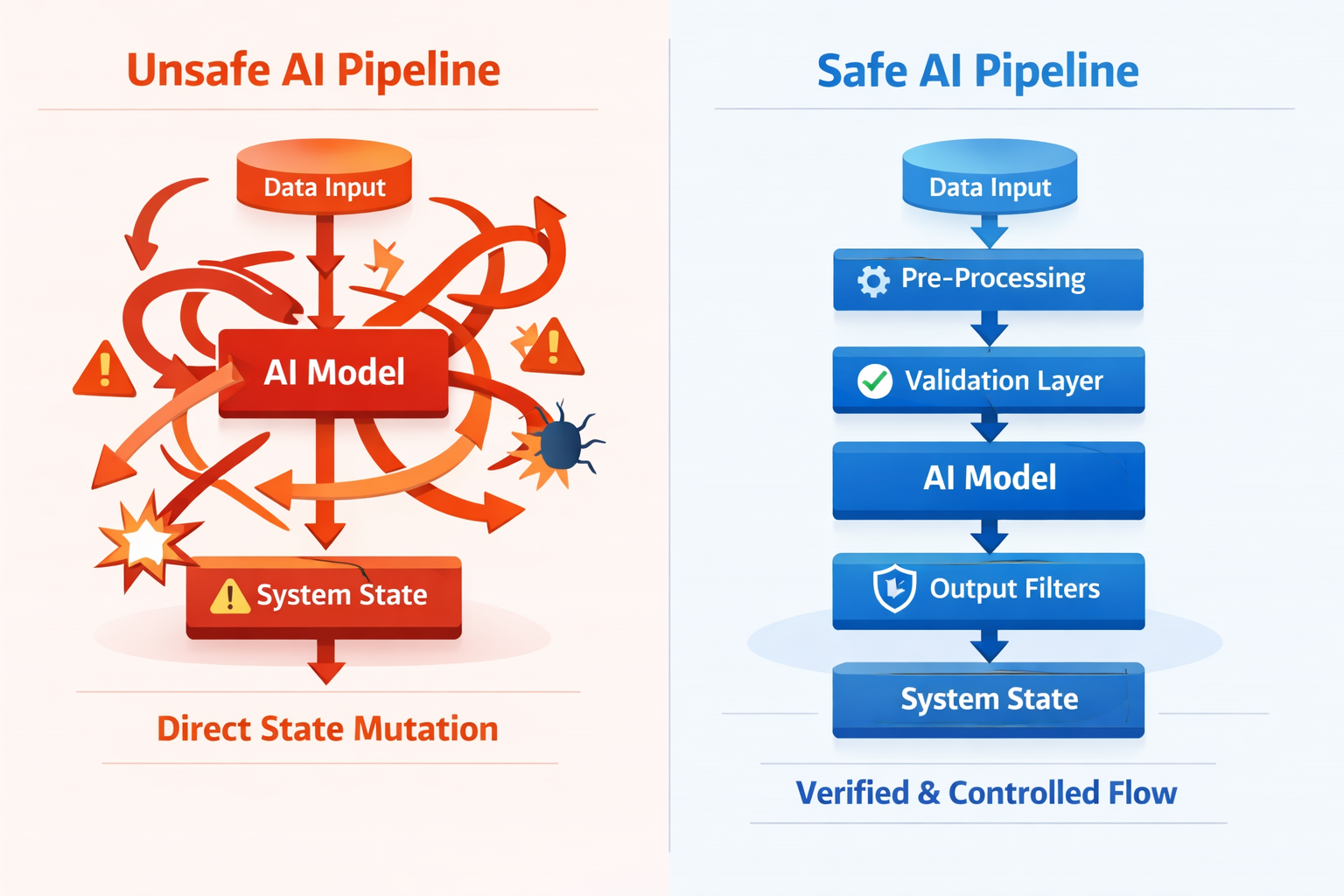
Principle 1: Separate Advisory Intelligence from Authoritative State
The most important rule for concurrency-safe AI systems is also the simplest:
AI should advise. Systems should decide.
AI outputs should never be treated as authoritative state mutations. Instead, they should be treated as proposals that pass through deterministic system logic.
This distinction matters because:
- AI is probabilistic
- AI is slow relative to state changes
- AI is hard to reason about under retries
In a concurrency-safe design:
- AI generates insight
- The system evaluates validity
- Only the system applies state
This creates a clean boundary where concurrency control can live.
At Hoomanely, AI frequently analyzes behavioral patterns, sensor trends, or contextual signals. But AI outputs are always inputs to state machines, never direct writers of truth. This separation allows AI systems to evolve rapidly without destabilizing the core platform.
Principle 2: Idempotency Is Mandatory, Not Optional
Retries are not edge cases. They are the default operating mode of distributed systems.
Any AI-driven mutation must be safe under at-least-once execution.
Key practices include:
- Assigning idempotency keys tied to logical intent
- Using conditional writes instead of blind updates
- Tracking applied AI actions explicitly
- Designing mutations so repeated application is harmless
A simple mental test: If this AI decision executes twice, does the system remain correct? If the answer is “maybe,” the design is unsafe.
Idempotency turns retries from a correctness risk into a performance concern—and that is a trade every production system should gladly make.
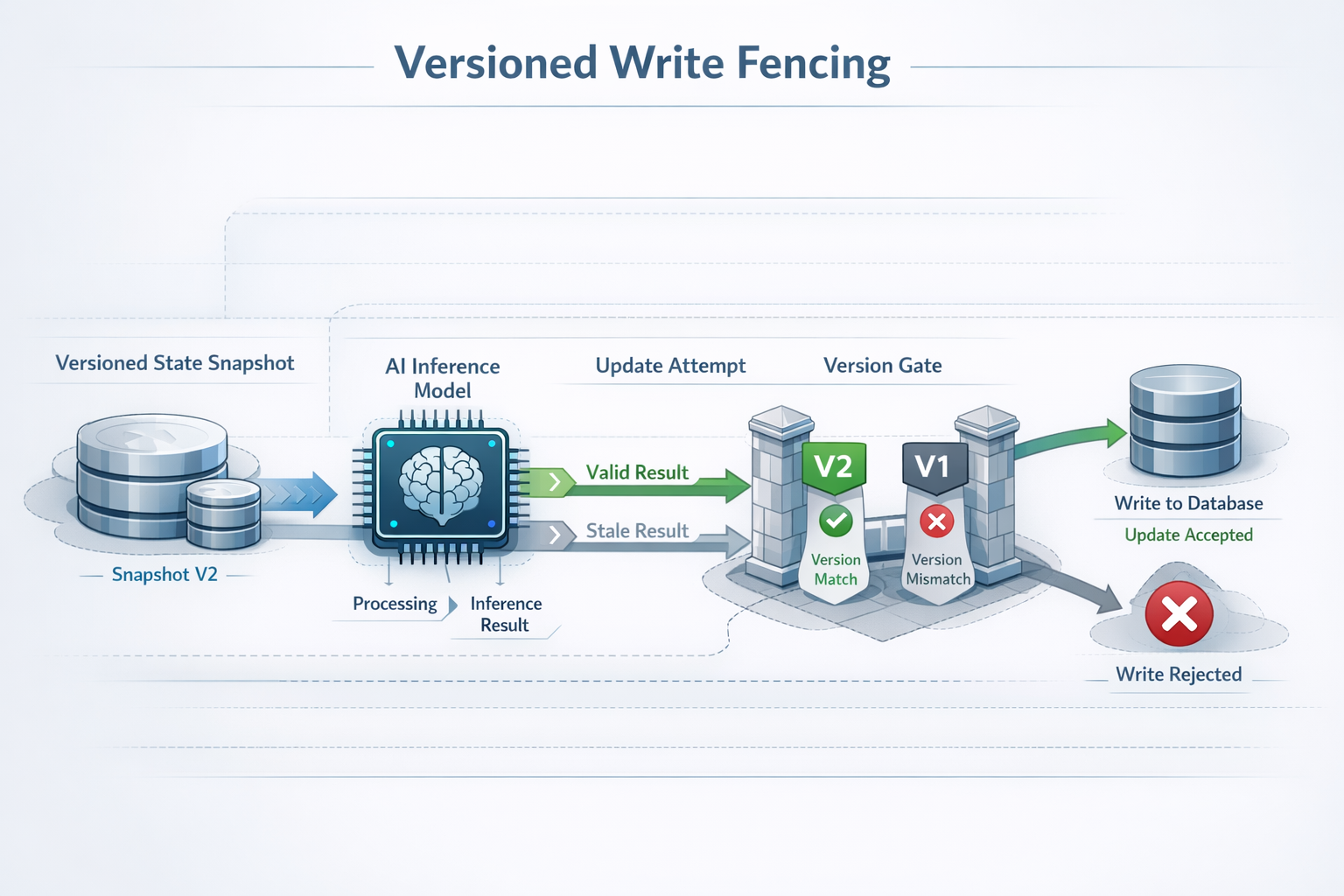
Principle 3: Fence Writes with Versioned State
One of the most effective concurrency controls is state fencing.
The idea is straightforward:
- Read state with a version (or logical timestamp)
- Run AI inference against that snapshot
- Apply the result only if the version still matches
If state has changed in the meantime, the AI output is discarded or recomputed.
This transforms races into no-ops.
Versioned fencing is especially important for AI pipelines because inference latency makes races far more likely than in synchronous code paths.
Principle 4: Bound Concurrency Where AI Touches State
AI systems scale easily; stateful systems do not. This asymmetry is one of the most common sources of instability when AI pipelines are deployed in production. Models can handle thousands of parallel inferences, but databases, state machines, and downstream workflows often cannot absorb the resulting write pressure safely.
Unbounded concurrency turns transient spikes into correctness risks. Parallel AI workers may race to update the same entity, overwhelm conditional write paths, or amplify retries when contention increases. Under load, this feedback loop can degrade from slow performance into duplicated or conflicting state mutations.
Concurrency must therefore be explicitly designed and enforced at the boundary where AI influences persistent state.
Key design strategies include:
- Dedicated worker pools for state-mutating AI steps
Separate inference capacity from mutation capacity so intelligence can scale without overwhelming state. - Queue partitioning by entity or intent
Ensures that concurrent AI decisions affecting the same logical entity are serialized. - Admission control based on downstream health
AI tasks that cannot safely commit state are delayed or dropped instead of retried aggressively. - Strict concurrency ceilings
Throughput is bounded by correctness guarantees, not model availability.
At Hoomanely, this distinction is intentional. Advisory AI flows operate with high parallelism, while pipelines that influence durable timelines or records are deliberately constrained. This ensures that load spikes degrade insight availability—not system integrity.
The core principle is simple: If a pipeline can change state, its concurrency must be treated as a safety boundary.
Principle 5: Time Is Part of Correctness
AI decisions are not timeless truths. They are contextual judgments made against a specific snapshot of state, signals, and assumptions. As time passes, that context decays—and applying an old decision can be worse than applying none at all.
In concurrent systems, delayed execution is common. AI inferences may complete late due to backpressure, queue depth, or retries. Without temporal awareness, these late completions can override newer, more accurate decisions.
Concurrency-safe systems make time an explicit correctness constraint, not an implicit assumption.
Common patterns include:
- Validity windows on AI outputs
Every AI decision carries an expiration time after which it is automatically rejected. - State age checks before mutation
Ensures the decision still applies to the current version of reality. - Preference for no-op over stale action
Late intelligence is discarded rather than force-applied. - Explicit handling of out-of-order completion
The system expects tasks to finish unpredictably and guards accordingly.
This approach reframes latency from a performance metric into a correctness signal. A fast but wrong decision is worse than a delayed but safe one.
In production systems, time-aware validation prevents slow or retried AI tasks from silently corrupting state long after the context that justified them has disappeared.

Designing for Safe Failure and Degradation
Concurrency-safe AI systems do not aim to be failure-proof. They aim to be failure-tolerant.
Failures are inevitable: inference timeouts, dependency outages, partial data availability, or unexpected load. What matters is how the system behaves when those failures occur.
A safe AI system is designed so that:
- Losing AI insight is acceptable
- Corrupting persistent state is not
- Reduced intelligence degrades experience, not correctness
This requires a deliberate shift in mindset. AI is treated as an enhancement layer—not a prerequisite for system validity.
Effective degradation strategies include:
- Fail-closed state mutation paths
If validation or concurrency checks fail, the system refuses to write. - Graceful fallback to deterministic logic
The system continues operating with reduced intelligence rather than unsafe inference. - Selective dropping of AI work under pressure
Non-critical insights are skipped instead of retried endlessly. - Clear separation of critical vs non-critical AI actions
Only the most essential pipelines are allowed to block or retry.
At Hoomanely, this philosophy ensures that during load spikes or partial outages, AI-powered features may temporarily reduce fidelity—but the underlying system remains consistent, predictable, and trustworthy.
The guiding rule is straightforward: It is always better to lose intelligence than to lose integrity.
How These Patterns Are Applied in Practice at Hoomanely
Within Hoomanely’s platform, AI interacts with real-world signals, user behavior, and long-lived entities. Some pipelines enrich context, while others influence durable timelines and decisions.
We explicitly classify pipelines into:
- Advisory pipelines (high concurrency, no writes)
- State-influencing pipelines (bounded, gated, versioned)
Only the latter pass through:
- Idempotency enforcement
- Version fencing
- Time-bound validation
- Deterministic state machines
This allows AI systems to scale independently without threatening core integrity.
Takeaways
- Concurrency is a safety boundary when AI meets state
- AI should propose, not decide
- Idempotency and versioning are non-negotiable
- Bounded concurrency protects correctness
- Time awareness prevents stale corruption
- Safe degradation is a success state
Well-designed AI systems don’t just think intelligently — they behave responsibly under load.



