Designing Hardware That Explains a Reset Event

In embedded systems, resets are often treated as normal behavior. A watchdog expires. A brownout occurs. A PMIC toggles reset. Firmware crashes. Power sequencing fails. A peripheral hangs the bus. A rail collapses temporarily. The system resets and comes back online. From the outside, everything appears functional again.
But the actual failure disappears the moment the reset occurs. This is one of the biggest problems in real-world embedded debugging: the system recovers faster than engineers can understand what happened.
At Hoomanely, we learned this very early while building connected edge devices with multiple processors, sensor domains, cameras, external peripherals, and distributed power architecture. A reset event rarely originates from a single cause. More importantly, the visible symptom is often far away from the real failure source. A device may reboot because a rail dipped for 8 milliseconds, a peripheral locked an interrupt line, a wake source oscillated, an external sensor partially powered through a GPIO, or firmware entered a timing deadlock during suspend. After reboot, the evidence is gone.
Traditional debugging methods struggle here because reset events are inherently destructive. They wipe volatile state, restart sequencing, reinitialize peripherals, and clear the exact conditions engineers need to inspect. This is why we stopped treating resets as isolated processor events. Instead, we started designing hardware that can explain why the reset happened.
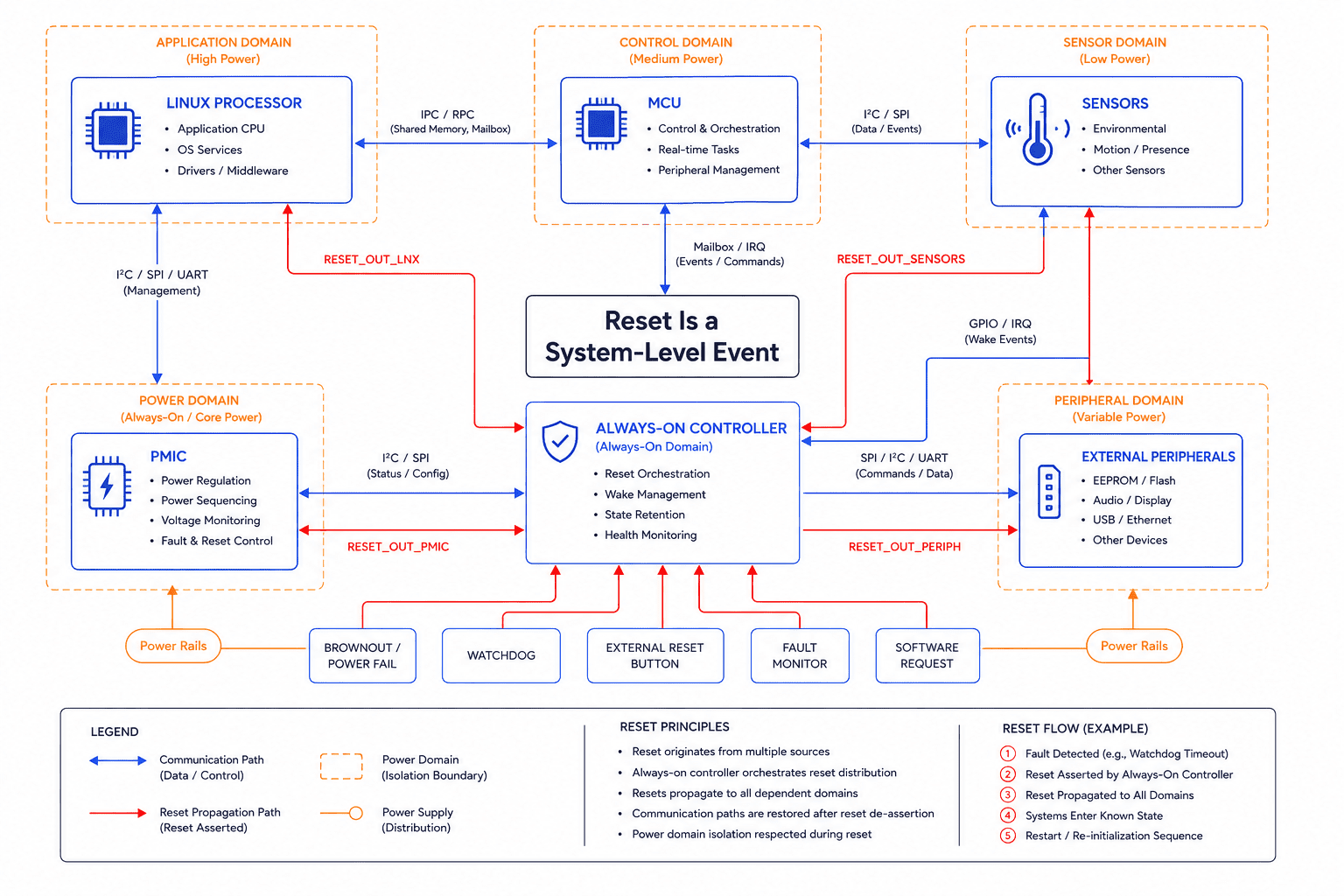
A reset is a system-level event, not an MCU event
Most designs approach reset architecture from the processor's perspective. The MCU has NRST, watchdog reset, brownout reset, software reset, and external reset. The assumption is that understanding the processor reset source is sufficient.
In practice, modern systems contain multiple independent reset domains:
- PMIC reset logic
- External watchdogs
- Sensor reset lines
- Radio reset domains
- Linux processor resets
- USB reset behavior
- Power-good monitors
- Retention domains
- Asynchronous external wake sources
Now the system can enter inconsistent states where one processor resets while another remains active, peripherals reboot while clocks remain unstable, or power domains collapse independently.
The processor may correctly report "external reset occurred." But that doesn't explain which subsystem triggered it, what electrical condition caused it, or what sequence preceded it. The reset source register becomes informationally incomplete. At system scale, reset visibility must extend beyond the MCU.
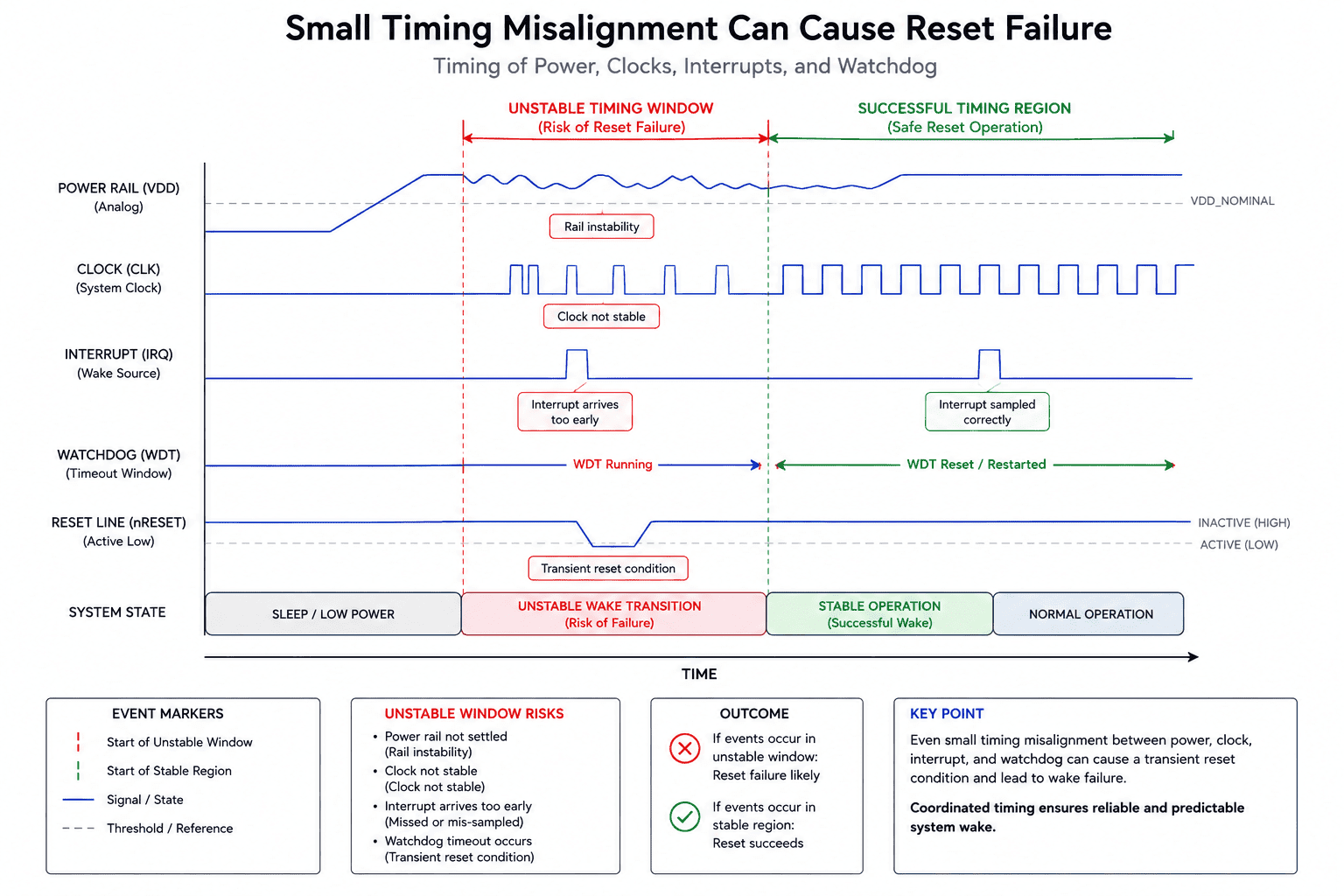
Most reset failures are timing problems
One of the hardest truths in embedded systems is that many reset-related failures aren't permanent faults, they're timing failures. A power rail rises slightly slower during cold temperature startup. A PMIC enable line transitions before a regulator stabilizes. An interrupt arrives during suspend entry. A peripheral exits reset before its clock domain becomes valid. The system fails for milliseconds, then recovers.
These failures are dangerous because they rarely appear consistently during lab validation. They emerge after hundreds of power cycles, under thermal drift, during noisy battery conditions, or only during partial subsystem wake scenarios. Traditional debugging tools struggle because oscilloscopes capture only isolated windows, while firmware logs disappear during reset. This is why reset architecture must preserve system context before recovery destroys it.
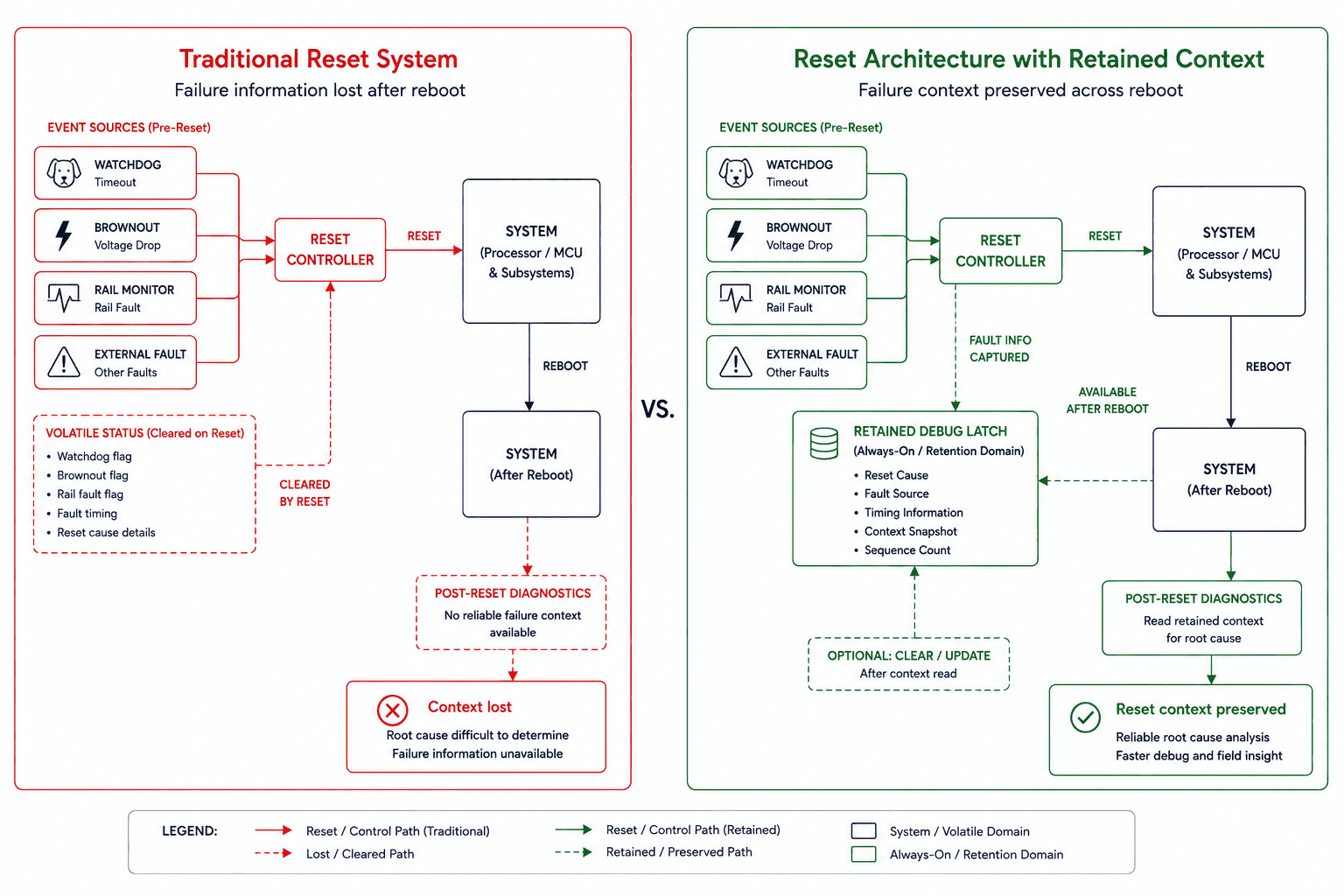
The reset cause must survive the reset
One of the most important architectural principles we adopted was simple: the explanation for a reset must survive the reset itself. This sounds obvious, but most systems don't actually preserve enough information. Common implementations only expose watchdog reset, software reset, brownout reset, and external reset, but those categories are too broad.
A watchdog timeout alone says almost nothing useful. Questions still remain: which subsystem stopped responding, was storage active, was the system entering sleep, was DMA running, did an interrupt storm occur, was a peripheral holding a shared bus, was the rail already unstable before timeout? Similarly, a brownout flag doesn't explain which rail collapsed first, whether the collapse was caused by load transient, sequencing error, or external power instability.
Meaningful reset visibility requires preserving subsystem state, sequencing stage, rail validity, wake ownership, and transition context, not just the reset category.
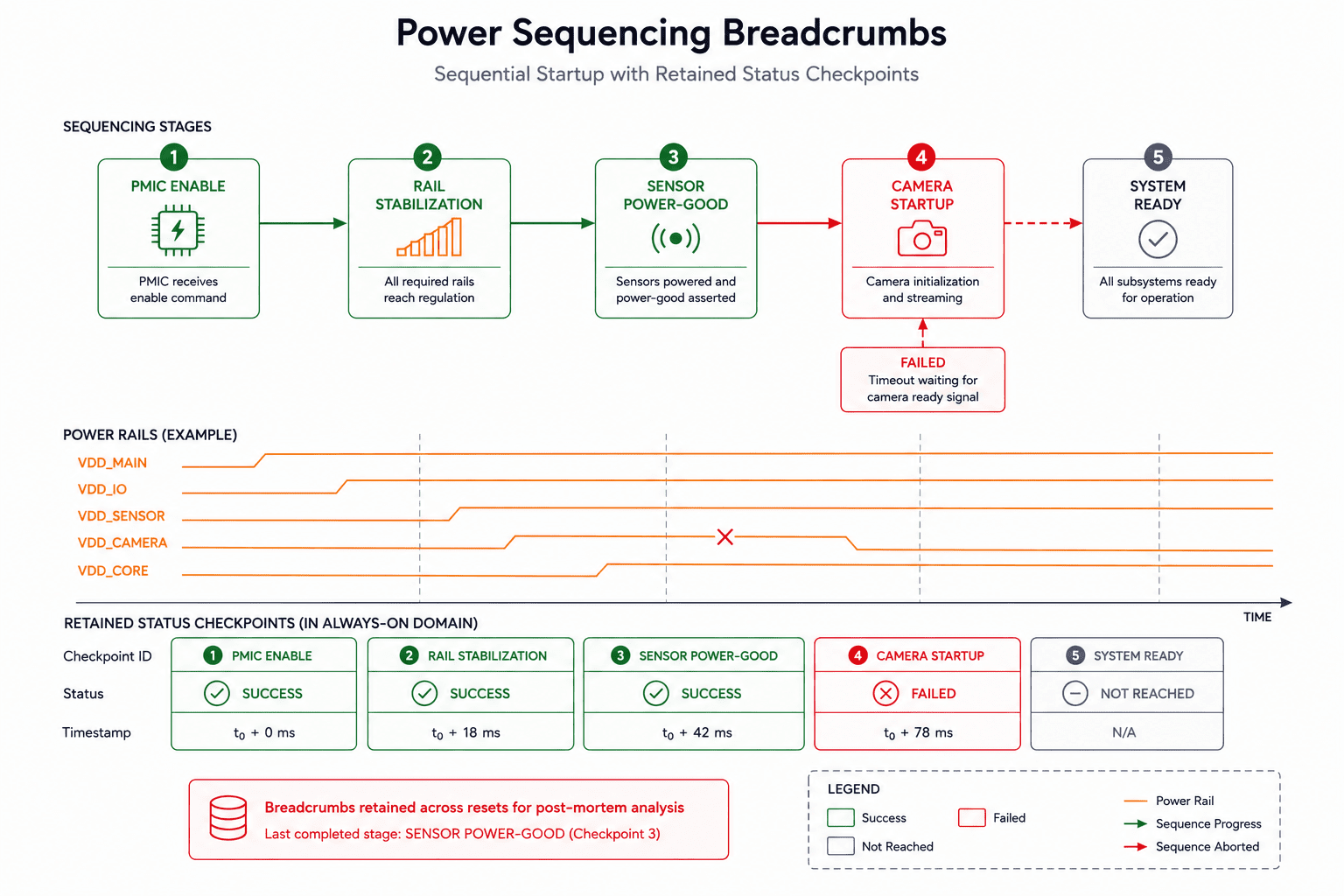
Power sequencing should leave breadcrumbs
One of the most effective approaches we implemented was making power sequencing self-observable. Instead of treating sequencing as hidden hardware behavior, we began exposing sequencing progression explicitly through GPIO state indicators, latchable fault flags, persistent PMIC status, rail-good monitoring, subsystem handshake signals, and retained debug state.
Now, if a subsystem fails during bring-up, the system can identify how far sequencing progressed, which rail failed validation, which domain never acknowledged readiness, or which dependency violated timing constraints. This transforms debugging dramatically. Without sequencing visibility, the report is "the board resets randomly." With sequencing visibility, it's "sensor domain acknowledged power-good, but camera rail never stabilized before watchdog expiration." The second statement is actionable engineering information. The first is noise.
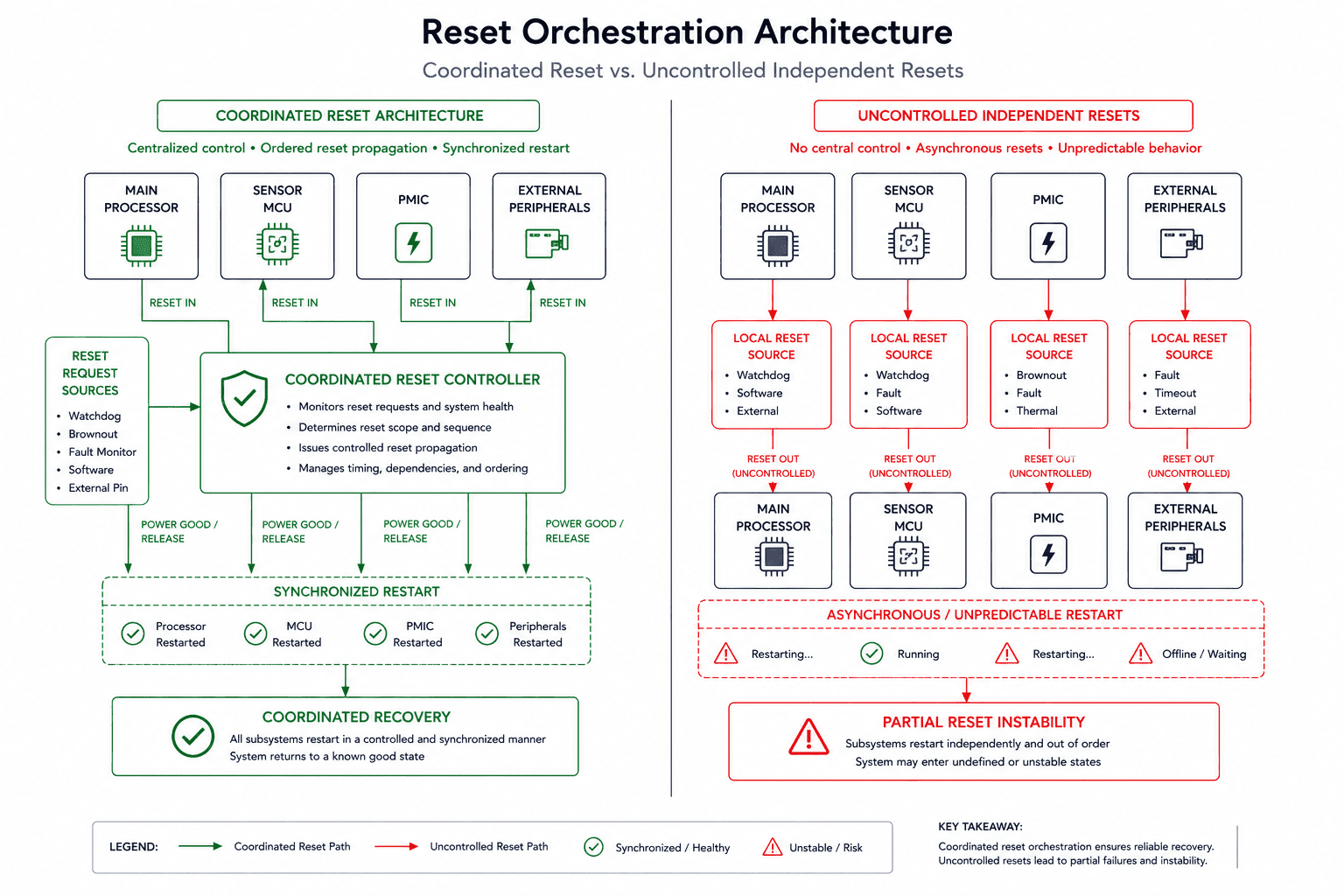
Coordinated reset architecture matters
In distributed systems, resets must behave predictably across subsystems. A common mistake is allowing every processor or peripheral to reset independently without coordination. Initially this appears modular, in practice it creates inconsistent system states. Linux resets while sensor MCUs remain active, peripheral state machines continue running, shared buses remain busy, or retained interrupts survive unexpectedly.
Now the restarted processor re-enters a system whose external state no longer matches initialization assumptions. These are some of the hardest bugs to reproduce because the reset itself creates nondeterministic system conditions. At Hoomanely, we gradually shifted toward reset orchestration rather than isolated reset ownership. Some resets must remain local. Others must propagate across domains intentionally. The key is that reset behavior should be architecturally defined, not accidentally emergent.
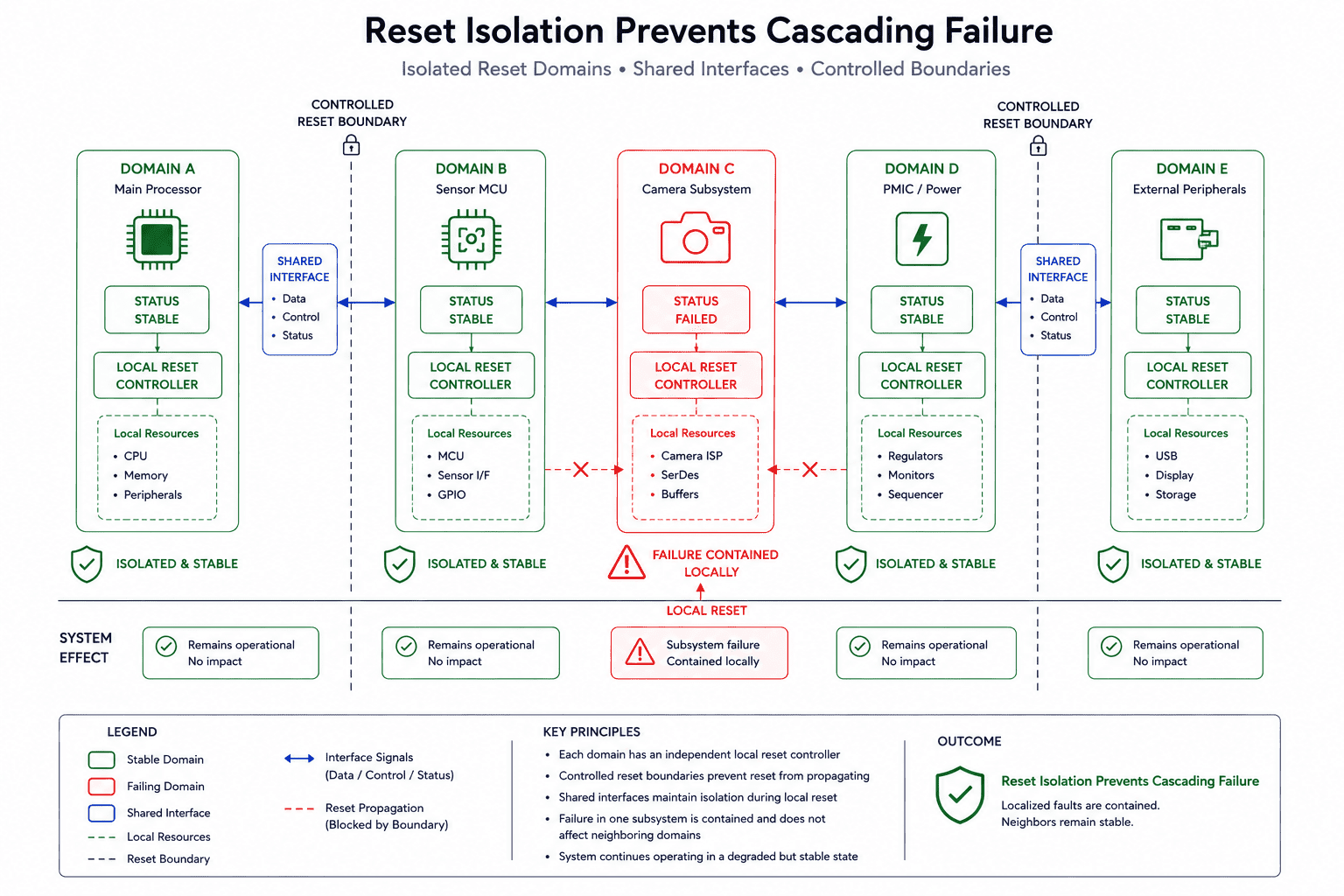
Reset boundaries are architectural boundaries
One of the clearest indicators of system maturity is how intentionally reset boundaries are designed. In weaker architectures, resets spread unpredictably, one subsystem glitches another, partial rail collapse triggers unrelated domains, shared enables create cascading resets, or watchdog recovery unintentionally destabilizes neighboring logic.
In stronger architectures, reset domains are explicit. Subsystems understand who can reset them, which rails affect them, what dependencies must exist before startup, and which signals remain valid during recovery. This becomes especially important in systems with external sensors, detachable modules, SOM-carrier separation, distributed processors, or mixed-voltage domains. Reset isolation isn't just about fault recovery, it's about preventing unrelated failures from propagating unnecessarily.
Hardware should explain failure without firmware
One major design mistake is relying entirely on firmware logging for reset diagnosis. Firmware is fragile during failures, especially during watchdog events, clock instability, stack corruption, memory faults, power collapse, or partial resets. In many critical failures, firmware never gets the opportunity to log useful information.
This is why hardware-level observability matters. Some of the most valuable debug mechanisms are extremely simple: retained fault latches, persistent rail indicators, sequencing LEDs, reset-source propagation lines, hardware fault aggregation, or GPIO-driven debug checkpoints. These mechanisms survive conditions where firmware cannot, providing visibility during the exact moments where software loses control.
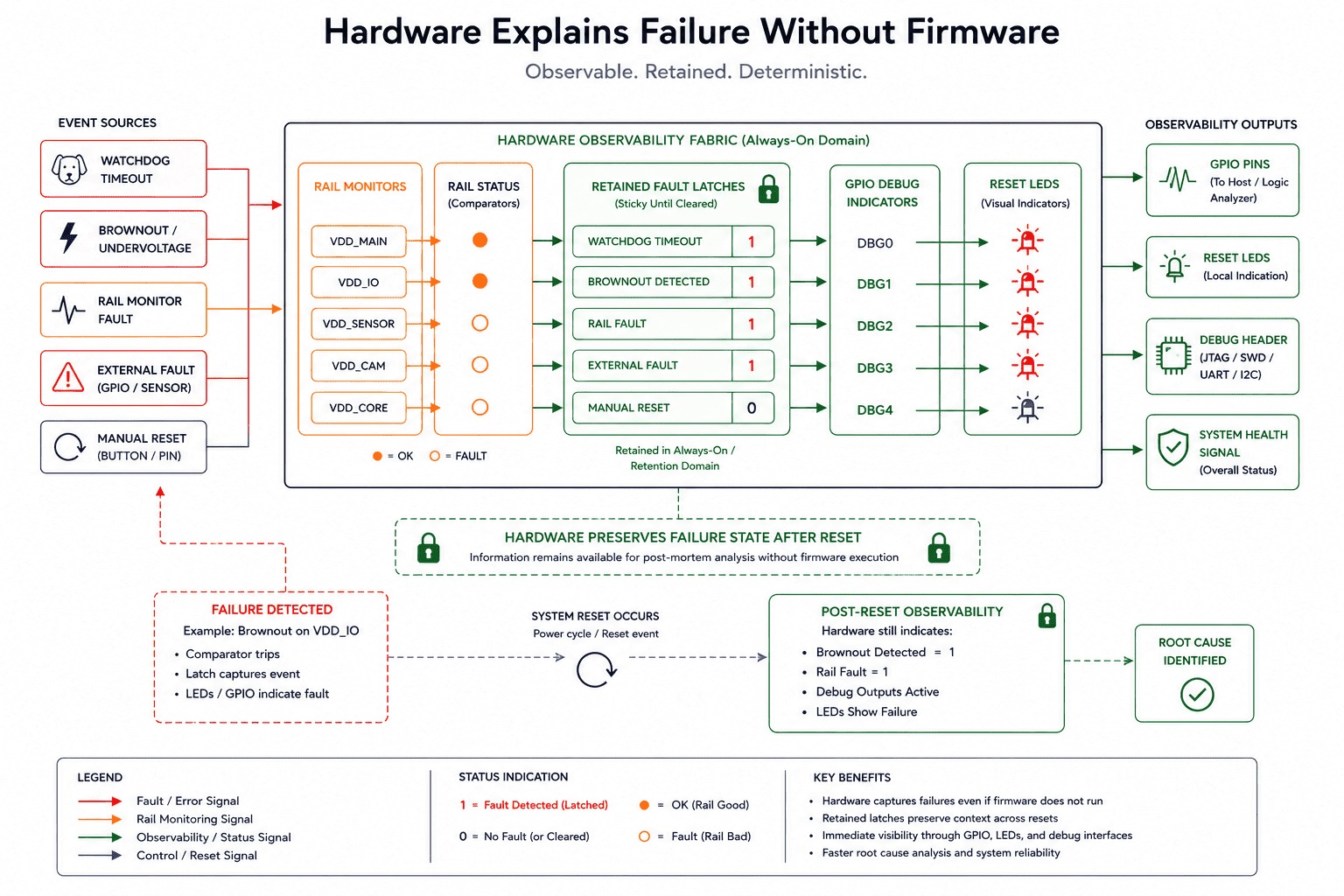
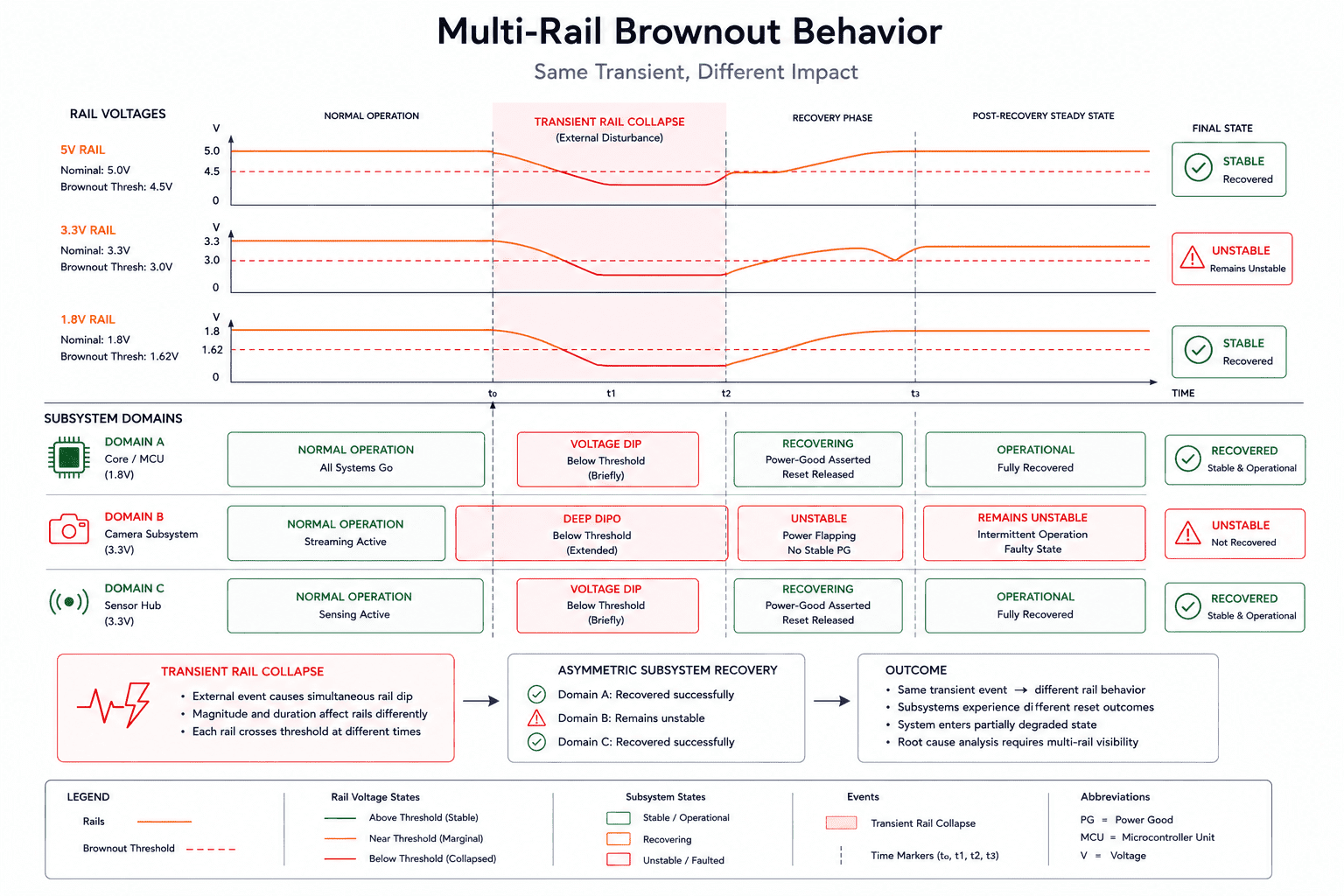
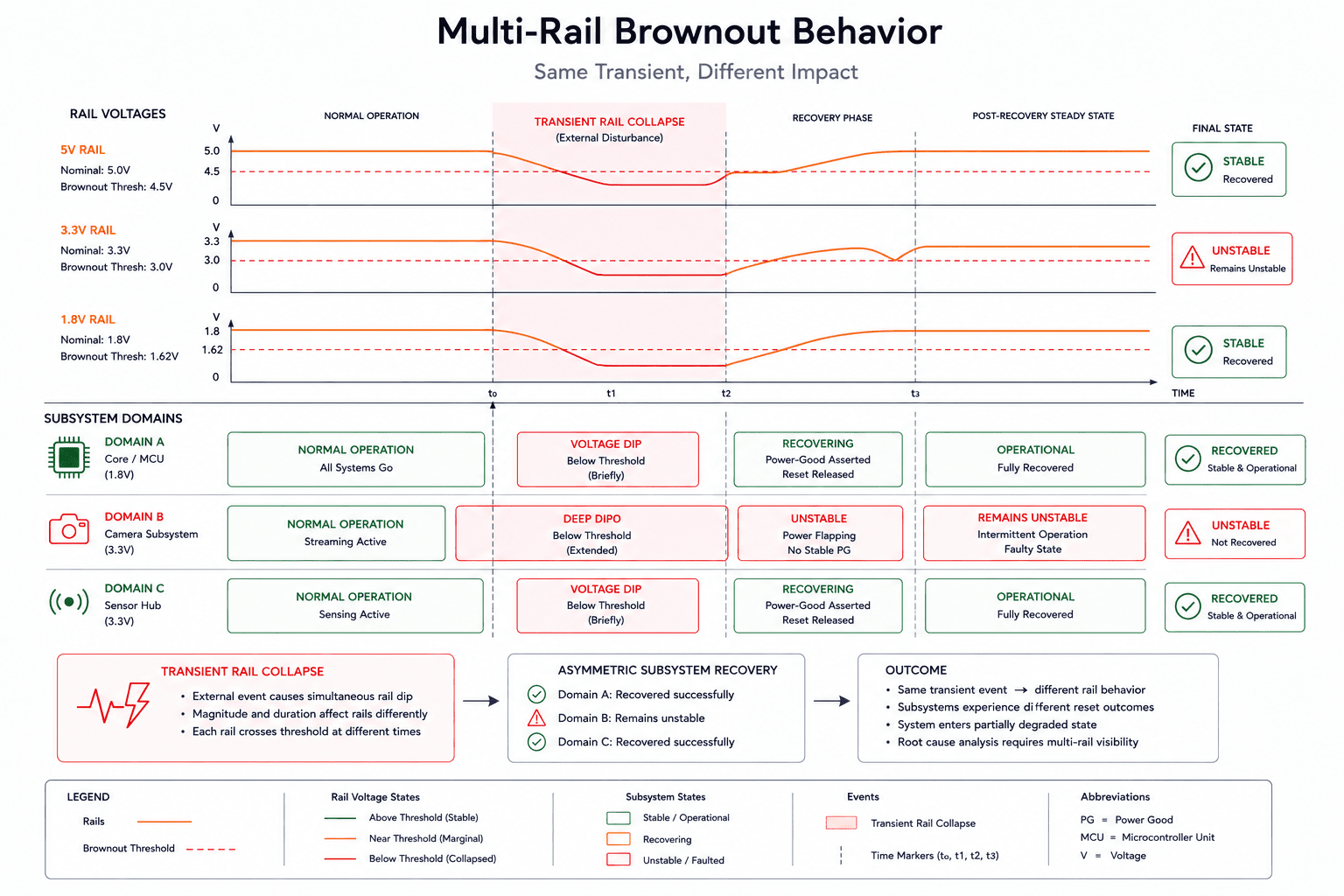
Brownouts rarely look like brownouts
One of the most misleading reset categories is the brownout reset. Engineers often imagine brownouts as large visible voltage drops. Real brownouts are frequently much smaller, transient dips, sequencing instability, localized rail collapse, fast load spikes, or temporary regulator saturation. Some last only microseconds.
Yet those brief events can corrupt transactions, destabilize clocks, violate timing assumptions, or trigger undefined peripheral behavior before the processor itself resets. In distributed systems, different rails react differently to the same event, one subsystem may recover immediately, another may partially reset, another may remain electrically unstable without fully rebooting. This creates inconsistent system behavior that looks like firmware instability while actually originating from power integrity, which is why rail visibility and sequencing observability become essential during reset analysis.
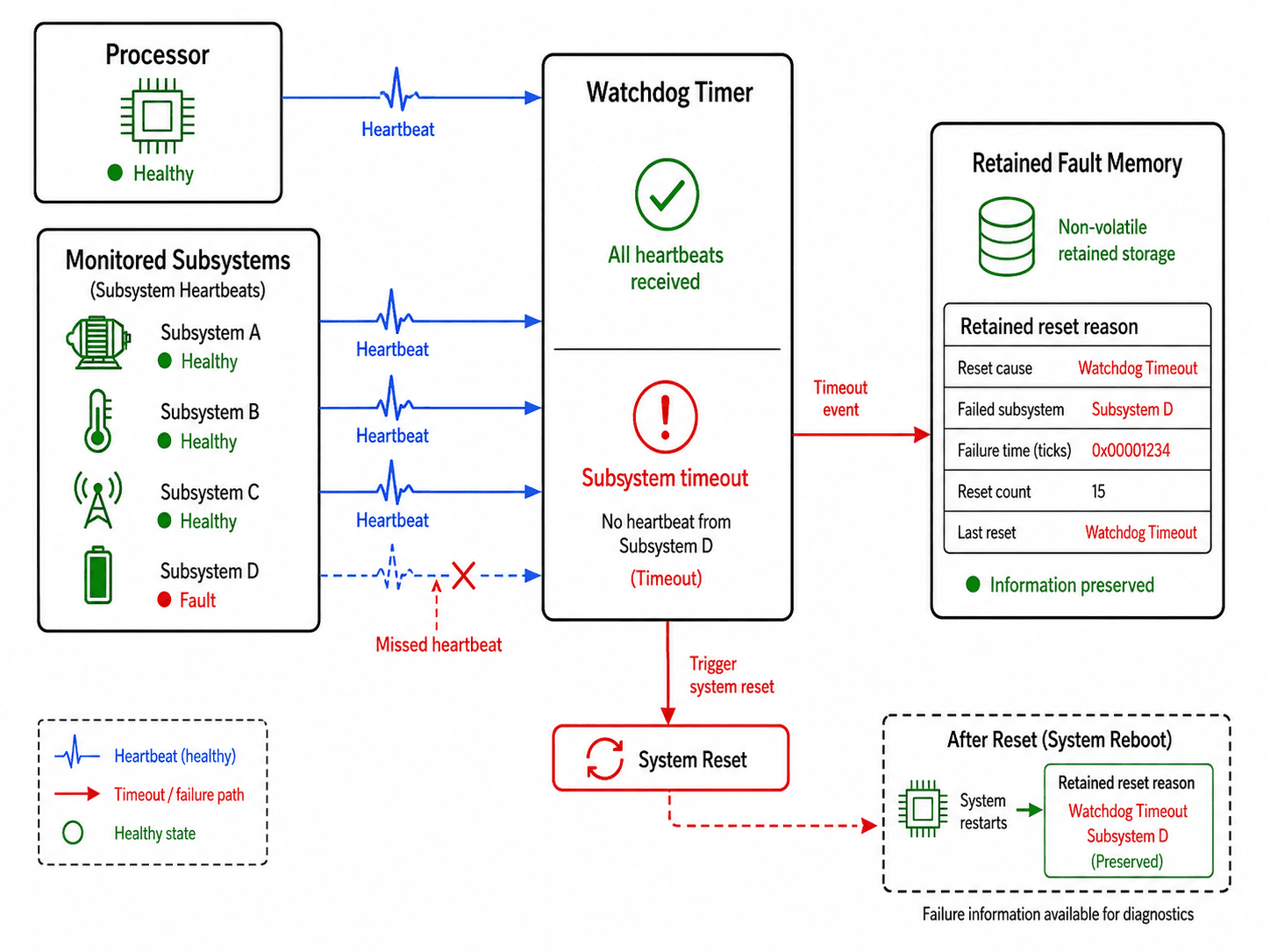
Watchdogs should explain what timed out
Many systems implement watchdogs as binary recovery tools, system alive or system dead. But watchdog architecture becomes far more useful when paired with subsystem observability. Instead of simply resetting the processor, the system should preserve which subsystem stopped responding, which task failed heartbeat validation, whether storage or communication was active, and what operating mode existed before timeout.
Otherwise the watchdog only tells engineers "something failed eventually," rarely enough. A well-designed watchdog system narrows the problem space immediately, especially important in systems containing asynchronous peripherals, distributed processors, external sensors, and multiple timing domains, since not all watchdog failures originate in the processor itself. Sometimes the processor is merely the victim of another subsystem failing first.
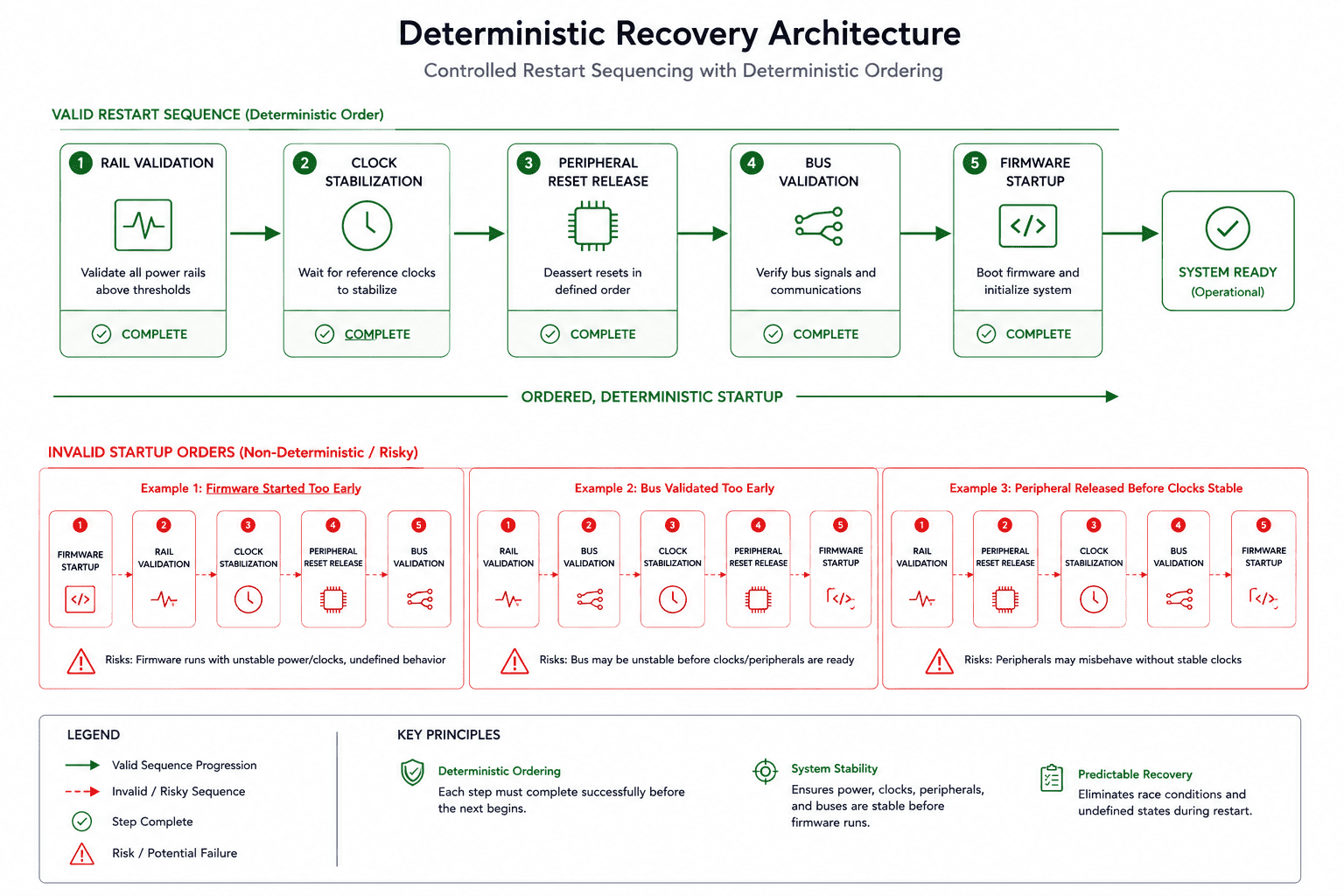
Reset recovery must be deterministic
A reset event is only half the problem. Recovery behavior matters equally. Many systems recover inconsistently because startup assumptions are invalid after partial subsystem resets, retained peripherals may still hold interrupts, buses may remain busy, sensors may require stabilization delays, or external domains may not have fully collapsed.
Now recovery timing changes depending on the previous failure mode. At Hoomanely, we learned that deterministic recovery requires explicit startup sequencing, rail validation before initialization, subsystem acknowledgement, timeout-aware bring-up, and controlled dependency ordering. Otherwise, resets simply hide instability temporarily before the next failure occurs.
Final thoughts
Reset architecture is often treated as simple infrastructure. In reality it's one of the most important observability systems inside an embedded product. A reset event represents power behavior, subsystem coordination, timing integrity, sequencing correctness, and architectural maturity.
When reset visibility is weak, engineers spend days reproducing failures. When reset visibility is strong, failures become diagnosable almost immediately. The difference isn't luck. It's whether the system was intentionally designed to preserve context during failure. Because in modern embedded systems, the hardest bugs are rarely the ones that crash permanently. They're the ones that recover before anyone understands why they happened.