Edge vs Cloud Inference: Finding the Right Balance for Real-World ML


Introduction
Over the past decade, cloud inference has powered most large-scale machine learning systems — from recommendation engines to speech assistants. But as devices at the edge get faster, cheaper, and more privacy-aware, a hybrid pattern is emerging: compute just enough on the device to protect the user and reduce noise, and push the heavier tasks to the cloud for deeper understanding.
At Hoomanely, this hybrid flow is essential. Our smart feeding bowls and wearables run on compact compute modules with tight storage limits, yet they capture sensitive thermal, audio, and motion data from inside homes. To safeguard user privacy while still enabling high-quality insights (like anomaly detection, eating behavior classification, or indicative temperature trends), we perform first-level filtering directly on the edge — removing human speech, masking backgrounds, segmenting dog regions — and send only the sanitized, ML-ready signals to the cloud for advanced inference.
This post explains why edge inference matters, where cloud inference still wins, and how combining both gives the most reliable, privacy-safe, and cost-efficient architecture for pet-tech and other IoT ecosystems.
The Problem: Sending Raw Data to the Cloud Doesn’t Scale
When ML systems rely exclusively on cloud inference, three big issues show up quickly:
1. Privacy Risks
Raw audio from homes, full-frame camera images, and unfiltered sensor data often contain:
- human speech
- people and objects in the background
- identifiable environments
Uploading this directly to servers creates compliance challenges and user mistrust.
2. Bandwidth + Cost Explosion
A single uncompressed 640×480 RGB frame is ~900 KB.
A 10-second audio snippet sampled at 16 kHz is ~320 KB.
Multiply this by:
- every detection trigger
- every device online
- every household
…and cloud ingestion becomes expensive, slow, and energy-hungry.
3. Latency Breaks Real-Time Use Cases
Actions like:
- suppressing false alerts
- identifying dog-presence in bowls
- triggering audio-based events
…need fast response times. Sending everything to a server introduces network delays and often fails in patchy WiFi conditions.
Raw → Cloud → Output is simply too slow, too expensive, and too risky.
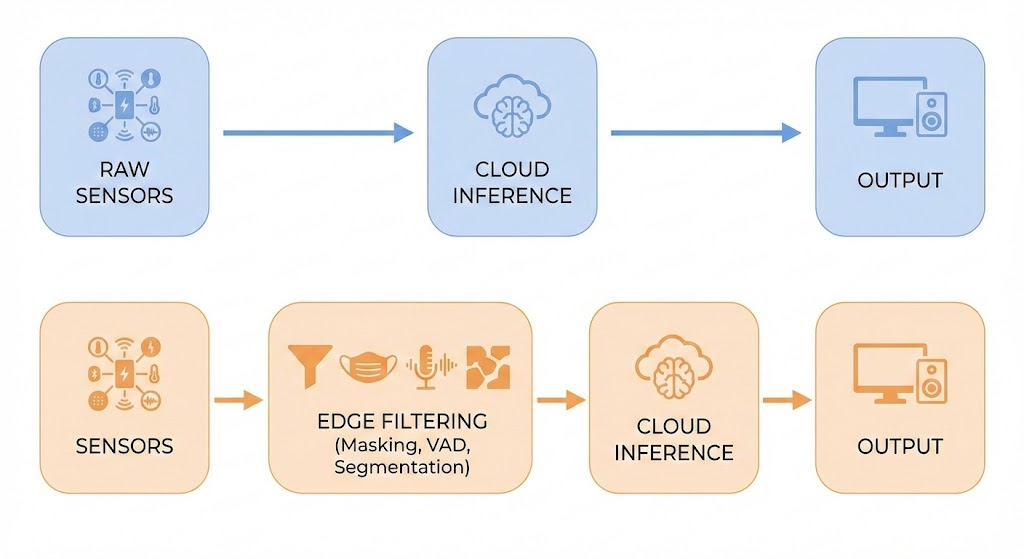
The Approach: Split Inference Into Edge Tasks and Cloud Tasks
A modern hybrid architecture answers the problems above by distributing ML tasks based on who is best suited to perform them.
Here’s how the division typically looks:
🔹 What the Edge Should Do
Fast, lightweight, privacy-critical filtering.
- Dog vs Non-Dog Filtering
Tiny CNN/YOLO-N models can discard frames where no dog is present — reducing uploads by 70–90%. - Background Masking or Eye/Nose Segmentation
Only send the dog-relevant region (e.g., cropped eyes for temperature estimation). - Audio Noise Removal
Models like MelCNN or tiny-TasNet remove human speech before any data leaves the bowl. - Frame Selection / Event Triggering
Edge inference decides when something interesting has happened. - Device-side Compression + Sanitization
Replace identifiable backgrounds with masks.
Edge inference acts as a privacy filter + data compressor + relevance engine.
🔹 What the Cloud Should Do
Heavy models, deep reasoning, long-context understanding.
- Anomaly Detection
Detecting unusual patterns in eating behavior requires months of longitudinal data — not practical on-device. - Fine-grained Classification
Breed identification, illness-associated patterns, or multi-class behavior models are bigger and slower. - Time-Series Aggregation + Trends
Cloud databases can correlate thousands of daily records over time. - Large Models (Transformers, Deep CNNS, Multimodal Fusion)
These are far beyond the edge’s memory budget.
Cloud inference excels at global context, deeper accuracy, and cross-session intelligence.
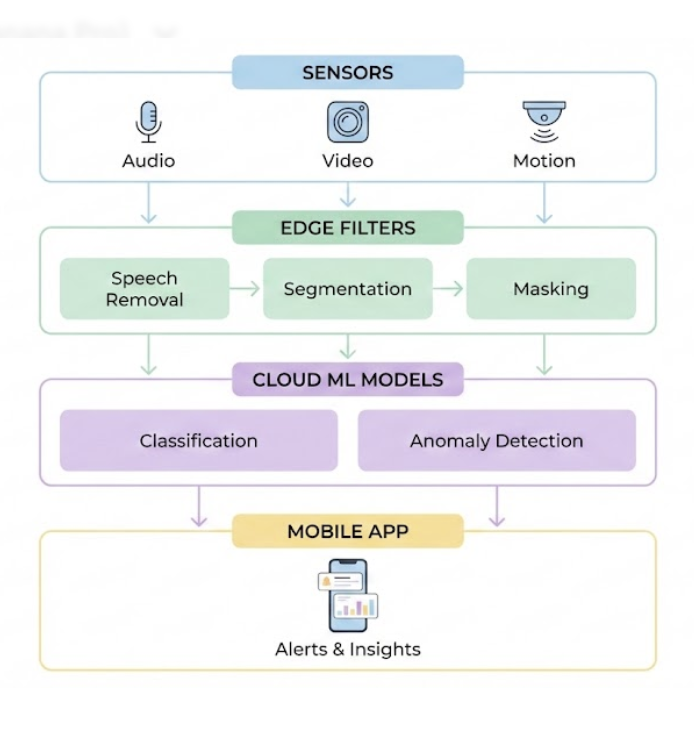
How Edge + Cloud Work Together: The Hybrid Pipeline
To illustrate how this unfolds in production, here is a typical data journey inside a smart pet device.
1. Capture → Edge Preprocessing
The device captures:
- RGB frame
- Thermal frame
- 10-second audio window
- IMU motion segment
Each goes through an edge-pass:
| Sensor | Edge Step | Purpose |
|---|---|---|
| RGB | Dog-presence model → background masking | Remove people, walls, furniture |
| Thermal | Eye-region segmentation | Reduce irrelevant temperature noise |
| Audio | Human-speech removal + VAD | Ensure privacy & remove false detections |
| IMU | Lightweight event classifier | Avoid uploading massive raw sequences |
2. Sanitized Data → Cloud
Only compressed, masked, dog-only data is transmitted.
3. Cloud Inference
The server performs:
- Dog eating vs non-eating classification
- Anomaly scoring on meal embeddings
- Temperature pattern analysis
- Activity classification (running, resting, scratching)
- Long-term trend forecasting
4. Final Output to User Apps
Cloud pushes the processed insights to:
- daily summaries
- real-time alerts
- vet-assistant Q&A systems
- anomaly notifications
This hybrid pipeline ensures privacy, speed, efficiency, and scalability — all without compromising model accuracy.
Why Edge Inference Matters More Than Ever
1. Privacy-by-Design
Edge filtering removes:
- human speech
- backgrounds
- personally identifiable information
…before the data leaves the user’s home — an essential part of GDPR-aligned and trust-first design.
2. Lower Bandwidth + Lower Cloud Cost
If you block 90% irrelevant frames at the edge:
- uploads shrink
- ingestion cost shrinks
- storage shrinks
This makes the system sustainable as device fleets grow.
3. Lower Latency and Higher Reliability
Inference that must happen instantly — like detecting dog presence or triggering an event — belongs on the device.
4. Better User Experience
Cloud outages or slow WiFi shouldn’t break core functionality.
Edge ensures devices keep working even if the internet doesn’t.
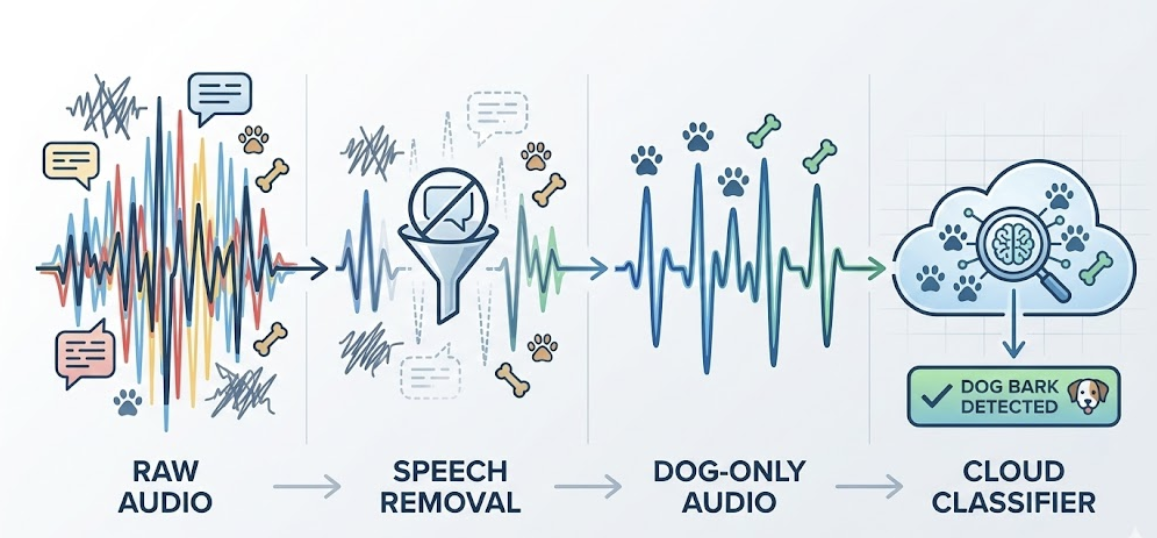
A Real Example: How Audio Is Processed on the Edge
Smart bowls need to differentiate:
- eating
- drinking
- barking
- background noise
- human speech
Sending raw 10-second audio clips to the cloud is:
- wasteful
- slow
- privacy-sensitive
Instead, the audio flow works like this:
- Edge Step: Human Speech Removal
A lightweight denoiser (e.g., MelCNN-Tiny) filters out speech. - Edge Step: VAD + Keyword Masking
Voice Activity Detection ensures non-speech is passed forward. - Edge Step: Class Pre-filter
Only clips where animal-like activity is detected are kept. - Cloud Step: High-accuracy Classification + Anomaly Detection
Cloud models compute:- probability curves
- meal embeddings
- long-term behavioral deviations
This saves 80–90% upload size and removes all personally sensitive audio.
When Should You Choose Edge vs Cloud? A Practical Framework
Think of inference placement as a decision tree:
1. Is the data privacy-sensitive?
- Yes → Do first-level processing on edge
- No → Can send raw to cloud (but consider costs)
2. Is the use case latency-critical?
- Yes → Edge
- No → Cloud is fine
3. Is the model too large for the device?
- Yes → Cloud
- No → Edge or hybrid
4. Do you need long-term historical context?
- Yes → Cloud
5. Is bandwidth limited or expensive?
- Yes → Edge-filtering required
A rule of thumb:
Edge handles immediacy and privacy. Cloud handles depth and intelligence.
Results: Why Hybrid ML Improves System Accuracy and Reliability
Teams adopting Edge + Cloud pipelines consistently see:
✔ 70–90% Reduction in Upload Volume
Edge filtering discards irrelevant and private frames.
✔ 2–4× Faster Real-Time Decisions
Latency-sensitive triggers run locally.
✔ Reduced False Positives
Speech removal, background masking, and dog-presence filtering dramatically improve model precision.
✔ Improved User Privacy and Trust
Only sanitized data is uploaded.
✔ Lower Compute Costs Over Time
Cloud inference scales linearly; edge offsets the load.
Key Takeaways
- Edge and Cloud are not competitors — they complement each other.
- Edge inference protects privacy, reduces bandwidth, and supports real-time decisions.
- Cloud inference delivers deeper, long-context intelligence that edge devices cannot handle.
- A hybrid, privacy-first ML pipeline is now the best architecture for smart consumer IoT, pet-tech, wearables, and home robotics.
- At scale, this approach reduces cost, improves accuracy, and builds long-term trust with users.



