Graceful Degradation: What We Turn Off First


When an edge AI system starts to fail, it rarely fails all at once.
Memory pressure creeps up. DMA stalls appear sporadically. Inference deadlines start slipping. Power draw spikes in ways the lab never showed.
The question is not whether something will break in production — it’s what you choose to sacrifice first.
At Hoomanely, graceful degradation became a design requirement only after we learned the hard way: uncontrolled failure is far worse than intentional loss of capability.
This post walks through how we designed our edge AI stack to degrade deliberately, what we turn off first, and why these choices matter more than peak accuracy.
The Wrong Way to Fail
Our early systems failed implicitly.
When memory ran out, the process crashed.
When inference fell behind, frames piled up.
When multiple pipelines ran together, DMA contention quietly starved sensors.
Nothing told us what was being lost — only that something had already gone wrong.
In real homes, this translated to:
- missing events without explanation
- delayed alerts after the moment passed
- silent model resets that looked like false negatives
We needed failure to be explicit, predictable, and reversible.
Degradation Is a Policy, Not a Bug
Graceful degradation is not about squeezing the last bit of performance out of a dying system.
It is about deciding which capabilities matter most when resources become scarce.
That meant answering uncomfortable questions upfront:
- Is partial vision better than delayed vision?
- Is low-frequency inference better than no inference?
- Is raw sensor data more valuable than a model prediction?
Once we framed degradation as policy, not accident, the architecture changed.
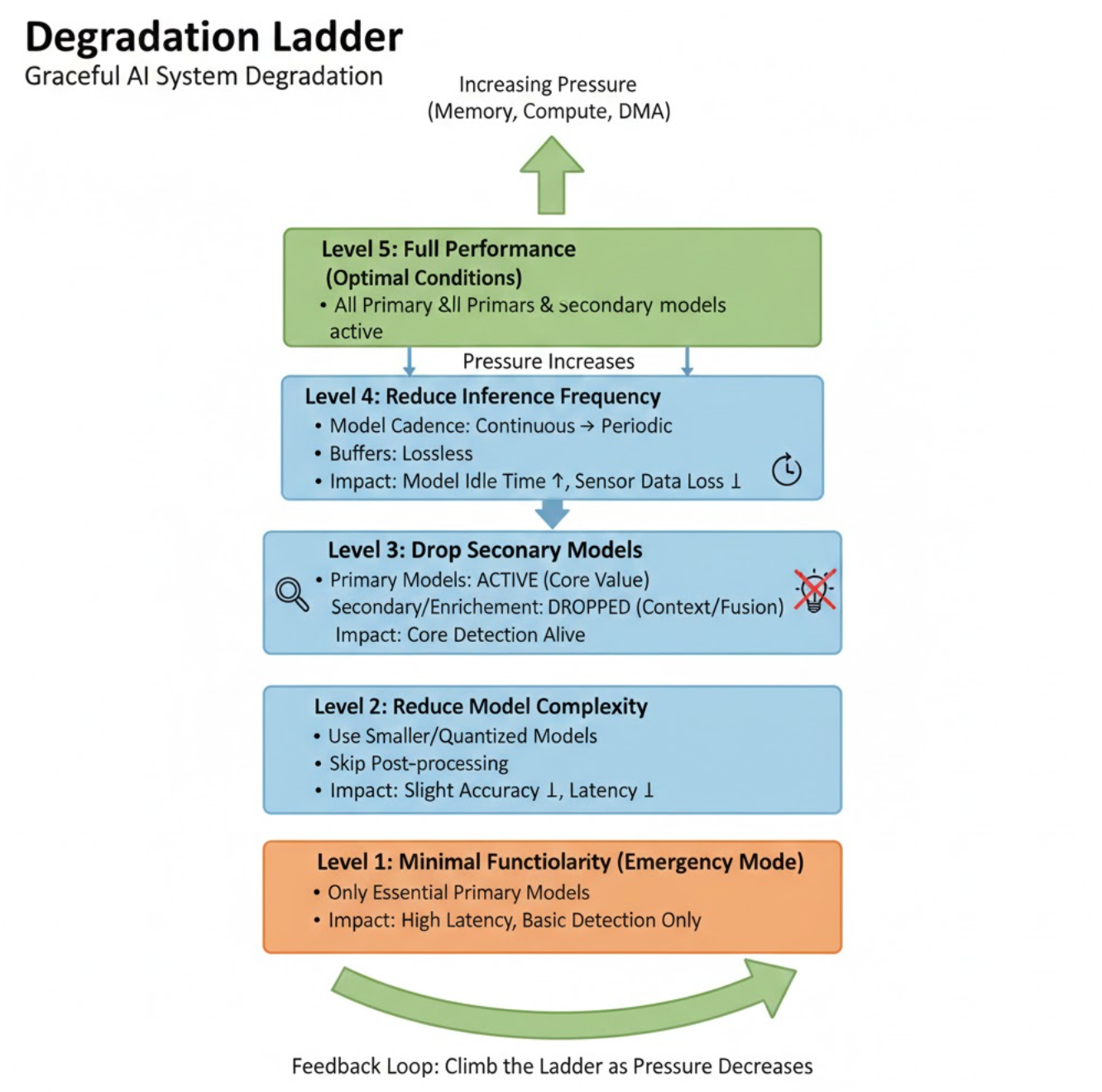
The Degradation Ladder
We designed our system around a strict, ordered ladder of capability loss.
When pressure increases, the system climbs this ladder — one rung at a time — instead of falling off a cliff.
1. Reduce Inference Frequency (Not Sensor Capture)
The first thing we slow down is model inference, never sensors.
Sensors run on reality’s clock. Models run on compute’s clock.
When memory or DMA pressure rises:
- sensor sampling remains untouched
- buffers stay lossless
- inference cadence drops from continuous → periodic
This preserves ground truth for later reasoning.
Observed impact:
- Model idle time ↑
- Sensor data loss ↓ to near zero
- User-visible latency unchanged
2. Drop Secondary Models
Not all models are equally important.
Our pipelines distinguish between:
- primary detection models (core user value)
- secondary enrichment models (nice-to-have context)
When contention increases, enrichment goes first.
Examples:
- confidence refinement
- secondary classification heads
- optional fusion passes
This keeps core detection alive while reducing compute load.
3. Reduce Spatial or Temporal Resolution (Never Both)
If we must degrade signal quality, we do it along one axis only.
For vision:
- reduce frame rate or resolution, not both
For audio:
- shorten windows or reduce overlap, not both
Collapsing both dimensions destroys semantic structure.
Preserving one dimension allows models to stay calibrated.
4. Disable Fusion Before Core Signals
Multi-modal fusion is powerful — and expensive.
When resources tighten:
- fusion pipelines pause
- raw modality pipelines continue independently
A good single signal beats a bad fusion.
We would rather deliver a confident audio-only inference than a confused audio+vision output.
5. Enter Observation-Only Mode
The final rung is observation without inference.
In this mode:
- sensors run
- data is buffered or summarized
- models stop executing
This is not failure.
It is preparation.
Once pressure subsides, inference resumes on fresh data.
What We Never Turn Off First
Some things are non-negotiable.
We never sacrifice:
- sensor integrity
- time synchronization
- buffer correctness
Corrupt data is worse than missing predictions.
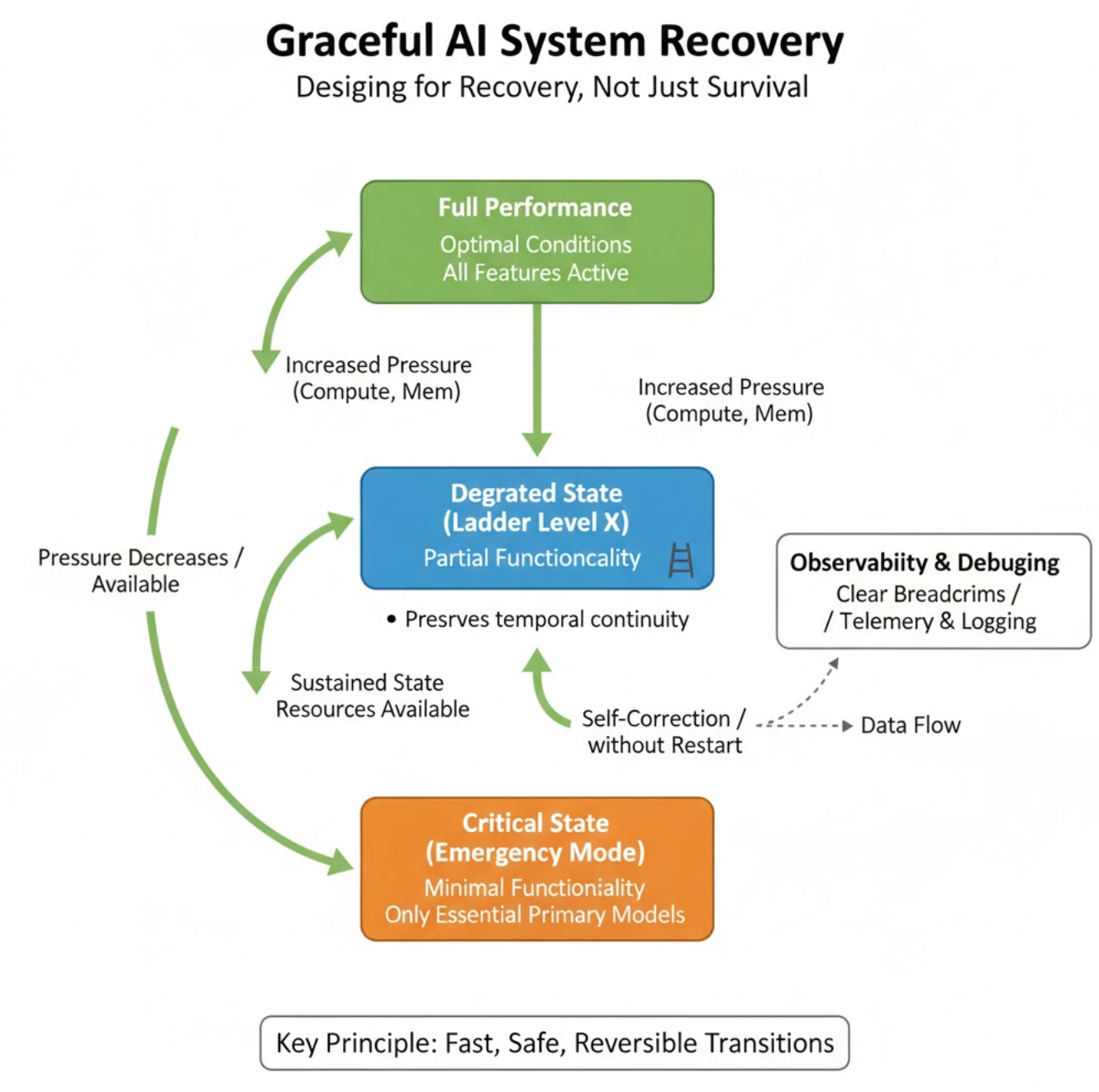
Designing for Recovery, Not Just Survival
Graceful degradation only matters if recovery is fast and safe.
Every degraded state must:
- be reversible without restart
- preserve temporal continuity
- leave clear breadcrumbs for debugging
Degradation without observability is just silent failure.
The Bigger Lesson
Most edge AI systems fail not because models are weak — but because systems pretend resources are infinite.
Graceful degradation forces honesty.
It acknowledges that:
- compute is finite
- memory is shared
- sensors never wait
And when pressure comes, intentional loss beats chaotic collapse.
Takeaways
- Degradation must be explicit and ordered
- Sensors are sacred; models are optional
- Reducing quality along one axis preserves meaning
- Fusion is powerful, but fragile under pressure
- Recovery matters as much as survival
Edge AI doesn’t need to be perfect.
It needs to be predictable.



