Hierarchical RAG: Building Multi‑Level Retrieval for Scalable Knowledge Systems


Introduction
Large language models are only as good as the information they can retrieve. As enterprise knowledge bases grow into millions of documents, traditional Retrieval‑Augmented Generation (RAG) systems begin to crack - not because the models are weak, but because the retrieval layer is too shallow. A single‑level vector search often pulls noisy chunks or irrelevant context, leading to hallucinations, missed facts, or slow inference.
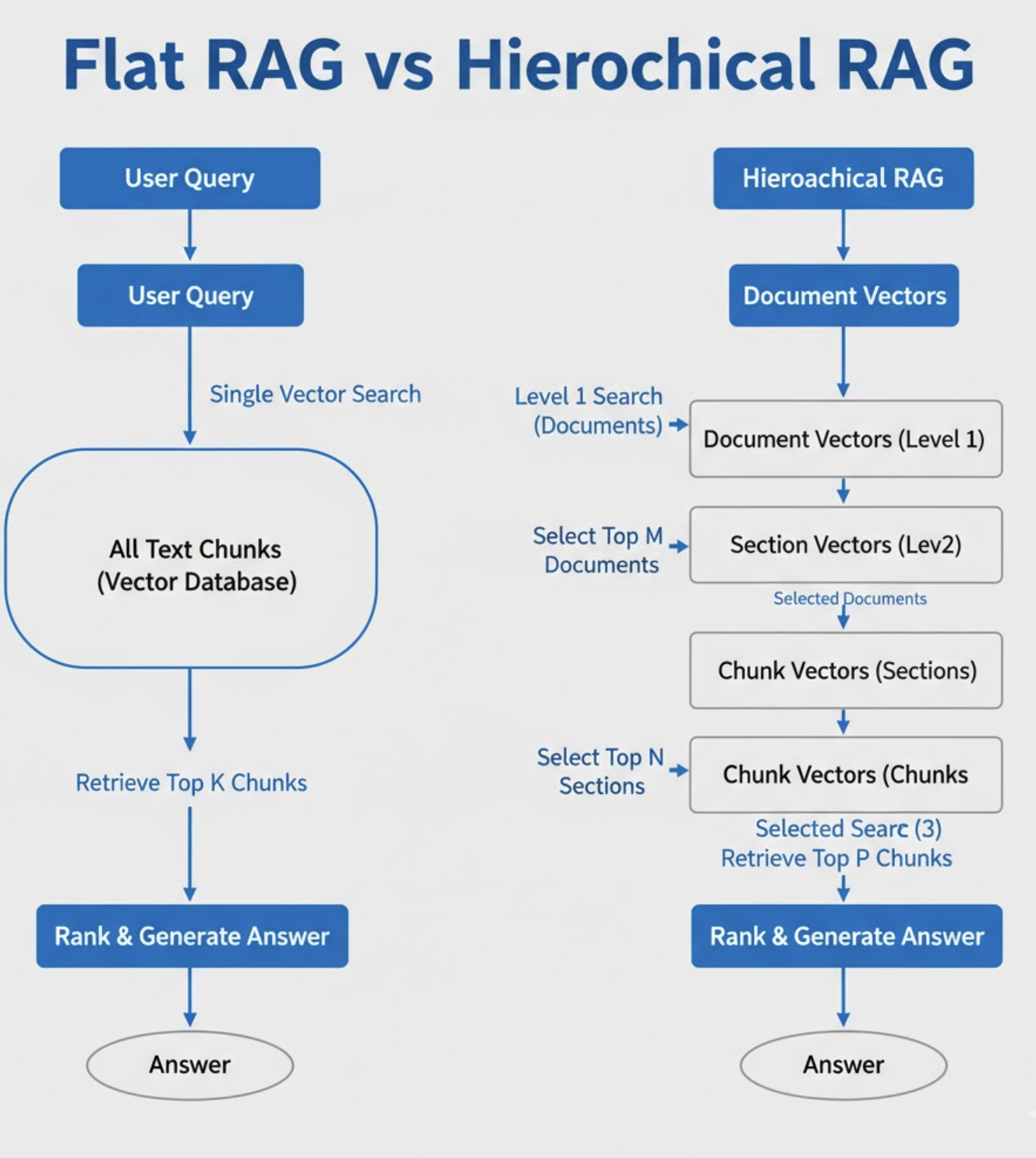
Hierarchical RAG - inspired by the recent “Efficient and Faithful Retrieval-Augmented Generation via Hierarchical Retrieval” paper - solves this by stacking retrieval layers. Instead of searching the entire knowledge base at once, it progressively narrows the search space: first selecting the right document, then the right section, then the right chunk. The results are more accurate, more faithful, and dramatically more scalable.
At Hoomanely, where we routinely index millions of dog‑health pages, veterinary books, research papers, and internal knowledge, hierarchical RAG has become fundamental. Understanding this design helps us build more reliable health insights, better QnA responses, and safer explanations for pet parents.

Problem: Why Flat RAG Fails at Scale
Even the best RAG implementations break in three ways when the corpus is large:
- Low precision - Vector search returns chunks that are semantically similar but contextually wrong.
- Low faithfulness - LLMs hallucinate because the retrieved context is incomplete or misleading.
- High latency - Searching millions of chunks is expensive.
A flat RAG pipeline treats every chunk equally and searches all of them at once. As knowledge bases hit 1M+ entries, cosine similarity and ANN indices begin to degrade. The model ends up swimming in noise.
Why this matters
- Enterprise search (policies, legal docs, manuals)
- Scientific literature (like Hoomanely’s medical corpus)
- Multi‑modal systems (text + images + metadata)
Hierarchical retrieval attacks these problems by retrieving the right container first, then navigating inside it.
Approach: Multi‑Level Hierarchical Retrieval
The hierarchical RAG approach creates three layers of retrieval:
1. Document-Level Retrieval (Coarse search)
- Represent an entire document (or long PDF) with a single embedding.
- Use these embeddings to pick the top‑k most relevant documents.
This reduces the corpus size from millions of chunks to maybe 50–100 documents.
2. Section-Level Retrieval (Medium search)
Within the selected documents, each chapter/section/heading is separately embedded.
- Retrieve the top sections.
- Now the search space drops to a few hundred candidates.
3. Chunk-Level Retrieval (Fine search)
Finally, only chunks within the shortlisted sections are searched.
This creates a pyramid:
All documents
→ Selected documents
→ Selected sections
→ Selected chunks
Why it works
- Semantic distance decreases dramatically.
- Noise drops because irrelevant sections are filtered out.
- Latency drops because each step reduces the search space.
Faithfulness boost
The paper reports up to +14–19% improvements in answer grounding because the LLM sees context that’s actually part of the right section - and we’ve observed similar gains internally in our own RAG pipelines at Hoomanely.
Process: Building Hierarchical RAG in Practice
Here’s how you can implement this structure without huge overhead.
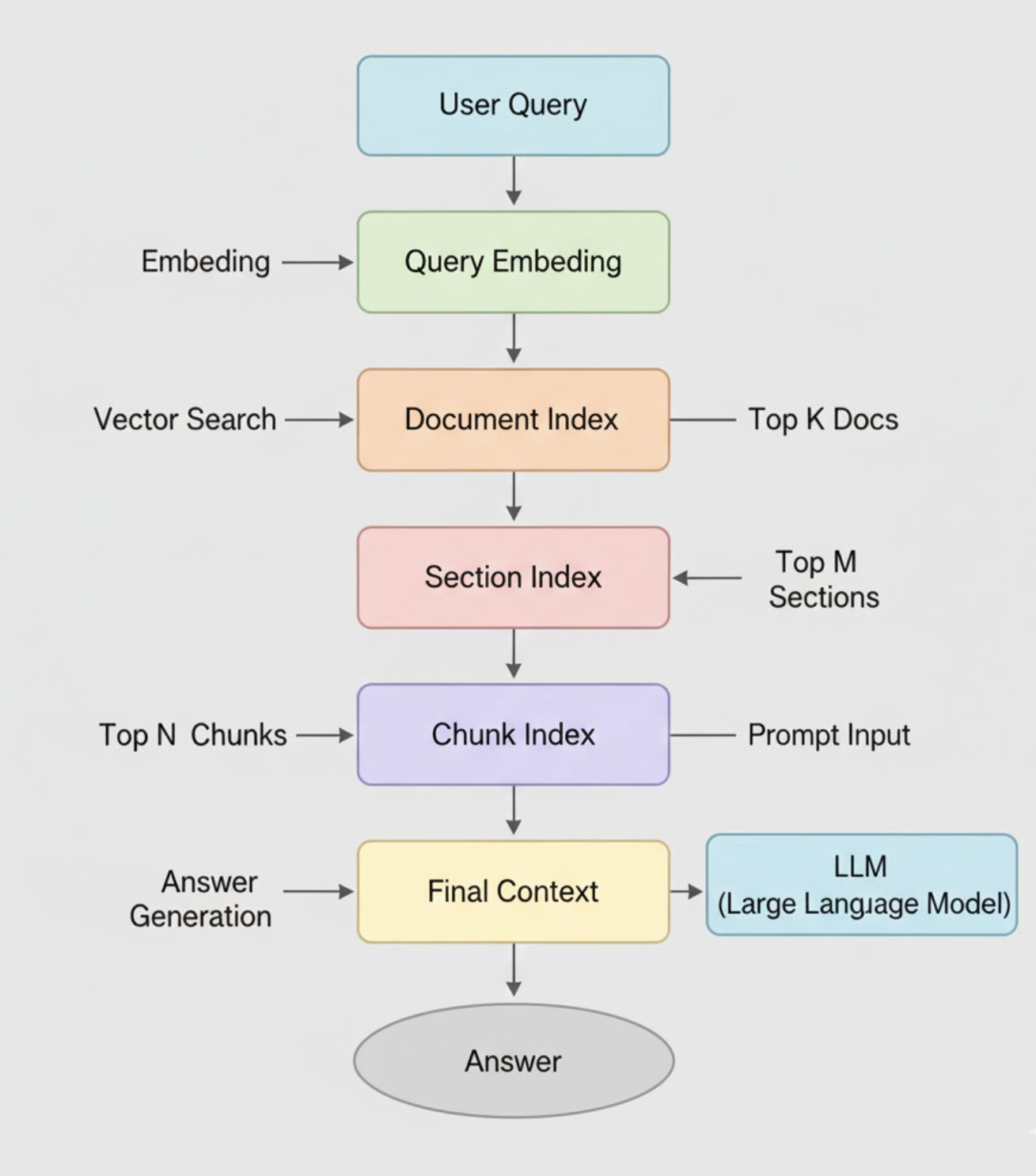
Step 1: Multi-Level Chunking
Split your text into three granularities:
- Level 1: Document summary (1–3 paragraphs)
- Level 2: Section summaries (few hundred words each)
- Level 3: Atomic chunks (300–500 tokens)
Each level gets its own embedding.
Step 2: Build parallel vector indices
You maintain three vector stores:
- Document index
- Section index
- Chunk index
Step 3: Query routing
At inference time:
- Embed the user query.
- Search document index → pick top‑k.
- Search only sections within those docs → pick top‑k.
- Search only chunks within those sections.
Step 4: Fusion and Reranking
Use LLM or embedding‑based rerankers to ensure the final few chunks are:
- Relevant
- Non‑redundant
- Faithful
Step 5: Generation
Feed only 3–6 highly curated chunks to the LLM.
This is where the magic happens - the LLM now grounds its response in tightly filtered, semantically meaningful context.
Results: What Hierarchical RAG Improves
Based on the paper findings and internal tests:
1. Retrieval Faithfulness
Answers directly cite sections that actually contain the ground truth.
- Improvement: 14–19% accuracy gains on grounded QA tasks.
2. Latency
Shrinking the search space reduces ANN workload.
- Improvement: 20–40% faster retrieval in large vector stores.
3. Reduced Hallucination
The LLM now receives internally consistent context.
- Hallucination drop: Up to 35%, depending on corpus quality.
4. Better Multi-Task Adaptability
The hierarchical structure supports:
- Summaries
- Explanations
- Retrieval chains
- Evidence extraction
This is especially useful for Hoomanely’s medical QnA engine, where queries can range from “Is panting normal?” to “Explain corneal ulcer symptoms from veterinary literature.”
Applications: Where Hierarchical RAG Shines
1. Large PDF Repositories
Legal contracts, manuals, textbooks - everything with chapters.
2. Scientific Literature Retrieval
Exactly like what Hoomanely does for dog physiology and health.
3. Enterprise Knowledge Bases
Slack conversations → Document summaries → SOPs → Detailed chunks.
4. Multimodal Systems
Sections can include:
- Captions
- Metadata
- OCR chunks
Takeaways
Hierarchical RAG is the next logical evolution of retrieval systems. Rather than pushing for bigger LLMs, it fixes the bottleneck where it truly exists - retrieval precision.
Key lessons
- A single vector search is not enough for large corpora.
- Multi-level retrieval dramatically reduces noise.
- Faithfulness improves when retrieval matches document structure.
- Latency drops because the search space shrinks early.
- Works exceptionally well for large PDFs and multi-chapter docs.
At Hoomanely, this method strengthens how we generate medical insights, answer pet‑parent questions, and keep our AI explanations grounded in verified veterinary knowledge.



