High-Frequency RAG: Designing Retrieval Pipelines That Survive User-Interactive Latency Budgets

Interactive AI experiences are different from traditional RAG pipelines. They exist inside tight user-facing latency boundaries where even a 300–500 ms delay can change how users feel about the system. A chat interface that responds instantly feels intelligent; one that hesitates feels broken. When retrieval sits on the hot path of every user interaction, the system must guarantee predictable speed—not just occasional speed.
Real-time AI features such as conversational assistance and insight lookups depend on near-instant retrieval. Users may ask follow-up questions, request interpretations of device data, or navigate multi-step flows in rapid bursts. The retrieval engine must keep up regardless of index load, query complexity, or backend fluctuations.
High-Frequency RAG is the architectural pattern built specifically for this reality. It focuses on deterministic latency, adaptive retrieval strategies, fallback logic, and strong observability. Rather than optimizing purely for semantic precision, it optimizes for consistency under real-world constraints. This blog dives into how such a pipeline is designed—and why modern AI applications need it.
Why Typical RAG Architectures Struggle When Users Are Waiting
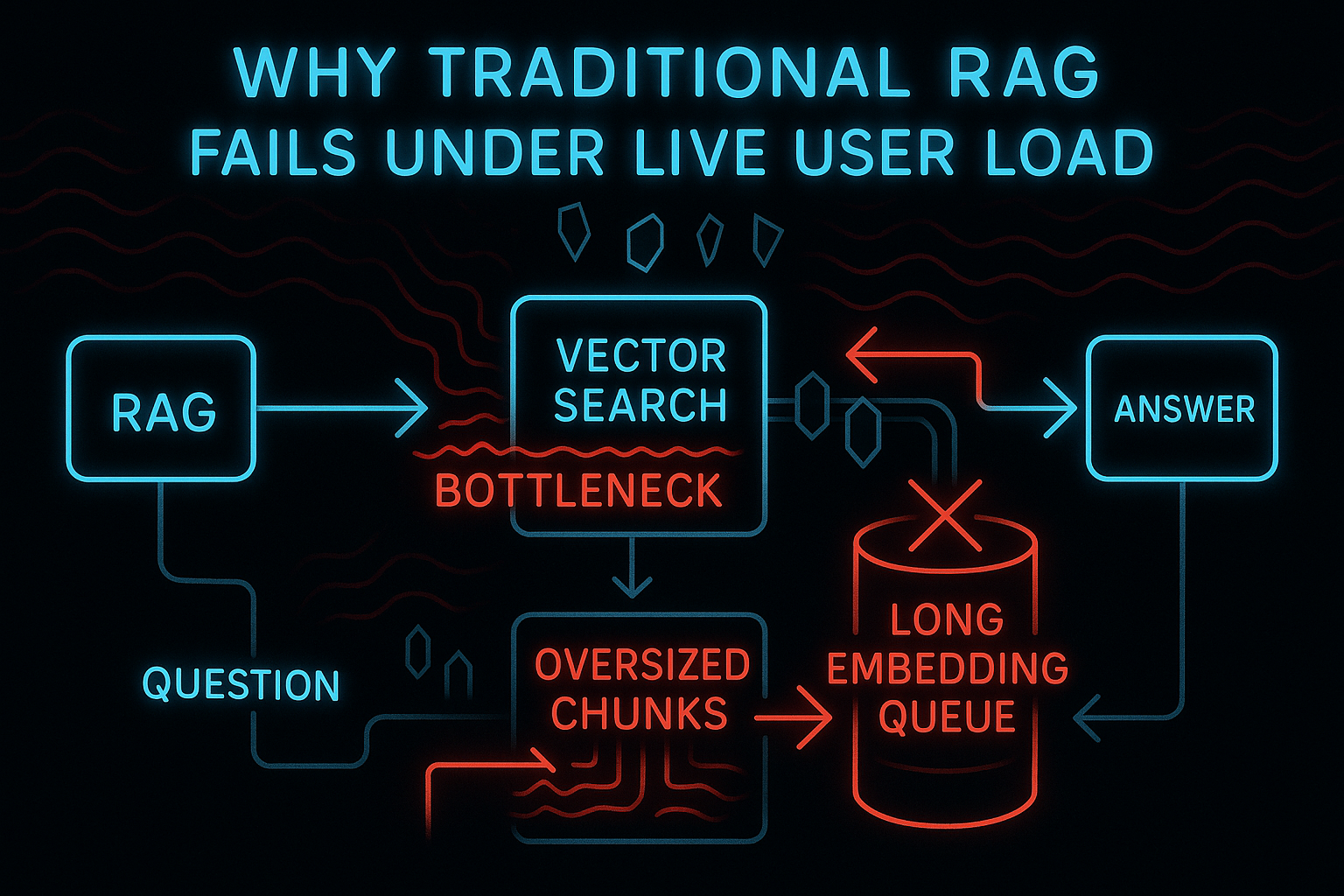
Most RAG systems were never designed for live interactive workloads. They assume queries can take hundreds of milliseconds or more, that the vector index will always be healthy, and that the model can wait for retrieval to finish. But real-world conditions break those assumptions.
- Sparse retrieval layers may spike in latency during cluster rebalancing.
- Vector queries fluctuate depending on shard temperature, load, and parallel traffic.
- Embedding generation may block if the model is occupied or scaling is insufficient.
- Chunking strategies often retrieve too much text, creating unnecessary I/O.
- Pipelines run serially instead of concurrently, amplifying tail latency.
The problem isn’t that retrieval is slow—it’s that it is inconsistent. A system that returns in 80 ms one moment and 420 ms the next creates a visible UX hiccup. In conversational AI, that inconsistency becomes the user’s emotional reality.
To solve this, retrieval can't behave like an academic search pipeline. It must behave like a real-time system with deadlines, fallbacks, and adaptive decision-making.
Multi-Stage Retrieval Flow
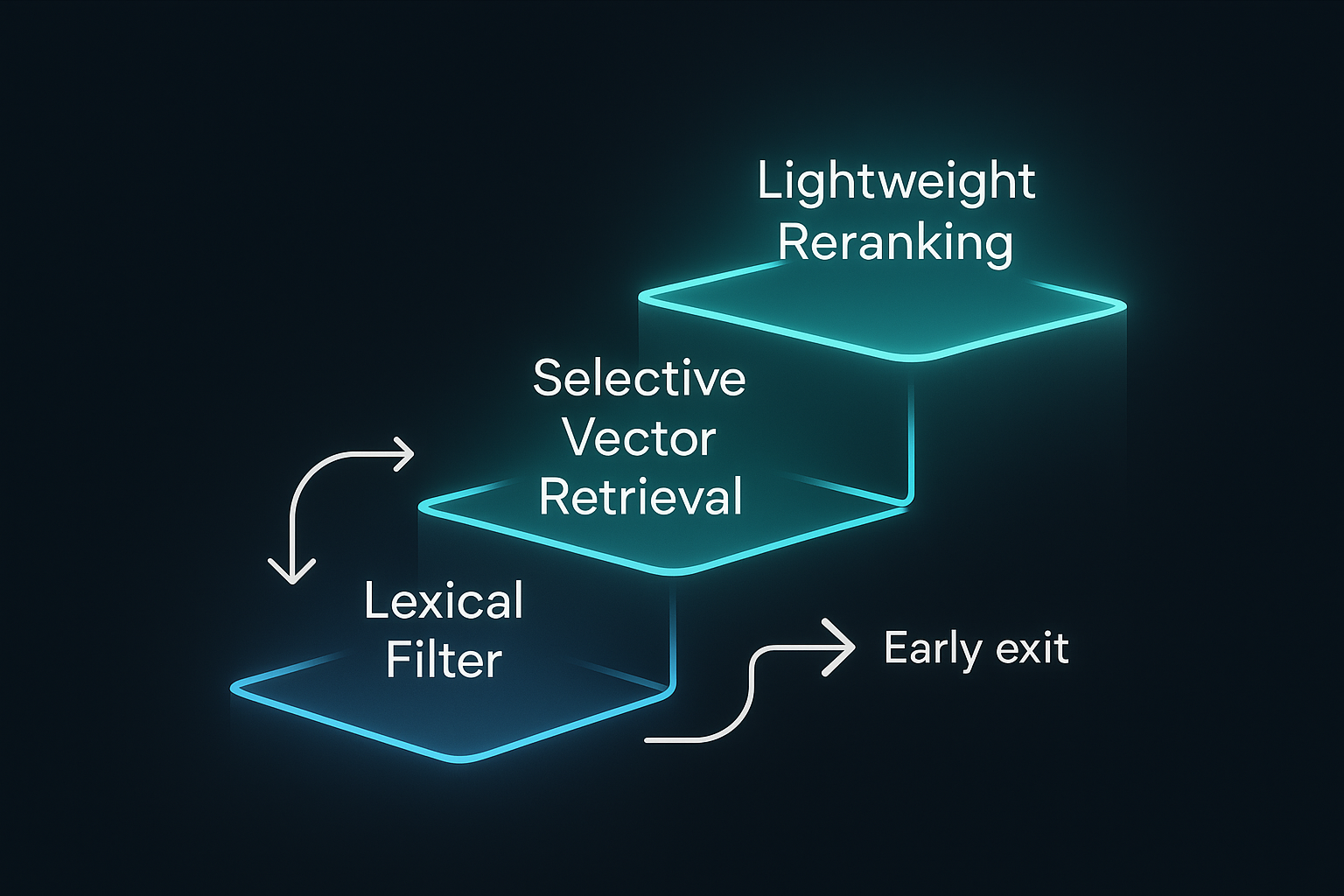
High-Frequency RAG does not rely on heavy vector search alone. Instead, retrieval begins with fast, lightweight operations and escalates only when necessary.
Instead of a specific sparse algorithm, the pipeline starts with a lexical pre-filter, a low-cost mechanism based on keyword extraction, metadata fields, or document signatures. These operations often complete in just a few milliseconds and serve as an efficient way to narrow the candidate set before any semantic operations begin.
Once the candidate set is created, a selective vector search may run on this smaller pool rather than across the entire index. This combination avoids global vector search, keeps traffic localized, and dramatically reduces latency variance. If the query appears straightforward or if the lexical signals already produce strong candidates, deeper semantic search may be skipped entirely.
This multi-stage strategy has a clear purpose: only escalate computation when the early stages indicate it is necessary.
At Hoomanely, this approach ensures that everyday conversational and insight queries remain fast and consistent, even when the index is receiving updates or when vector nodes are under high load.
Parallel Retrieval With Early Cancellation
While multi-stage retrieval gives structure, real-time workloads require more resilience. Retrieval paths must run concurrently wherever possible, because waiting for a single path to finish introduces unpredictable variance.
High-Frequency RAG launches multiple retrieval strategies at once—lexical filters, selective vector lookups, metadata-based hits, recent session context—and continuously monitors which one returns a relevant result first. As soon as the pipeline has enough context, the remaining operations are canceled.
This approach provides a safety net against unexpected slowdowns. If vector search stalls for a moment, lexical filtering still completes quickly. If lexical results are weak, vector retrieval fills the gap. Parallelism ensures the system uses whichever path proves fastest for that specific request.
done, pending = await wait(tasks, return_when=FIRST_ACCEPTABLE)
for task in pending:
task.cancel()
It shows how the system avoids waiting unnecessarily and how early cancellation stabilizes latency.
Adaptive Chunking: Adjusting Context Granularity Dynamically
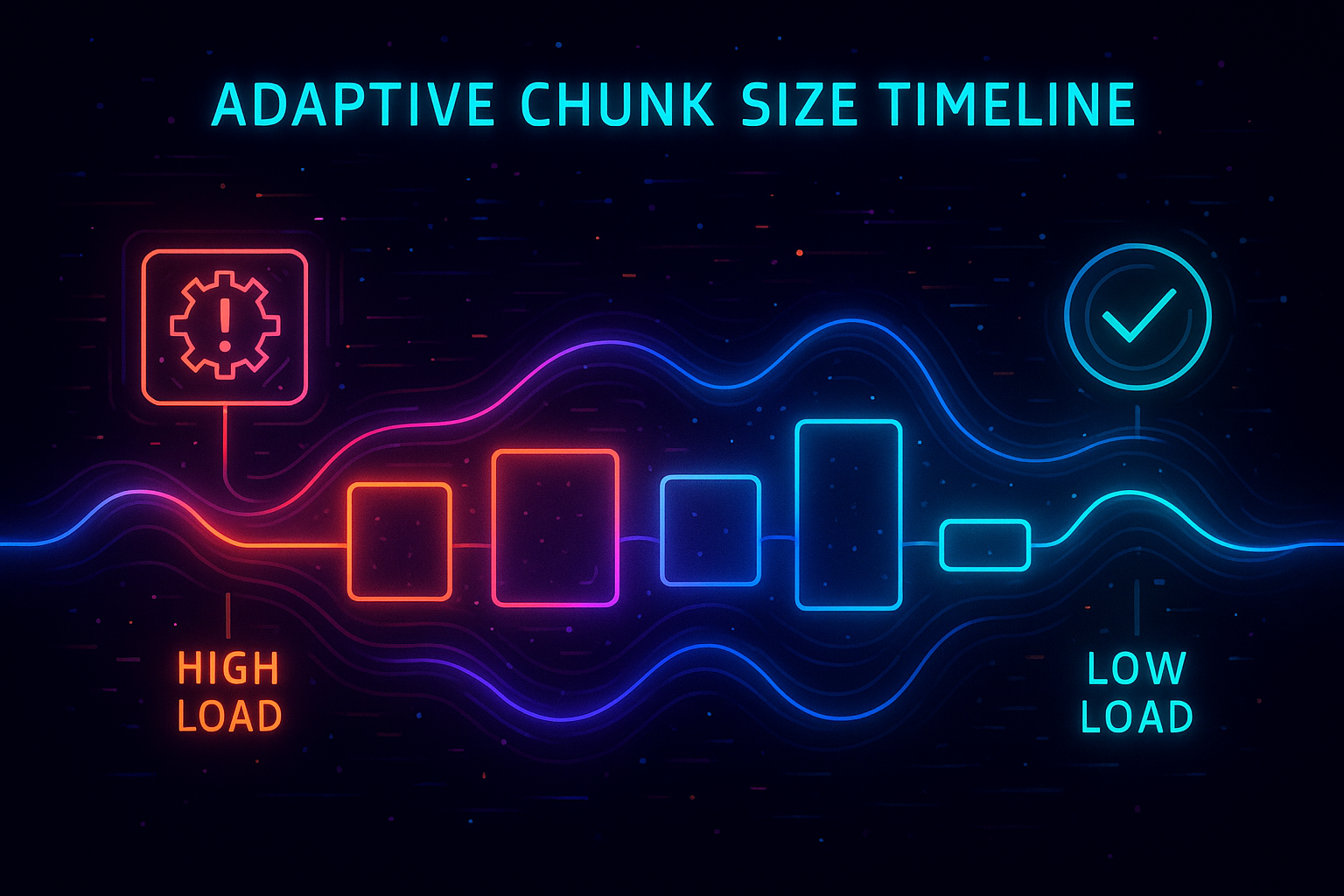
Semantic chunking is often static in RAG design, but static chunking is ill-suited to user-interactive environments. When the system is under load, large chunks become a bottleneck. They increase I/O, inflate memory usage, and complicate scoring. When load is low, however, larger chunks help maintain narrative coherence and semantic richness.
High-Frequency RAG uses adaptive chunking—a mechanism that adjusts the size and number of chunks based on system conditions, query type, and recent latency patterns. If the system detects rising tail latencies or cluster pressure, it trims chunk sizes or limits the number of chunks per document. When the system is idle, chunk sizes may expand automatically.
The chunking strategy may also adjust based on user behavior. If a user is in a multi-turn conversation, larger context blocks simplify the LLM’s reasoning. If the query is crisp and specific, smaller chunks are more efficient.
This adaptability keeps retrieval responsive without sacrificing contextual richness.
Deadlines as a First-Class Retrieval Primitive
A key insight of High-Frequency RAG is that latency budgets cannot be informal expectations—they must be binding constraints. Retrieval must complete on time, even if doing so means skipping expensive operations or returning partial results. Every stage has a defined time window:
- A narrow window for lexical filtering
- A moderate window for selective vector operations
- A limited window for reranking
- A strict cap for full retrieval execution
If a stage doesn’t complete before its window expires, it is terminated and the pipeline moves on. This protects the overall time budget and ensures that users experience consistent responsiveness.
The goal is not to find the perfect set of documents; the goal is to find a sufficient set of documents within the UX threshold.
This is one of the reasons Hoomanely’s interactive features maintain speed even when backend systems experience temporary slowdowns or uneven load distribution.
Fallback Modes: Returning “Something Good Enough” Is Better Than Timing Out
Fallback logic is often overlooked in RAG pipelines. High-Frequency RAG treats fallback as a core design component. If a deeper semantic search cannot complete in its allotted time, the system returns what it already has—perhaps just lexical hits, cached context, or metadata-derived results.
Fallbacks create a continuum of results rather than a binary success/failure outcome. Even a shallow context is preferable to a timeout. The LLM can still respond intelligently using narrative templates, cached user history, or previously assembled background information.
This type of safety net is crucial for real-world UX. Users rarely notice when retrieval uses a fallback mechanism; they immediately notice when the system pauses for too long.
Context Caching: The Secret to Millisecond Retrieval
Much of user interaction consists of related queries. Users follow threads, seek clarifications, or request variations of previous answers. High-Frequency RAG exploits this by caching partial retrieval outputs, frequently referenced chunks, and session-specific knowledge bundles.
Caching drastically shortens the retrieval path for repeated or similar queries. Instead of re-running lexical or vector search, the pipeline simply reassembles context from cached memory. This often removes tens of milliseconds from request latency and lowers pressure on vector indices.
At Hoomanely, caching helps conversational AI and insight flows feel instant, especially when users revisit recently discussed contexts.

Observability: The Only Way to Make High-Frequency RAG Work
All adaptive and deadline-bound behavior depends on strong observability. High-Frequency RAG logs per-stage latency, cache hits, fallback causes, retrieval path selection, vector score patterns, and token usage. It tracks tail latency amplification and correlation with system load.
These insights reveal when selective vector queries are becoming too slow, when lexical filtering is too permissive, when chunk sizes should shift, or when fallback frequency is rising. Observability transforms the pipeline from a static mechanism into a continuously evolving system.
Without it, tuning becomes guesswork and inconsistent experiences appear unpredictably.
What High-Frequency RAG Looks Like in Practice
A user might ask: “Why does today’s feeding pattern look unusual?”
The system immediately runs a lexical filter on related logs and metadata, gathering candidates within a few milliseconds. A selective vector lookup and a reranking task run in parallel. If the lexical candidates are already strong, the pipeline stops early and cancels the ongoing vector search.
Chunk sizes are trimmed to meet token limits. The final assembled context reaches the LLM quickly, and the response arrives in well under a second. Even if the vector index were saturated, the fallback strategy would preserve the experience.
High-Frequency RAG ensures that the user never feels the retrieval complexity—only the responsiveness.
Takeaways
High-Frequency RAG shifts retrieval from “find the best documents” to “find good documents consistently fast.” Its design patterns emphasize:
- Deterministic time-bounded behavior
- Parallel retrieval with early cancellation
- Adaptive chunking based on load
- Graceful fallback modes
- Context caching for repeated queries
- Deep observability for continuous tuning
- Predictability as the primary UX outcome



