How BERT Learned Pet Questions (And Got Really Good at It)


Introduction: Why We Needed a Question Classifier
At Hoomanely, we receive thousands of pet‑related questions across health, behaviour, grooming, food, training and more. These queries help us understand what pet parents care about-and where our product needs to improve. But manually reviewing every question is slow, inconsistent, and impossible to scale.
To fix this, we built an internal BERT‑based question classifier capable of instantly tagging incoming questions into well‑defined categories. The foundation of this model came from 4,401 questions, auto‑labelled with GPT‑5 and then manually verified by our team for high‑confidence training data.
The Dataset: 4,401 Human‑Reviewed Questions
We first asked GPT‑5 to label thousands of historical questions into seven categories. Then our team manually audited and corrected them to remove drift or misclassification.
Final dataset distribution:
| Category | Count |
|---|---|
| Activity | 504 |
| Behaviour | 608 |
| Food | 697 |
| General | 1130 |
| Grooming | 208 |
| Health | 1074 |
| Training | 180 |
| Total | 4401 |
This balanced‑enough distribution (with expected real‑world skew toward Health and General) became the backbone of our fine‑tuned classifier.

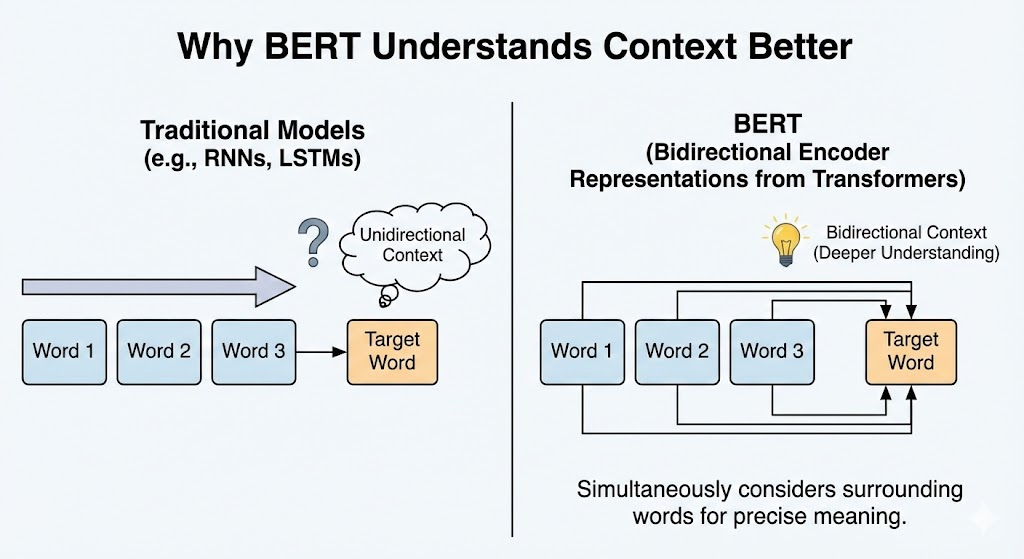
Why BERT for Classification?
BERT is powerful for this task because:
- It understands context, not just keywords
- It handles short, noisy user queries extremely well
- Fine‑tuning requires relatively little data compared to training from scratch
- Lightweight variants (DistilBERT, MiniLM) perform well enough for real‑time workloads
Instead of hand‑crafted rules or TF‑IDF baselines, BERT learns semantic patterns in questions—like understanding that:
- “My dog keeps shaking its head” → Health
- “How do I stop leash pulling?” → Training / Behaviour
- “Can puppies eat curd?” → Food
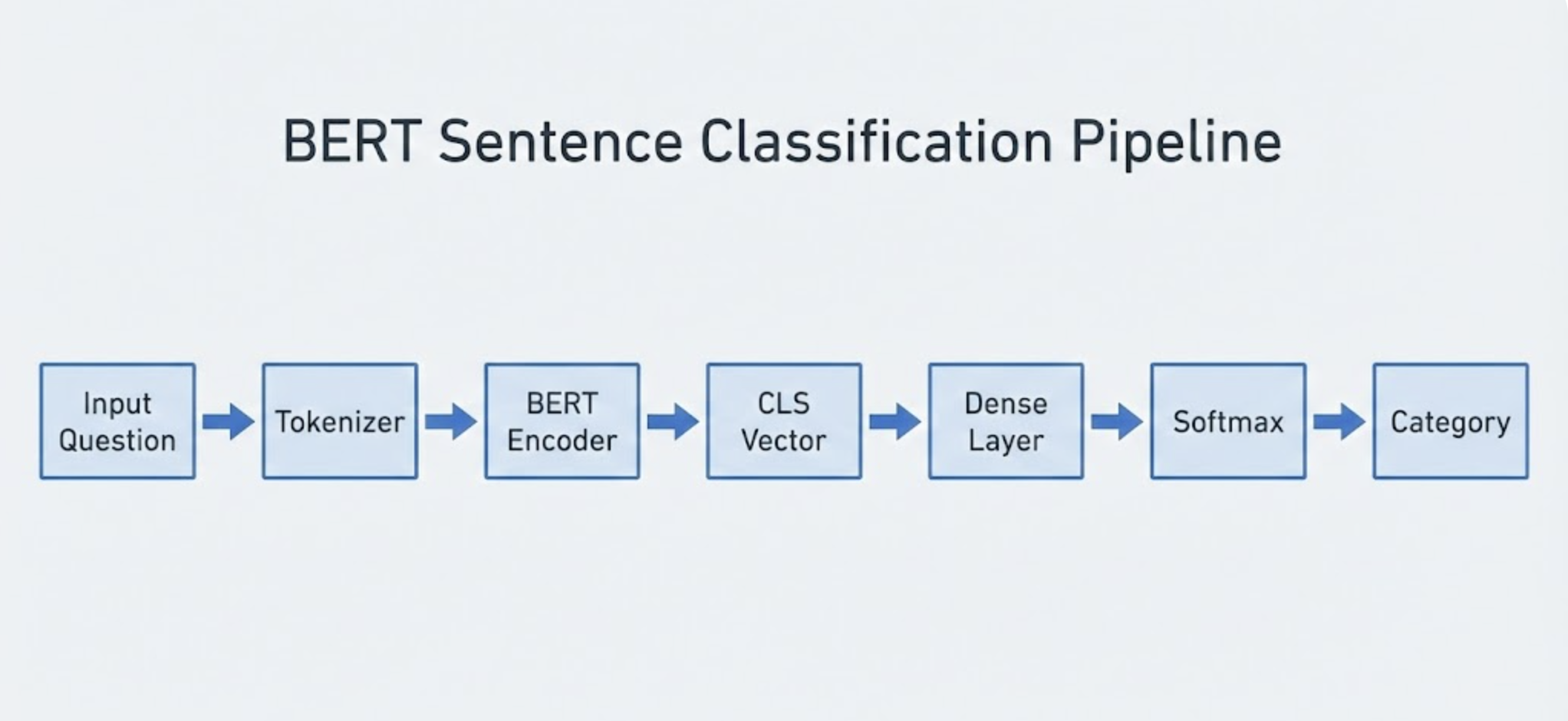
How BERT Classification Works (Conceptually)
Here's the simplified flow:
- Tokenization – Convert text to WordPiece tokens
- Embedding + Transformer Layers – BERT encodes contextual meaning
- [CLS] Vector – The special CLS token becomes a summary of the entire sentence
- Classification Head – A small feed‑forward network maps CLS → category
Input Question → Tokenizer → BERT Encoder → CLS Vector → Dense Layer → Softmax → Category
Building the Training Pipeline
Step 1 - Clean & Standardize the Dataset
- Remove duplicates
- Lowercase and strip punctuation only where necessary
- Convert categories into numeric labels
- Train‑validation split of ~85/15 (stratified)
Step 2 - Model Choice
We used a compact, fast variant of BERT:
- base model: DistilBERT / MiniLM
- head: 1–2 linear layers with dropout
- optimizer: AdamW
- loss: CrossEntropy
- max length: 64 tokens (more than enough for questions)
Step 3 - Fine‑Tuning
A lightweight training loop:
- batch size 16–32
- 3–5 epochs
- learning rate warmup + decay
- early stopping
We didn’t need huge epochs-BERT converges quickly when the labels are clean.

Visual: End‑to‑End Pipeline
Historical Questions ──► GPT‑5 Labeling ──► Human Audit
│
▼
Clean Labeled Dataset
│
▼
Fine‑tune BERT Model
│
▼
Real‑Time Question Categorization Service
How We Use This Classifier at Hoomanely
Once deployed, the classifier became a central part of our internal analytics.
1. Understanding User Needs at Scale
We can now see which domains users struggle with most-health, food, training, etc.-in real time.
2. Prioritising Content & Product Features
If the classifier detects a rising spike in “Grooming” queries, our content and product teams know exactly what to address.
3. Routing Questions Inside Our AI Stack
Certain pipelines benefit from knowing the category:
- Health → fetch from clinical RAG datasets
- Behaviour → route to behavioural models
- General → lightweight FAQs
4. Improving Long‑Term Data Quality
With consistent classification, historical analytics becomes far more trustworthy.
Learnings & Takeaways
- GPT‑5 labels are great, but human review is essential. Even minor noise can hurt fine‑tuning.
- Even 4–5k clean examples are enough for a high‑accuracy BERT classifier.
- Smaller BERT variants perform extremely well for short queries.
- Consistent taxonomy is more important than model architecture.
Final Thoughts
This project strengthened Hoomanely’s internal analytics and made our understanding of user queries data‑driven rather than guesswork. With reliable automatic categorization, we can now build better experiences-more relevant answers, more accurate routing, and sharper product decisions.
As we scale to tens of thousands of questions, the classifier will continue to evolve, incorporating new categories and richer signals.
If you’re building something similar, start with clean labels, choose a small BERT variant, and fine‑tune just enough-not more.



