How Do You Build Edge ML When You Don’t Have Labels Yet?


Introduction
Building machine learning systems for the edge sounds exciting—until you realize that most real-world edge problems begin with a simple, uncomfortable truth: you don’t have labeled data. Not enough of it. Not the right kind. And certainly not data that reflects the messy environments your devices will operate in.
At Hoomanely, we build edge-first intelligence for pet health—processing audio, vision, and sensor data directly on devices like smart feeding bowls. Early on, we faced a classic paradox: to train robust edge models, we needed real-world data; to collect real-world data, we needed models that already worked. Manual labeling at scale wasn’t feasible, and deploying heavy foundation models directly on-device wasn’t an option either.
This post walks through a practical, production-tested approach for bootstrapping edge ML systems when labeled data doesn’t exist yet, using a staged teacher–student pipeline that gradually distills large models into efficient edge-ready ones.
The Problem: Edge ML Without Labels
Edge ML systems live under strict constraints:
- Limited compute and memory
- Always-on inference requirements
- Highly variable real-world conditions
- Strong privacy expectations
But the biggest challenge often comes earlier—data.
For tasks like detecting dog eating or drinking sounds at a feeding bowl, public datasets are either too generic or completely misaligned with the acoustic reality of homes. Audio recorded inches from stainless-steel bowls sounds nothing like curated benchmark datasets.
Manually labeling thousands of hours of audio wasn’t scalable. Worse, early data is noisy by definition—models fail, environments vary, and user behavior is unpredictable. We needed a way to learn from the chaos without human labeling becoming the bottleneck.
The Approach: Teacher → Adapter → Edge Student
Instead of training a small edge model directly, we adopted a progressive distillation strategy:
- Use a large foundation model to generate weak labels
- Refine those labels using a domain-adapted intermediate model
- Train a compact edge-native model on the refined dataset
This approach treats large models not as deployment targets, but as temporary teachers—tools for accelerating dataset creation.
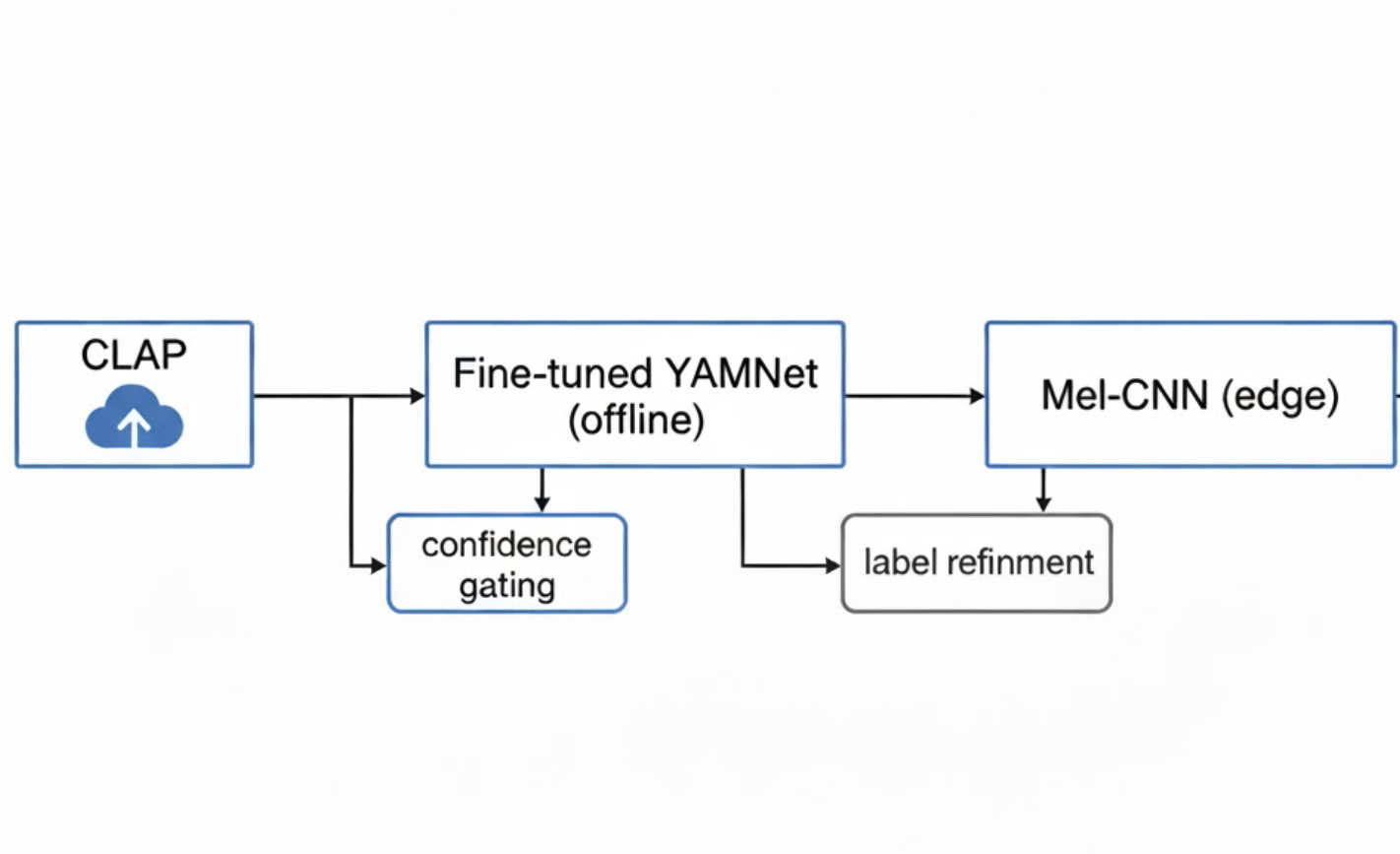
Stage 1: Foundation Models as Label Generators
We began with CLAP, an audio–text foundation model capable of semantic matching between sounds and natural language queries.
Instead of asking CLAP to produce hard class predictions, we used it as a semantic filter:
- Input: short audio clips
- Queries: “dog eating kibble”, “dog drinking water”, “dog chewing”, “background noise”
- Output: similarity scores for each query
Only predictions above a high confidence threshold were accepted. Everything else was marked as unknown.
This step gave us three things:
- A rough initial label distribution
- An early sense of class imbalance
- A fast way to discard irrelevant audio
Importantly, CLAP was never intended to be accurate enough for deployment. Its role was to turn unlabeled audio into a weakly labeled dataset.
Stage 2: Refining Labels with a Domain Adapter
While CLAP is powerful, it’s also heavy and expensive to run at scale. More importantly, it lacks inductive bias for our specific acoustic environment.
This is where YAMNet came in—not as a transformer competitor, but as a generalist CNN adapter.
We fine-tuned YAMNet on:
- CLAP-labeled samples (high confidence only)
- A small, manually verified validation set
- Augmented audio reflecting bowl acoustics and indoor noise
The goal wasn’t perfect accuracy. It was consistency.
YAMNet helped us:
- Smooth over CLAP’s semantic noise
- Enforce clearer class boundaries
- Re-label large volumes of data more efficiently
At this stage, we had a dataset that finally resembled what our edge devices would hear in the wild.
Stage 3: Training the Edge-Native Student Model
With enough refined data in hand, we trained a Mel-spectrogram-based CNN from scratch.
Why not deploy YAMNet?
Because edge deployment isn’t about accuracy alone. It’s about:
- Predictable latency
- Low memory footprint
- Thermal stability
- Deterministic behavior
Our Mel-CNN was trained using:
- Refined YAMNet labels
- Device-specific augmentations
- Optional knowledge distillation (matching YAMNet logits)
The result was a model that:
- Runs in real time on low-power CPUs
- Consumes a fraction of the memory
- Performs better on our task than its teachers
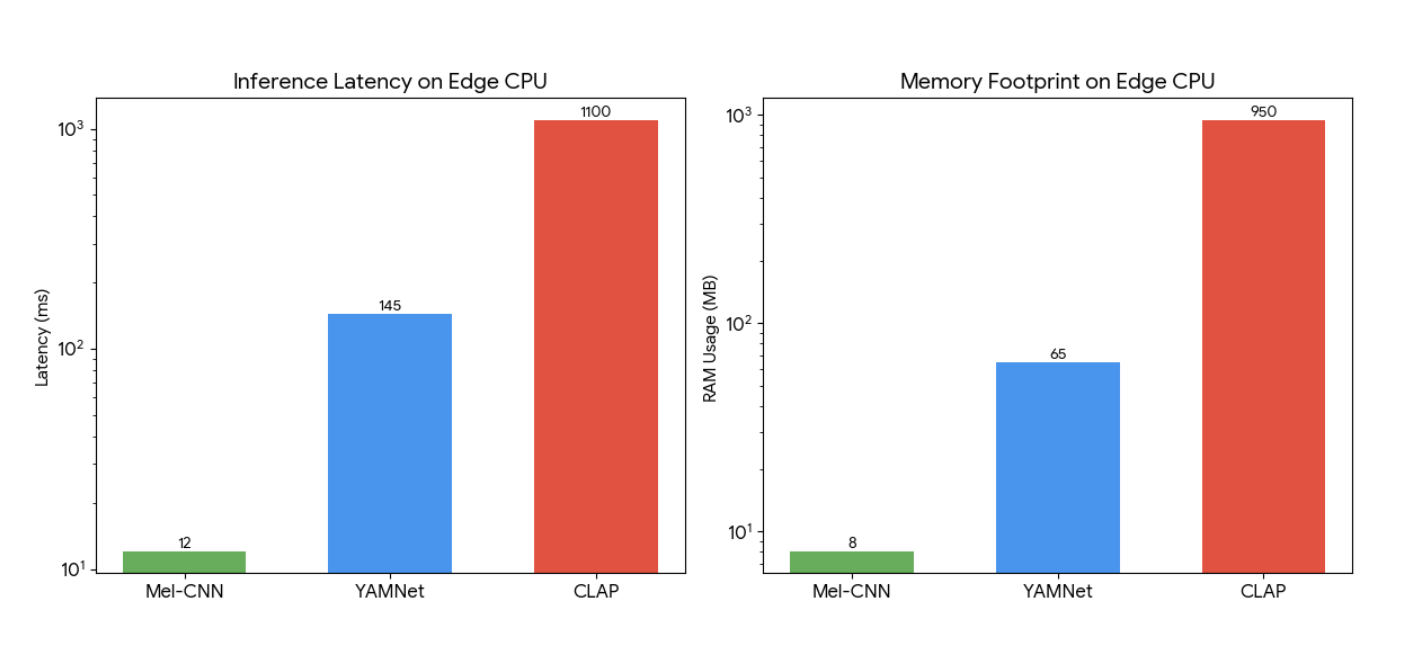
Results: What Actually Improved
This staged approach delivered clear, measurable benefits:
- Lower labeling cost: No large-scale manual annotation
- Faster iteration: Models improved as data improved
- Better edge performance: Sub-100ms inference latency
- Higher precision: Fewer false positives in real homes
Most importantly, it allowed us to deploy early, learn from reality, and improve continuously—without waiting for a “perfect” dataset.
Why This Matters for Edge ML
Foundation models are changing how ML systems are built—but not always how they’re deployed.
For edge ML, their biggest impact may be upstream:
- Accelerating dataset creation
- Reducing human labeling effort
- Enabling rapid domain exploration
The final deployed model doesn’t need to be big. It needs to be reliable.



