How OCR Quality Shapes RAG Accuracy: A Cloud Comparison


When engineers talk about Retrieval-Augmented Generation (RAG), the conversation often starts at embeddings, chunking, or vector databases. But the uncomfortable truth is this: RAG quality is bottlenecked by OCR quality. If the extracted text is noisy, fragmented, or wrongly segmented, no embedding model - no matter how powerful - can recover the lost semantics.
In real-world pipelines, especially those involving thousands of pages of scientific, legal, or medical documents, OCR becomes the silent foundation of the entire knowledge system. At Hoomanely, where our RAG systems power pet‑health intelligence, we saw this firsthand. Working with books, vet manuals, and long-form PDFs taught us that OCR fidelity directly shapes retrieval precision, hallucination rates, and overall reliability.
This article explores the engineering realities behind OCR → RAG pipelines, comparing Google Document AI, Azure Document Intelligence, and AWS Textract. We ultimately chose Google’s Document AI (Bulk OCR API) - and here is the reasoning engineers should know.
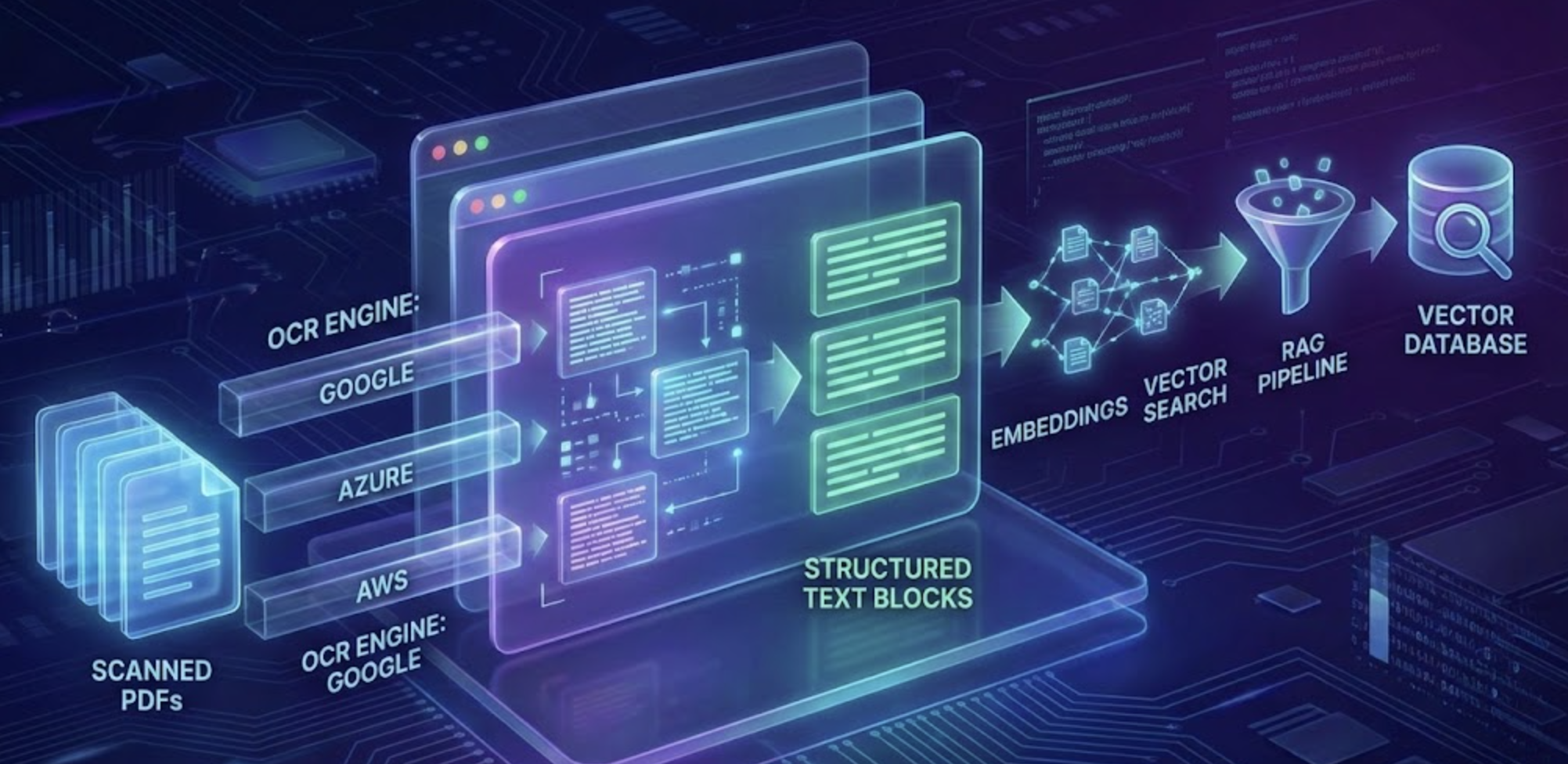
1. Why OCR Quality Makes or Breaks RAG
Before embeddings, chunking, or vector search ever happen, OCR determines:
- What text even exists for the model to embed
- How cleanly sentences are preserved (fewer breaks → better semantic embedding)
- Whether diagrams, tables, and lists survive structurally
- How searchable headings become (critical for hierarchical RAG)
- Whether retrieval pulls the right knowledge or gibberish
A simple rule holds true:
Garbage OCR → Garbage chunks → Garbage embeddings → Garbage answers.
The more complex the PDFs - rotated pages, multi-column layouts, tables, marginal notes - the higher the impact of OCR quality.
2. The Cloud OCR Landscape: Google vs Azure vs AWS
Below is a practical comparison from an engineer's perspective, not a marketing sheet. All three services are strong - but optimized for slightly different philosophies.
Google Document AI (OCR + Layout + Bulk Processor)
Strengths:
- Best-in-class text extraction accuracy for complex PDFs
- Excellent layout reconstruction (hierarchies, blocks, tables)
- Bulk OCR API is extremely fast and scalable
- Native confidence scores for tokens, lines, structures
- Handles handwriting decently
Weaknesses:
- Slightly higher cost for some processors
- Multi-language OCR could be more flexible
Ideal for: large RAG systems, long scientific PDFs, layout-sensitive documents.
Azure Document Intelligence (Form Recognizer)
Strengths:
- Very good form/table extraction
- Strong pretrained fields for structured documents
- Solid accuracy on business PDFs
Weaknesses:
- Struggles with scanned books, older documents
- Bulk processing not as streamlined as Google
Ideal for: enterprise invoices, forms, business workflows - less ideal for book-style RAG.
AWS Textract
Strengths:
- Good character-level OCR
- Native integration with AWS ecosystem
- Clear separation of DetectText, AnalyzeDocument APIs
Weaknesses:
- Over-segmentation issues on complex pages
- Layout blocks frequently mis-ordered in multi-column PDFs
- No true bulk OCR equivalent
Ideal for: AWS-first teams, simple OCR workloads.
3. Why OCR Impacts RAG Accuracy So Strongly
RAG systems depend on consistency. But OCR errors introduce:
- Broken sentences → incorrect embeddings
- Lost headings → weaker retrieval structure
- Jumbled paragraphs → semantic dilution
- Misordered columns → hallucination triggers
- Missed words → wrong answers in downstream LLMs
For embedding models, sentence coherence matters. Even small OCR misreads (e.g., "therm*l" instead of "thermal") distort vector space.
This is why engineers must treat OCR as a core model stage - not a preprocessing step.
4. Architecture: OCR → Processing → RAG
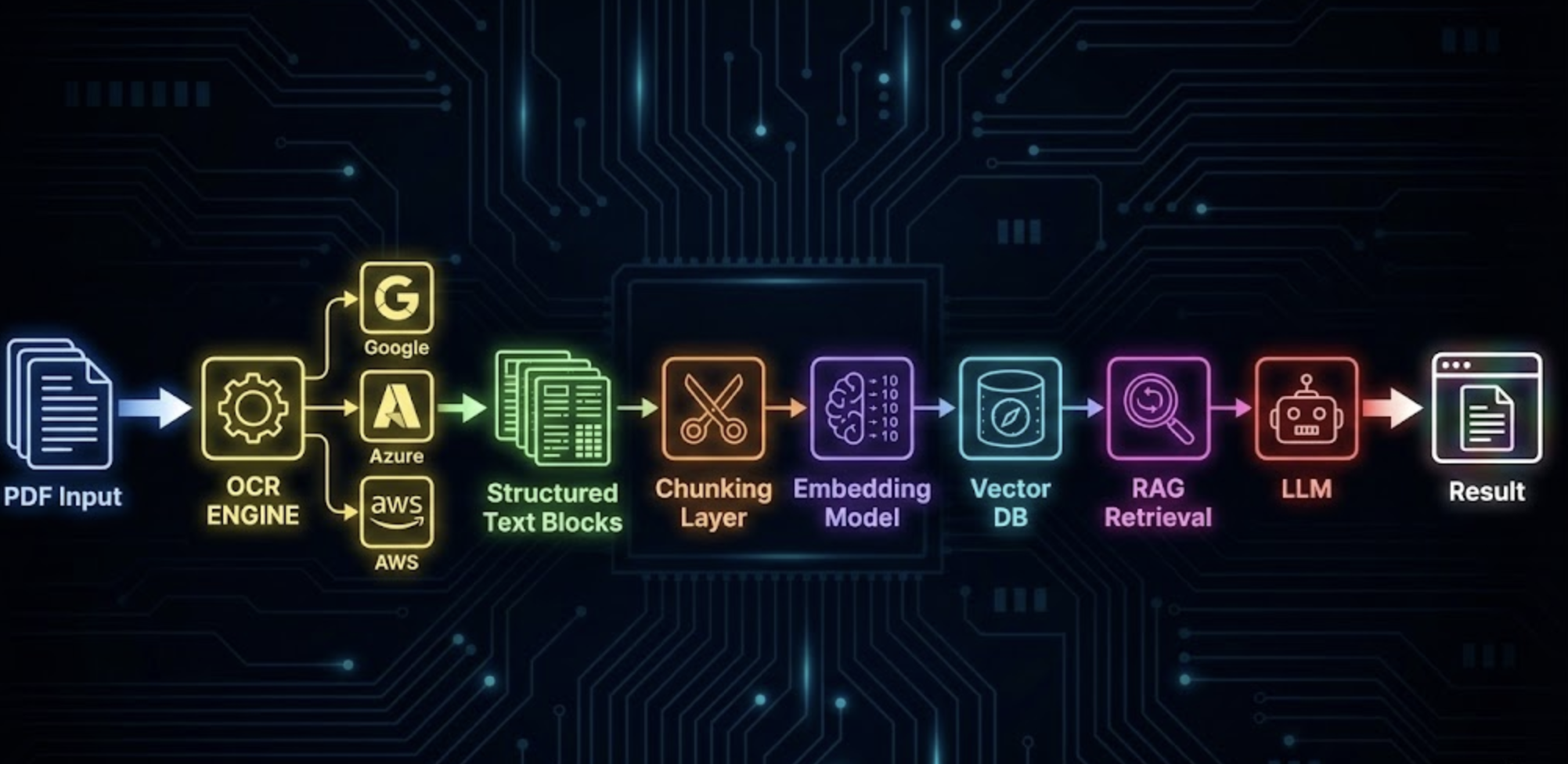
A clean, reliable pipeline looks like this:
- OCR extraction (bulk processor for speed)
- Layout parsing (page → block → line → token)
- Chunking (sentence-aware or layout-aware)
- Metadata enrichment (section titles, page numbers)
- Embedding generation (BAAI BGE, Titan, or ST models)
- Indexing in vector DB (OpenSearch, Pinecone, Weaviate)
- Retrieval + reranking
- LLM synthesis
OCR sits at the front but controls everything downstream.
5. Why We Selected Google Document AI (Bulk OCR)
After running thousands of pages from veterinary books and research material, our observations were clear:
1. Google had the lowest sentence-break error rate
RAG thrives on stable sentence boundaries. Google's layout engine was consistently reliable.
2. Column reconstruction was superior
Azure and AWS often linearized multi-column pages incorrectly.
3. Table extraction was significantly cleaner
This helped preserve dosage tables, ingredient lists, and nutrition charts relevant to pet health.
4. Bulk OCR processing was a game changer
We processed hundreds of pages in minutes - crucial for large datasets.
5. Confidence scoring improved filtering
We dropped low-confidence spans before chunking, boosting retrieval quality.
This is why the Hoomanely internal pipeline adopts Google Document AI for OCR, followed by our own layout-aware chunking and multi-level RAG retrieval.
6. Sample Comparison: OCR Output Fragment
Below is a simplified illustration of how OCR differences impact RAG.
Raw PDF Section Example:
A 2-column page with headings, table, and paragraph text.
- Correct column order
- Accurate table cell grouping
- Preserved headings
Azure
- 90% accurate text but breaks headings incorrectly
- Occasional column merges
AWS
- Over-segmentation into short lines
- Columns flattened into left→right reading order
Implication: Google’s output produces the most coherent embeddings in our testing.
8. How Better OCR Reduces Hallucinations in RAG
LLMs hallucinate when context is:
- missing
- ambiguous
- fragmented
- noisy
Cleaner OCR → clearer chunks → stronger grounding → fewer hallucinations.
We observed measurable reductions in "made-up" nutritional or medical facts once we moved to Google's Bulk OCR.
9. OCR Cost and Throughput Considerations
- Bulk mode: extremely efficient at scale
- Good cost-performance ratio
Azure
- Slightly higher costs for form-heavy extraction
AWS
- More granular pricing but slower for large corpora
For large RAG systems (tens of thousands of pages), throughput matters as much as accuracy.
10. Key Takeaways
- OCR fidelity is the single largest determinant of RAG quality.
- Google Document AI provides the best balance of accuracy, speed, and layout preservation.
- AWS is fine for simpler documents; Azure excels at forms.
- Multi-column scientific PDFs almost always perform best under Google.
- Investing in OCR upfront saves exponential debugging effort later.
- Hoomanely’s internal pipeline uses Google Bulk OCR for this reason.



