How We Built a Noise-Cancellation Dataset Without a Sound Studio


Noise cancellation sounds glamorous - until you try doing it in the real world.
Dog sounds in homes are messy. Fans hum. TV dialogue spills into the mic. Steel bowls clink. A dog sniffs, licks, barks, scratches, and eats… all at the same time. A clean dataset of isolated dog sounds simply doesn’t exist in nature.
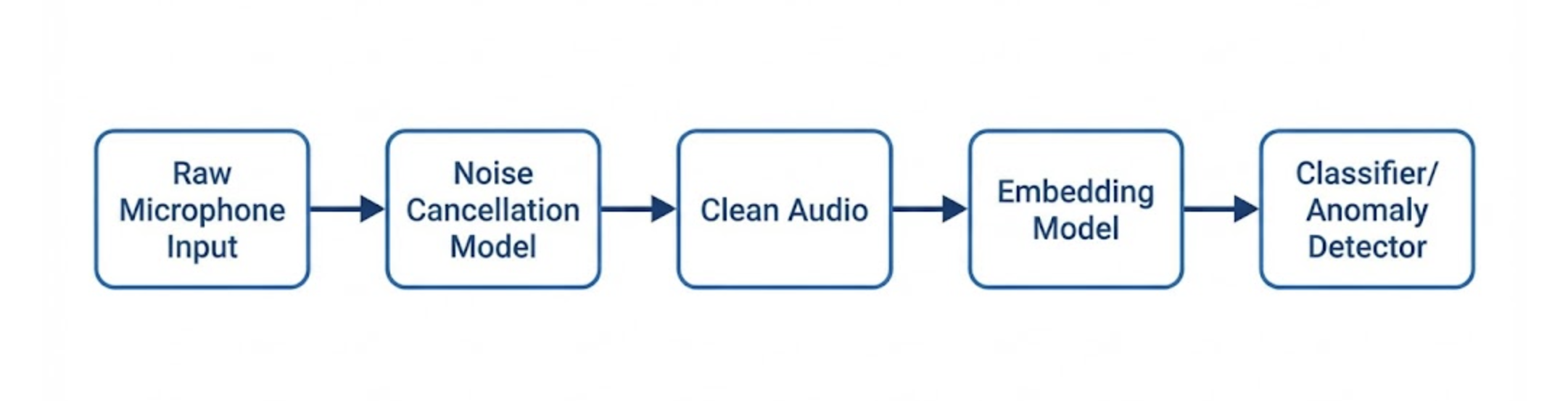
At Hoomanely, where we build pet-centric AI systems, we needed a strong noise-cancellation model to clean the raw audio captured during mealtime. Without clean inputs, downstream tasks like anomaly detection, event classification, and health insights break down.
But we didn’t have a soundproof studio.
We didn’t have thousands of perfectly labeled eating sounds.
We didn’t have hardware-clean signals.
What we did have was a practical strategy: build a synthetic-but-realistic dataset using publicly available dog audio, scraped eating sounds, and large noise corpora - then mix them in controlled ways to train robust models.
This is the story of how we built that dataset, how it helped our noise-cancellation model improve, and what other engineers can learn from the process.
1. The Problem: Real Homes Are Acoustic Chaos
Every ML model begins with a simple question: What ruins the signal?
With dog audio, the answer is everything. Our early recordings from the field highlighted challenges:
- Ceiling fans and HVAC hum.
- TV shows, music, distant human speech.
- Metallic clinks from bowls.
- Refrigerator compressors.
- Other dogs barking nearby.
- Echo in small rooms.
- Microphone handling noise.
Realizing that building a clean dataset in such chaos is nearly impossible, we chose the opposite strategy:
➡ Build clean signals first. Then add noise on our own terms.
This flipped the usual “collect messy data → clean it → train on it” workflow into a synthetic-mixing pipeline that mimics real homes far better.
2. The Approach: Start With Clean Dog Sounds
We needed clean dog-centric sounds (especially eating), so our dataset had three components:
1. Public Dog Audio Dataset (General Dog Sounds)
We used a publicly available dog sound dataset from Google that includes:
- Barks
- Whines
- Sniffs
- Growls
- Panting
They’re recorded in varied but relatively clean environments - perfect as base signals.
2. Scraped Dog Eating Sounds
Dog eating sounds are scarce, so we collected samples from:
- Public videos (where usage was legally allowed)
- Open-domain audio platforms
- User-generated meal recordings
These had to be lightly cleaned and segmented, but they gave us the unique acoustic pattern we needed: rhythmic crunching, licking, gulping.
3. Generic Noise Libraries
To simulate home environments, we downloaded open-source noise datasets containing:
- White, pink, brown noise
- TV/music fragments
- Human speech
- Kitchen noises
- Traffic & ambient city sound
- Indoor room tones
By mixing these with our clean dog audio, we could generate thousands of realistic “noisy” samples without recording a single second inside a controlled studio.
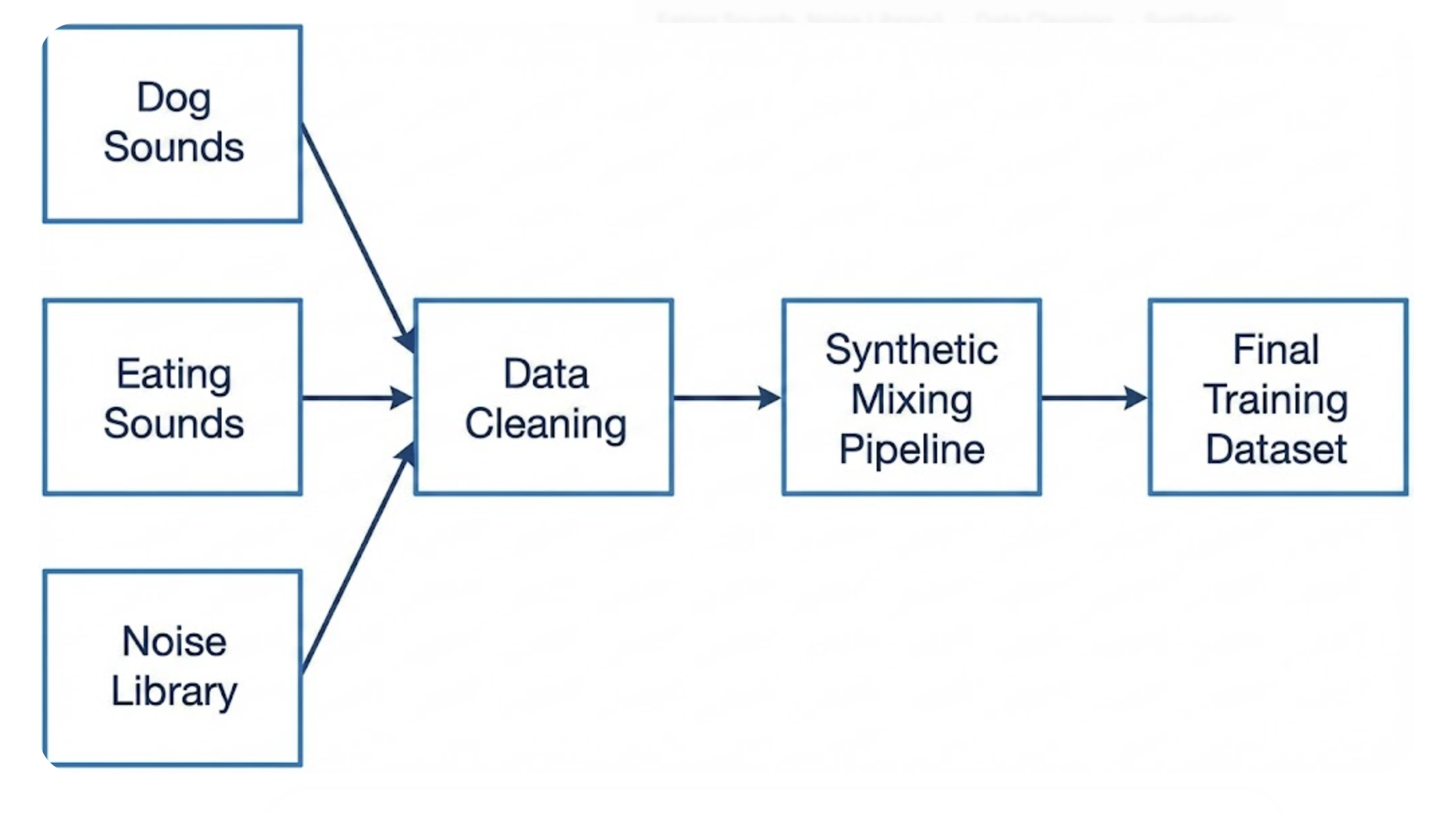
3. The Mixing Pipeline: Where the Magic Happens
The core of our dataset is not the audio itself - it’s the procedure.
We built a controlled mixing system that takes:
- a clean dog sound clip D(t)
- a noise sample N(t)
and produces:
Mixture M(t) = D(t) + α × N(t)
Where α is a random mixing coefficient that simulates real-world SNR (Signal-to-Noise Ratio).
Randomization Strategy
Every mixture varies randomly in:
- Noise type (speech, fan hum, music…)
- Noise intensity (SNR from +10 dB to −12 dB)
- Start offsets (noise begins mid-way, dog sound begins early, etc.)
- Clipping probabilities (simulate metal bowl clinks)
- Reverberation simulation using small room IRs
- Duration jitter to avoid overfitting to fixed lengths
This randomness forces the model to learn actual dog acoustics, not specific noise patterns.
Why Synthetic Mixing Works Better Than Cleaning Real Audio
Real dogs never give you clean stems. If you try to train a separation model from real recordings:
- noise is entangled with the signal
- mislabelled segments pollute training
- you overfit to one house’s soundscape
Synthetic mixtures solve all three problems.
➡ We know exactly what the clean audio is.
➡ We know exactly what noise was added.
➡ The model gets perfect supervision.
This is the same strategy used in speech separation models like Conv-TasNet and AudioSep.
4. Training the Model: Why This Dataset Helped
Once we had thousands of (clean dog sound, noisy mixture) pairs, training a noise-cancellation model became straightforward.
We used a pre-trained separation architecture (Tiny-TasNet-style for efficiency), and fine-tuned it on our dog-specific synthetic mixtures.
The Impact of the Dataset
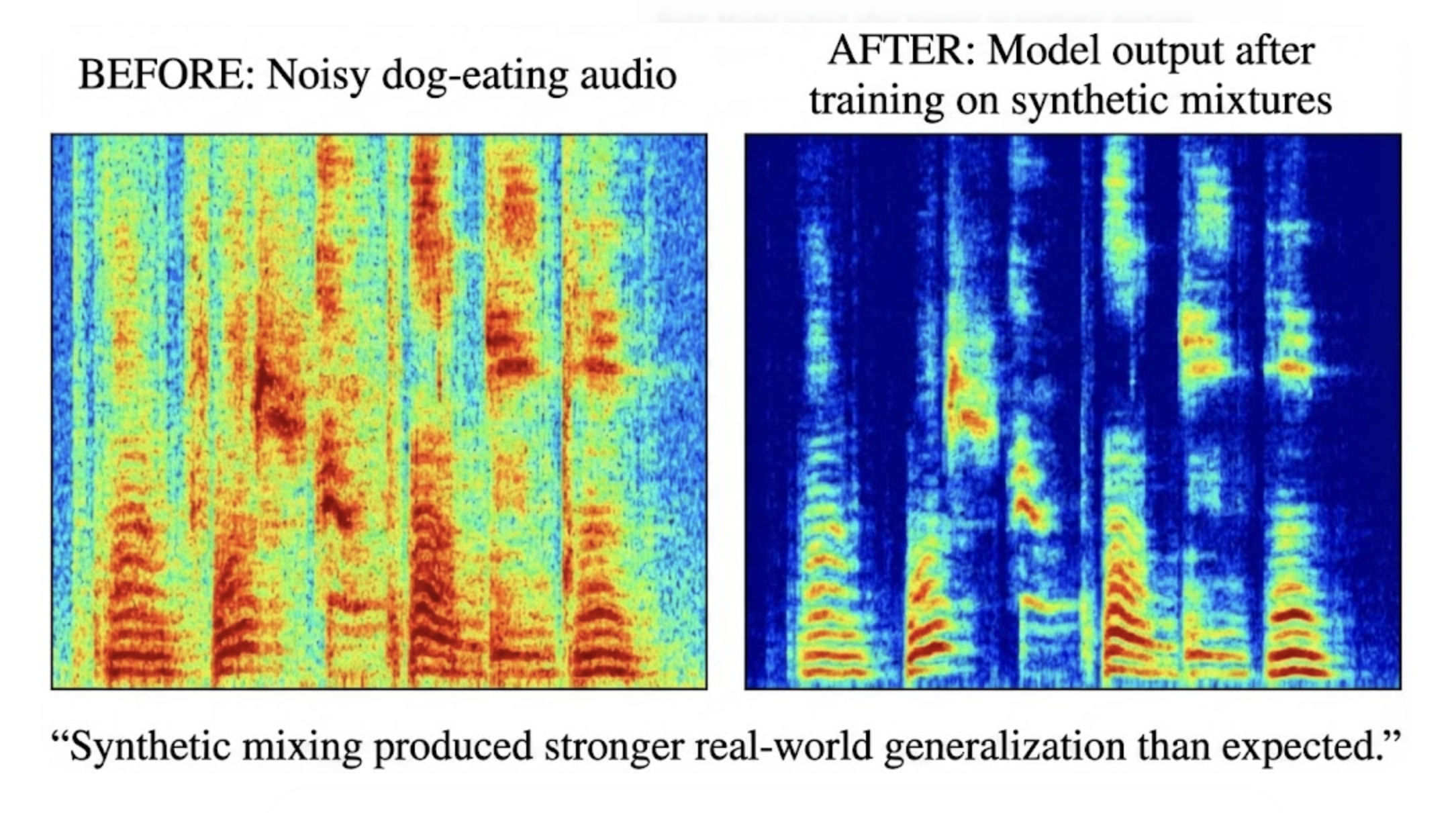
Even though the dataset was synthetic, the results in real homes were dramatically better:
- Sharper detection of eating patterns
- Reduced false positives in anomaly detection
- Cleaner spectra for downstream ML models
- Better handling of complex noises (TV, speech, utensils)
Our first validation runs on synthetic audio were strong, but real-world performance lagged until we improved the dataset.
Once synthetic mixing was tuned properly, real-world separation significantly improved.
In short:
➡ The dataset mattered more than the model architecture.
5. Lessons Learned While Building the Dataset
Building a noise-cancellation dataset without a studio sounds hacky. It isn’t. It’s an industry-standard technique used in speech, music, and environmental sound modeling.
Here are the takeaways that mattered most:
1. Clean bases are non-negotiable
Every good model begins with knowing exactly what the clean target should be.
2. Real-world noise diversity > number of samples
A dog eating with fan noise is different from dog eating with TV noise.
We prioritized variety, not volume.
3. Random SNR mixing is the most powerful augmentation
It created robustness across all environments.
4. You must mix a lot of terrible scenarios
Dog sound at −12 dB, drowning under music, still needs to be separated by the model.
Training on difficult mixtures improved performance on easy ones.
5. Synthetic data ≠ fake data
It’s a structured simulation that helps the model learn real-world invariances.
6. The Hoomanely Connection: Why This Matters
Hoomanely’s goal is simple: help pet parents understand their pets better through smart, non-intrusive technology.
Audio is a core pillar of that vision - especially during meals, where subtle behavioral changes (gulping too fast, irregular chewing, choking, gasping, coughing) can offer early signals about health.
Noise-free audio isn't a luxury; it’s a requirement.
By building this dataset and training a robust noise-cancellation model:
- our bowl’s audio analytics improved,
- our anomaly detection algorithms became more stable,
- and our insights became more trustworthy for pet parents.
This dataset-building process directly strengthens the foundation of EverBowl's audio intelligence.
7. Common Pitfalls (and How We Avoided Them)
❌ Pitfall 1: Mixing too much synthetic noise
If every clip is overwhelmingly noisy, the model learns to suppress everything - including dog sounds.
Fix: maintain a balanced SNR distribution.
❌ Pitfall 2: Using only one type of noise
A model overfits to patterns it sees repeatedly.
Fix: use dozens of noise categories.
❌ Pitfall 3: Forgetting time alignment
Audios must be sampled at the same rate and aligned precisely.
Fix: resample & pad all clips consistently.
❌ Pitfall 4: Not validating with real recordings
Synthetic performance does NOT equal real-world performance.
Fix: validate with real bowls, real homes, real dogs.
8. Results: Did It Actually Work?
After training on our synthetic dataset:
- Separation quality improved noticeably on real eating sessions
- Our validation SI-SDR increased significantly
- The model generalized to unseen noises (cars, utensils, footsteps)
- Eating regularity patterns became clearer
- Anomaly detection false alarms dropped
This confirmed our hypothesis:
➡ When clean real-world data is impossible, synthetic mixing is the most reliable way to bootstrap an audio model.
9. Takeaways
Building a noise-cancellation dataset without a sound studio isn’t just possible - it’s practical, scalable, and surprisingly effective.
Here’s what matters most:
- Start with the cleanest dog audio you can find.
- Scrape eating sounds - they are rare and incredibly valuable.
- Use diverse noise sources and mix them aggressively.
- Train with varied SNRs, durations, and noise categories.
- Validate frequently with real-world recordings.
- Iterate on the dataset more than the model.
The result? An AI system that actually hears dogs - not the chaos around them.



