How We Distilled SOTA Transformers for Real-Time Edge Audio Classification

Audio classification on edge devices presents a unique engineering challenge that doesn't get enough attention in the ML community. While everyone's building massive transformer models that need GPU clusters, we needed something that could run on a Raspberry Pi and accurately detect different types of dog sounds in real-time. This is the story of how we bridged that gap using knowledge distillation with CLAP transformers.
The Edge Audio Problem Nobody Talks About
Audio classification on constrained hardware is fundamentally harder than image classification, and here's why: you can't just look at an audio file and understand what's wrong. With images, a developer can visually inspect mislabeled data or understand why a model failed. But audio? It's just a waveform or a spectrogram that requires domain expertise to interpret.
Add to this the real-world complications: background noise, varying recording quality, different microphone characteristics, and the computational constraints of edge devices. You need a model that's both small enough to run on limited hardware and accurate enough to be useful. That's a tough combination.
Most edge audio solutions compromise on one of three things:
- Accuracy: Simple models that miss nuanced sounds
- Latency: Cloud-based inference that introduces delays
- Generalisation: Over-fitted models that fail in new environments
We needed all three: high accuracy, real-time inference, and robustness across different acoustic environments.
The State of Edge Audio Classification
The standard approach for audio classification on edge devices typically involves lightweight CNN architectures or simplified recurrent models. Here's what exists:
Traditional CNNs on Mel Spectrograms: Convert audio to mel-frequency spectrograms (essentially visualising audio frequencies over time) and run a small convolutional network. This works but lacks the contextual understanding that makes modern AI powerful.
Quantised Mobile Models: Take a larger model like YAMNet or VGGish and compress it through quantisation. The problem? You're starting with models that weren't designed for your specific use case, and compression inevitably hurts performance.
Feature Engineering + Classical ML: Extract handcrafted features (MFCCs, zero-crossing rates, spectral features) and use SVMs or Random Forests. Interpretable but brittle—they fail when real-world audio doesn't match your assumptions.
Transfer Learning from General Models: Fine-tune pre-trained audio models on your specific task. Sounds good in theory, but these models are usually too large for edge deployment, or they lose critical knowledge during aggressive compression.
Where These Approaches Fall Short
The fundamental limitation? None of these methods effectively transfer the knowledge of state-of-the-art models to edge-compatible architectures.
Quantisation and pruning help with size, but they're crude tools—you're essentially hoping important information survives compression. Classical approaches lack the representational power of modern transformers. And training small models from scratch on limited data? They simply can't learn the rich audio representations that large models develop.
We needed a principled way to distill the understanding of a massive, accurate model into something that could run on a $50 piece of hardware. That's where our teacher-student framework came in.
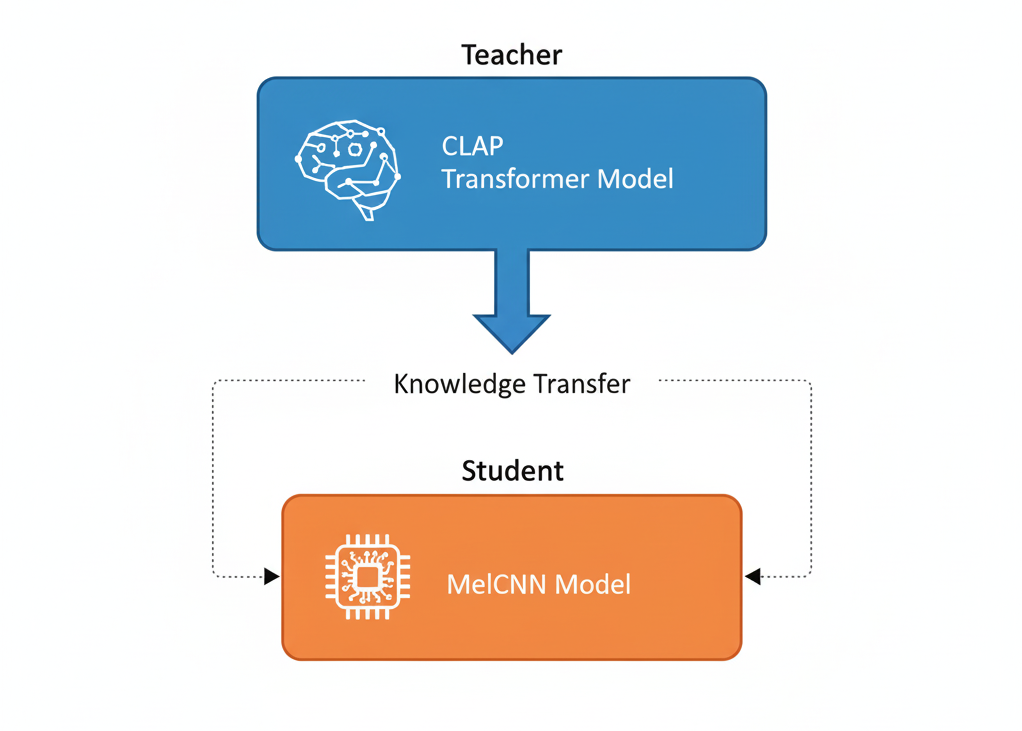
Our Approach: Knowledge Distillation with CLAP
We designed a knowledge distillation pipeline using CLAP (Contrastive Language-Audio Pretraining) as our teacher model and a custom MelCNN as our student model for edge deployment.
Why CLAP as the teacher? CLAP is a transformer-based model that understands audio in the context - it's been trained on massive datasets to align audio and text representations. This means it doesn't just classify sounds; it understands them conceptually. For our dog sound classification problem, this contextual understanding was invaluable.
Why MelCNN for the edge? We needed something computationally efficient that could process mel-spectrograms with minimal overhead. A well-designed CNN architecture can achieve this while still having enough capacity to learn from CLAP's rich representations.
The key insight: we don't need the student to replicate the teacher's architecture, just its understanding. CLAP's job was to provide high-quality labels and soft targets; the MelCNN's job was to learn those patterns in a computationally efficient way.
The Data Pipeline: Quality Over Quantity
Raw audio data from the internet is messy. Really messy. Dogs barking with background music, outdoor recordings with wind noise, videos with human speech overlapping barks—none of this would train a reliable model.
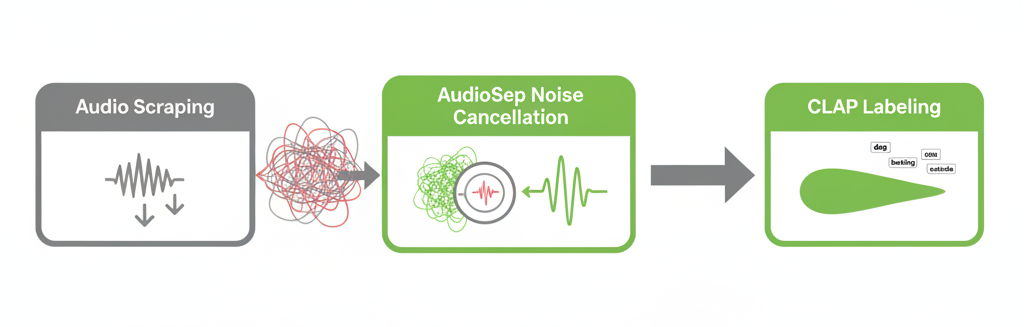
Our three-stage data pipeline:
Stage 1: Large-Scale Scraping
We collected thousands of dog sound audio samples from various sources—YouTube, sound libraries, user submissions. The goal was volume and diversity: different breeds, different contexts, different recording conditions.
Stage 2: Noise Cancellation with AudioSep
Here's where it gets interesting. We ran every audio sample through AudioSep, a source separation model that can isolate specific sounds from noisy backgrounds. Think of it as extremely advanced noise cancellation—it doesn't just remove noise, it separates out the dog sounds from everything else in the recording.
This step was critical. Without it, CLAP would label ambiguous sounds incorrectly, and those errors would propagate to our student model.
Stage 3: High-Quality Labeling with CLAP
Clean audio samples went through CLAP for classification. Because CLAP has such strong generalisation from its pre-training, it could accurately classify dog sounds into our target categories even without fine-tuning. This gave us a large dataset of reliably labeled dog sounds.
The beauty of this pipeline? We automated the creation of a high-quality labeled dataset without manual annotation. CLAP's strong zero-shot capabilities did the heavy lifting.
Training the Student: Distillation in Practice
With our CLAP-labeled dataset ready, we trained the MelCNN using knowledge distillation. The student model learned from both:
- Hard labels: The class assignments from CLAP
- Soft targets: The probability distributions over classes (these contain richer information about similarities between classes)
The MelCNN's architecture was designed specifically for edge deployment:
- Efficient depth-wise separable convolutions
- Optimised input resolution (smaller mel-spectrograms)
- Minimal fully-connected layers
- Quantisation-friendly operations
The resulting model was under 2MB and could perform inference in under 50ms on a Raspberry Pi 4. But more importantly, it maintained over 90% of CLAP's accuracy on our test set—far better than training a small model from scratch would achieve.
What We Learned (and What Surprised Us)
AudioSep was non-negotiable: In early experiments without noise separation, the model would pick up on background correlations instead of the actual dog sounds. Clean data made all the difference.
CLAP's zero-shot power: We initially planned to fine-tune CLAP on our dog sounds, but its zero-shot classification was already so accurate that fine-tuning provided minimal gains. This saved significant compute time.
The student exceeded expectations: We expected some accuracy degradation with such aggressive model compression, but the knowledge distillation framework preserved much more information than traditional compression methods.
Edge deployment has hidden complexity: Model size is just one factor. Memory bandwidth, cache utilisation, and quantisation strategies mattered as much as the architecture itself.
Key Takeaways
✓ Audio classification on edge requires different thinking than cloud-based ML. You need to prioritise efficiency without sacrificing accuracy.
✓ Knowledge distillation bridges the capability gap between SOTA models and deployable ones. Don't just compress—teach.
✓ Data quality matters more than quantity for specialised tasks. Noise separation and high-quality labeling were force multipliers.
✓ SOTA models like CLAP can be powerful labeling tools even if you can't deploy them. Use them as teachers, not just as endpoints.
✓ Edge constraints force better engineering, leading to systems that are not just small, but robust and efficient.
Building production ML systems is about making intelligent tradeoffs. For us, that meant accepting we couldn't run transformers on a Raspberry Pi—but we could teach a much simpler model everything those transformers knew.



