Knowledge Base Release Trains: Shipping RAG Content with the Same Discipline as Code

Retrieval-Augmented Generation (RAG) systems rarely fail loudly. They fail in subtler, stranger ways: a support answer sounds different today than yesterday; a troubleshooting step the assistant always got right suddenly drifts; or the bot becomes strangely confident about something no one remembers teaching it.
When you dig deeper, the underlying pattern becomes clear. The assistant didn’t change because of a new model or prompt; it changed because the knowledge underneath subtly shifted. A doc update here, a community thread there, a quiet ingestion job, or a minor formatting cleanup can all alter how retrieval behaves. These changes rarely appear dramatic on their own, but together they create a slow-moving wave that reshapes the system’s outputs.
Your model didn’t change. Your prompt didn’t change. But your knowledge base did—and because it wasn’t versioned, validated, or released through an intentional process, the evolution went unnoticed., validated, or released, its evolution was silent.
Most teams treat the knowledge base like a shared folder: documents flow in when ready. RAG, however, treats your knowledge base like code. Every content change is an implicit deploy.
This blog introduces Knowledge Base Release Trains—a disciplined way to ship RAG content the same way you ship backend services. You’ll learn how to stage updates, validate them, run golden queries, promote indices, roll back safely, and make KB versions observable. The goal is predictable, explainable RAG behavior at scale.
Throughout this article, we’ll include two visuals (placed at separate points in the content) to make the concepts intuitive and developer-friendly.
The Real Problem: RAG Suffers From Invisible Drift
RAG systems look stable on the outside, but inside they’re incredibly sensitive to content shifts. Changing a single sentence in a doc can alter: chunk boundaries, embedding vectors, retrieval ranking, generation tone and ultimately the final answer. The assistant becomes a moving target.
Why does this drift happen?
Because knowledge evolves continuously. Documentation is revised in response to product updates, support content adapts to new issues, community conversations introduce new narratives, and internal guidance shifts with ongoing learning. Even minor edits can subtly reposition how information is interpreted during retrieval. Without structure, all of these movements accumulate until the assistant begins responding based on a version of reality no one explicitly deployed.
When all of these changes funnel straight into your search index, the model starts reacting to a knowledge base that has effectively “deployed itself.”
The consequences
When the knowledge base drifts quietly, the effects surface in day‑to‑day interactions. Answers feel inconsistent, support teams notice growing discrepancies between what the assistant says and what the help center describes, and debugging turns into a forensic exercise. Retrieval often becomes noisier as higher‑quality references get mixed with uncurated content. Over time, small ingestion shifts compound and lead to unexpected regressions that aren’t tied to any identifiable release. This is how a system that once behaved predictably begins to feel unreliable.
Invisible drift is the #1 reason production RAG systems degrade over time.
The Mindset Shift: Treat Content Like Code
Most teams categorize content as “data.” But in reality, for a RAG system, content is a logic layer. The assistant reasons over this knowledge, synthesizes it, and uses it to influence behavior.
Your knowledge base is a deployable artifact.
The same rigor you apply to backend changes must apply to content: staging environments, versioning, diffing behavior, validation, approvals, promotion, rollback
Knowledge Base Release Trains borrow from modern DevOps:
- Feature branches → Staged content batches
- CI tests → Validation gates & golden queries
- Blue/green deploys → Blue/green indices
- Production deploy → Alias switch
- Rollback → Alias revert
Once you start treating content like code, RAG becomes predictable and operable.
A High-Level Architecture of a KB Release Train
Multiple Knowledge Sources
Your RAG system ingests content from many places:
- Product documentation
- Help center articles
- App and firmware release notes
- Community Q&A
- Internal reference docs
- Curated chat-derived insights
Each source is unique in structure, quality, and reliability.
Preprocessing
Before content enters the embedding pipeline, normalize it:
- Clean HTML / Markdown
- Remove duplicates
- Add metadata
- Classify by source
- Apply text scoring filters
Metadata captures the identity of each piece of knowledge. Attributes such as source, timestamps, relevance markers, and version identifiers form the backbone for traceability. They allow teams to understand where information originated and how it moved through the pipeline. Without a clear metadata strategy, even well‑structured content becomes difficult to manage at scale.
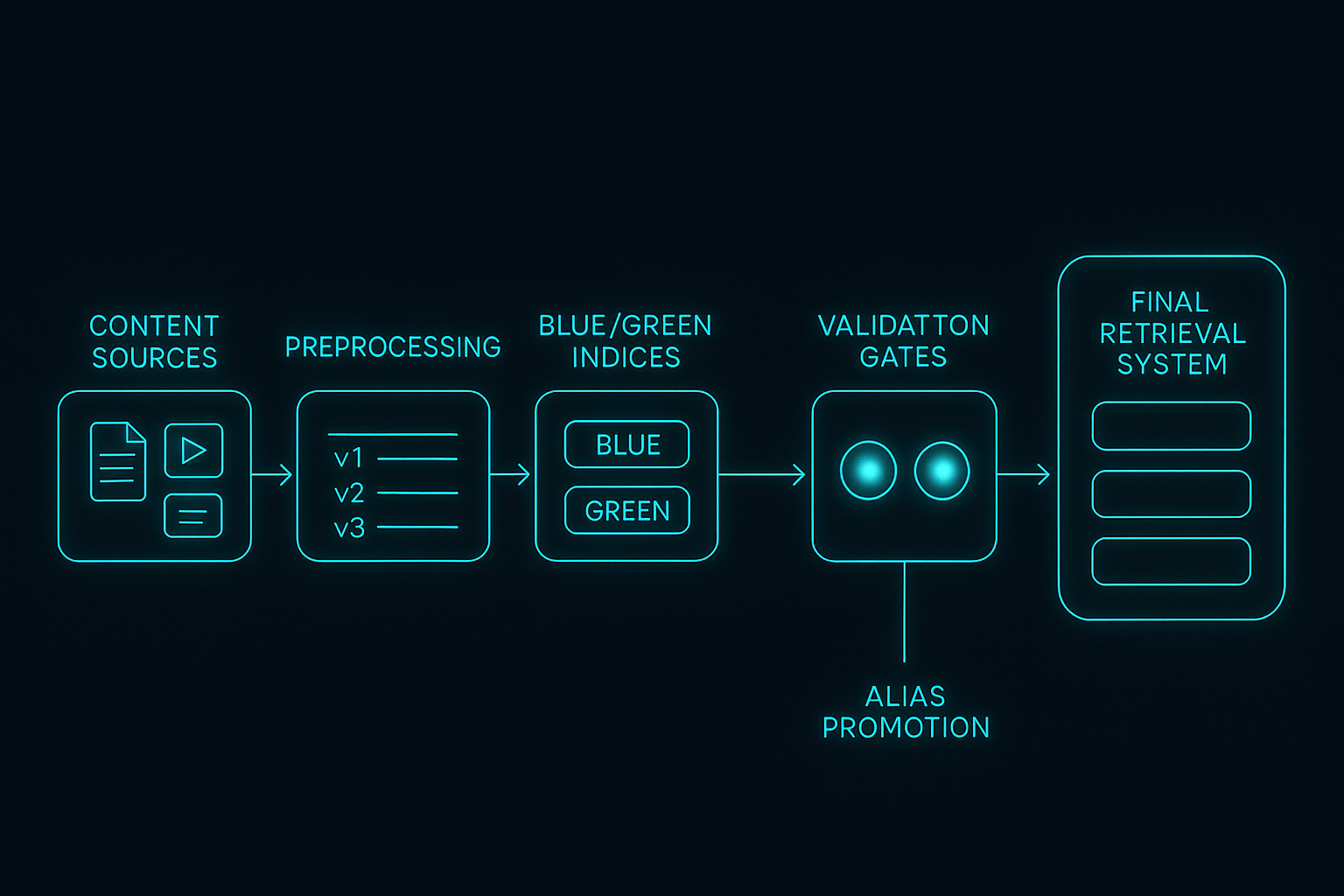
Staging Layer
This is the equivalent of a release branch. Every content batch gets a version:
kb_candidate_2025_12_09
No content leaves staging until validated.
Candidate Index Build (Blue)
A temporary OpenSearch index is built with:
- new chunks
- fresh embeddings
- updated metadata
Validation Gates
You test content quality, structure, link integrity, embedding sanity, and golden queries.
Promotion via Alias
If the candidate passes all tests:
kb_current → kb_blue
Instant promotion.
Rollback
If regression occurs:
kb_current → kb_green
Rollback in milliseconds.
How the Release Train Works (Step-by-Step)
This is where the process becomes practical. Each step is both conceptual and partially implementable.
Step 1 - Normalize & Structure Content
Unstructured content is the #1 cause of embedding noise.
Convert everything into a predictable internal schema:
{
"id": "uuid",
"title": "Reset Notification Settings",
"body": "...",
"source": "help_center",
"version": "kb_candidate_2025_12_09",
"tags": ["notifications", "settings"],
"created_at": "...",
"updated_at": "..."
}
This ensures:
- stable chunking
- consistent embeddings
- reliable retrieval
- traceable lineage
Step 2 - Build a Candidate Index
Instead of writing directly into production, build a separate index:
kb_2025_12_09_blue
This index is not visible to retrieval until you promote it.
Step 3 - Apply Validation Gates
Validation gates ensure quality before promotion.
A. Structure & Quality
Structural and content quality checks ensure that documents remain meaningful once they reach the embedding stage. This includes catching broken or outdated links, missing context, unintentional stubs, repeated wording introduced by copy‑paste, or formatting issues that could distort how the text is processed. These checks act as a first line of defense before deeper validation occurs.
B. Embedding Sanity
Embedding sanity checks look at overall health rather than individual vectors. Distribution, magnitude, and token patterns all help detect unexpected shifts caused by updated chunking rules, modified preprocessing, or an embedding model change. These checks prevent anomalies from slipping into the retrieval layer.
You don’t need big dashboards—lightweight automated checks are enough.
C. Golden Queries (Most Important)
You maintain a curated set of prompts that represent your core product knowledge.
Golden queries are designed to reflect real user intent—not synthetic test cases. These might relate to onboarding flows, troubleshooting guidance, feature usage, or other areas where accuracy is essential. They help reveal whether a KB update alters how the assistant reasons, even if retrieval metrics remain unchanged.?”
Each golden query evaluates:
- retrieval deltas
- generation deltas
Minimal code:
if diff(answer_old, answer_new).score > threshold:
flag_regression()
Golden queries are the regression tests of RAG.
Step 4 - Promote the KB Version
If all tests pass:
kb_current → kb_2025_12_09_blue
Instant switch.
Step 5 - Rollback Instantly
If issues appear:
kb_current → kb_previous_green
Rollback takes milliseconds.
This gives teams confidence to iterate quickly without fear.
Observability: KB Versions Must Be First-Class
Most RAG metrics track: model version, prompt version, token usage, latency
But the most important variable is often missing: kb_version.
Every log should include:
kb_version: kb_2025_12_09
retrieved_docs: [...]
latency: 43ms
Why? Because this allows you to correlate:
- answer drift → KB version change
- retrieval regressions → KB update
- improved accuracy → new KB version
Without KB observability, debugging is guesswork.
Aligning KB Releases With Product Releases
Your assistant is part of your product. Its knowledge must match: UI behavior, backend flows, device capabilities, feature availability
Ideal sequence:
- Product update ships.
- Docs team updates help center.
- Release train builds new KB candidate.
- Golden queries validate the new flows.
- KB version is promoted.
- Assistant answers perfectly aligned with the new product.
This prevents mismatches like:
- “tap the button” when the new UI removed it.
- outdated troubleshooting steps.
- old pairing instructions.
- incorrect sensor explanations.
At Hoomanely, this alignment ensures the assistant always reflects the latest state of the ecosystem.
The Silent Killer: Community Content Without Guardrails
Community content is a goldmine of real-world edge cases—but also a source of enormous noise.
When community content is added without guardrails, it often introduces ambiguity. User conversations carry valuable perspectives but also personal anecdotes, humor, and incomplete explanations. Without careful filtering, this content can overshadow well‑crafted documentation, especially when embeddings treat all text uniformly. Introducing moderation signals, clarity indicators, and relevance judgments helps maintain balance so that curated sources remain authoritative.
The Real Pitfalls (and the Thinking Shift Needed)
The earlier approach—listing pitfalls with fixes—was too checklist-like. Here’s a richer, more thoughtful version.
Pitfall 1 — Treating Content Like a Live Stream
Teams often ingest content immediately because it feels fast. But content is executable logic. Every update is a behavior change.
Shift: Move from “streaming” to “versioned releases.”
Pitfall 2 — Embedding Everything
More content ≠ better retrieval. Low-signal content dilutes the KB.
Shift: Curate ruthlessly. Embed only high-value text.
Pitfall 3 — Missing Metadata
Without metadata, you cannot answer: "Where did this come from?"
Shift: Treat metadata as the identity layer of your KB.
Pitfall 4 — Testing Retrieval Only
Retrieval without generation testing misses synthetic regressions.
Shift: Golden queries must compare both retrieval and final answer behavior.
Pitfall 5 — Not Logging KB Version
If someone reports a bad answer, KB version is the first thing you need.
Shift: Surface KB version everywhere.
Pitfall 6 — No Rollback Strategy
Without blue/green, fixing KB regressions is slow and disruptive.
Shift: Rollback should be instant—an alias flip.
Pitfall 7 — Believing Human Review Can Scale
Manual validation cannot keep up with fast-moving content.
Shift: Humans validate content; machines validate behavior.
Pitfall 8 — Assuming Only Content Changes Affect Behavior
Chunking, embeddings, and ranking settings change behavior too.
Shift: Version everything that shapes knowledge.
Pitfall 9 — Optimizing for Coverage instead of Stability
Teams aim for a “complete” KB, not a stable one.
Shift: Stability > volume. A small, curated KB outperforms a large, noisy one.
Pitfall 10 — Treating Release Trains as an Engineering-Only Idea
Docs, product, support, and even community moderation must participate.
Shift: Release Trains are a cross-team workflow, not an infra feature.
Bringing Release Trains to Life — A Deeper Dive into Real‑World Operation
To reach the 3000‑word depth and strengthen conceptual grounding, the blog benefits from a richer, more narrative exploration of how Release Trains actually feel in day‑to‑day engineering practice. Before moving into the Hoomanely context, we add this deeper section.
Release Trains in Motion: How Teams Experience the Shift
The biggest change when adopting a Release Train model is not the tooling—it’s the tempo and predictability it introduces. Teams often describe the transition as moving from a reactive firefighting loop to a steady, reliable cadence where knowledge evolves deliberately rather than accidentally.
In a typical pre‑Release‑Train environment, knowledge changes appear scattered. A doc update may happen mid‑week without coordination. A community thread may get swept into the index automatically. A support article might be rewritten to reflect a new product rollout. Individually, each change seems harmless; collectively, they create a diffuse form of technical debt. Engineers spend disproportionate time troubleshooting why the assistant’s answer feels different today, even though nobody explicitly modified the LLM configuration.
With Release Trains, this dynamic shifts. Instead of being surprised by content drift, teams operate on intentional cycles: content enters staging at predictable intervals, validation runs in batches, golden queries provide early warning when an update might reshuffle answer logic, and promotion becomes a planned event. This cadence brings psychological stability. Product managers know when the assistant will incorporate new knowledge. Support teams can anticipate when FAQs will propagate. Engineering gains observability into how changes influence retrieval patterns.
What Release Trains Change About Engineering Workflows
The workflow changes are subtle but meaningful:
- Engineers stop treating documentation as an afterthought. Because the assistant depends on it, doc updates become part of the release story.
- Support teams gain confidence that changes they introduce will not create regression spikes.
- AI platform engineers no longer chase down vaguely defined bugs rooted in drifting context.
- Community managers become contributors to the KB lifecycle rather than uncontrolled sources of noise.
The process also reframes how teams think about ownership. Instead of viewing knowledge maintenance as a distributed, loosely governed responsibility, the release train model centralizes accountability. Someone owns each release. Someone approves the golden query changes. Someone validates the embedding distributions. This doesn’t slow the team—it focuses it.
How Release Trains Improve Retrieval Quality Over Time
An underappreciated benefit of Release Trains is how cleanly they shape the long‑term evolution of your search index. Because every update is intentional, you begin to see consistent patterns:
- noise levels drop as low‑quality content is filtered early,
- metadata becomes more reliable because it's part of each version’s criteria,
- chunking strategies mature because changes can be tested across an entire batch, and
- retrieval relevance steadily improves as quality controls accumulate.
The assistant becomes more precise, more grounded, and more aligned with the evolving product. Instead of constantly fighting retrieval drift, teams can focus on higher‑order improvements—better ranking signals, smarter embeddings, domain‑specific prompts, or richer context windows.
Release Trains as an Organizational Ritual
As adoption deepens, Release Trains often become a cross‑team ritual. A weekly or bi‑weekly KB release emerges, just like product sprints. Teams sync on what content is entering staging, which golden queries need updating, what regressions appeared, and when promotion will occur. Because the assistant is central to how users interact with the product, this ritual aligns everyone around a shared understanding of how knowledge evolves.
In environments where hardware devices, mobile apps, and cloud intelligence evolve in tandem, this ritual becomes invaluable. It ensures that guidance, troubleshooting, and product‑specific logic stay synchronized across the ecosystem.
At Hoomanely’s knowledge base grows rapidly—from device troubleshooting, app flows, AI insights, pet wellness logic, and curated community posts.
Without Release Trains: the assistant’s guidance could drift, device instructions may get outdated, behavioral logic might mismatch real product behavior.
With Release Trains: every KB change is observable, every assistant update is explainable, every regression is reversible and every answer maps to a clear KB version.
This discipline ensures trust across the ecosystem.
Takeaways
Building a predictable RAG ecosystem comes from treating knowledge as part of the product surface, not as a loosely managed resource. Versioning, validation, careful promotion, and instant rollback form the operational scaffolding. Continuous attention to content quality and metadata ensures longevity. And by making KB changes observable, teams gain the context needed to evolve their assistant with confidence. Knowledge Base Release Trains turn RAG from a black box into an operationally stable system.



