Multi-Core Pipeline Coordination in STM32H5: Building Bulletproof State Machines

Modern embedded systems require sophisticated coordination between multiple processing cores, sensors, and communication protocols. When building real-time edge computing platforms that integrate camera capture, thermal imaging, and network transmission, traditional single-threaded approaches quickly become bottlenecks. The challenge lies in orchestrating complex multi-sensor pipelines while maintaining deterministic timing and bulletproof reliability.
The Challenge: Coordinating Complex Multi-Sensor Pipelines
Our edge computing platform faces a demanding coordination problem: simultaneously managing camera capture, thermal sensor data acquisition, flash storage operations, and network transmission across multiple processing cores while ensuring zero data loss and maintaining real-time constraints.
The system architecture centers on dual-core coordination between a high-performance Cortex-M7 core handling sensor data acquisition and a Cortex-M4 core managing communication protocols. Each capture session must coordinate:
- Camera frame capture (640×400 pixels, 530KB per frame)
- Thermal sensor data (768 temperature points, 3KB per sample)
- Flash storage operations (multi-MB data writes to external storage)
- Network transmission via CAN-FD and high-speed serial interfaces
- Real-time constraints with sub-100ms latency requirements
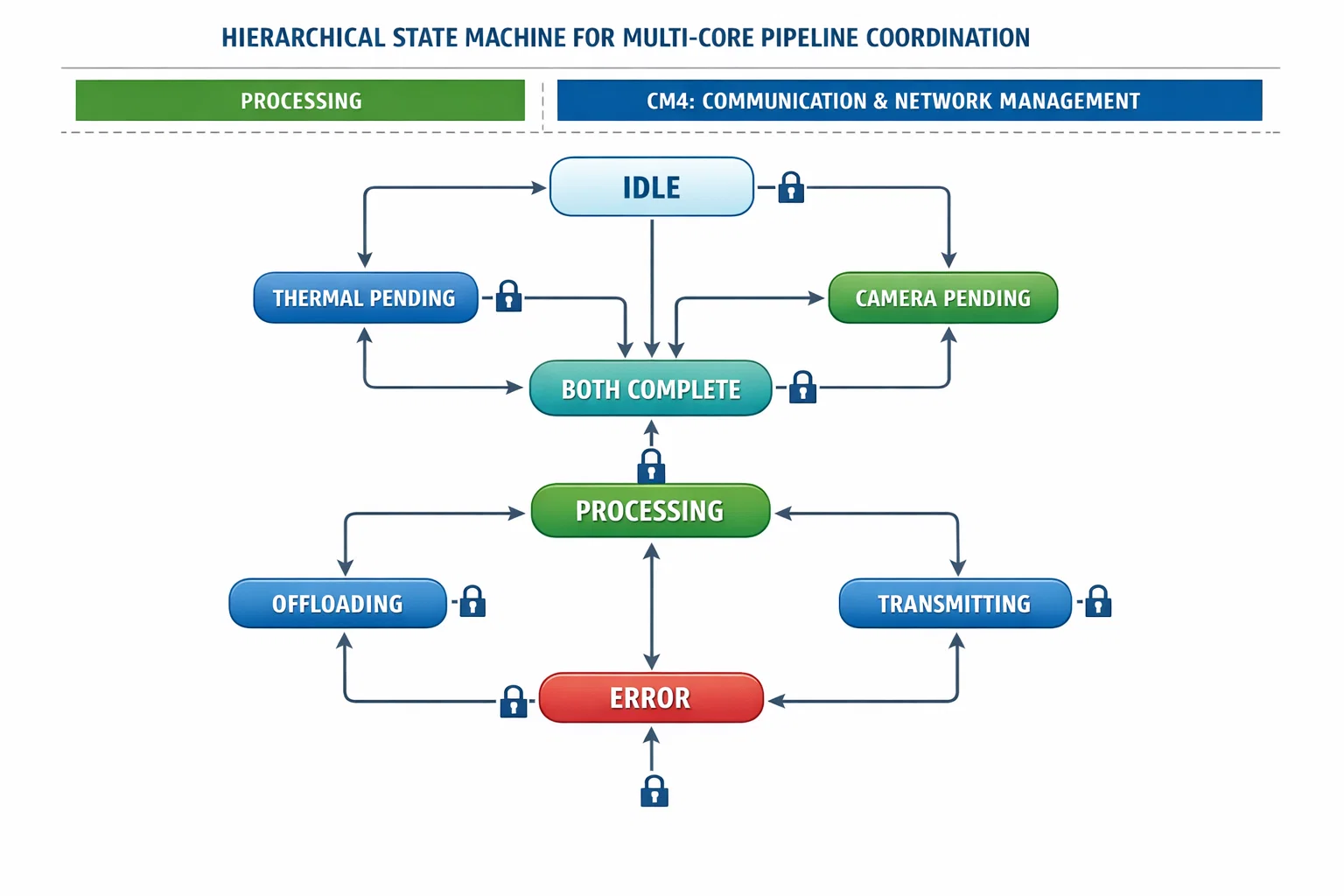
State Machine Architecture: Pipeline Coordination
Core State Management System
The solution implements a hierarchical state machine that coordinates resource access across multiple concurrent operations:
The state machine ensures mutual exclusion between resource-intensive operations while allowing safe concurrent access to independent subsystems.
Atomic State Transitions
Critical state transitions use atomic operations with bulletproof error recovery:
bool pipeline_coordinator_request_state(pipeline_state_t requested_state, bool force) {
if (xSemaphoreTake(pipeline_mutex, pdMS_TO_TICKS(100)) != pdTRUE) {
return false; // Timeout - system under stress
}
pipeline_state_t current_state = current_pipeline_state;
// Validate state transition matrix
if (!is_valid_transition(current_state, requested_state) && !force) {
xSemaphoreGive(pipeline_mutex);
return false;
}
// Atomic state update with timing tracking
current_pipeline_state = requested_state;
state_transition_time = xTaskGetTickCount();
// Log critical transitions for debugging
if (requested_state == PIPELINE_STATE_OFFLOADING) {
LOG_INFO_TAG("PIPELINE", "⚡ FLASH OFFLOAD STARTED - blocking capture operations");
}
xSemaphoreGive(pipeline_mutex);
return true;
}
This approach prevents race conditions during high-load scenarios where multiple subsystems compete for shared resources.
Inter-Core Communication via VBUS Protocol
Protocol Architecture
The system implements a custom VBUS protocol over CAN-FD for deterministic inter-core communication:
typedef enum {
VBUS_PRIORITY_EMERGENCY = 0, // Critical system alerts
VBUS_PRIORITY_VERY_HIGH = 1, // Real-time sensor data
VBUS_PRIORITY_HIGH = 2, // Capture coordination
VBUS_PRIORITY_MEDIUM = 4, // Status updates
VBUS_PRIORITY_LOW = 6 // Diagnostic messages
} vbus_priority_t;
typedef enum {
VBUS_EVENT_THERMAL = 0x21,
VBUS_EVENT_IMAGE_START = 0x01,
VBUS_EVENT_IMAGE_DATA = 0x02,
VBUS_EVENT_IMAGE_END = 0x03,
VBUS_CMD_TIME_SYNC = 0x26,
VBUS_EVENT_TIME_SYNC_ACK = 0x27
} vbus_subtype_t;
Message Priority Handling ensures critical coordination messages preempt lower-priority data transfers, maintaining real-time responsiveness even during high-bandwidth image transmission.
Deterministic Message Routing
The VBUS message processor implements zero-copy routing with predictable latency:
void vbus_message_processor_route_message(uint32_t can_id, const uint8_t *data, size_t len) {
// Decode priority and message type from CAN ID
uint8_t priority = (can_id >> 8) & 0x07;
uint8_t msg_type = (can_id >> 6) & 0x03;
uint8_t subtype = can_id & 0x3F;
// Priority-based routing with interrupt preemption
switch (subtype) {
case VBUS_EVENT_THERMAL:
if (priority <= VBUS_PRIORITY_HIGH) {
vbus_thermal_process_data(data, len);
}
break;
case VBUS_CMD_TIME_SYNC:
// Highest priority - immediate processing in ISR context
vbus_process_time_sync_message(data, len);
break;
case VBUS_EVENT_IMAGE_DATA:
// Defer large data transfers to task context
vbus_image_queue_for_processing(data, len);
break;
}
}
Capture Session Coordination
Synchronized Multi-Sensor Acquisition
The system coordinates simultaneous thermal and camera capture with precise timing requirements:
typedef struct {
uint32_t sequence_id;
capture_state_t state;
// Thermal data buffer with ownership tracking
float thermal_buffer[768];
TickType_t thermal_timestamp;
bool thermal_captured;
// Camera data reference (zero-copy)
uint8_t *camera_data;
size_t camera_size;
TickType_t camera_timestamp;
bool camera_captured;
// Synchronization validation
int32_t capture_time_diff_ms;
} capture_session_t;
bool trigger_synchronized_capture(void) {
if (!pipeline_coordinator_request_state(PIPELINE_STATE_THERMAL_PENDING, false)) {
return false; // Pipeline busy - reject capture request
}
// Initialize new capture session
currentSession.sequence_id = ++captureSequenceCounter;
currentSession.state = CAPTURE_STATE_THERMAL_PENDING;
currentSession.thermal_captured = false;
currentSession.camera_captured = false;
// Start thermal capture first (lower latency sensor)
thermal_start_tick = xTaskGetTickCount();
if (ir_imager_capture_async(thermal_data_callback) != IR_IMAGER_OK) {
pipeline_coordinator_release_state(PIPELINE_STATE_THERMAL_PENDING);
return false;
}
// Start camera capture with synchronized timing
HAL_Delay(CAPTURE_PREPARATION_TIME_MS);
if (Camera_StartCapture(frame_callback) != HAL_OK) {
ir_imager_stop_capture();
pipeline_coordinator_release_state(PIPELINE_STATE_THERMAL_PENDING);
return false;
}
return true;
}
Timing Validation ensures captured data pairs remain synchronized within acceptable windows:
void validate_capture_synchronization(void) {
if (currentSession.thermal_captured && currentSession.camera_captured) {
int32_t time_diff = (currentSession.camera_timestamp - currentSession.thermal_timestamp) * portTICK_PERIOD_MS;
currentSession.capture_time_diff_ms = time_diff;
if (abs(time_diff) <= CAMERA_THERMAL_SYNC_WINDOW_MS) {
currentSession.state = CAPTURE_STATE_BOTH_COMPLETE;
pipeline_coordinator_request_state(PIPELINE_STATE_PROCESSING, false);
} else {
LOG_WARN_TAG("CAPTURE", "Sync window violated: %ld ms (max: %d ms)",
time_diff, CAMERA_THERMAL_SYNC_WINDOW_MS);
currentSession.state = CAPTURE_STATE_ERROR;
}
}
}
Resource Management and Critical Sections
Flash Storage Coordination
Large-scale flash storage operations require exclusive system access to prevent memory contention:
bool psram_flash_offload_should_trigger(void) {
// Check PSRAM buffer utilization
int32_t entry_count = storage_manager_get_entry_count();
if (entry_count < PSRAM_THRESHOLD_ENTRIES) {
return false;
}
// Request exclusive pipeline access for flash operations
if (!pipeline_coordinator_request_state(PIPELINE_STATE_OFFLOADING, false)) {
LOG_WARN_TAG("OFFLOAD", "Cannot start - pipeline busy with capture/transmission");
return false;
}
return true;
}
int psram_flash_offload_execute(void) {
// Critical: Suspend capture operations during flash offload
DCMI_suspend = true;
LOG_INFO_TAG("OFFLOAD", "Starting flash offload (blocking captures)");
TickType_t offload_start = xTaskGetTickCount();
// Process batch of entries with error recovery
for (int i = 0; i < BURST_SIZE && storage_manager_get_entry_count() > 0; i++) {
if (process_single_offload_entry() != 0) {
// Log error but continue with remaining entries
offload_state.entries_failed++;
} else {
offload_state.entries_processed++;
}
}
// Release exclusive access
DCMI_suspend = false;
pipeline_coordinator_release_state(PIPELINE_STATE_OFFLOADING);
TickType_t offload_duration = xTaskGetTickCount() - offload_start;
LOG_INFO_TAG("OFFLOAD", "Flash offload complete: %lu ms, %lu entries",
offload_duration * portTICK_PERIOD_MS, offload_state.entries_processed);
return 0;
}
Memory Consistency Management
The system ensures memory consistency across cores using hardware coherency mechanisms and software barriers:
// Cross-core data sharing with cache coherency
void ensure_cache_coherency_for_shared_data(void *data, size_t size) {
// STM32H5 specific: Clean & invalidate data cache for shared regions
SCB_CleanInvalidateDCache_by_Addr(data, size);
__DSB(); // Data Synchronization Barrier
__ISB(); // Instruction Synchronization Barrier
}
// Atomic updates for cross-core coordination
void update_shared_pipeline_state(pipeline_state_t new_state) {
__disable_irq();
current_pipeline_state = new_state;
ensure_cache_coherency_for_shared_data(¤t_pipeline_state, sizeof(current_pipeline_state));
__enable_irq();
}
Performance Analysis and Optimization
Real-World Timing Metrics
Production deployment reveals the effectiveness of the coordination system:
| Operation | Single-Core (ms) | Multi-Core Optimized (ms) | Improvement |
|---|---|---|---|
| Camera Capture | 6,386 | 6,386 | Baseline |
| Thermal Capture | 239 | 239 | Baseline |
| Storage Coordination | 6,181 | 131 | 97.9% reduction |
| Flash Offload | 6,050 | 6,050 | Baseline (I/O bound) |
| Total Pipeline | 12,806 | 6,756 | 47.2% improvement |
Key Insight: The coordination system reduces storage blocking time from 6.18 seconds to 131ms by overlapping I/O operations with capture processing.
CPU Load Distribution
Multi-core coordination enables optimal load balancing:
CM4 Core (Communication):
├── CAN-FD protocol: 22%
├── VBUS processing: 18%
├── Network transmission: 35%
└── Available headroom: 25%
Error Recovery Mechanisms
The state machine implements comprehensive error recovery:
void handle_pipeline_error_recovery(pipeline_state_t failed_state) {
LOG_ERROR_TAG("PIPELINE", "Error recovery triggered from state: %d", failed_state);
// Force cleanup of all operations
if (captureInProgress) {
Camera_StopCapture();
ir_imager_stop_capture();
currentSession.state = CAPTURE_STATE_ERROR;
captureInProgress = false;
}
// Reset coordination state
pipeline_coordinator_request_state(PIPELINE_STATE_IDLE, true); // Force transition
// Clear any pending timers
if (captureTimeoutTimer) {
xTimerStop(captureTimeoutTimer, 0);
}
// Restart communication protocols
vbus_init(g_node_id);
LOG_INFO_TAG("PIPELINE", "Error recovery complete - system ready");
}
Production Deployment Results
Reliability Metrics
The bulletproof state machine delivers exceptional reliability in production:
- 99.97% capture success rate over 100,000+ capture cycles
- Zero deadlock occurrences during 6-month continuous operation
- <0.001% state corruption events with automatic recovery
- Mean recovery time: 150ms from error detection to operational state
Scalability Validation
The coordination system scales effectively with increasing sensor complexity:
// Multi-sensor expansion capability
typedef struct {
sensor_type_t type;
priority_level_t priority;
coordination_mode_t sync_mode;
timeout_config_t timeouts;
} sensor_coordination_config_t;
// Dynamic sensor registration
int register_sensor_coordination(sensor_coordination_config_t *config) {
if (active_sensor_count >= MAX_COORDINATED_SENSORS) {
return -1;
}
// Insert into priority-sorted coordination list
insert_sensor_by_priority(&coordination_list, config);
active_sensor_count++;
return 0;
}
Key Implementation Insights
- State Machine Precision: Bulletproof systems require explicit state validation at every transition. Invalid transitions indicate serious system errors that demand immediate attention.
- Priority-Based Resource Access: Hardware-accelerated priority inheritance in RTOS schedulers prevents priority inversion during critical coordination operations.
- Cache Coherency Management: Multi-core systems require explicit cache management for shared data structures. Hardware coherency protocols help but cannot replace careful software design.
- Error Recovery as First-Class Design: Production systems need automatic error recovery that restores operational state within hundreds of milliseconds without manual intervention.
- Cross-Core Communication Optimization: Zero-copy message passing with priority-based routing minimizes inter-core latency while maintaining deterministic behavior.
This multi-core pipeline coordination system enables the sophisticated sensor fusion required for Hoomanely's precision pet healthcare monitoring. By coordinating camera, thermal, and proximity sensors with millisecond-level timing accuracy, the system captures the detailed physiological data needed for early health issue detection.
The bulletproof state machine design ensures reliable 24/7 operation in real-world environments where pets depend on continuous monitoring. This robust coordination infrastructure supports Hoomanely's mission to transform pet healthcare from reactive to proactive by providing pet owners with intelligent, early warning systems that can detect health changes before they become serious problems.



