ONNX Runtime: The Engine Behind Fast and Flexible AI Inference


Intro
Imagine spending weeks training a model, only to realize that deploying it efficiently across devices - from cloud GPUs to Raspberry Pi boards - feels like a whole new challenge. That’s where ONNX Runtime comes in. Built by Microsoft and backed by an open community, ONNX Runtime (ORT) is the high-performance engine that helps run AI models anywhere - fast, efficiently, and with minimal friction.
At Hoomanely, where we deploy ML models on embedded systems like the Raspberry Pi CM4 to detect dog behaviors in real time, ONNX Runtime plays a crucial role. It allows us to bring the same neural networks we train on servers to small devices, keeping inference fast and power-efficient.
1. The Need for a Common Runtime
Deep learning frameworks like PyTorch, TensorFlow, and Keras each have their own ecosystems and model formats. But when it comes to deployment, these differences create friction:
- Incompatibility: A model trained in PyTorch can’t directly run in TensorFlow Serving.
- Performance Tuning: Each platform has its own optimization tricks.
- Hardware Limits: Smaller devices can’t handle heavyweight runtime dependencies.
This fragmentation made AI deployment cumbersome - until ONNX (Open Neural Network Exchange) stepped in.
2. What Is ONNX?
ONNX is an open standard for representing machine learning models. Think of it as a universal file format - like PDF for documents - that allows a model trained anywhere to run everywhere.
- You can export models from frameworks like PyTorch or TensorFlow into
.onnxformat. - You can run them using ONNX Runtime on CPUs, GPUs, or even specialized accelerators like NPUs.
That’s the foundation. But the real magic lies in how ONNX Runtime executes these models.
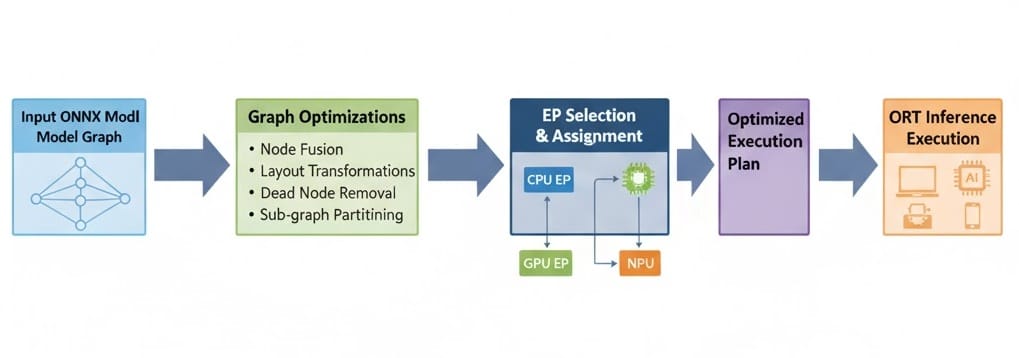
3. Under the Hood: How ONNX Runtime Works
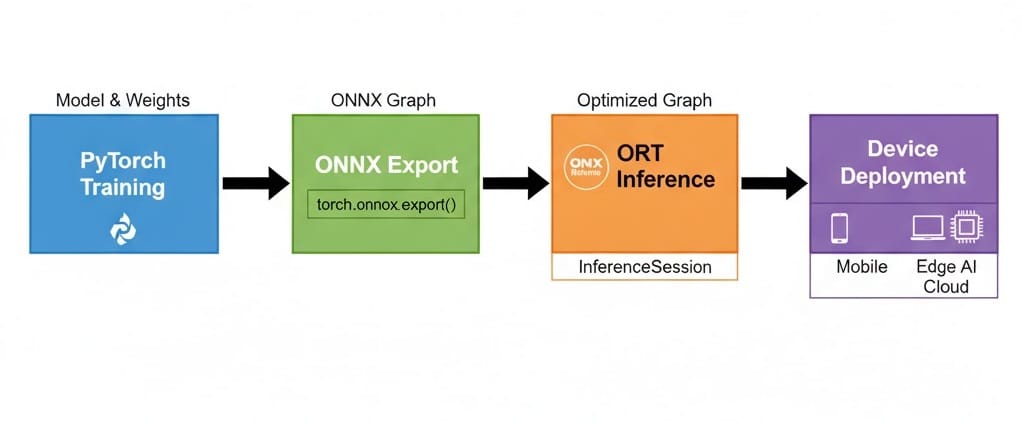
ONNX Runtime is designed as a modular, extensible inference engine. Let’s unpack its key components:
a. Graph Optimization
Before execution, ONNX Runtime analyzes the computational graph of the model - the web of layers and operations - and applies a series of optimizations:
- Constant Folding: Precomputes operations with static inputs.
- Operator Fusion: Combines multiple operations (like Conv + BatchNorm + ReLU) into a single efficient kernel.
- Memory Reuse: Reduces redundant memory allocations.
These optimizations significantly reduce latency and memory footprint - a must for edge inference.
b. Execution Providers (EPs)
ONNX Runtime can run on almost any hardware, thanks to its Execution Provider architecture. Each provider optimizes inference for specific hardware backends:
- CPU: Default provider for general-purpose processors.
- CUDA / TensorRT: For NVIDIA GPUs with FP16 and INT8 acceleration.
- DirectML / ROCm: For AMD GPUs.
- OpenVINO / CoreML: For Intel and Apple silicon.
- NNAPI / QNN: For Android and Qualcomm devices.
In practice, this means you can switch hardware without rewriting a single line of model code - just change the execution provider.
c. Quantization and Mixed Precision
ONNX Runtime supports quantization (e.g., FP32 → INT8) and mixed precision inference to reduce computation without a noticeable drop in accuracy. For edge devices, this can lead to:
- 2–4× faster inference
- Up to 75% smaller model size
- Lower power draw - crucial for battery-powered devices
4. Why It’s Fast: Behind the Performance
ONNX Runtime achieves its speed through multiple layers of optimization:
1. Pre-Execution Graph Transformations
By simplifying the graph before execution, it reduces computational overhead.
2. Kernel-Level Optimizations
Custom kernels are used for operations like convolution or attention - leveraging vectorization, parallelization, and low-level libraries (like cuDNN, MKL, or Eigen).
3. Execution Fusion and Threading
ORT uses fine-grained parallel execution and operator fusion to minimize context-switching between layers.
4. Lazy Initialization & Memory Pools
Memory pools reduce dynamic allocations, while lazy initialization ensures only necessary components are loaded - perfect for low-RAM systems like CM4.
5. Real-World Impact: From Cloud to Edge
At Hoomanely, we rely on ONNX Runtime to deploy models like audio anomaly detectors and vision-based behavior trackers - running efficiently on Raspberry Pi CM4s embedded in our smart bowls.
Here’s what we gain:
- Uniform Deployment: Same model runs on both cloud and edge.
- Latency Reduction: 2–3× faster inference vs native PyTorch.
- Lower Overhead: Runtime binary under 15 MB, easy to integrate with C++ or Python.
- Cross-Platform Support: ARM64, x86, macOS, Android, iOS - all covered.
This enables us to bring complex ML pipelines directly to the pet’s environment, reducing cloud dependency and ensuring privacy.
6. Extending ONNX Runtime: Custom Ops and Plugins
If your model has non-standard layers (say, a custom activation), ONNX Runtime allows you to register custom operators or build execution providers that integrate specialized hardware.
For example:
- Adding a thermal sensor fusion op for our temperature-detection pipeline.
- Integrating Qualcomm DSP for low-power inference on mobile devices.
This flexibility makes ONNX Runtime a foundation for innovation, not just deployment.
7. Integrating with Modern ML Toolchains
ONNX Runtime is deeply compatible with today’s ML workflows:
- PyTorch → torch.onnx.export() → ORT
- TensorFlow → tf2onnx.convert() → ORT
- Hugging Face → optimum.onnxruntime for optimized transformers
This makes it ideal for teams that experiment in research frameworks but need stable, fast inference in production.
8. The Future of ONNX Runtime
ONNX Runtime continues to evolve rapidly - from improving transformer acceleration to adding support for LLM inference. Features like ORT GenAI and memory-efficient attention kernels are bringing it closer to high-end inference frameworks like TensorRT, while maintaining its cross-platform advantage.
For edge and embedded AI - where every millisecond and milliwatt count - this evolution is pivotal.
Key Takeaways
- Portable: Train anywhere, deploy everywhere.
- Optimized: Leverages hardware acceleration with execution providers.
- Lightweight: Small binary, ideal for edge.
- Extensible: Supports custom ops and new hardware.
- Proven: Used in production by Microsoft, NVIDIA, and startups like Hoomanely.
Author’s Note
At Hoomanely, our mission is to make pet care smarter, safer, and more empathetic using technology that can live close to the pet - not just in the cloud. ONNX Runtime helps us push AI to the edge - literally - ensuring that every bark, blink, and bite is understood faster and locally.




