Optimising Audio Classifiers with Class-Specific Deep Learning Models

Training robust audio classification models requires diverse, high-quality data. But what happens when your dataset is imbalanced, when you have plenty of examples of dogs barking, but far fewer of dogs drinking or sneezing? Traditional augmentation techniques like pitch shifting or time stretching can only stretch your limited samples so far before they start sounding unnatural or repetitive.
We faced this exact challenge while building audio classification systems at Hoomanely. Our solution? Train a separate diffusion model for each audio class, allowing us to generate unlimited, class-specific synthetic samples that preserve the unique acoustic characteristics of each sound category. This post walks through our approach, why it works, and what we learned along the way.
The Challenge: Imbalanced Audio Classes
Audio datasets in the real world rarely come balanced. When classifying dog sounds, bark, howl, panting, eating, drinking, sneeze, and more, some categories naturally have more available samples than others. Vocalisations like barking are abundant in online sources, while subtle sounds like drinking or sneezing are much harder to find.
This imbalance creates a fundamental problem: models trained on imbalanced data learn to favor majority classes. A classifier might achieve seemingly good overall accuracy by simply predicting "bark" most of the time, while completely failing on rarer but equally important categories.
Traditional solutions include:
- Oversampling: Duplicating minority class samples (leads to overfitting)
- Undersampling: Removing majority class samples (wastes valuable data)
- Class weights: Penalizing mistakes on minority classes more heavily (helps, but doesn't add diversity)
- Basic augmentation: Pitch shift, time stretch, noise addition (limited novelty)
None of these approaches actually create new information. They either reuse existing samples or artificially manipulate them in predictable ways. We needed something more powerful.
Our Approach: One Diffusion Model Per Class
The core insight behind our approach is simple: different audio classes have fundamentally different acoustic properties. A dog's bark is characterized by sharp transients and specific frequency patterns. Panting has rhythmic breathing sounds. Eating involves crunching and chewing textures. These classes shouldn't be augmented the same way.
Instead of training a single augmentation model for all sounds, we trained separate diffusion models for each class. Each model learns the unique distribution of its target sound category, enabling it to generate new samples that are:
- Acoustically authentic to that specific class
- Diverse enough to improve model generalisation
- Balanced with other classes in the final dataset
The Pipeline
Our class-wise augmentation pipeline consists of four stages:
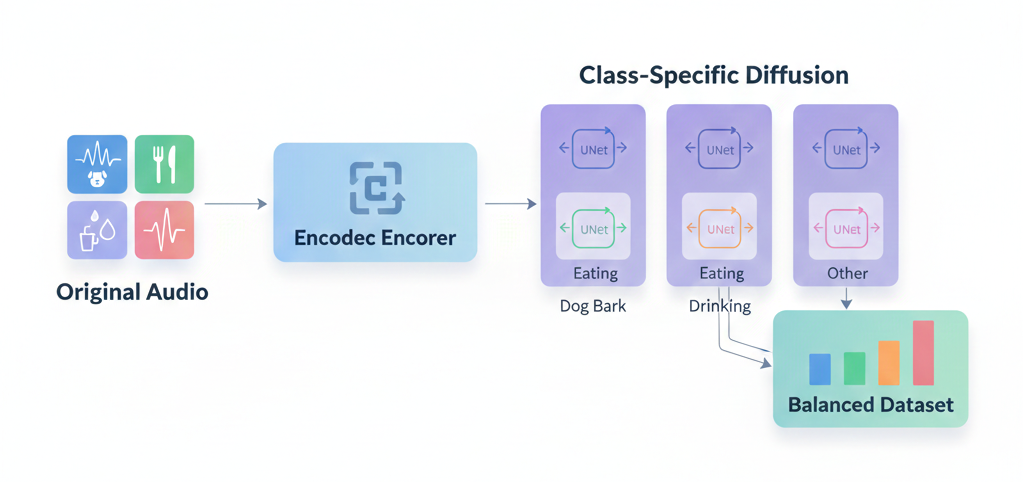
Stage 1: Audio Encoding
Raw audio waveforms are transformed into a compact latent representation using an audio codec model (Encodec). This compression captures the essential acoustic information while making the diffusion process computationally tractable.
Stage 2: Class-Specific Diffusion Training
For each audio class, we train a dedicated UNet-based diffusion model on the encoded representations of that class's samples. The model learns to denoise random noise back into latent codes that "sound like" samples from that class.
Stage 3: Synthetic Sample Generation
Given the trained models, we can generate as many new samples as needed for each class. We start from an existing sample's latent code, add controlled noise, and let the diffusion model refine it into a new variation.
Stage 4: Decoding and Dataset Assembly
Generated latent codes are decoded back to audio waveforms. We then assemble a balanced dataset with equal representation from each class, combining original samples with synthetic ones.
Why Class-Specific Models Matter
Training separate models for each class isn't just a convenience, it's architecturally essential. Here's why:
Preserving Class Characteristics
A single diffusion model trained on mixed audio classes would learn to generate "average" sounds that blur the boundaries between categories. It might produce samples that are acoustically valid but don't clearly belong to any one class, exactly the opposite of what a classifier needs to learn from.
By isolating each class during training, our diffusion models become specialists. The "bark" model never sees eating sounds, so it can't accidentally generate hybrid samples. Each model develops a focused understanding of its target category's acoustic signature.
Controlled Augmentation Factor
Different classes need different amounts of augmentation. If barking has abundant samples and sneezing has few, we can generate more sneezes and fewer barks to reach our target balance. With class-specific models, this scaling is trivial, we simply run each model for as many iterations as needed.
Quality Over Quantity
Counter-intuitively, training smaller, specialized models often produces higher-quality outputs than training one large model. Each diffusion model has a simpler task (learn one type of sound) and can dedicate its full capacity to that goal. The result is sharper, more realistic synthetic samples.
Preventing Data Leakage in Evaluation
One critical detail that's easy to overlook: augmented samples must stay with their source files during train/test splitting.
If an original audio file ends up in the training set while its augmented versions land in the test set, the model will essentially be tested on data it has already "seen." This leads to artificially inflated performance metrics that don't reflect real-world generalization.
Our splitting strategy explicitly groups files by their original source:
- Identify the "root" filename for each augmented sample
- Group all augmentations with their original
- Assign entire groups to either training or validation, never split across
This ensures that when we evaluate our trained classifier, it's truly facing novel audio sources it hasn't encountered during training.
Training the Classifier
With our balanced, diffusion-augmented dataset ready, training the YAMNet classifier followed standard practices:
- Architecture: YAMNet, a lightweight CNN designed for audio classification
- Input: Mel spectrograms extracted from audio clips
- Training: Cross-entropy loss with the Adam optimiser
- Validation: Held-out samples (with proper grouping to prevent leakage)
The key difference wasn't in the training procedure, it was in the data. By presenting the model with a balanced distribution of diverse, high-quality samples across all classes, we enabled it to learn robust features for every category, not just the majority ones.
Observed Improvements
After training on the augmented dataset, the classifier showed notable improvements in recognising previously underrepresented classes. Categories that had suffered from limited training data, like drinking and sneezing, now performed on par with well-represented classes like barking.
More importantly, the model's confusion between acoustically similar classes (like different vocalisations) decreased. The diffusion-augmented samples provided enough within-class diversity that the model could learn what truly distinguishes each category, rather than memorizing specific recordings.
Key Takeaways
1. Class-specific augmentation preserves acoustic identity.
Training one diffusion model per class ensures that synthetic samples maintain the unique characteristics of their target category.
2. Deep learning augmentation creates genuine diversity.
Unlike traditional signal processing, diffusion models generate novel variations that expand the effective size of your dataset without trivial repetition.
3. Data splitting must respect augmentation groups.
Always keep augmented samples with their original sources during train/test splitting to avoid data leakage and inflated metrics.
4. Balance is achievable without discarding data.
Rather than undersampling majority classes, generate more samples for minority classes to achieve balance while retaining all original information.
5. Specialized models outperform generalized ones for augmentation.
Smaller, focused diffusion models produce higher-quality outputs than a single model trying to learn all classes simultaneously.



