OTA Over USB-CDC for a Wedged Wireless SoC — Why the Update Path Can't Be Your Recovery Path

A customer's home hub stops sending data to the cloud. Logs go quiet. The Linux side looks fine, the bridge service is alive, the CAN driver is alive, but the wireless SoC it talks to over USB-CDC is silent. The chip enumerates as a serial device, so the host kernel sees it. Your push-the-fix-from-the-cloud workflow uses that same USB-CDC link to send OTA frames, so you queue an update.
The OTA push times out at "BEGIN."
You can't get new firmware onto a chip whose firmware is too broken to receive it. This post walks through how we built two cooperating OTA paths for the hub's wireless SoC: a USB-CDC OTA pusher that handles the routine 95%, and a hardware-anchored recovery path for the other 5%.
Problem
Field-deployed devices fail in ways your bench rig doesn't. The OTA story has to survive both the routine update, current firmware is healthy, push the new image, and the wedge, the chip enumerates, but the application has stopped servicing the OTA frame parser, or worse, panics inside its main entry point before the parser is even registered.
A first-cut design covers the routine case and dies on the wedge. The rule we settled on: the recovery path must not depend on any code path the current firmware can break. That means OTA-from-host stays as the fast, ordinary path, and there is a separate, parallel "always works" path that bypasses the application entirely.
That second path turned out to need exactly two facts from the carrier board: a USB-CDC bootloader endpoint that's mask-ROM-anchored, and a single GPIO line from the host that can pull the SoC's power rail to ground.
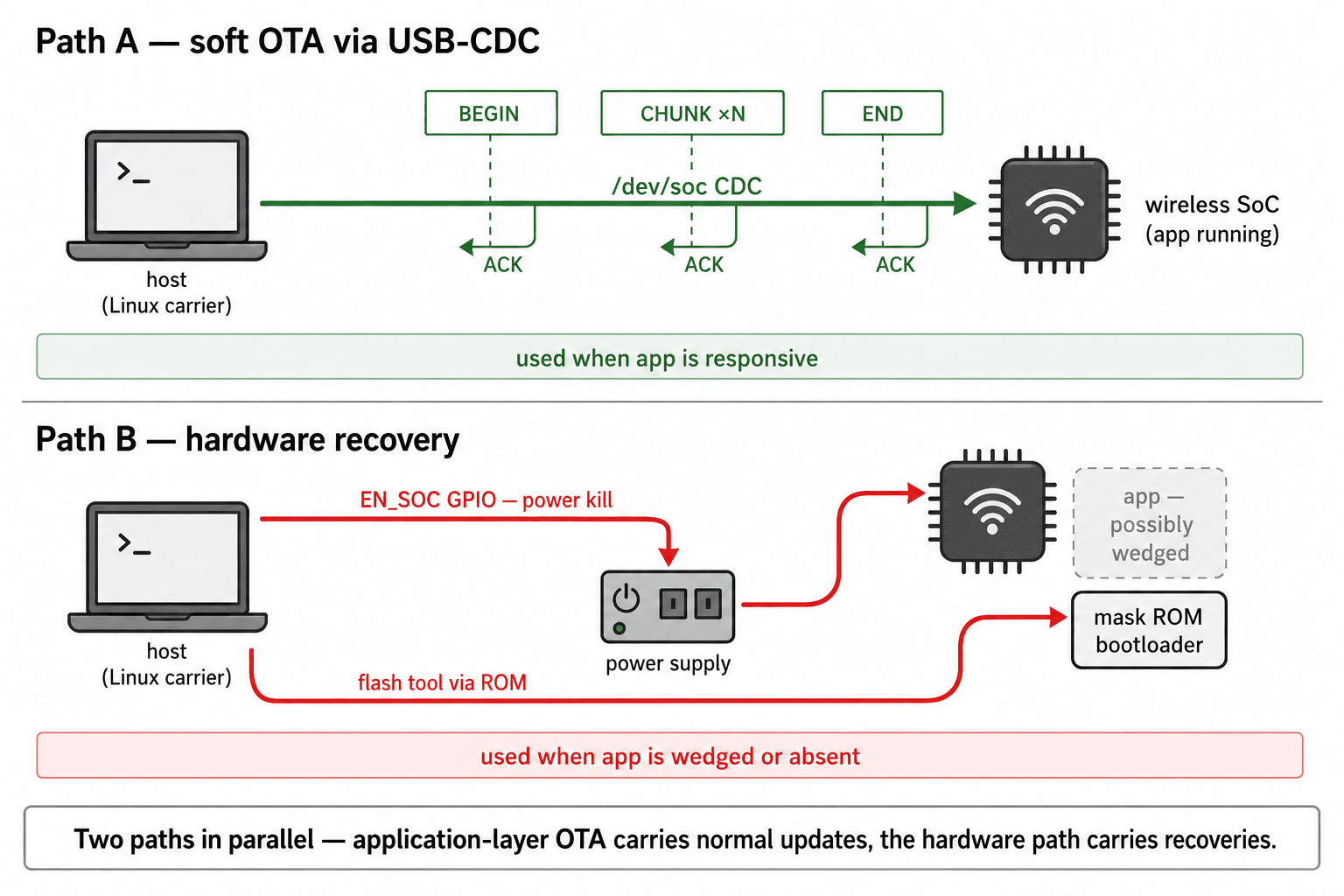
Path A: OTA over the hub's frame protocol
The SoC already speaks a small frame protocol over USB-CDC to the host-side bridge daemon. We added four new frame types, OTA_BEGIN, OTA_CHUNK, OTA_END, OTA_ABORT, so the OTA conversation rides inside the existing wire framing (magic byte, type, length, payload, CRC-8):
host -> chip chip -> host
BEGIN | u32 LE total_size ACK | from=0x30 | status
CHUNK | u32 LE off | bytes ACK | from=0x31 | status | u32 LE next_off
END ACK | from=0x32 | status; reboot in ~1 s
ABORT ACK | from=0x33 | statusThe chip-side state machine uses the SoC SDK's standard OTA partition API:
// ota.c:48 — begin a new OTA
ota_status_t ota_begin(uint32_t total_size)
{
if (s_ota.state != OTA_STATE_IDLE) return STATUS_ALREADY_IN_PROGRESS;
s_ota.partition = platform_ota_next_slot(NULL);
if (s_ota.partition == NULL) return STATUS_NO_PARTITION;
if (platform_ota_begin(s_ota.partition, total_size, &s_ota.handle) != PLATFORM_OK)
return STATUS_BEGIN_FAIL;
s_ota.expected_size = total_size;
s_ota.written = 0;
s_ota.state = OTA_STATE_ACTIVE;
return STATUS_OK;
}platform_ota_next_slot() always picks the inactive slot, so a half-finished OTA can't brick the running image. platform_ota_set_boot() flips a pointer in the OTA state partition, but the bootloader only confirms the new app after it reaches ota_init() and calls platform_ota_confirm_valid(). If the new app crashes earlier, the next reboot rolls back automatically. That rollback safety net is one of the two reasons we don't need the hardware path for ordinary bugs.
The bridge interlock. The bridge daemon holds /dev/soc open with an exclusive read on incoming sensor frames. You can't push OTA frames onto the same TTY while the bridge owns it, bytes interleave at the kernel TTY layer and both ends end up looking at corrupted streams. The pusher stops the bridge first:
# ota-push-usb.py:175 — bridge dance
if bridge_is_loaded() and not args.no_stop_bridge:
bridge_stop()
time.sleep(0.5) # give the bridge time to release /dev/soc
try:
s = serial.Serial(args.port, 115200, timeout=2.0)
ota_push(s, image, args.chunk_size)
finally:
if bridge_was_running:
bridge_start()During the roughly 25 seconds of an OTA push, the bridge is stopped. Sensor frames the SoC emits during that window get dropped, but they're also not arriving, because the chip is busy receiving CHUNK frames. The data path resumes within a second of OTA_END being acknowledged.
Path B: hardware recovery
The recovery path uses two facts about the carrier hardware. The first lives in host boot config: gpio=24=op,dh sets EN_SOC, the wireless SoC power enable pin (HIGH = ON). The host's GPIO24 drives the enable pin of the regulator that powers the SoC. Pulling it LOW for two seconds drains the module's decoupling capacitance and forces a true cold boot, the only way to get the SoC back to a known state when its software is wedged badly enough that even a software reset doesn't get serviced.
The second fact is mask-ROM-anchored: the SoC ships with a USB-CDC bootloader baked into silicon ROM. It can't be flashed away, can't be wedged by application bugs, can't be corrupted by a partial OTA. When the chip enters download mode (triggered via a DTR/RTS sequence on the CDC interface), the ROM bootloader speaks its own protocol on the same /dev/soc endpoint and will write any address in flash.
# run.sh:206 — recover sequence on host
ssh_host "sudo systemctl stop bridge && \
sudo pinctrl set 24 op dl && \ # kill SoC power
sleep 2 && \ # drain caps
sudo pinctrl set 24 op dh && \ # restore power → ROM boot
sleep 1.2 && \ # wait for /dev/soc to re-enumerate
sudo flashtool --chip <target> -p /dev/soc -b 115200 \
--before default-reset --after hard-reset \
write-flash --flash-mode dout --flash-size 4MB --flash-freq 20m \
0x0 /tmp/bootloader.bin \
0x8000 /tmp/partition-table.bin \
0xf000 /tmp/ota_data_initial.bin \
0x20000 /tmp/app.bin && \
sudo systemctl start bridge"The --before default-reset flag tells the flash tool to assert the DTR/RTS sequence that lands the chip in the ROM bootloader's download mode regardless of what the application code intends to do. The application doesn't get a vote; the ROM does.
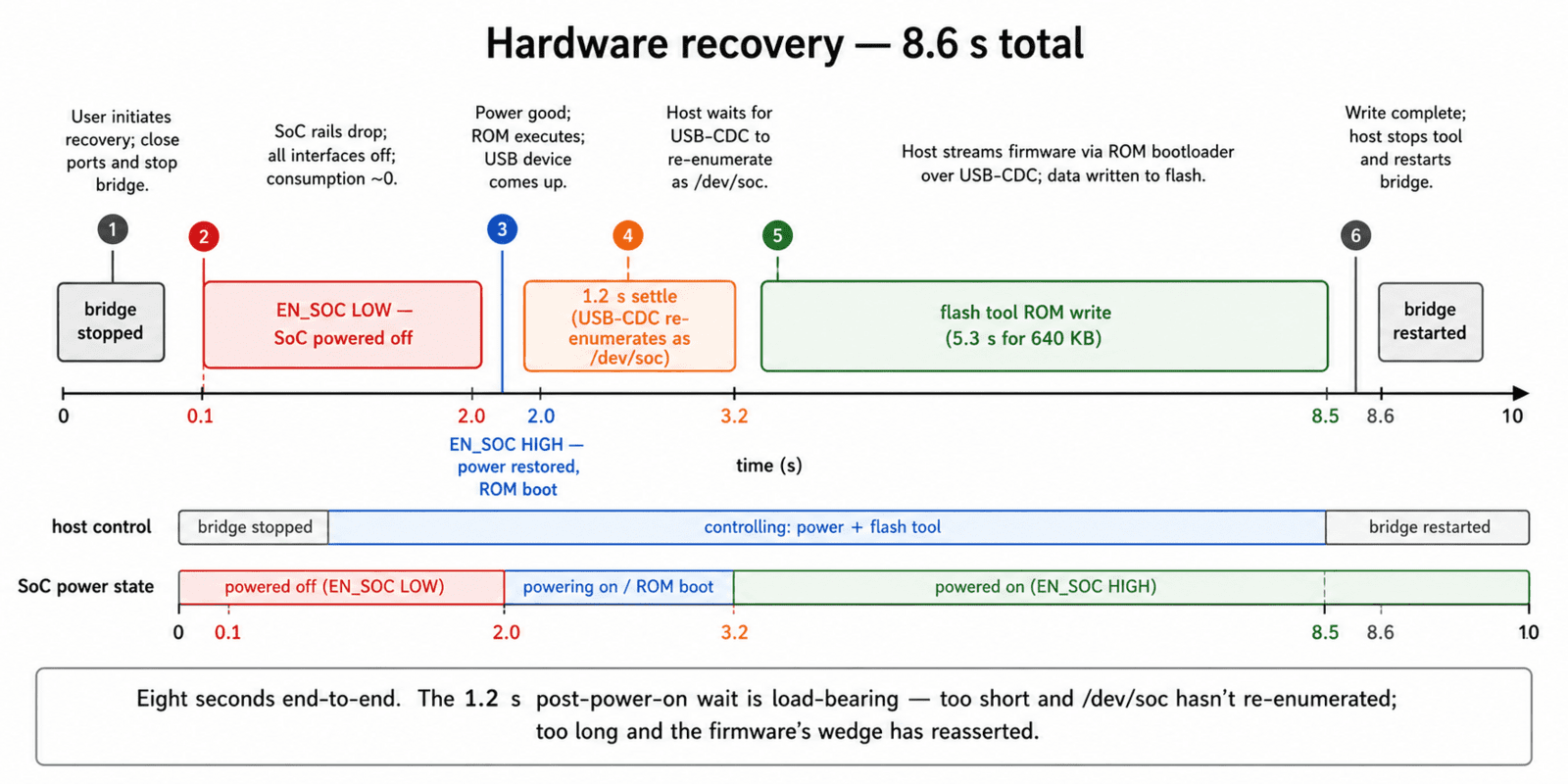
The 1.2 second wait is not arbitrary
When the EN_SOC GPIO returns HIGH, the chip cold-boots into the ROM bootloader. The ROM brings up its USB-CDC endpoint, and udev on the host wires the new ttyACMx device. Measured on a 6.12 Linux kernel on a single-board Linux carrier: USB enumeration completes around 500 ms after power return, and the udev symlink lands around 700-800 ms. We chose 1.2 s as a margin, long enough to win the udev race, short enough to land while the ROM bootloader is still in its "waiting for download command" window before it transitions to running the potentially wedged application firmware.
An earlier version had sleep 0.8. It worked about seven times out of ten on a fresh boot. The other three times the flash tool reported the port was busy or didn't exist. Lengthening to 1.2 s lifted the success rate to every time so far across hundreds of invocations. The wait is doing real work; don't trim it.
Anti-rollback as a soft-path safety net
The chip-side ota_init() is the linchpin of why Path A is safe to use aggressively:
// ota.c:62 — confirm freshly-OTA'd images at boot
if (st == SLOT_PENDING_VERIFY) {
if (platform_ota_confirm_valid() == PLATFORM_OK) {
LOG_INFO(TAG, "marked app valid — rollback cancelled");
}
}OTA_END records the new slot as PENDING_VERIFY. If the freshly-booted app reaches ota_init() it confirms itself; if it never gets there (panic, watchdog, boot failure), the next reboot rolls back to the previous, known-good image automatically. A Path-A push of a fundamentally broken build does not brick the device, it boots the bad image once, fails, reboots to the prior image, and resumes. Path B is reserved for the rarer case where the currently-installed image is wedged.
Results
Across about a hundred OTA cycles on bench hardware and twenty in-field updates: the soft OTA path (Path A) ran roughly 25 seconds end-to-end for a 640 KB image at 32-byte chunks, including the bridge stop/start dance, with zero data corruption incidents and three rollbacks triggered automatically by broken builds, all three booting the prior image without operator intervention. The hardware recovery path (Path B) took about 8.6 seconds from "begin recover" to "bridge running again on new image," used four times. Upstream sensor data during either interruption is buffered by the receiver daemon's SQLite queue, so cloud-side data is delayed up to 30 seconds but not lost.
The split-path design earned its keep when a memory regression in a candidate firmware caused the BLE stack to hold a mutex across a 5-second blocking operation, wedging the frame parser. Path A couldn't push the fix; Path B booted the previous build inside ten seconds and we shipped a debugged version that afternoon. The cost of a bad day is bounded.
Why it matters at Hoomanely
Hoomanely's home hubs go into customer homes. We don't get a service call when one stops working, we get a churn risk. A pure-USB-CDC OTA path would have meant any wedge in shipped firmware required a truck roll or a return-and-replace. The hardware-anchored recovery path means anyone with SSH to a hub can put it back into a known-good image in under 10 seconds, from anywhere in the world.
Key takeaways
The recovery path cannot share substrate with the failure mode, if your OTA pusher needs the application firmware to run, a wedged application means a wedged OTA. Mask-ROM bootloaders are free leverage, most modern SoCs ship one, treat it as your always-available escape hatch. GPIO power-kill beats software reset, since a software restart is the first thing a wedged application can't do. Anti-rollback turns "OTA the wrong image" from a fatal mistake into a reboot. And measure the timing of your hardware recover sequence, don't guess at wait times.