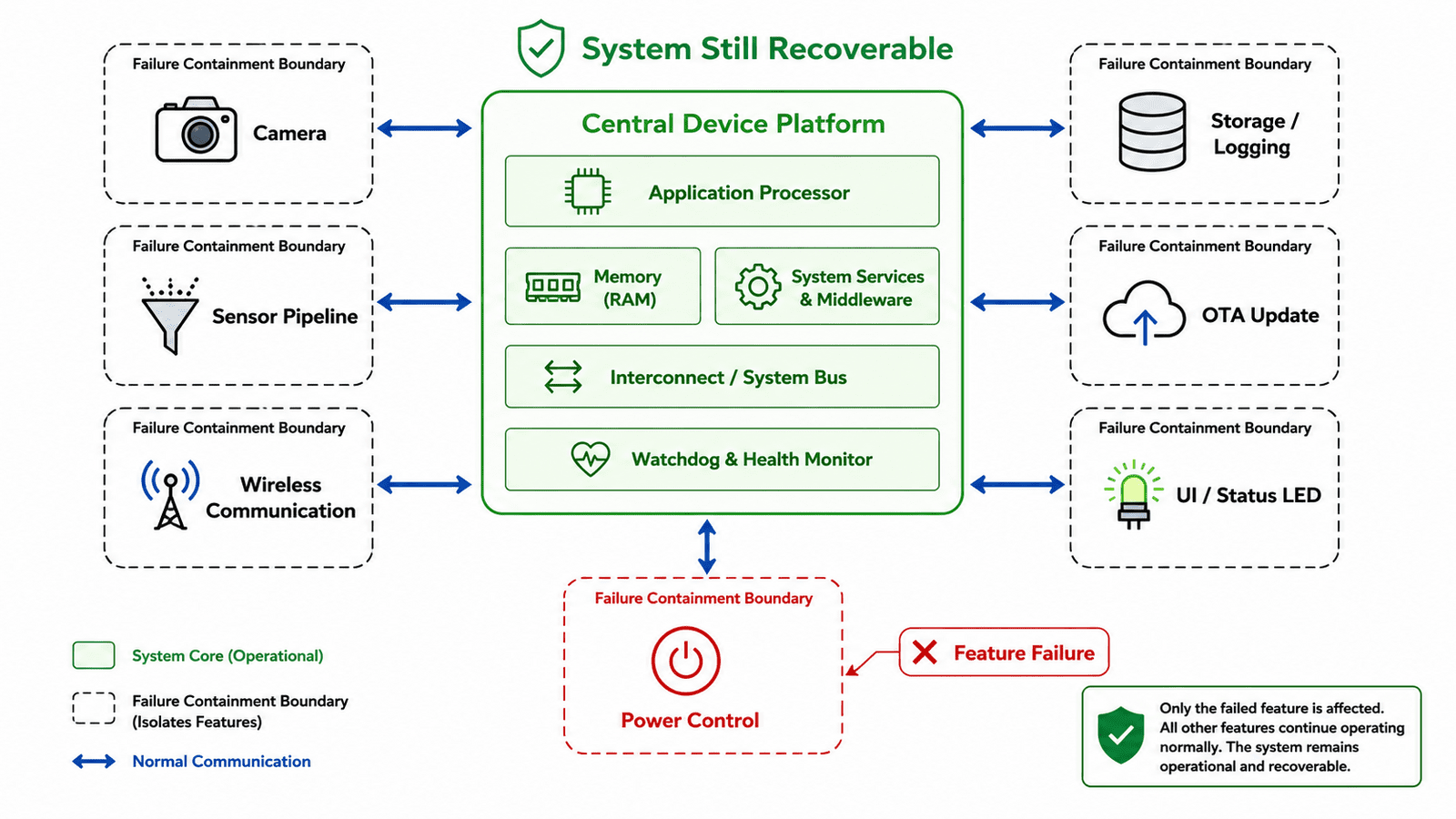
Preventing One Feature From Bricking the Whole Device

Modern embedded products are no longer single-purpose machines. A connected edge device may capture images, process sensor data, communicate over wireless or wired interfaces, store logs, run OTA updates, manage power states, control LEDs, detect proximity, and coordinate with other boards, all inside one compact system.
Each feature may be valid by itself. The camera works. The sensor pipeline works. The communication stack works. The OTA mechanism works. The power management logic works. But the real question is different: can one broken feature take down the entire device? That is where product-grade embedded design begins.
At Hoomanely, this question comes up often because our systems are built as long-running, field-deployed products where multiple subsystems must coexist reliably. A feature may fail, a peripheral may hang, a firmware module may behave unexpectedly, or a power domain may become unstable. But the device shouldn't become unrecoverable because one part of the system failed. A good embedded product isn't one where nothing ever goes wrong, it's one where failure stays contained.
A feature failure should not become a system failure
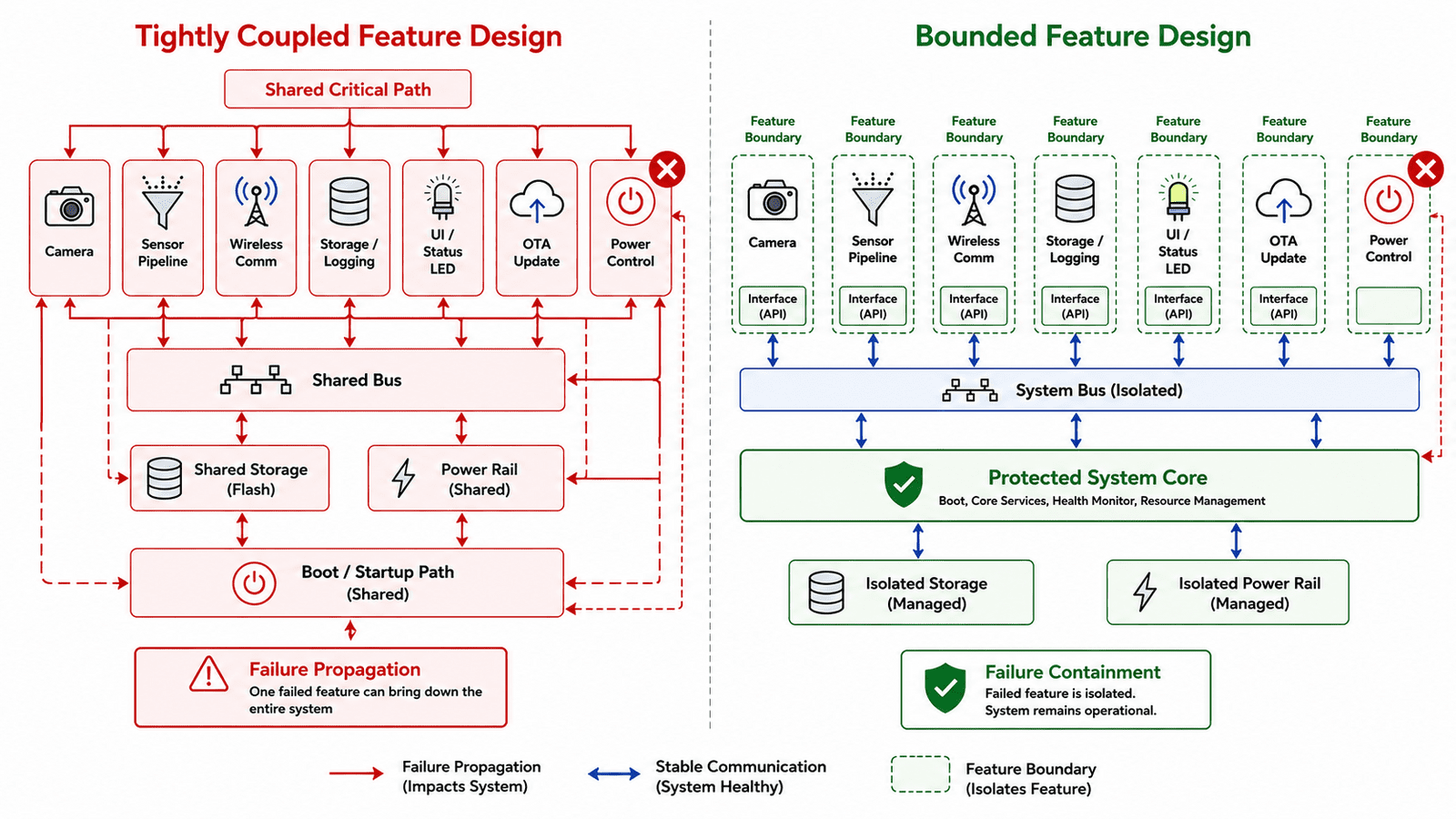
One of the most common architectural mistakes is allowing every feature to share the same critical path. A new feature gets added, it needs a sensor, a driver, a task, a power rail, a memory buffer, a communication interface, and some persistent storage. It works during development, so it gets integrated deeply into the main application flow. Over time this pattern repeats, until eventually one feature can block boot, stall the main loop, exhaust memory, overload a rail, corrupt shared storage, or prevent firmware updates.
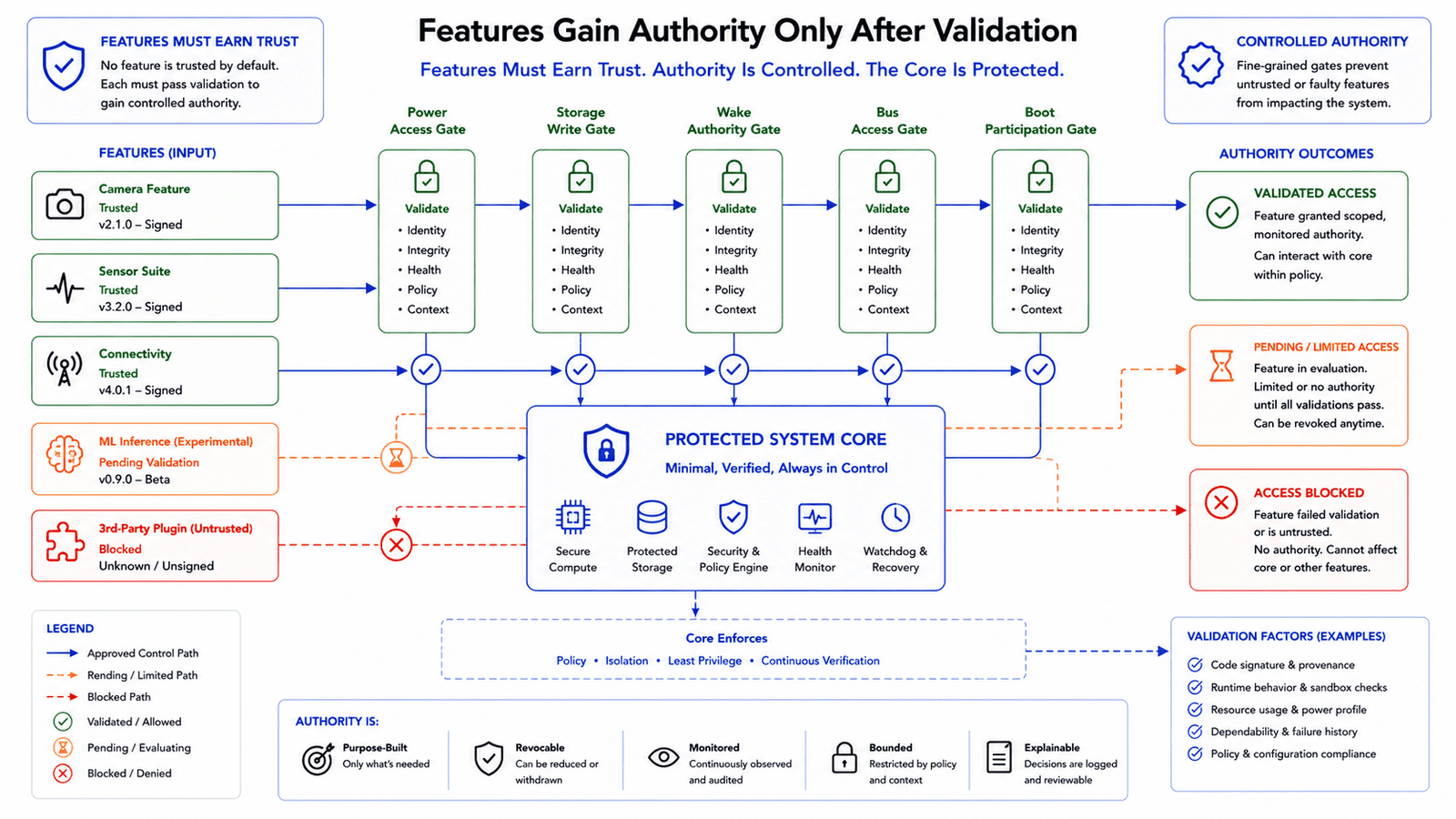
That's how a feature becomes dangerous, not because the feature itself is bad, but because the system gives it too much authority. A camera feature shouldn't be able to permanently block the device from booting. A sensor driver shouldn't be able to prevent recovery mode. A wireless stack shouldn't be able to corrupt the only working firmware image. A UI feature shouldn't be able to disable debug access. A logging feature shouldn't be able to fill storage until the system becomes unusable. The core design principle is simple: every feature must have a boundary. Without boundaries, features slowly become system-level risks.
Bricking usually comes from shared assumptions
When people think about bricking a device, they usually imagine a failed firmware update. That's one type, but not the only one. A device can become practically bricked even when firmware is technically still present, booting but immediately crashing because a peripheral never responds, entering a watchdog loop because a task blocks forever, resetting repeatedly because one feature enables a high-current load too early, failing to connect because a corrupted configuration file prevents networking, or never reaching OTA recovery because the boot sequence waits indefinitely for a non-critical sensor.
In all these cases, the device isn't dead physically, but from a user or field-support perspective, it's unavailable. This happens when the system assumes every feature will behave correctly every time. Real products can't make that assumption. A robust product must assume peripherals may be missing, sensors may return invalid data, storage may become full or corrupted, network connectivity may fail, power rails may droop, firmware modules may crash, and user-triggered flows may happen at inconvenient times. The system should continue to provide a recovery path even when these assumptions fail.
Boot must belong to the system, not to features
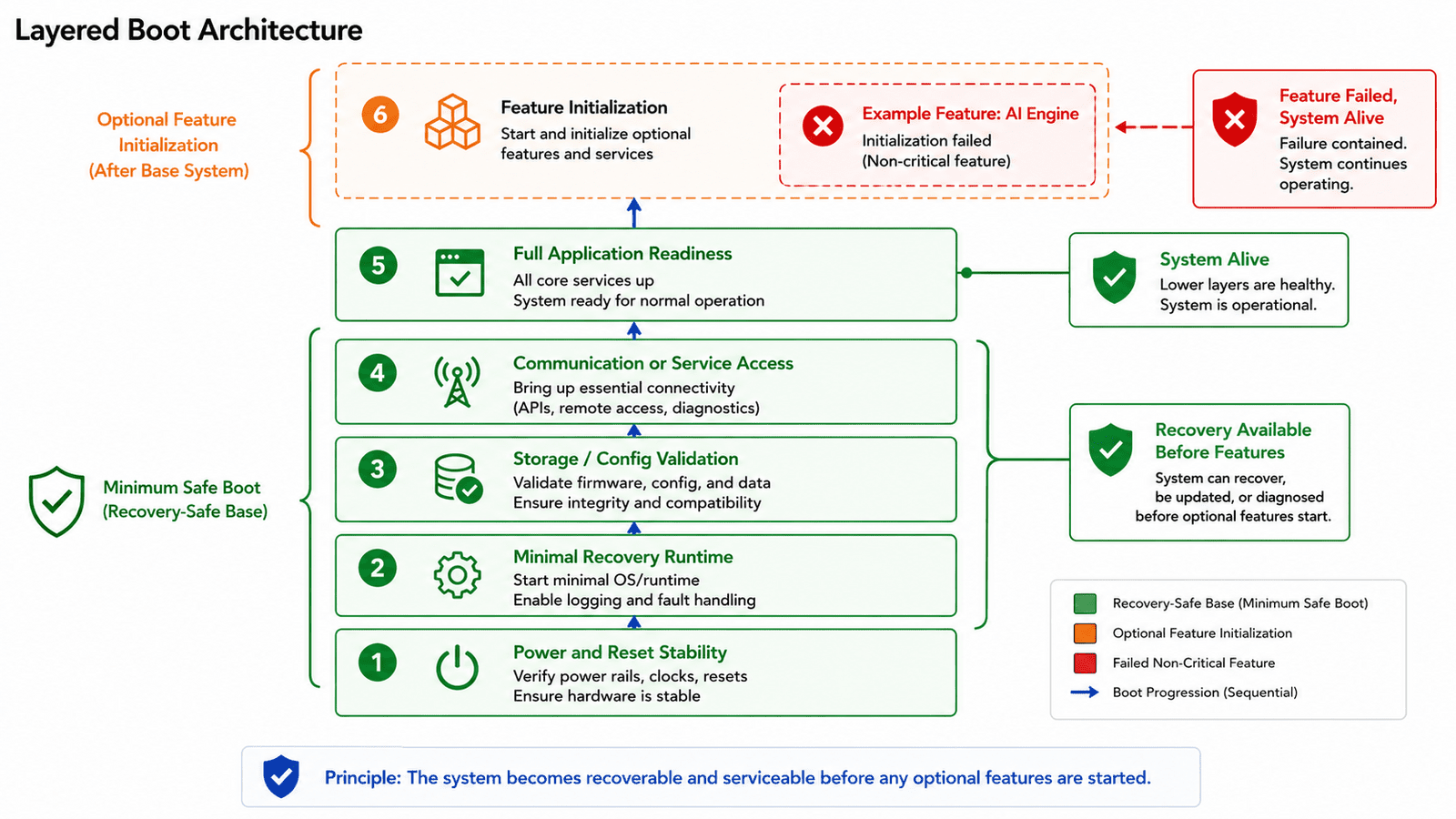
The boot path is the most important part of device recoverability. If a feature can block boot, that feature has too much control. During boot, the system should bring up only what's required to establish a stable, recoverable platform, everything else should be treated as optional until proven healthy.
A common mistake is initializing every subsystem during early boot because it feels convenient. This works beautifully when every subsystem behaves, but if one non-critical sensor fails, boot may stall. If a bus hangs, the entire device may appear dead. If a configuration file is corrupted, the application may crash before enabling recovery mechanisms. At Hoomanely, we prefer a more layered boot philosophy:
- First establish a minimum safe state where power is stable
- The processor is alive
- Reset cause is understood
- Debug or recovery access is available
- Firmware can make decisions
Only after that should higher-level features start.
A practical boot hierarchy: establish power and reset stability, start the minimum runtime required for recovery, validate storage and configuration, bring up communication or service access where possible, initialize sensors and feature modules, then mark individual features healthy or degraded. This ensures optional feature failure doesn't prevent the system from becoming recoverable, the device should be able to say "this feature failed, but the system is alive." That difference matters.
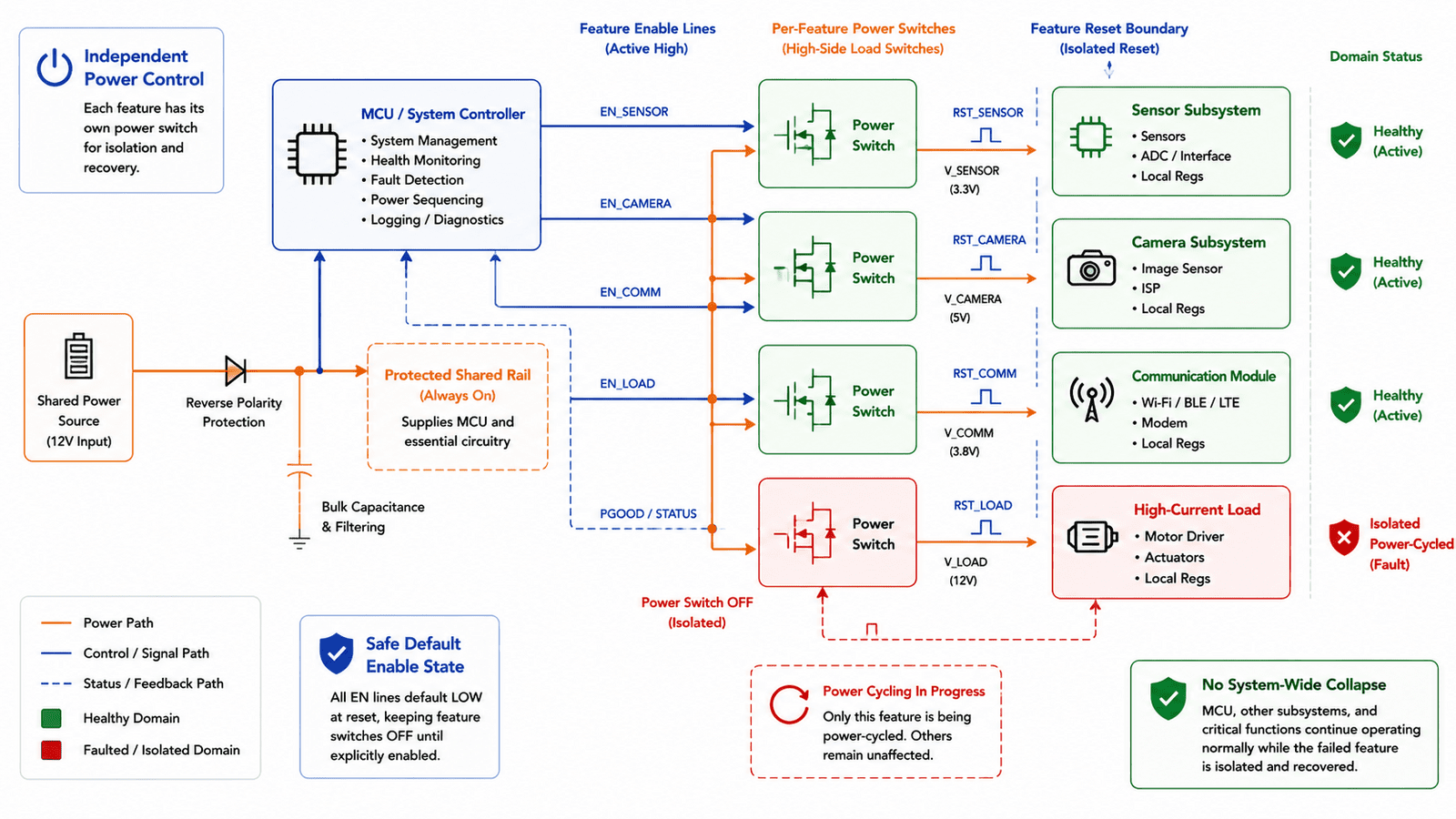
Feature isolation starts in hardware
Firmware isolation is important, but hardware isolation is just as important. If a feature controls a high-current load, shared rail, wake source, reset line, or bus interface, it can affect much more than its own function. An illumination feature may pull down a shared rail if enabled at the wrong time. A sensor connected to a shared I2C bus may hold SDA low and block other devices. A level shifter may back-power a disabled domain. A peripheral may keep an interrupt line asserted and prevent sleep. A communication transceiver may remain in an unexpected state and disturb bus behavior.
These aren't software-only problems, they're architecture problems. Hardware must define clear containment boundaries:
- A feature power rail should be switchable or isolatable where necessary
- A noisy or high-load feature shouldn't share sensitive rails without proper isolation
- A hung peripheral shouldn't permanently lock the only control bus
- A resettable subsystem should have a way to recover independently
- A feature enable line should fail to a safe state
- A missing peripheral shouldn't create an undefined electrical condition
The goal isn't to make every feature completely independent, that would be expensive and impractical. It's to prevent one feature from gaining uncontrolled influence over the full system.
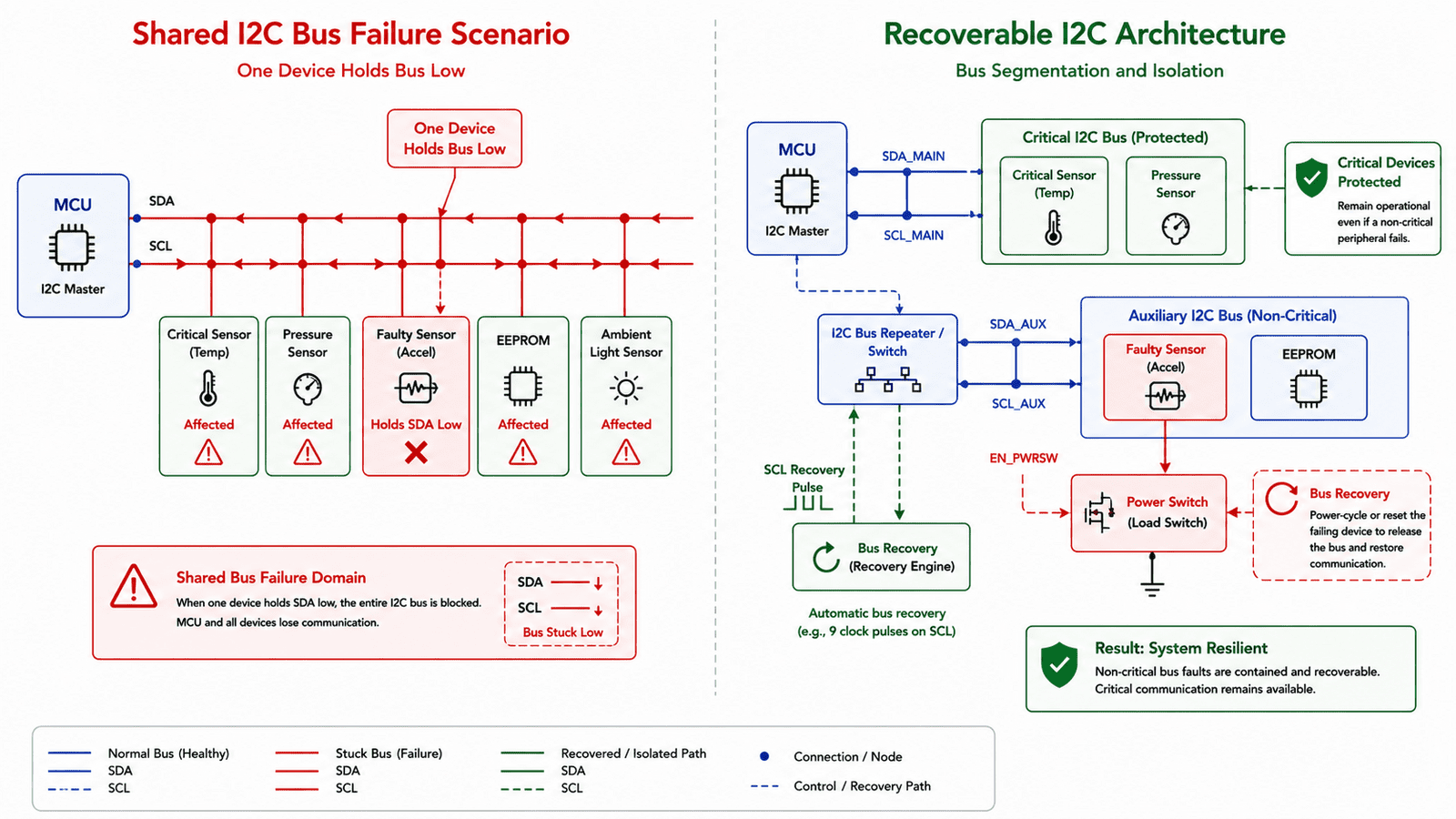
Shared buses need failure containment
Shared communication buses are one of the most common places where one feature can affect many others. I2C is a classic example, it's simple, widely used, and convenient, but one misbehaving device can hold the bus low and block communication for every other device on that bus. The same applies to SPI chip-select mistakes, UART framing issues, CAN transceiver state problems, shared interrupt lines, and shared reset signals.
A shared bus should be treated as a shared failure domain, which means the design should include a recovery strategy. Can the bus be reset? Can the failing device be power-cycled independently? Can the firmware detect a stuck bus? Can the system continue operating in degraded mode? Can critical devices be separated from experimental or non-critical devices? In early prototypes it's tempting to connect many peripherals to one shared bus to save pins and routing effort, in production systems that convenience can become a reliability risk. The question is not only "can all devices communicate?" It is also "what happens when one device stops communicating correctly?"
Storage must never be a single point of failure
Persistent storage is another common source of device bricking. A feature may write logs, store images, cache metadata, save configuration, or maintain local state. If storage isn't controlled carefully, a feature can consume all available space, corrupt shared files, or leave the system unable to boot cleanly, especially dangerous when configuration, logs, OTA metadata, and runtime data share the same storage region without strict boundaries.
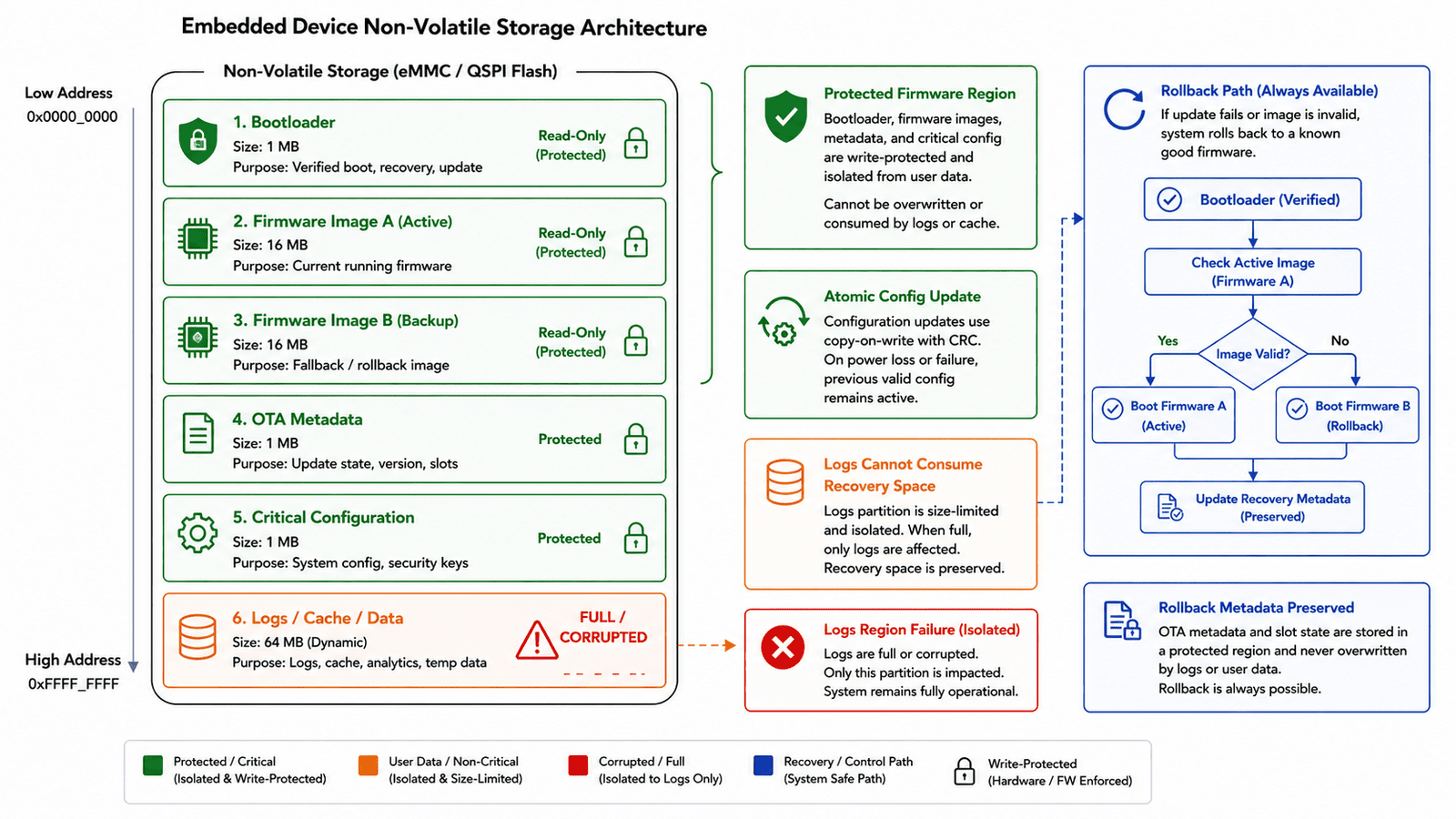
A good storage architecture treats persistence as a controlled system resource, not an unlimited feature convenience:
- Separating critical configuration from bulk logs
- Limiting log growth
- Using atomic writes for important state
- Validating configuration before applying it
- Maintaining known-good defaults
- Preserving OTA rollback metadata
- Ensuring recovery mode doesn't depend on writable feature data
A logging feature should never brick the device by filling storage. A corrupted feature cache should never prevent boot. A failed write should never destroy the last known-good configuration.
OTA must be protected from feature complexity
OTA update systems deserve special protection. A device that can update itself can recover from many field issues, but if the OTA path depends too heavily on normal application behavior, it can become fragile. If OTA requires the full application to boot, all feature services to initialize, network configuration to load correctly, storage to be fully healthy, and no watchdog loops to occur, then OTA isn't truly a recovery mechanism, it's just another feature.
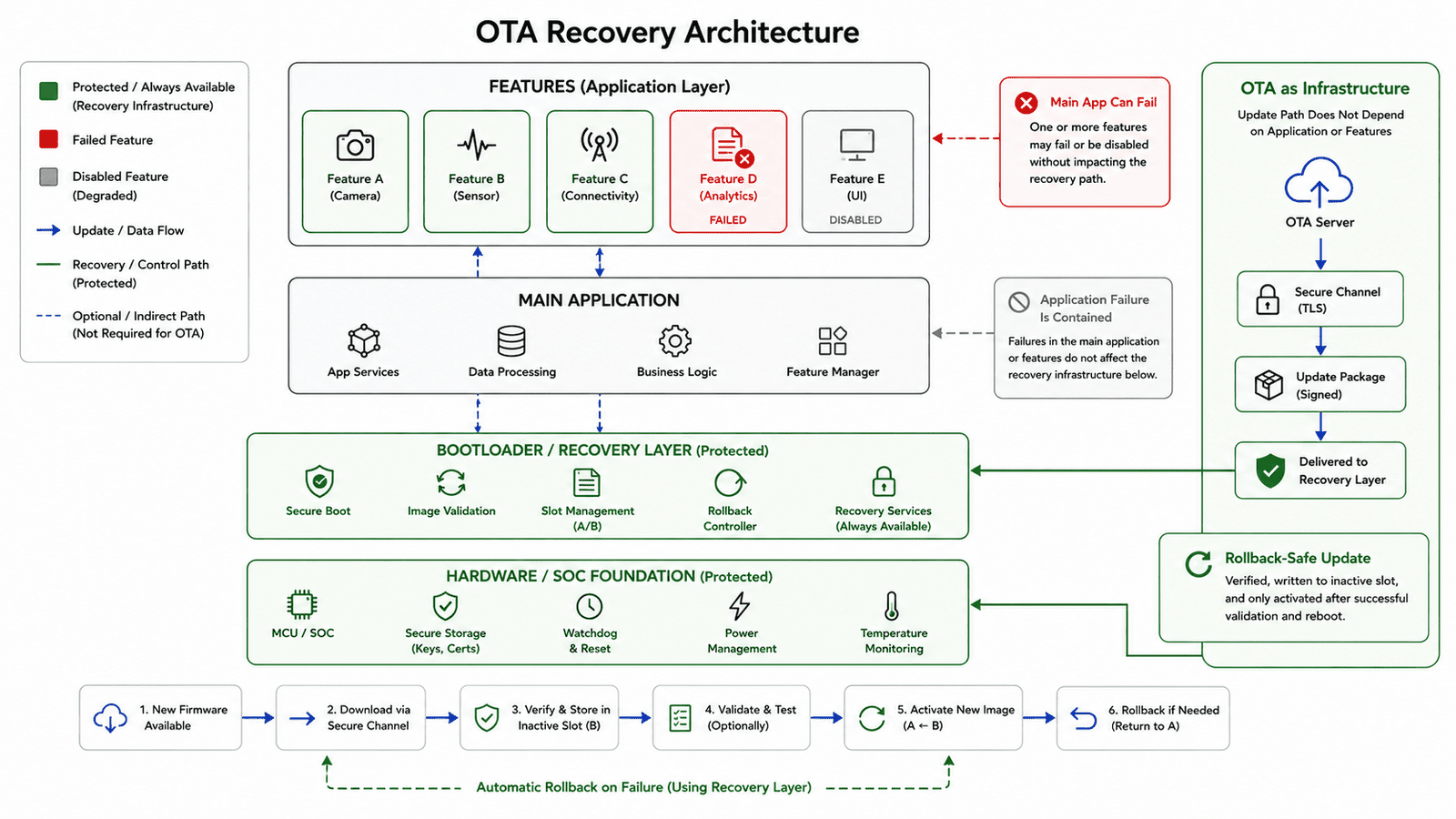
A robust OTA architecture should be closer to infrastructure than application logic, protected from ordinary feature failures as much as possible. This usually means a bootloader or recovery path that remains independent, firmware image validation, rollback support, separation between update metadata and application logs, safe handling of interrupted updates, and a way to enter recovery even when the main application is unhealthy. The most dangerous OTA failure isn't simply a failed download, it's a system that loses the ability to update because another feature broke first.
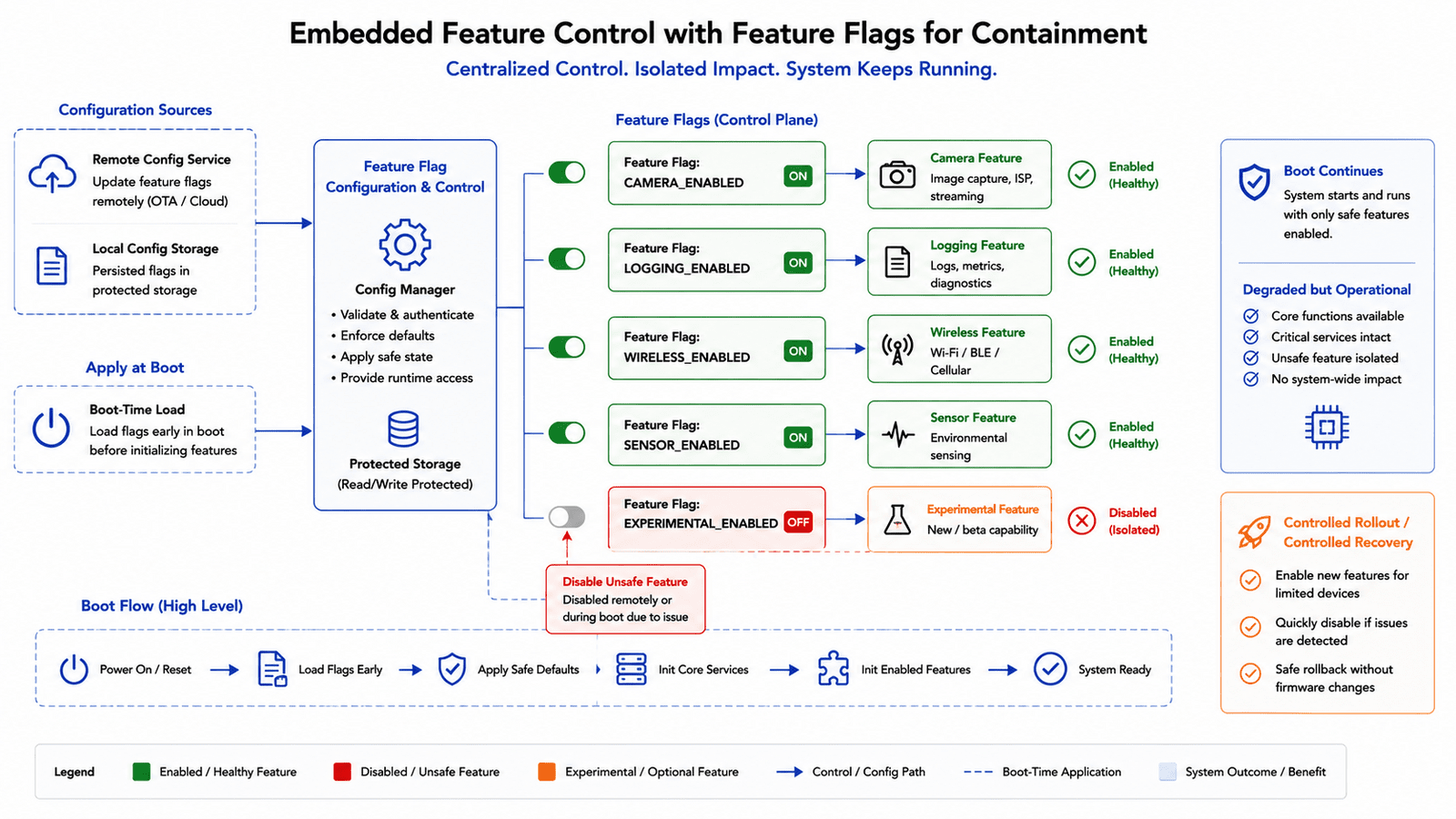
Feature flags are not just product tools
In cloud software, feature flags are often used for controlled rollouts. In embedded systems, they can also be used for containment, allowing a device or fleet to disable a problematic feature without replacing the whole firmware image immediately. This is extremely valuable when a feature behaves unexpectedly under field conditions not reproduced during validation.
But feature flags must be designed carefully. If a flag is stored in a corrupted configuration region, depends on the failing feature itself, or is applied too late in the boot process, it may not help. A good embedded feature flag system should be available early, simple to evaluate, and safe by default, letting the system boot and decide "this feature is disabled until proven safe." This is especially useful for features that interact with power, sensors, storage, or communications. Feature flags aren't a substitute for good architecture, but they're a powerful layer of operational safety.
Watchdogs should recover the system, not hide the problem
Watchdogs are often used as a final line of defense, if the system hangs, the watchdog resets it. That's necessary, but not sufficient. A watchdog that simply resets the device may create an endless reboot loop if the same feature fails again immediately after boot.
A better watchdog strategy preserves context and supports escalation: if the device crashes once during normal operation, reboot normally. If it crashes repeatedly during the same feature initialization, skip that feature on the next boot. If failures continue, enter safe mode. If safe mode starts successfully, keep communication and OTA available. This turns the watchdog from a blind reset tool into part of a recovery policy, the system learns enough from repeated failures to avoid repeating the same mistake indefinitely. A practical recovery ladder:
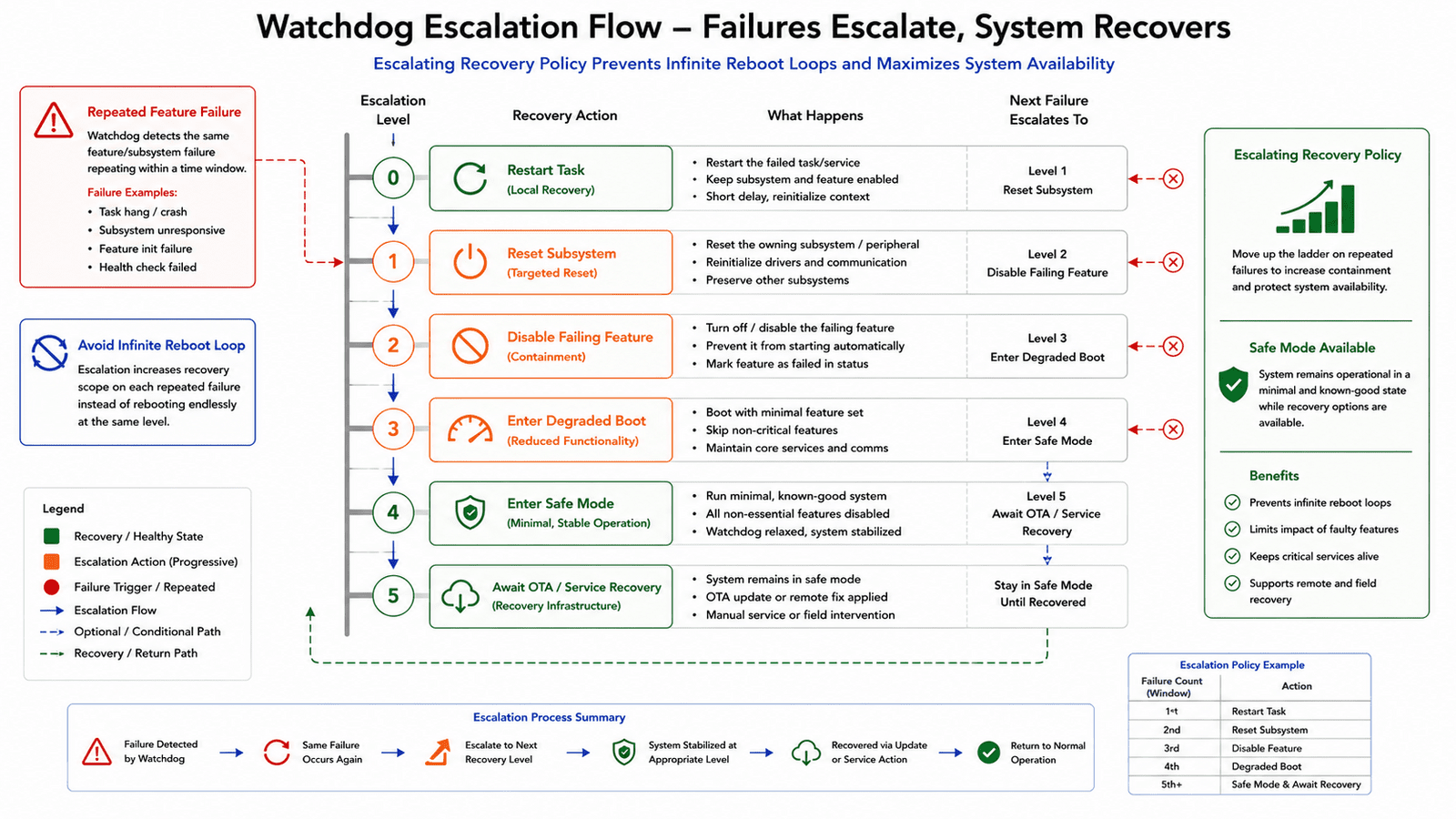
- First failure restarts the affected task
- Repeated feature failure disables that feature temporarily
- Repeated system reset enters degraded boot
- Continued instability enters recovery mode
- Recovery availability waits for remote update or service action
Safe mode should be a first-class architecture
Safe mode is one of the most valuable patterns in embedded product design, the system state where the device intentionally starts with minimum functionality to preserve recoverability. It doesn't need to support every product feature, only enough capability to inspect, configure, update, or service the device.
A useful safe mode includes stable power initialization, basic processor runtime, minimal communication path, reset and fault reporting, OTA or service update support, configuration reset, and enough diagnostics to identify failed subsystems, while avoiding non-essential sensors, high-current loads, advanced processing, unnecessary storage writes, and experimental feature paths. Safe mode isn't a failure, it's a controlled recovery state. A device that enters safe mode is still alive. A device trapped before safe mode is not.
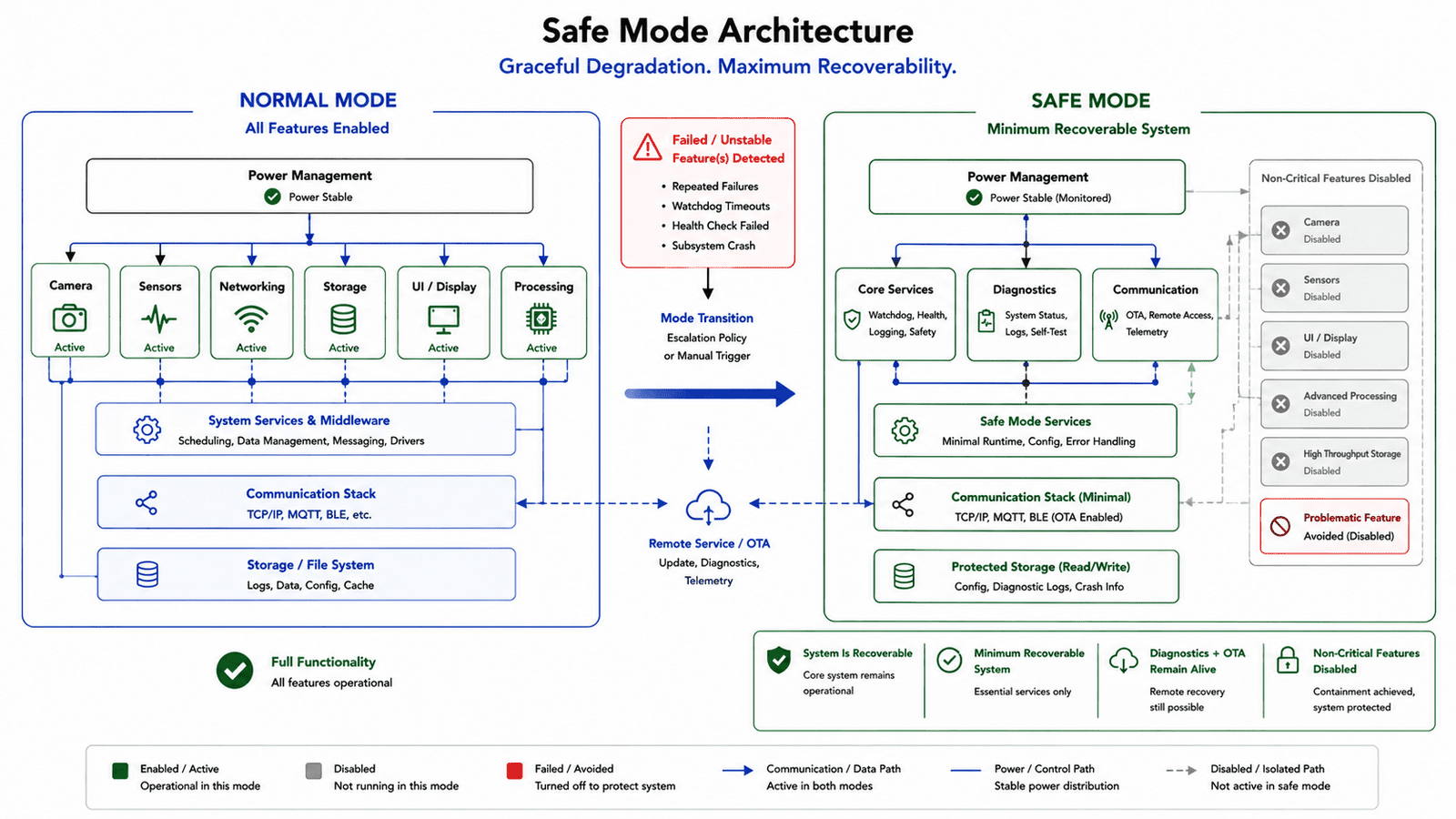
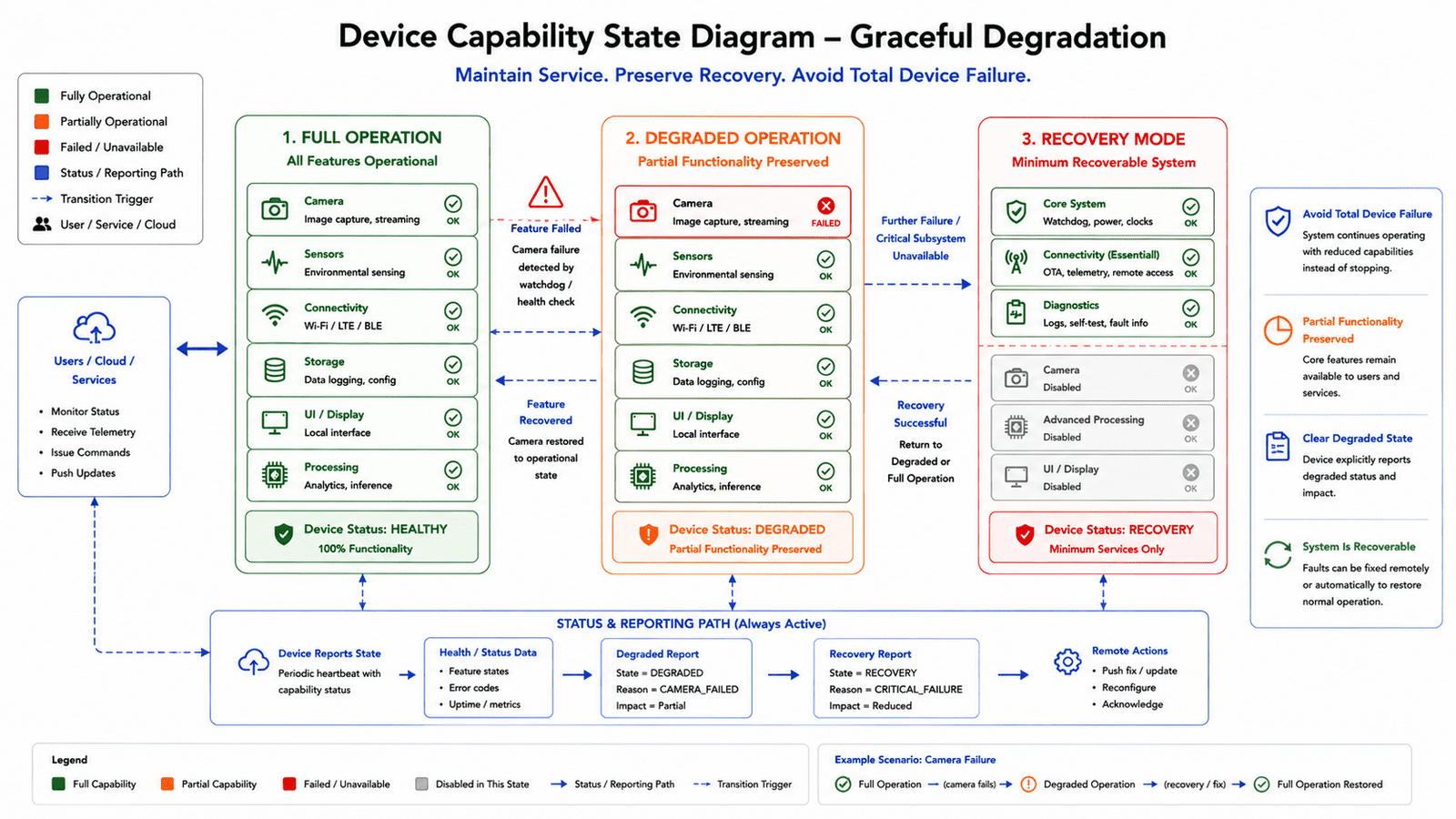
Degraded operation is better than total failure
Not every feature failure should produce a full device failure. If a non-critical sensor fails, the device may still provide partial value. If a camera fails, other sensing modes may continue. If wireless is unavailable, local buffering may continue. If storage is limited, the system may reduce logging rather than crash.
This requires firmware and product architecture to understand degraded states, classifying failures as critical failures requiring recovery, feature failures disabling only one capability, temporary failures that may retry, environmental failures requiring waiting, and configuration failures that can fall back to defaults. The user doesn't care whether a subsystem driver returned a timeout, they care whether the device is usable, recoverable, and trustworthy. A degraded device with clear behavior is far better than a device that silently bricks itself trying to maintain full functionality.
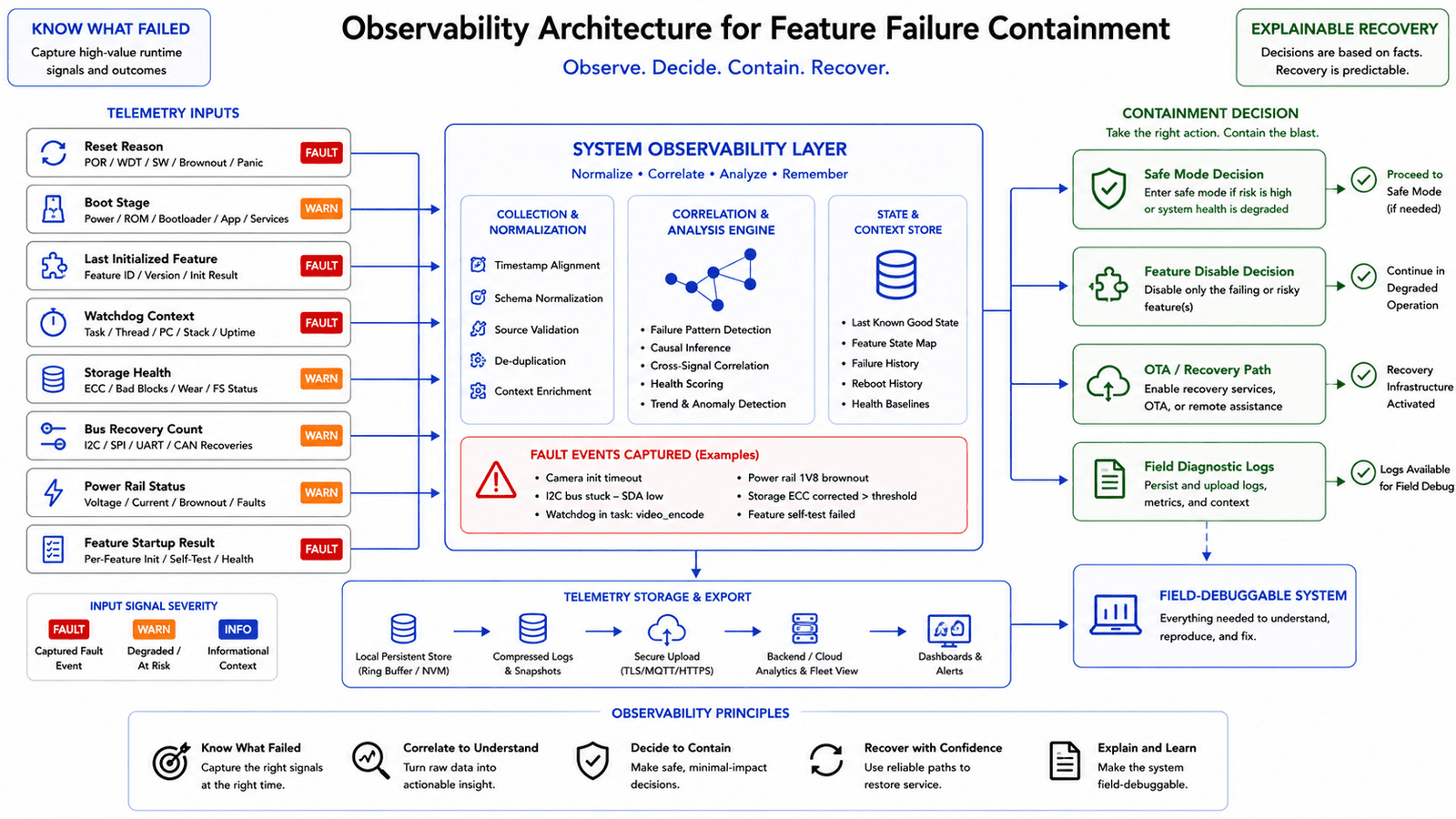
Observability makes containment practical
Failure containment only works if the system can identify what failed. If every failure looks like a generic reboot, the system can't make intelligent recovery decisions. This is why observability must be part of the architecture:
- Reset reason
- Boot stage
- Last successful subsystem initialization
- Watchdog context
- Rail-good status
- Storage health
- Bus recovery count
- Feature startup result
- Safe-mode entry reason
Even a small amount of retained state can dramatically improve diagnosis. Knowing that a device failed three times immediately after enabling a specific feature is far more useful than knowing only that a watchdog reset occurred.
Final thoughts
Preventing one feature from bricking the whole device isn't a single mechanism, it's a design philosophy. It requires hardware boundaries, firmware supervision, safe boot paths, recoverable storage, protected OTA, meaningful watchdog behavior, feature flags, degraded operation, and system observability. Most importantly, it requires accepting that features will fail: a sensor may hang, a bus may lock, a file may corrupt, a rail may dip, a firmware module may crash, a new feature may behave differently in the field than it did in the lab. The system should be ready for that.
At Hoomanely, the goal isn't to build devices that depend on perfect behavior from every subsystem, it's to build devices that remain recoverable when one subsystem behaves badly. A feature is valuable only if it improves the product without threatening the product. And the strongest embedded systems aren't the ones where every feature is tightly connected, they're the ones where every feature is allowed to fail without taking the whole device down.