Progressive Intelligence: Evolving AI Insights

User-facing AI rarely gets a “perfect” moment. Users act now, while context arrives later: uploads finish after the screen has moved on, background sync dribbles in, retrieval indexes lag behind writes, and models improve between releases. If you treat an AI insight as a single final answer, you end up with painful tradeoffs—either you block the experience waiting for completeness, or you ship something fast and quietly overwrite it later.
Progressive intelligence is the calmer alternative. You publish a conservative, low-risk insight immediately, then improve it transparently as more evidence becomes available—without confusing users or rewriting history. This isn’t a prompting trick. It’s an architectural stance: asynchronous enrichment pipelines, confidence-aware update rules, deterministic timelines, and stability-first UI contracts that make improvements feel like progress, not flip-flopping.
The shift: Insights are living artifacts, not final answers
A progressive insight has a lifecycle. It starts small and safe, then gains depth as the system learns more. The point isn’t “be perfect instantly,” it’s “be dependable immediately, and smarter over time.”
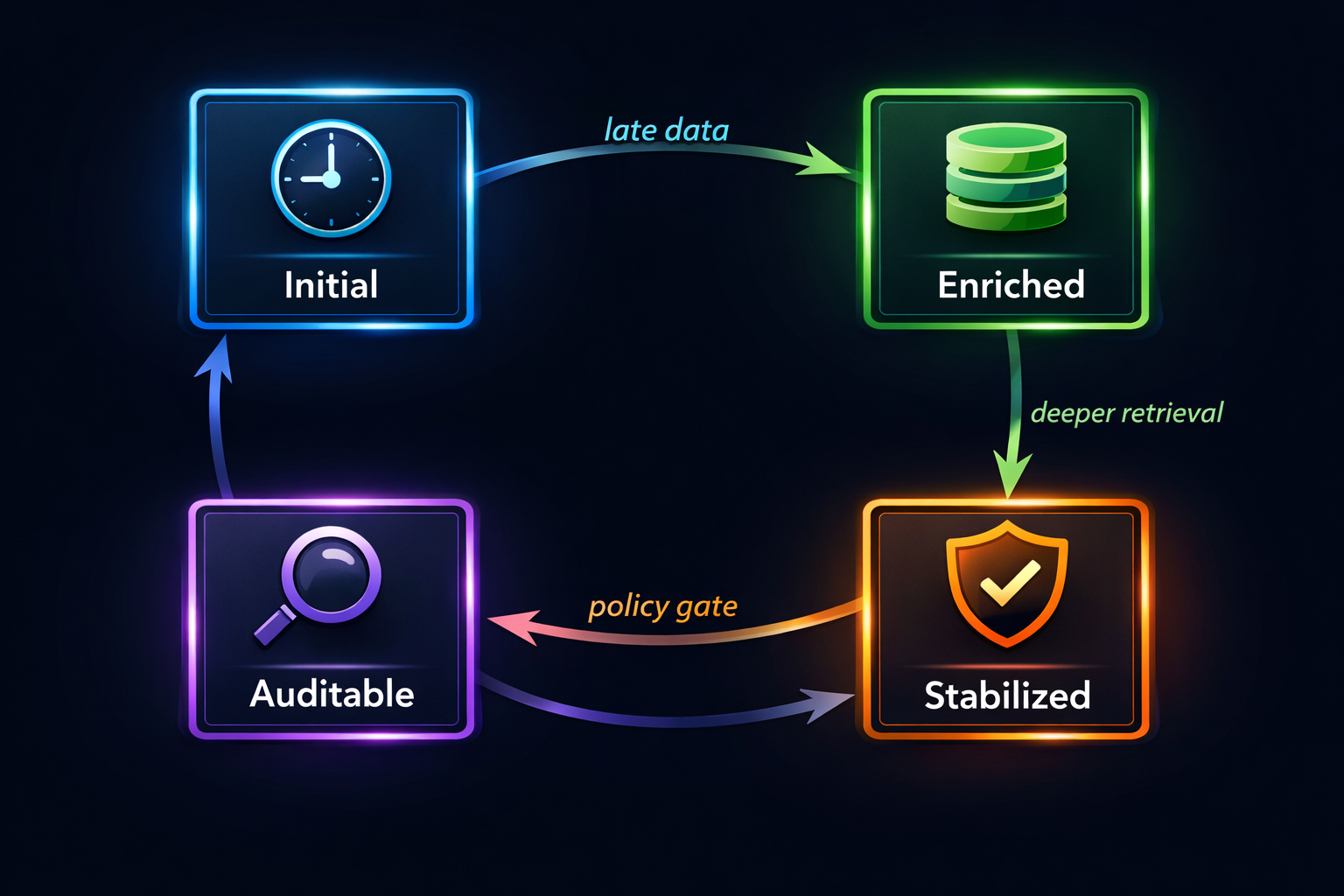
In practice, the lifecycle looks like this:
- Initial: fast, conservative, minimal dependencies
- Enriched: async, deeper retrieval, heavier inference
- Stabilized: bounded updates, fewer visible changes
- Auditable: traceable evidence + “why did it change?”
The last two are what separate a mature system from a demo. Users don’t mind systems that improve. They mind systems that change without warning
Why progressive insights matter in real products
Incomplete context isn’t rare. It’s the default operating condition.
- Late arrivals: telemetry uploads, mobile background sync, delayed sensor packets
- Evolving retrieval: re-indexing, embedding upgrades, backfills, filter changes
- Model evolution: better classifiers, routing updates, new safety policies
- Multi-stage reasoning: cheap heuristic now, expensive inference later
- Cross-signal joins: the real meaning appears only once multiple signals converge
If you don’t design for this, you get one of three failure modes:
- Blocked UX (slow, frustrating, “loading” everywhere)
- Thrash UX (insights flip-flop as late context arrives)
- Rewritten history (the past silently changes; trust erodes)
Progressive intelligence is how you stay fast and honest: ship safe now, enrich later, update with rules.
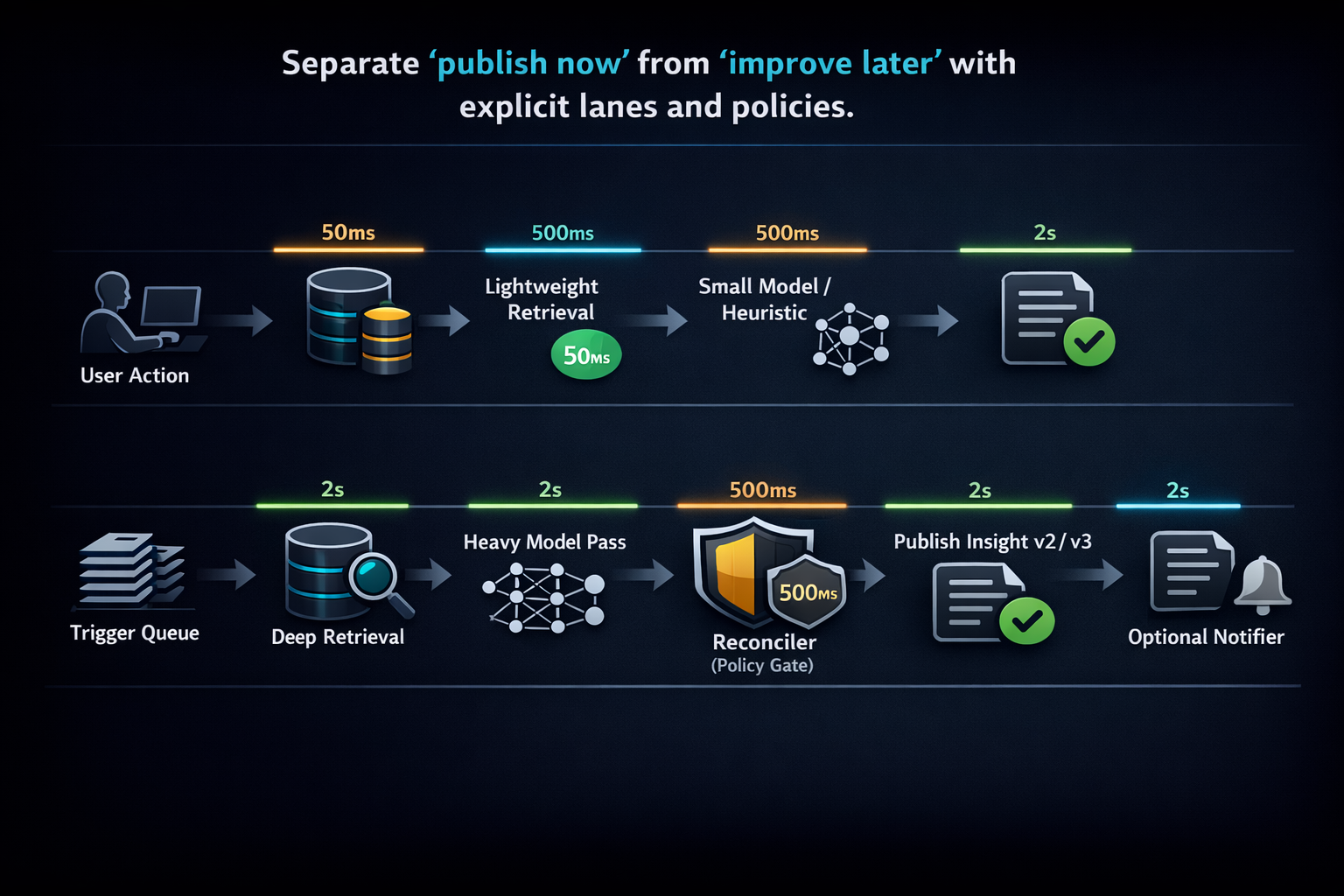
The architecture: separate “publish” from “perfect”
The simplest reliable pattern is a two-lane system:
Lane A: Fast path (Publish)
This is the lane that serves the moment. It’s optimized for low latency and safe defaults. It uses tight timeouts, partial retrieval, cached context, and lightweight models—anything that prevents the UI from waiting.
Lane B: Enrichment path (Improve)
This lane does the heavier work. It runs after the user’s action, joins late-arriving signals, performs deeper retrieval, and uses costlier inference. Most importantly: it doesn’t “edit” the past in-place. It creates an improved version and hands it to the UI under a stability contract.
A good way to think of it: Lane A protects experience. Lane B protects truth.
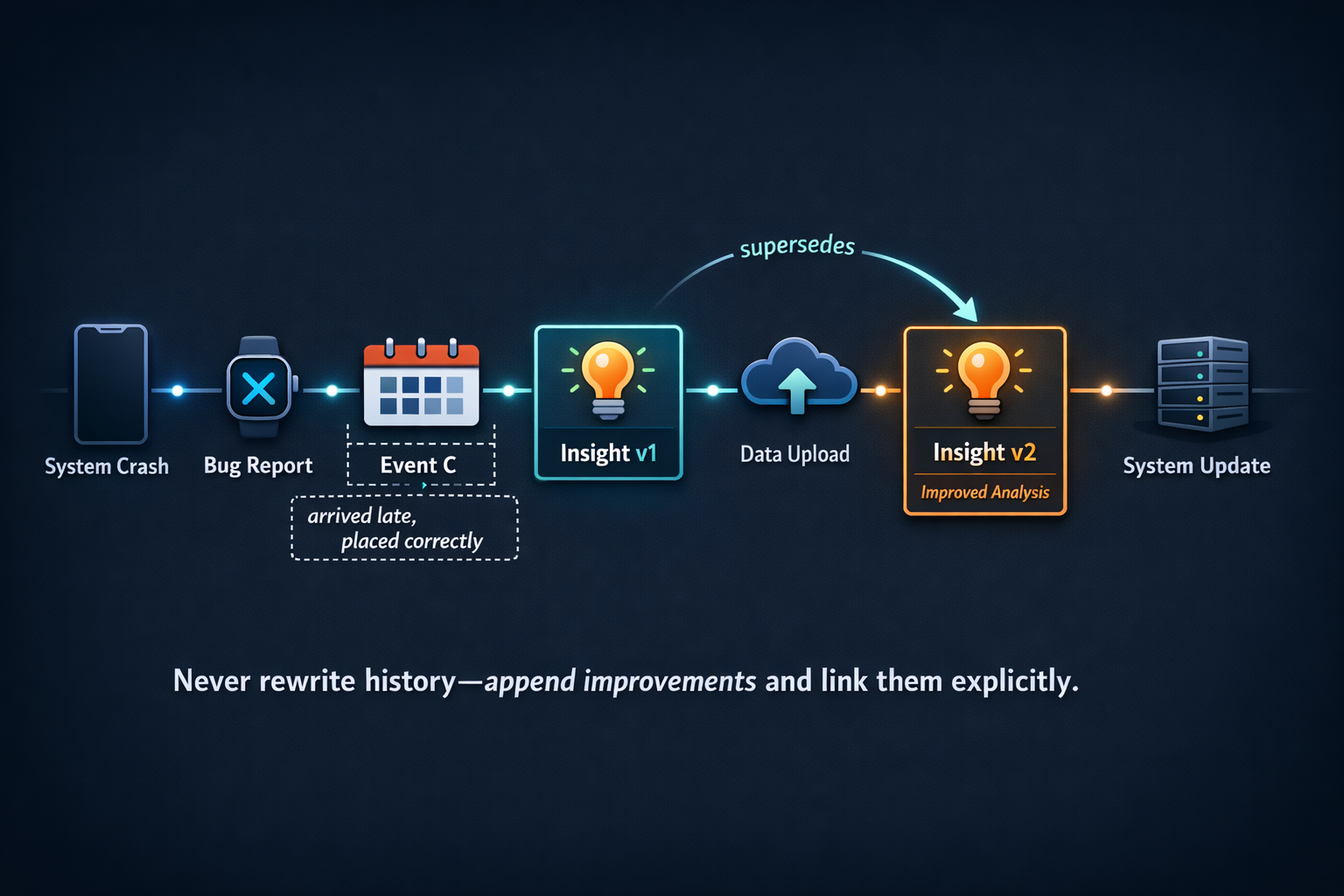
Deterministic timelines: never rewrite, always supersede
If insights appear in a feed or timeline, your ordering and update semantics matter as much as accuracy. Users remember what they saw. If yesterday’s card silently changes, it feels like the system is unreliable—even when the new output is objectively better.
A stability-first approach is append-only with supersession:
- The original insight is preserved as what you knew then.
- The improved insight references the prior one (“supersedes”).
- The UI can render it as an update (“Refined”, “More context added”) without pretending the earlier output never happened.
This avoids the trap of “latest = most recently processed,” which is not how humans interpret narrative. Humans care about what happened when—not when your pipeline caught up.
Confidence-aware updates: rules that prevent flip-flops
Progressive systems feel trustworthy when updates follow constraints. Without constraints, enrichment can look like indecision.
A pragmatic set of rules that works well in production:
1) Confidence as bands, not a raw number
Users don’t benefit from “0.73 vs 0.78.” They understand Low / Medium / High. Bands also let you design language consistently.
- Low: cautious phrasing, “needs more context”
- Medium: actionable guidance, still non-alarming
- High: stronger recommendation, clearer rationale
2) Hysteresis for state changes
Don’t let an insight bounce between bands because of small evidence shifts. Require stronger evidence to downgrade than to upgrade, or require the condition to persist.
3) Severity gating
If enrichment finds a more critical conclusion than the initial insight, don’t swap it quietly. Create a “notable update” event. Let the UI treat it differently (badge, notification, highlight).
4) Explainable deltas
Every time you publish an update, store a short “why it changed.” Even if you don’t show it to users, it’s essential for debugging and for internal trust.
This is where many teams accidentally build distrust: not by being wrong, but by being unpredictably right in different ways.
Stability-first UI contracts: how improvements stay calm
Most trust breaks happen in the UI. The backend can be perfectly versioned, but if the UI redraws the card in place with different wording, users experience it as “AI changing its mind.”
A stability-first UI contract answers four questions:
What never changes?
The insight’s identity and placement should feel stable—same anchor, same “thing.”
How do we show change?
Make it visible and lightweight: “Updated · 3m ago” or “Refined with more data.”
When do we apply updates?
Avoid updating repeatedly in short windows unless necessary. “No thrash” windows make the product feel composed.
How do we communicate what changed?
One line is enough: “Added overnight trend context” or “Incorporated late upload.”
When you get this right, enrichment feels like a natural deepening—not like correction.
The enrichment pipeline: improve without blocking
A clean progressive pipeline is not complicated, but it is strict about responsibilities:
- Triggers: events that should re-evaluate an insight (late data, aggregation completion, new retrieval index, model upgrade)
- Retriever: pulls context under time budgets with fallbacks
- Inferencer: chooses the right model tier for the current evidence
- Reconciler: applies update rules (confidence bands, hysteresis, severity gating)
- Publisher: writes a new version and marks it as superseding
- Notifier (optional): tells clients that a better version is available
The reconciling step is where “progressive intelligence” becomes real. Without it, you’re just rerunning inference and hoping it looks stable.
A small pattern that keeps enrichment safe is idempotent triggers:
# Deduplicate enrichment work per (insight_id, context_epoch)
key = f"{insight_id}:{context_epoch}"
if seen_before(key):
return # already enriched for this context boundary
run_enrichment(insight_id, context_epoch)
Even with retries, you want “at most one meaningful update per context epoch,” not a cascade of near-identical versions.
Imagine an insight generated shortly after a user interaction, but only partial evidence is available. The system publishes a conservative v1. Later, once uploads complete and deeper retrieval runs, it publishes v2 with better context and a clearer rationale.
Hoomanely’s mission is to make everyday care more understandable and proactive—turning device signals and user context into insights that feel dependable. Progressive intelligence supports that mission by making the product feel steady: early guidance is cautious, later guidance is richer, and updates are transparent rather than surprising.
Operating progressive systems: keep them sane at scale
Progressive pipelines can become noisy if you don’t control them. The goal isn’t “maximum updates.” It’s “meaningful improvements.”
Operational practices that matter:
- Backpressure: cap concurrent enrichments per user/device/session
- Debounce: collapse bursts of triggers into one run
- Timeout discipline: partial results over queue pileups
- Replay tests: late arrivals, out-of-order events, model change mid-stream
And you should track a small set of “health” indicators:
- time to first insight
- time to enriched insight
- average versions per insight (watch for thrash)
- % of updates that change the conclusion vs just add evidence
When these stay stable, your product feels stable.
Takeaways
Progressive intelligence is about earning trust through calm evolution:
- Publish fast, conservative insights under tight budgets.
- Enrich asynchronously with deeper context and stronger inference.
- Never rewrite history—supersede with explicit updates.
- Use confidence bands and hysteresis to prevent flip-flops.
- Treat the UI as a contract: stable anchors, visible updates, small deltas.
- Operate enrichment like infrastructure: dedupe, backpressure, replay.
Users trust systems that improve because they can feel the system behaving responsibly—not because the first answer was perfect.



