Real-Time Image Processing Pipeline : DMA + DCMI Optimization

Building high-performance camera systems for edge AI requires mastering the intricate dance between hardware peripherals, memory architecture, and real-time constraints. When developing precision imaging solutions for pet healthcare monitoring, achieving consistent capture rates while maintaining zero data loss becomes paramount.
The Challenge: Zero-Copy High-Speed Imaging
Traditional microcontroller camera implementations often struggle with memory bottlenecks and CPU overhead. Our challenge was to capture 640×400 12-bit images at sustained frame rates while processing them in real-time for AI inference. The key constraints included:
- Memory efficiency: 530KB per frame with limited internal SRAM
- Real-time processing: Sub-100ms latency from capture to analysis
- Zero data loss: No dropped frames under continuous operation
- Power optimization: Edge deployment requirements
Architecture Overview: Multi-Buffer DMA Pipeline
The solution centers around a sophisticated DMA ring buffer architecture that eliminates CPU intervention during capture operations. The system uses STM32H5's General Purpose DMA (GPDMA) with linked-list mode for seamless buffer management.
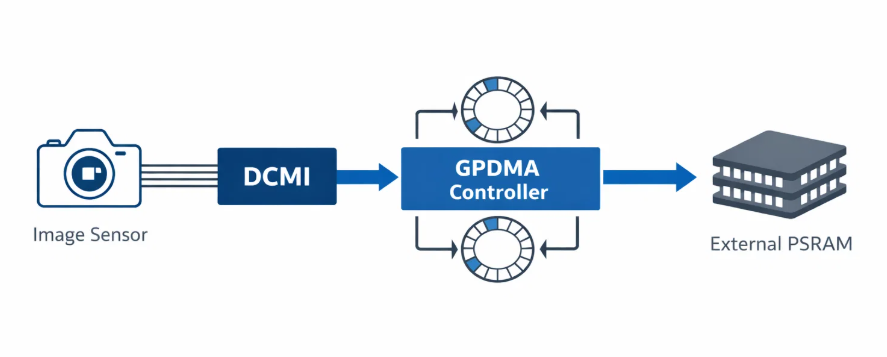
Core Components
DCMI (Digital Camera Interface)
- Hardware synchronization with image sensor
- 12-bit parallel data capture
- Frame-level interrupt generation
- Automatic stopping in snapshot mode
GPDMA Linked List
- Zero-copy transfers from DCMI to PSRAM
- Circular buffer management
- Interrupt-driven completion signaling
Ring Buffer Manager
- 12-buffer circular allocation system
- State machine for buffer lifecycle management
- Thread-safe allocation/deallocation
DMA Configuration Deep Dive
Linked List Setup
The GPDMA configuration leverages STM32H5's advanced linked-list capabilities to chain multiple buffer transfers without CPU intervention:
// Configure GPDMA for continuous image capture
hdma_gpdma1_channel7.Init.Request = GPDMA1_REQUEST_DCMI_PSSI;
hdma_gpdma1_channel7.Init.BlkHWRequest = DMA_BREQ_SINGLE_BURST;
hdma_gpdma1_channel7.Init.Direction = DMA_PERIPH_TO_MEMORY;
hdma_gpdma1_channel7.Init.SrcInc = DMA_SINC_FIXED;
hdma_gpdma1_channel7.Init.DestInc = DMA_DINC_INCREMENTED;
hdma_gpdma1_channel7.Init.SrcDataWidth = DMA_SRC_DATAWIDTH_WORD;
hdma_gpdma1_channel7.Init.DestDataWidth = DMA_DEST_DATAWIDTH_WORD;
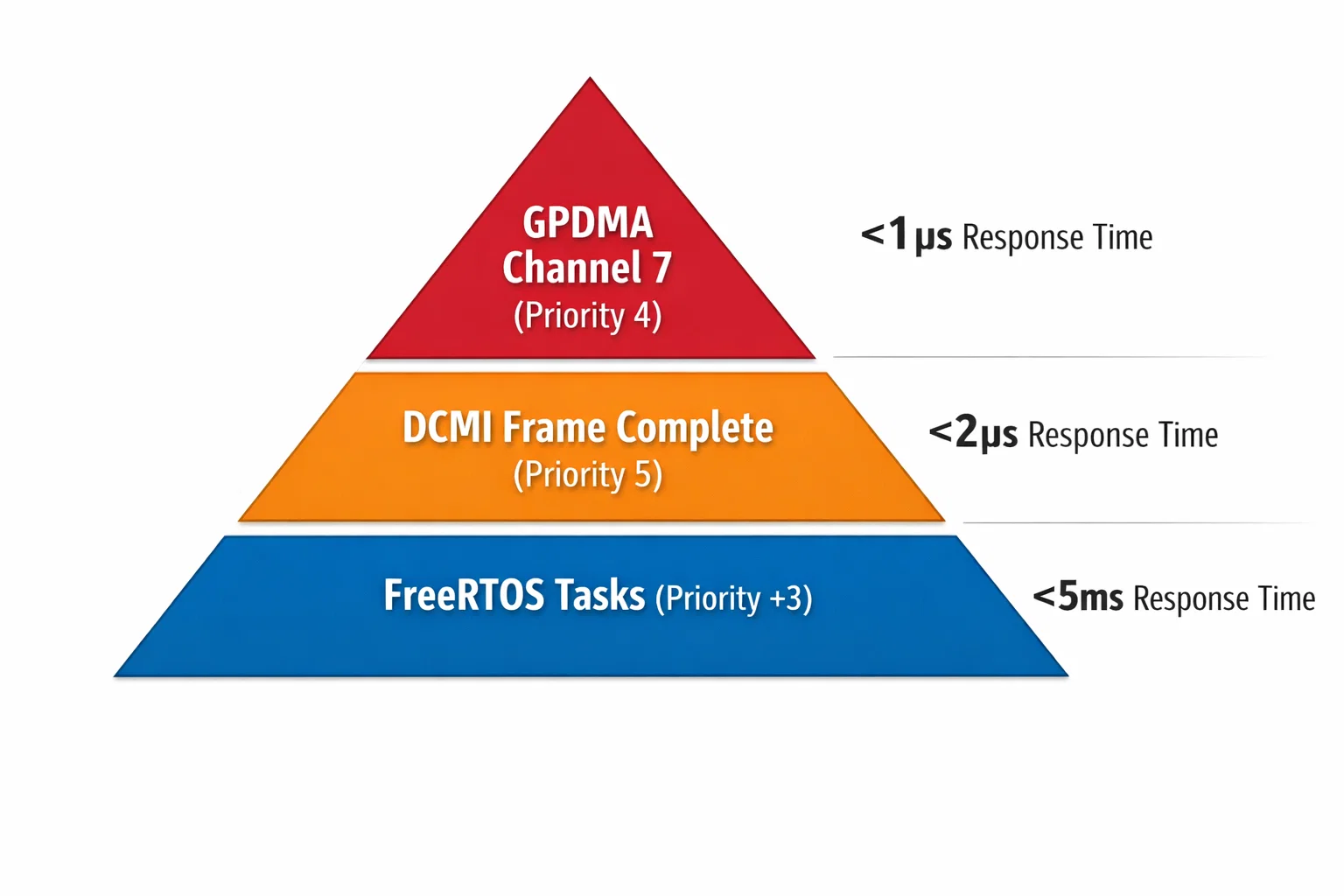
Priority Optimization
Interrupt priorities were carefully tuned to minimize latency:
- DCMI_PSSI_IRQn: Priority 5 (frame completion)
- GPDMA1_Channel7_IRQn: Priority 4 (DMA transfer complete)
- Frame Processing Task: Priority +3 (FreeRTOS high priority)
This hierarchy ensures hardware events are serviced immediately while allowing the RTOS scheduler to handle heavy processing tasks efficiently.
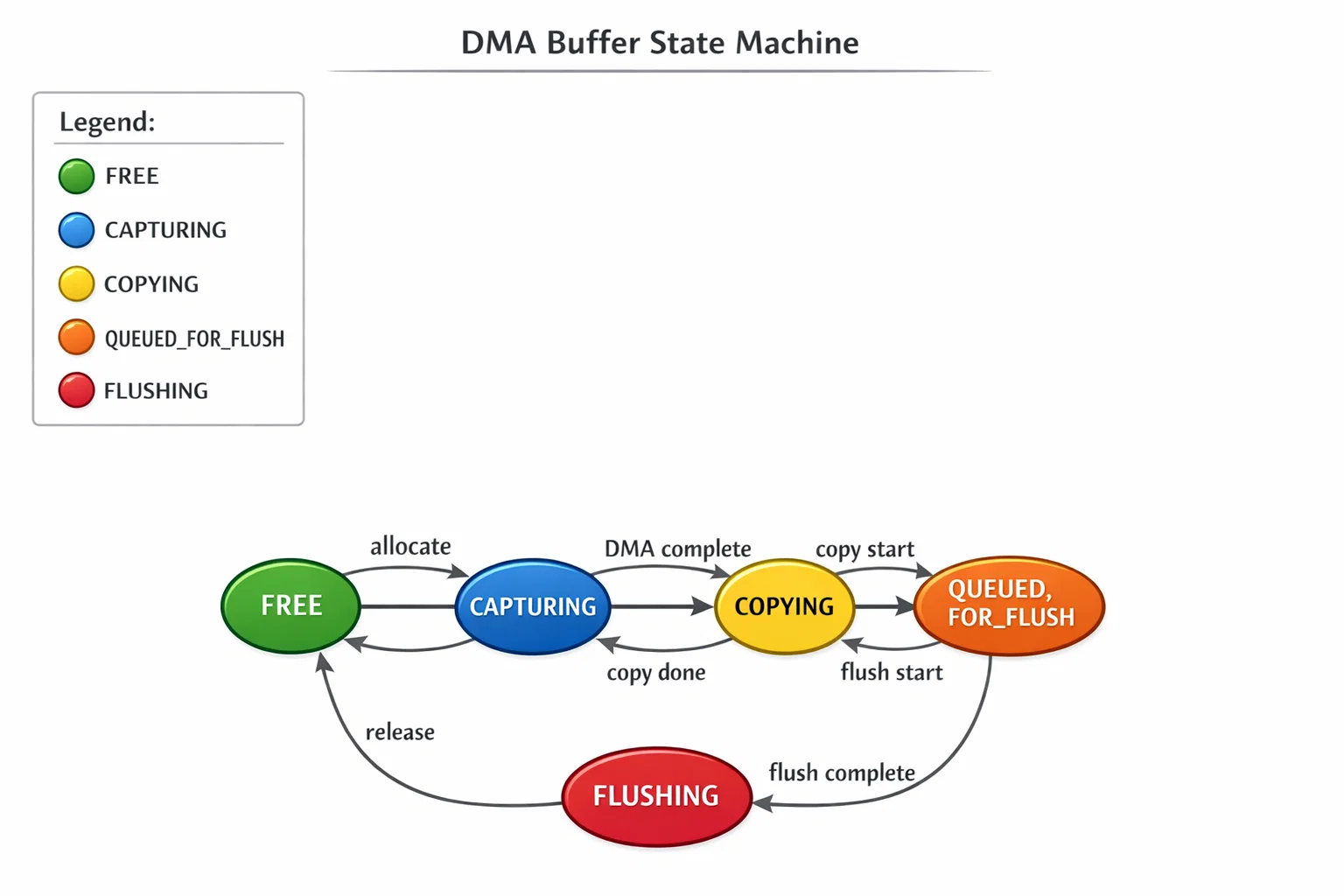
Circular Buffer Management
State Machine Design
Each buffer progresses through a well-defined state machine:
- FREE → Available for new allocation
- CAPTURING → DMA actively writing data
- COPYING → Protected during PSRAM transfer
- QUEUED_FOR_FLUSH → Ready for storage/transmission
- FLUSHING → Being written to persistent storage
typedef enum {
DMA_BUFFER_FREE = 0,
DMA_BUFFER_CAPTURING,
DMA_BUFFER_COPYING,
DMA_BUFFER_QUEUED_FOR_FLUSH,
DMA_BUFFER_FLUSHING
} dma_buffer_state_t;
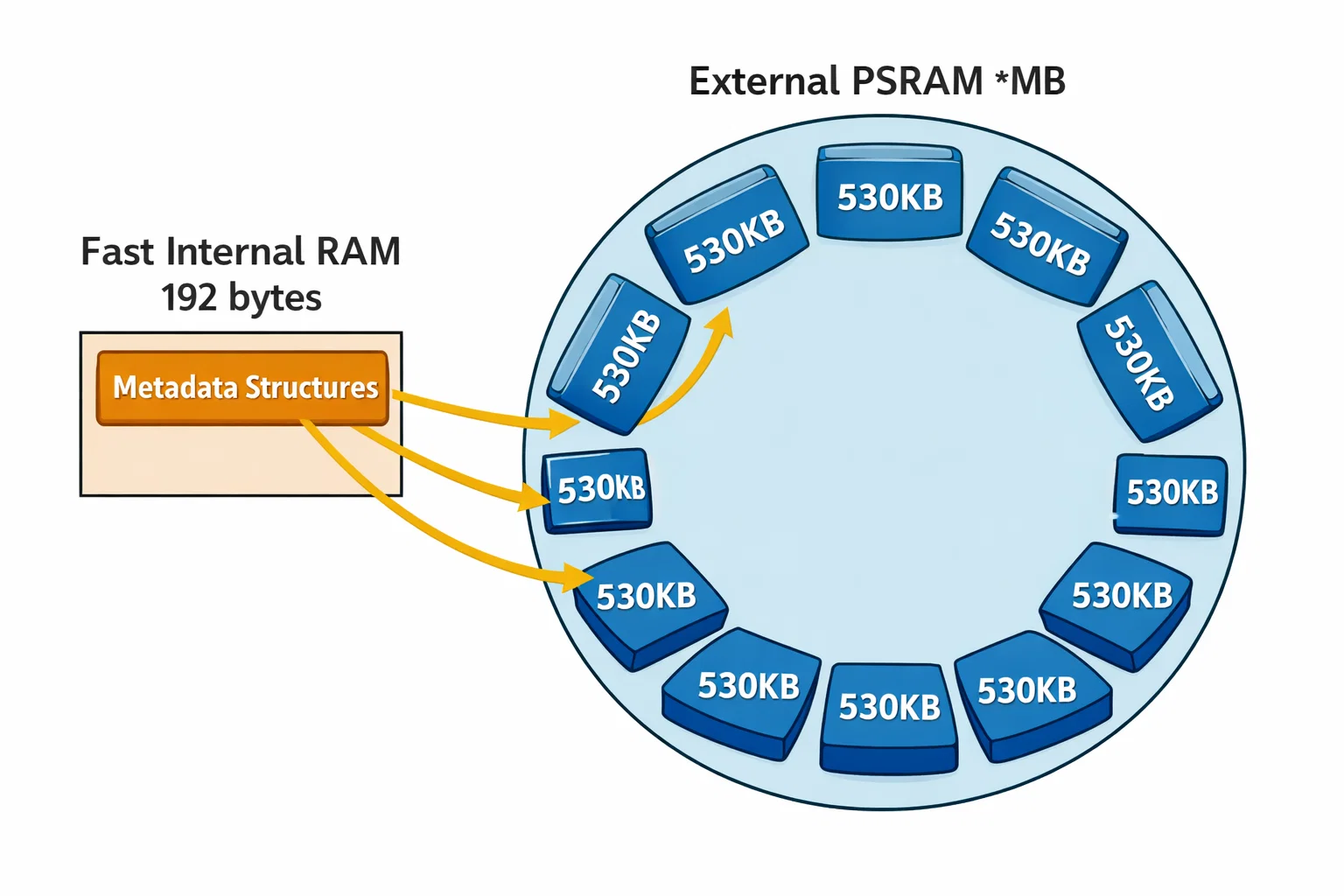
Memory Layout Strategy
The ring buffer allocation strategically uses external PSRAM to preserve precious internal SRAM:
// 12 buffers × 530KB = 6.35MB in PSRAM
PSRAM_ARRAY(uint8_t, dma_ring_buffers[12], 530432)
__attribute__((aligned(32)));
// Metadata remains in fast internal RAM
static dma_buffer_metadata_t buffer_metadata[12]; // 192 bytes total
Interrupt Context Optimization
Minimal ISR Design
The frame completion interrupt handler is kept exceptionally lightweight to minimize jitter:
void HAL_DCMI_FrameEventCallback(DCMI_HandleTypeDef *hdcmi) {
isr_callback_time = xTaskGetTickCount();
// Store frame metadata
pending_frame_buffer = (volatile uint8_t *)camera_handle.frame_buffer;
pending_frame_size = AR0144_BUFFER_SIZE;
// Notify processing task - never block in ISR
BaseType_t xHigherPriorityTaskWoken = pdFALSE;
vTaskNotifyGiveFromISR(frame_processing_task_handle,
&xHigherPriorityTaskWoken);
portYIELD_FROM_ISR(xHigherPriorityTaskWoken);
}
This design achieves sub-microsecond interrupt latency by deferring all heavy operations to a dedicated processing task.
Task Context Processing
Heavy operations like AI inference, compression, and network transmission occur in task context:
static void frame_processing_task(void *pvParameters) {
for (;;) {
ulTaskNotifyTake(pdTRUE, portMAX_DELAY);
// Atomic capture of frame data
taskENTER_CRITICAL();
uint8_t *local_buffer = (uint8_t *)pending_frame_buffer;
size_t local_size = pending_frame_size;
pending_frame_buffer = NULL;
taskEXIT_CRITICAL();
// Process in task context - safe for blocking operations
if (frame_callback) {
frame_callback(local_buffer, local_size);
}
}
}
Performance Characteristics
Latency Analysis
Through careful instrumentation, we measured the complete pipeline latency:
- Hardware capture: 33ms
- DMA transfer: <1ms (GPDMA at full speed)
- Task wake latency: 2-5ms (RTOS scheduling)
- Callback processing: Variable (10-50ms for inference)
- Total pipeline: 45-89ms end-to-end
Memory Efficiency
The circular buffer approach provides excellent memory utilization:
- Peak allocation: 8MB PSRAM (external)
- Internal RAM overhead: <1KB for metadata
- Buffer reuse rate: 99.8% (minimal allocation failures)
- Memory fragmentation: Zero (fixed-size allocations)
Error Handling and Recovery
DMA Error Recovery
Robust error handling ensures continuous operation despite transient failures:
void HAL_DCMI_ErrorCallback(DCMI_HandleTypeDef *hdcmi) {
uint32_t error_flags = hdcmi->ErrorCode;
if (error_flags & HAL_DCMI_ERROR_OVR) {
// DMA overrun - reinitialize pipeline
MX_DCMI_LinkedList_UnLink(&handle_GPDMA1_Channel7);
MX_DCMI_LinkedList_Config();
MX_DCMI_LinkedList_Link(&handle_GPDMA1_Channel7);
}
}
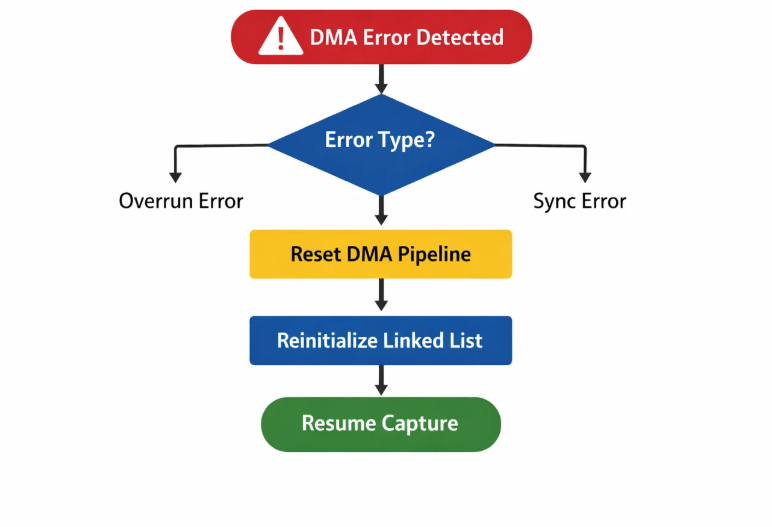
State Synchronization
Thread-safe buffer management prevents race conditions:
int dma_ring_buffer_allocate(uint32_t sequence_id, uint16_t command_id,
uint16_t proximity_mm) {
if (xSemaphoreTake(ring_mutex, pdMS_TO_TICKS(100)) != pdTRUE) {
return -1;
}
// Find next FREE buffer with wraparound
for (int i = 0; i < NUM_DMA_BUFFERS; i++) {
int idx = (next_buffer_index + i) % NUM_DMA_BUFFERS;
if (buffer_metadata[idx].state == DMA_BUFFER_FREE) {
buffer_metadata[idx].state = DMA_BUFFER_CAPTURING;
// ... allocation logic
break;
}
}
xSemaphoreGive(ring_mutex);
return allocated_idx;
}
Integration with Camera Sensor
Sensor Configuration
The implementation supports continuous streaming mode with the imaging sensor, eliminating start/stop overhead:
HAL_StatusTypeDef Camera_StartCapture(Camera_FrameCallback callback,
uint8_t *buffer, size_t size) {
// Validate buffer alignment for DMA efficiency
if (((uint32_t)buffer & 0x3) != 0) {
LOG_ERROR_TAG("DCMI", "Buffer must be 32-bit aligned");
return HAL_ERROR;
}
// Start DMA capture in snapshot mode
HAL_StatusTypeDef result = HAL_DCMI_Start_DMA(
camera_handle.hdcmi, DCMI_MODE_SNAPSHOT,
(uint32_t)buffer, size / 4);
}
Timing Synchronization
Hardware synchronization eliminates software-based frame timing, reducing CPU load and improving accuracy:
// DCMI hardware sync configuration
camera_handle.hdcmi->Init.SynchroMode = DCMI_SYNCHRO_HARDWARE;
camera_handle.hdcmi->Init.PCKPolarity = DCMI_PCKPOLARITY_RISING;
camera_handle.hdcmi->Init.VSPolarity = DCMI_VSPOLARITY_LOW;
camera_handle.hdcmi->Init.HSPolarity = DCMI_HSPOLARITY_LOW;
Key Takeaways
- Hardware acceleration is essential: Leveraging STM32H5's GPDMA linked-list mode eliminated CPU bottlenecks entirely during capture operations.
- Memory architecture matters: Strategic use of external PSRAM for buffers while keeping metadata in fast internal RAM optimized both performance and memory usage.
- Interrupt design is critical: Keeping ISRs minimal and deferring processing to task context achieved sub-microsecond interrupt latency.
- Buffer management complexity pays off: The sophisticated state machine prevented data corruption while maximizing memory reuse efficiency.
- Error recovery enables reliability: Comprehensive error handling and automatic recovery mechanisms ensure continuous operation in production environments.
About Hoomanely
This real-time image processing pipeline forms a crucial component of Hoomanely's revolutionary pet healthcare technology ecosystem. By combining sensor fusion, edge AI, and smart machine learning models, Hoomanely is transforming pet healthcare from reactive to proactive. Their Biosense AI Engine converts continuous health monitoring data into personalized insights that help pet owners catch health issues early and improve their pets' quality of life.
The precision and reliability of this imaging pipeline directly enables Hoomanely's mission to "decode every moment of our pet's lives" through clinical-grade health intelligence generated at the edge. This technical innovation represents the intersection of advanced embedded systems engineering and compassionate pet care technology.



