Real-Time Linux for High-Throughput Edge Control

Introduction
When designing mission-critical edge devices, engineers often face a familiar trade-off. On one side is Linux—powerful, flexible, and rich with ecosystems for networking, AI, and analytics. On the other is the deterministic world of bare-metal or RTOS-based microcontrollers, trusted for precise timing and reliability.
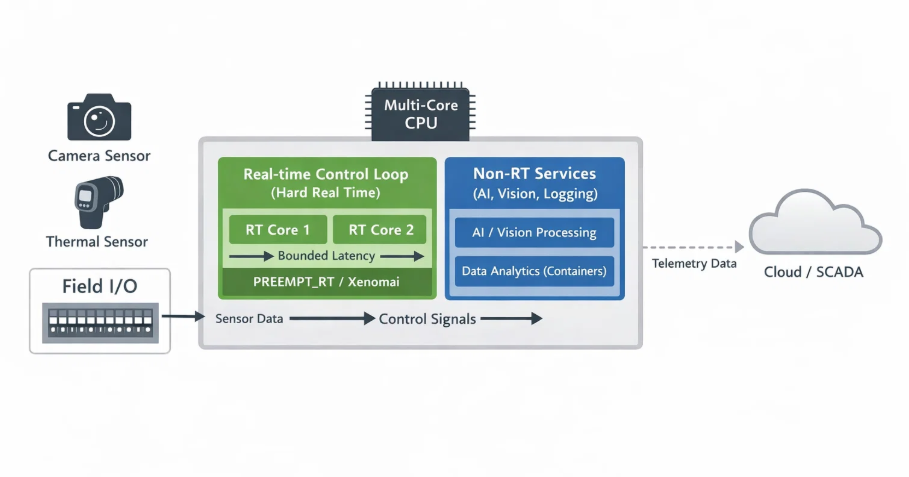
In a recent edge-AI system, we couldn’t afford to choose one over the other. We needed Linux to run complex inference pipelines and system orchestration, while simultaneously handling extreme sensor data rates with firmware-grade reliability. Packet loss, jitter, or delayed processing were not acceptable—even for a few milliseconds.
This post walks through how we architected a Linux-based real-time ingestion pipeline capable of sustaining 100,000+ events per second with zero packet loss, using proven embedded-systems principles applied deliberately inside a Linux environment.
The Problem: Where Linux Falls Short
Linux is optimized for throughput, not determinism. Its default networking and IPC paths work exceptionally well for bulk data transfers—files, streams, and sockets measured in kilobytes or megabytes.
Our workload was very different.
We relied on CAN-FD to stream high-frequency sensor data from multiple peripherals. CAN-FD supports higher bitrates and larger payloads than classic CAN, which is ideal for modern sensor fusion. But during peak operation, sensors transmit data in bursts, creating thousands of interrupts within milliseconds.
Under standard Linux configurations, this leads to a common failure mode:
- Kernel socket buffers fill up quickly
- User-space threads can’t drain them fast enough
- The kernel starts dropping frames silently
For a system built on the principle that every signal matters, even brief data loss was unacceptable.
The Approach: Treat Linux Like Firmware
The key realization was simple: Linux cannot be treated as a black box.
To achieve microcontroller-like reliability, we applied three well-known embedded design principles directly to Linux user space and kernel interfaces:
- Aggressive kernel-level buffering to absorb bursts
- Strict producer–consumer separation with CPU isolation
- Explicit flow control instead of blind data ingestion
Together, these steps transformed Linux from a “best-effort” OS into a predictable real-time data engine.
Step 1: Breaking Kernel Buffer Limits
By default, Linux socket receive buffers are intentionally small—often tens or hundreds of kilobytes. This is sensible for general workloads but completely inadequate for high-frequency sensor streams.
To handle burst traffic safely, we used the SO_RCVBUFFORCE socket option. Unlike SO_RCVBUF, this option allows privileged processes to override system-wide buffer limits, provided the process has CAP_NET_ADMIN.
We force-allocated a 32 MB receive buffer per socket. This large buffer acts as a shock absorber, holding incoming data long enough for user-space threads to process it without loss.
int size = 32 * 1024 * 1024; // 32 MB
setsockopt(sock, SOL_SOCKET, SO_RCVBUFFORCE,
&size, sizeof(size));
This single change dramatically reduced packet drops during burst scenarios by giving Linux more time to breathe.
Why this matters:
You are not “making Linux faster”—you are buying time. Large buffers convert microsecond-scale bursts into manageable workloads.

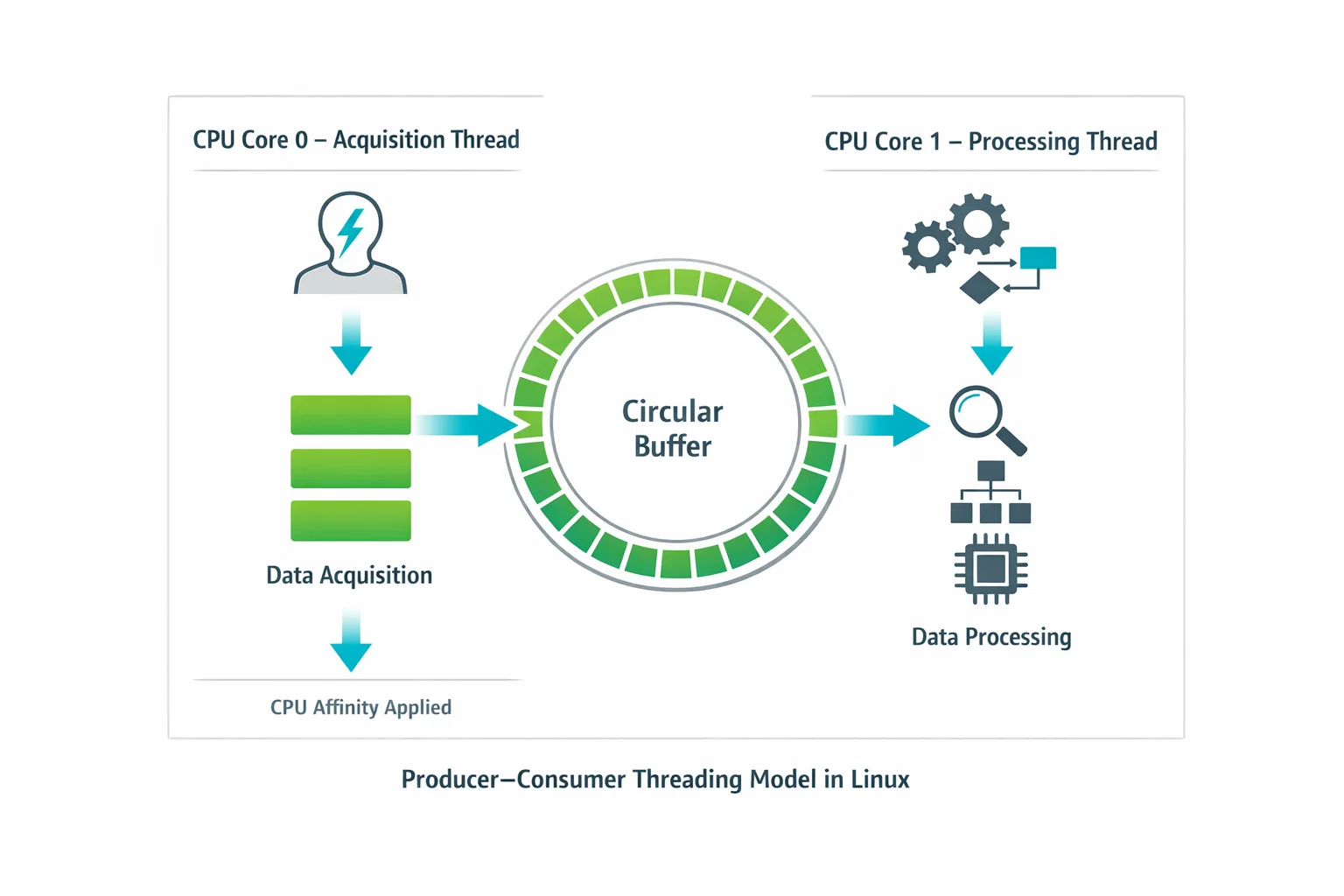
Step 2: Producer–Consumer, the Firmware Way
Large buffers alone are not enough. Data must still be drained fast and predictably.
We adopted a strict producer–consumer model, directly inspired by DMA-driven firmware designs.
- Producer Thread (Acquisition)
- Runs a tight loop calling
recvmsg() - Copies raw frames into a lock-free circular buffer
- Performs no parsing, no logging, no allocation
- Pinned to a dedicated CPU core using
pthread_setaffinity_np
- Runs a tight loop calling
- Consumer Thread (Processing)
- Parses protocol frames
- Performs validation and decoding
- Handles application-level logic and storage
This separation ensures that expensive operations never block the critical data-ingestion path.
Step 3: Software-Defined Flow Control
Even with deep buffers and optimized threading, no system can handle infinite input. If sensors transmit faster than the CPU can process data for long enough, failure is inevitable.
Instead of hoping this never happens, we designed for it.
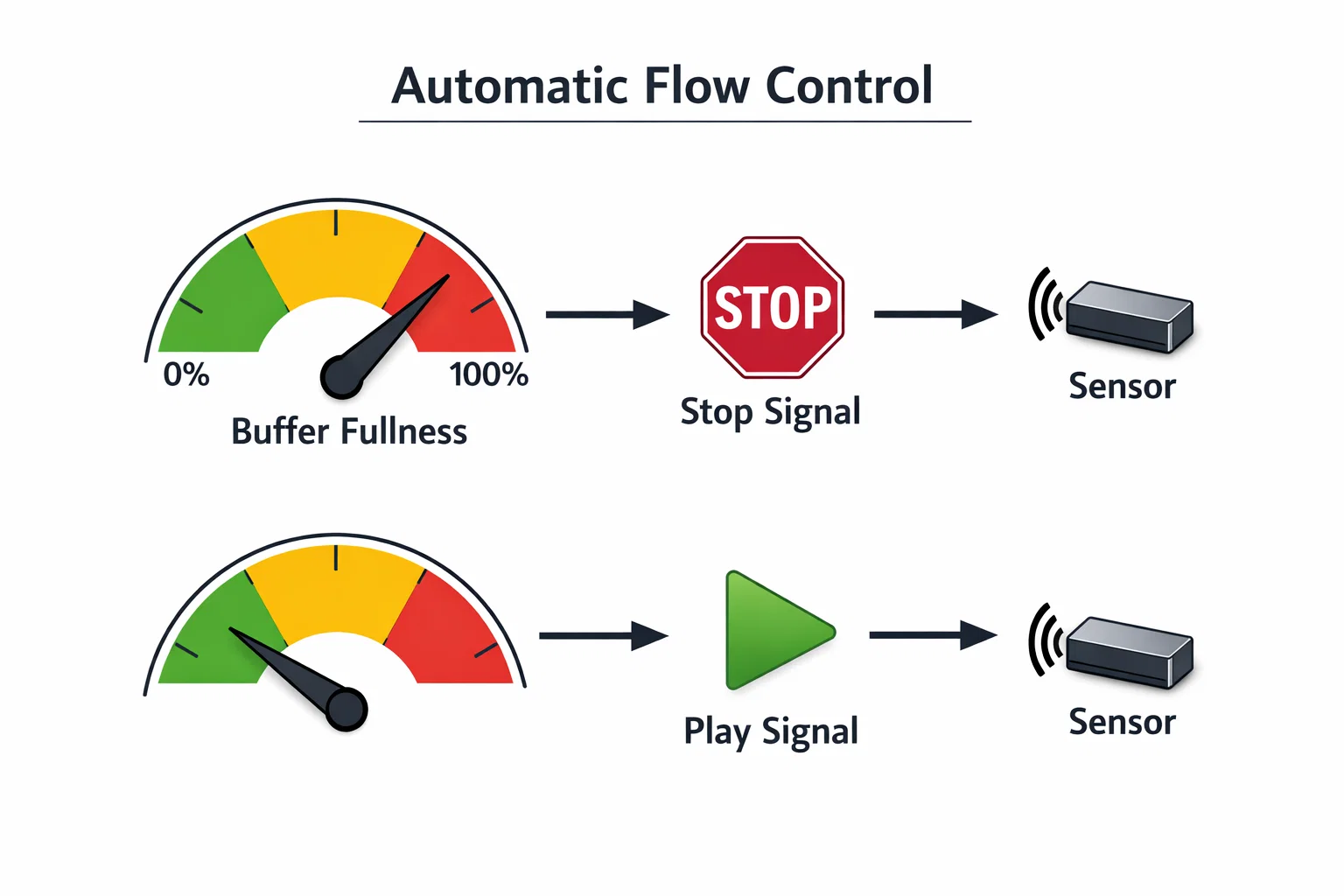
We implemented explicit backpressure using a simple watermark-based flow-control mechanism:
- High watermark (≈80%)
When the circular buffer reaches this level, the system sends a high-priority PAUSE command over the bus. Sensors immediately suspend transmission. - Low watermark (≈20%)
Once the buffer drains, a RESUME command is sent, and normal data flow continues.
This creates a closed-loop control system between the Linux host and external sensors.
Why this is critical:
Linux applications rarely implement backpressure at the protocol level. In embedded systems, it is often the difference between graceful degradation and catastrophic failure.
Results: From Best-Effort to Deterministic
After applying these changes, the system behavior changed dramatically:
- Packet loss: Reduced from ~3% during burst traffic to 0.00%
- Throughput: Sustained 100,000+ events per second
- Stability: Continuous operation under peak load without buffer overruns or thermal throttling
- Latency: Predictable ingestion latency suitable for closed-loop control
Most importantly, the system now fails gracefully. When overloaded, it pauses inputs instead of silently losing data.
Why This Matters at Hoomanely
At Hoomanely, our mission is to reinvent pet healthcare through Physical Intelligence. That means capturing subtle, high-frequency signals—thermal changes, motion patterns, posture shifts—that are invisible to the human eye but critical for early intervention.
This architecture powers the real-time sensor fusion layer inside our edge devices. By ensuring complete, lossless data capture, we give downstream AI models the full context they need to detect issues early and reliably.
In preventive healthcare, missing data is not just a technical flaw—it’s a missed opportunity to help an animal sooner.



